QUIC, TLS 1.3, DNS-over-HTTPS, далее везде
Хабр, привет! Это транскрипция доклада Артема ximaera Гавриченкова, прочитанного им на BackendConf 2018 в рамках прошедшего фестиваля РИТ++.

Здравствуйте!
В названии доклада приведён длинный список протоколов, мы по нему пройдемся постепенно, но давайте начнем с того, чего в названии нет.
Это (под катом) заголовок одного из блогов, в интернете вы могли таких заголовков видеть очень много. В том посте написано, что HTTP/2 — это не какое-то отдаленное будущее, это наше настоящее; это современный протокол, разработанный Google и сотнями профессионалов из многих продвинутых компаний, выпущенный IETF в качестве RFC в далеком 2015 году, то есть уже 3 года назад.
Стандарты IETF воспринимаются индустрией, как такие железобетонные документы, как могильная плита, фактически.
Планируется, что они определяют развитие интернета и учитывают все возможные сценарии использования. То есть, если у нас была старая версия протокола, а потом появилась новая, то она точно сохраняет совместимость со всеми предыдущими юзкейсами и дополнительно решает кучу проблем, оптимизирует работу и так далее.
HTTP/2 должен был быть адаптирован для продвинутого веба, готов к использованию в современных сервисах и приложениях, фактически быть drop-in replacement для старых версий протокола HTTP. Он должен был повышать производительность сайта, параллельно снижая нагрузку на бэкенд.

Даже SEO-шники говорили, что им нужен HTTP/2.

И его, вроде как, было очень просто поддержать. В частности, Нил Крейг из BBC писал в своем блоге, что достаточно «просто включить» его на сервере. Еще можно найти множество презентаций, где написано, что HTTP/2 включается следующим образом: если у вас Nginx, то можно в одном месте поправить конфигурацию; если нет HTTPS, нужно ещё дополнительно поставить сертификат; но, в принципе, это вопрос одного токена в конфигурационном файле.
И, естественно, после того, как вы пропишете этот токен, вы сразу начинаете получать бонусы от повышения производительности, новых доступных фич, возможностей — в общем, всё становится замечательно.

Ссылки со слайда:
1. medium.com/@DarkDrag0nite/how-http-2-reduces-server-cpu-and-bandwidth-10dbb8458feb
2. www.cloudflare.com/website-optimization/http2
Дальнейшая история основана на реальных событиях. Компания имеет некоторый онлайн-сервис, обрабатывающий порядка 500–1000 HTTP-запросов в секунду. Сервис этот находится под DDoS-защитой Cloudflare.
Существует множество бенчмарков, которые подтверждают, что переход на HTTP/2 снижает нагрузку на сервер вследствие того, что при переходе на HTTP/2 браузер устанавливает уже не 7 соединений, а по плану вообще одно. Ожидалось, что при переходе на HTTP/2 и памяти используемой станет меньше, и процессор будет менее нагружен.
Плюс к этому в блоге Cloudflare и на сайте Cloudflare предлагается включить HTTP/2 просто одним кликом. Вопрос: почему бы так не сделать?

1 февраля 2018 года компания включает HTTP/2 этой самой кнопочкой в Cloudflare, и на локальном Nginx тоже его включает. Месяц собираются данные. 1-го марта происходит замер потребляемых ресурсов, и потом sysops’ы смотрят число запросов в логах, которые приходят по HTTP/2 на стоящий за Cloudflare сервер. На следующем слайде будет процент запросов, пришедших на сервер по HTTP/2. Поднимите руки, кто знает, какой будет этот процент?
Из зала:»1–2%»

Ноль. По какой причине?
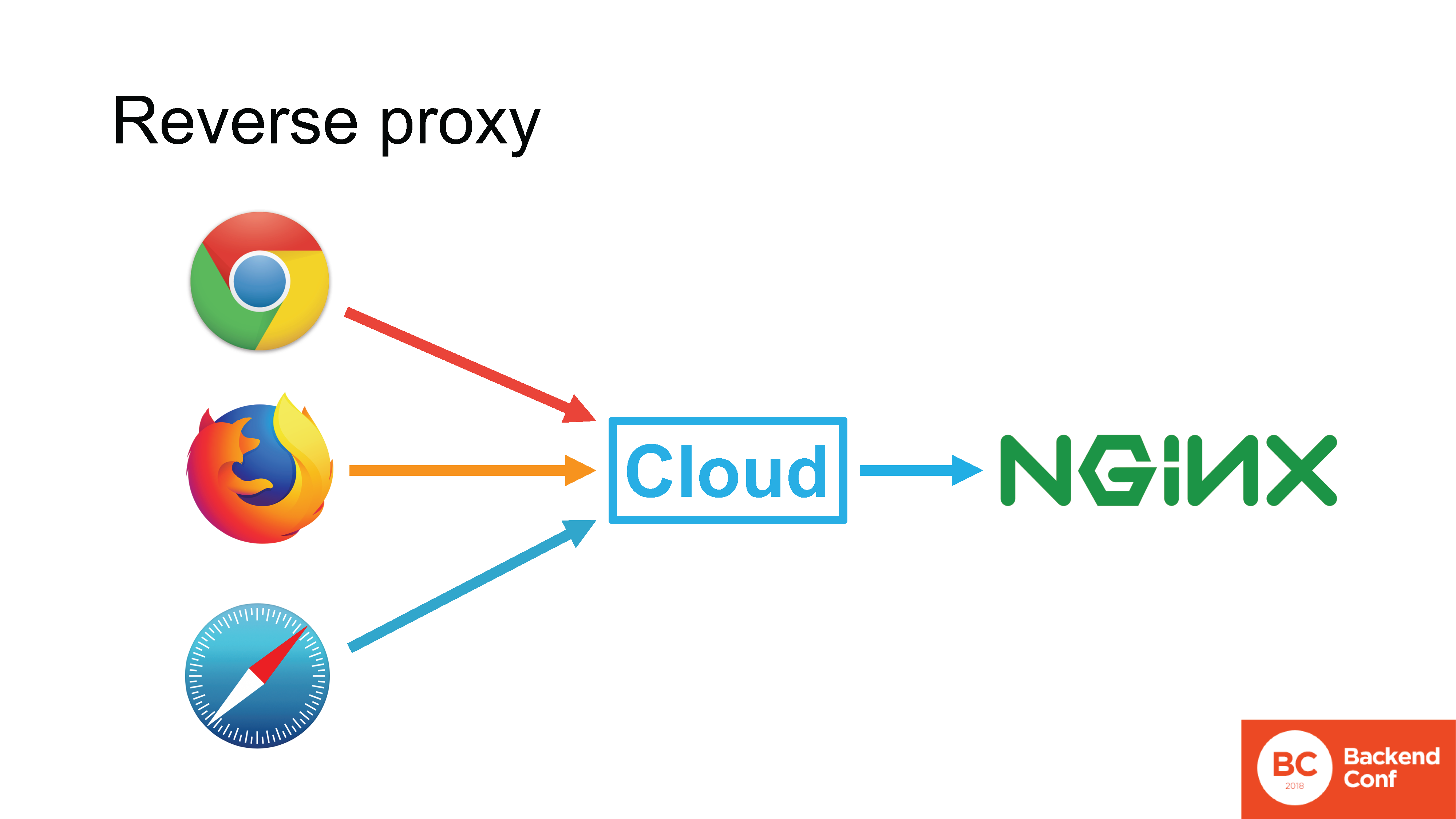
Cloudflare, а так же другие сервисы по защите от атак, MSSP и облачные сервисы, работают в режиме reverse proxy. Если в нормальной ситуации браузер напрямую соединяется с вашим Nginx, то есть соединение идет напрямую от браузера до вашего HTTP-сервера, то вы можете использовать тот протокол, который браузер поддерживает.
В случае, если между браузером и вашим сервером стоит облако, пришедшее TCP-соединение терминируется в облаке, TLS тоже там терминируется, и HTTP-запрос сначала попадает на облако, далее облако фактически обрабатывает этот запрос.
У облака есть собственный HTTP-сервер, в большинстве случаев тот же самый Nginx, в редких случаях это «самописный» сервер. Этот сервер парсит запрос, как-то его обрабатывает, консультируется с кэшами и, в конечном итоге, формирует новый запрос и отправляет его уже на ваш сервер по тому протоколу, который он поддерживает.
Все существующие облака, заявляющие о поддержке HTTP/2, поддерживают HTTP/2 на стороне, смотрящей в браузер. Но не поддерживают его на стороне, смотрящей к вам.
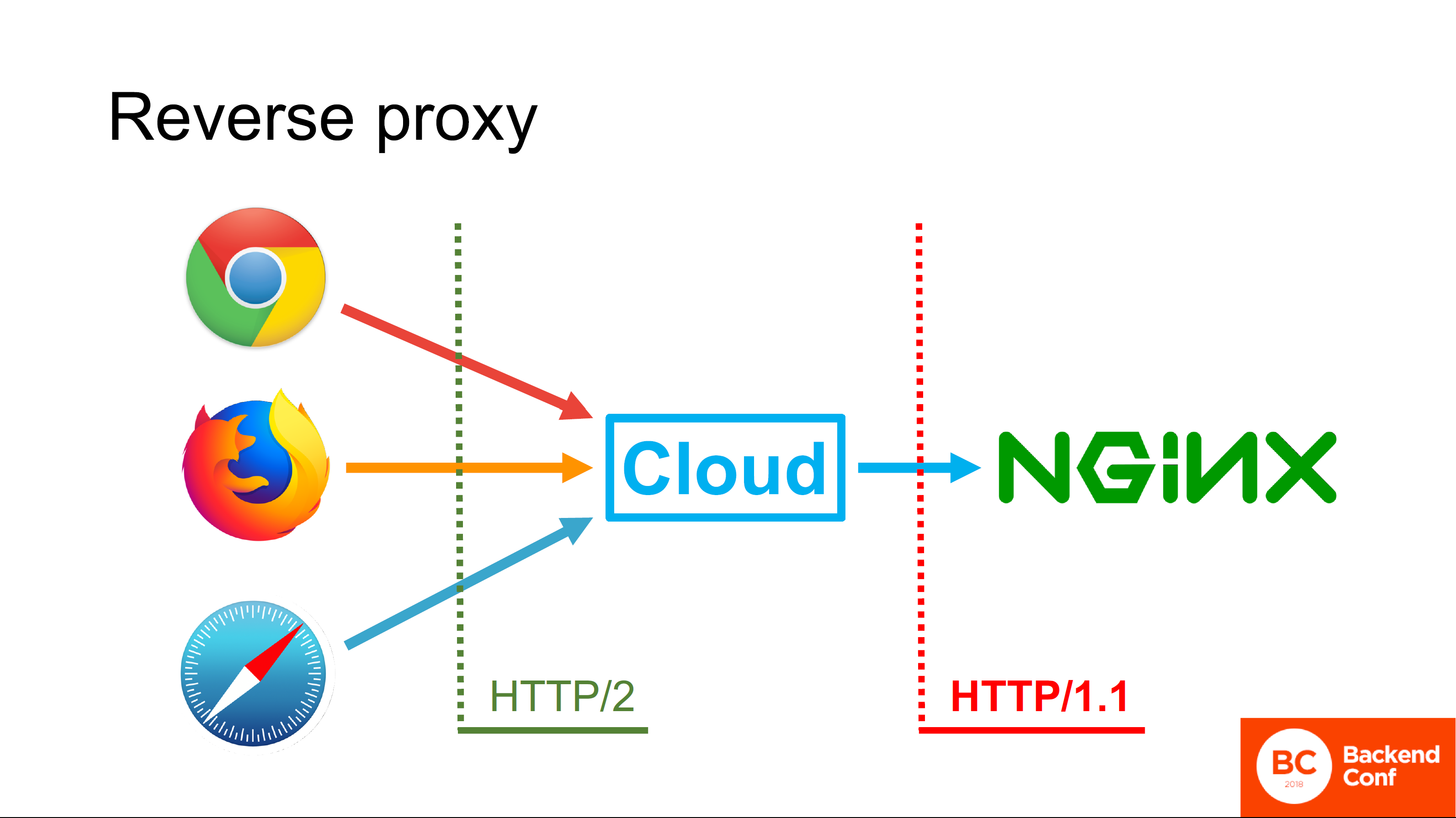
Почему?
Простой и не совсем правильный ответ: «Потому что в большинстве случаев у них развёрнут Nginx, а Nginx не умеет ходить по HTTP/2 к апстриму». Окей, хорошо, это ответ правильный, но не полный.

Полный ответ нам дают инженеры Cloudflare. Дело в том, что в фокусе спецификации HTTP/2, написанной и выпущенной в 2015 году, было повышение производительности браузера на специфичных, например, для Google сценариях использования.
Google использует собственные технологии, не использует reverse proxy перед своими production-серверами, поэтому о reverse proxy никто не подумал, и именно поэтому HTTP/2 от облака до апстрима не используется. Там, на самом деле, и профита мало, потому что в режиме reverse proxy, из того, что описано в протоколе HTTP/2, например, Server Push не поддерживается, потому что непонятно, как он должен работать, если у нас pipelining.
То, что HTTP/2 экономит соединения — это круто, но reverse proxy сам по себе их экономит, потому что он не открывает по одному соединению на каждого пользователя. Смысла поддерживать здесь HTTP/2 мало, а накладные расходы и проблемы связанные с этим — большие.

Что важно: reverse proxy — это технология, которая начала активно использоваться порядка 13 лет назад. То есть это технология середины 2000 годов: я еще в школу ходил, а она уже использовалась. В стандарте, выпущенном в 2015 году, она не упоминается, не поддерживается и работа по ее поддержке, на данный момент, в рабочей группе httpbis в IETF не ведется.
Это один пример тех вопросов, которые возникают, когда люди начинают внедрять HTTP/2. На самом деле, когда разговариваешь с людьми, которые развернули и имеют уже какой-то опыт работы с ним, постоянно слышишь примерно одни и те же слова.

Лучше всего их сформулировал Максим Матюхин из Badoo в посте на Хабре, где он рассказывал о том, как работает HTTP/2 Server Push. Он написал, что его сильно удивило, насколько отличается взаимодействие конкретно этой функциональности с браузерами, ведь он думал, что это полностью отработанная фича, готовая к использованию в продакшене. Эту фразу в отношении HTTP/2 я слышал уже очень много раз: думали, что это протокол, который «drop-in replacement» — то есть включаешь его, и все нормально — почему же на практике всё так сложно, откуда возникают все эти проблемы и недоработки?
Давайте разберемся.
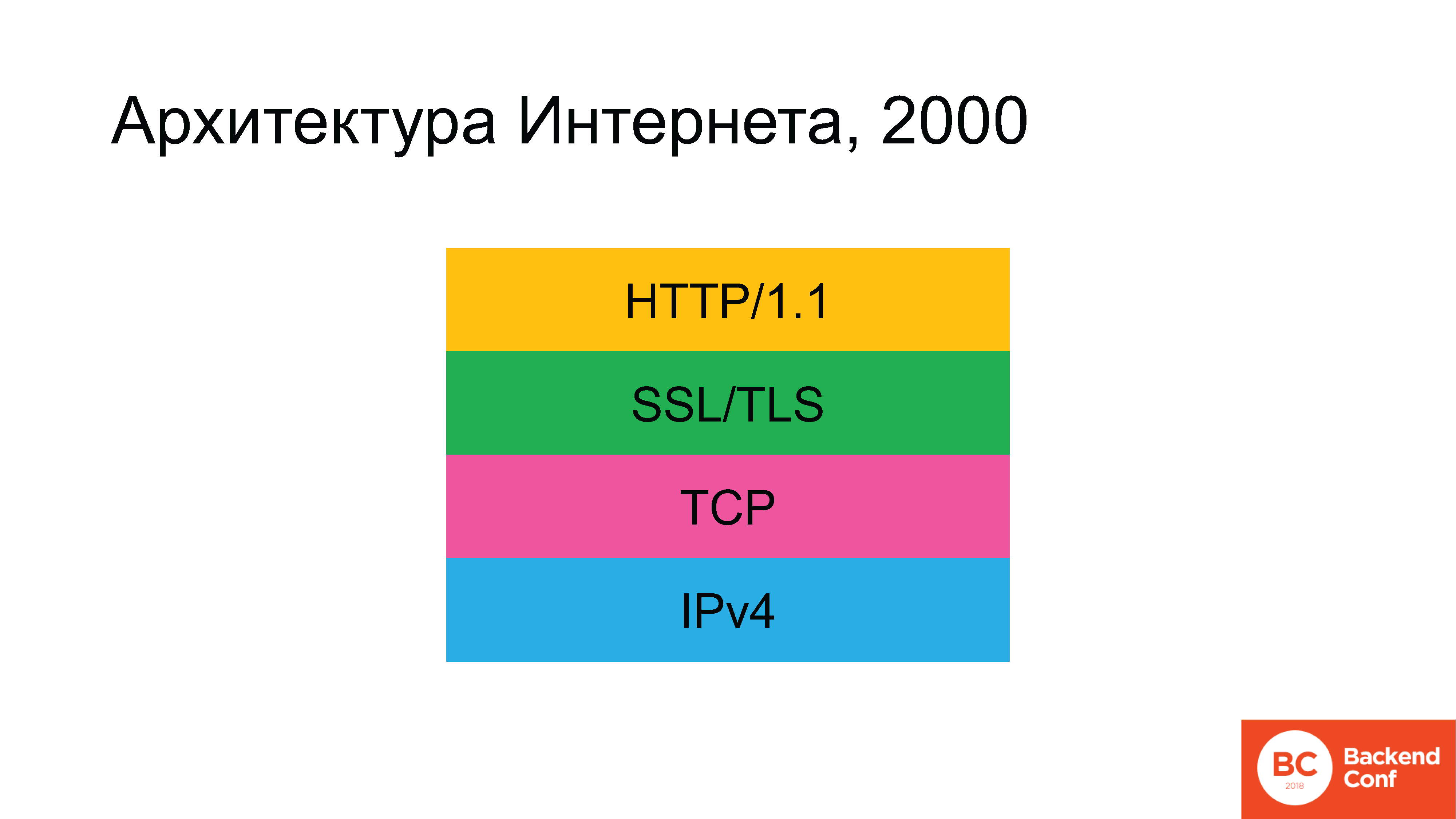
Исторически, в стародавние времена, архитектура интернета выглядела примерно следующим образом. Зеленого прямоугольника в какой-то момент не было, но потом он появился.
Протоколы использовались следующие: так как мы говорим про Интернет, а не про локальную сеть, то на нижнем уровне начинаем с протокола IPv4. Выше него использовался протокол TCP — или UDP, но для 90% случаев (так как 80–90% трафика в интернете — это Web) дальше был TCP, — затем SSL (который потом заменили на TLS), а выше уже был гипертекстовый протокол HTTP. Постепенно сложилась ситуация, что, по плану, к 2020 году архитектура интернета должна была в корне поменяться.

Протокол IPv6 с нами уже очень давно. TLS недавно обновили, мы еще обсудим, как это происходило. И протокол HTTP/2 тоже обновился.
У замечательного отечественного фантаста Вадима Панова в цикле «Анклавы» была такая прекрасная фраза: «Вы ждали будущего. Вы хотели будущего? Оно наступило. Вы его не хотели? Оно все равно наступило». Единственное, что осталось практически нетронутым — по состоянию на пару лет назад — это протокол TCP.
Люди, которые занимаются дизайном интернета, не могли пройти мимо такой вопиющей несправедливости и решили протокол TCP выкинуть тоже.
Ладно, это, конечно же, шутка. Проблема не просто в том, что протокол слишком старый. В протоколе TCP есть недостатки. Особенно многих беспокоило, что протокол HTTP/2 уже написан, стандарт 2015 года уже внедряется, но вот конкретно с TCP он работает не всегда хорошо, и неплохо бы под него подложить какой-нибудь другой транспорт, более подходящий для того, что когда-то называлось SPDY, когда пошли те разговоры, а потом и для HTTP/2.

Протокол решили назвать QUIC. QUIC — это ныне разрабатываемый протокол для транспорта. Он основан на UDP, то есть это датаграммный протокол. Первый черновик стандарта был выпущен в июле 2016 года, и текущая версия черновика…
[Докладчик проверяет почту на телефоне]
… да, всё ещё 12-я.
На данный момент QUIC еще не является стандартом — его активно пишут. Если я не ошибаюсь — я не стал писать на слайде, потому что боялся ошибиться –, но на IETF 101 в Лондоне говорилось, что где-то к ноябрю 2018 года планируется выпустить его уже как окончательный документ. Именно сам стандарт QUIC, потому что в рабочей группе документов еще восемь штук.

То есть стандарта еще нет, но уже идет активный хайп. Я перечислил только те конференции, где я был за последние полгода, где про QUIC была хотя бы одна презентация. О том, «какой он крутой», «как нам нужно на него переходить», «что делать операторам», «перестаньте фильтровать UDP — через него сейчас QUIC будет работать». Весь этот хайп длится уже достаточно давно — я уже видел много статей, которые призывали игровую индустрию переходить на QUIC вместо обычного UDP.

Ссылки со слайда:
1. conferences.sigcomm.org/imc/2017/papers/imc17-final39.pdf
2. blog.apnic.net/2018/01/29/measuring-quic-vs-tcp-mobile-desktop
В ноябре 2017 года в рассылке рабочей группы QUIC появляется вот такая ссылка: верхняя на whitepaper, а нижняя для тех, кому тяжело читать whitepaper — это ссылка на блог APNIC с кратким содержанием.
Исследователи решили сравнить производительность TCP и QUIC в текущем его виде. Для сравнения, чтобы не разбираться с тем, кто в чем виноват и где может быть вина Windows, со стороны клиента взяли Chrome под Ubuntu, а также взяли 2 мобильных устройства: какой-то Nexus и какой-то Samsung с Android 4 и 6 версий, соответственно, и в них тоже запустили Chrome.
Со стороны сервера они поставили Apache для того, чтобы видеть, как работает TCP-сервер, а для того, чтобы отслеживать QUIC, они выдрали кусок опенсорсного кода, который имеется в проекте Chromium. Результаты benchmark’ов показали, что, хотя во всех тепличных условиях QUIC действительно выигрывает у TCP, есть некоторые краеугольные кейсы, по которым он проигрывает.

Например, реализация QUIC от Google работает существенно хуже TCP, если в сети происходит packet reordering, то есть пакеты прилетают не в том порядке, в котором были отправлены сервером. В 2017–2018 годах, в век мобильных и беспроводных сетей, вообще нет никакой гарантии, что пакет в принципе долетит, не говоря уже о том, в каком порядке. QUIC отлично работает на проводной сети, но кто сейчас пользуется проводной сетью?

Вообще, разработчики этого кода в Google, видимо, очень не любят мобилки.
QUIC — это протокол, который реализован поверх UDP в user space. И на мобильных устройствах так же в user space. По результатам измерений, в нормальной ситуации, то есть при работе через беспроводную сеть, реализация протокола QUIC 58% времени проводит в Android в состоянии «Application Limited». Что это за состояние? Это состояние, когда мы какие-то данные отправили и ждем подтверждения. Для сравнения, на десктопах была цифра около 7%.
Всего 2 кейса использования: первый — беспроводная сеть, второй — мобильное устройство; и QUIC работает либо как TCP, либо существенно хуже. Естественно, это оказалось в рабочей группе IETF, посвященной QUIC и, естественно, на это отреагировал Google. Реакция Google была следующая:

mailarchive.ietf.org/arch/msg/quic/QktVML_qNDfqjIGirj4t5D0JRGE
Ну, мы посмеялись, но на самом деле это абсолютно логично.
Почему? Потому что дизайн QUIC — хотя мы говорим уже о внедрении в production, но — на самом деле дичайший эксперимент.
Вот, скажем, семиуровневая модель ISO/OSI. Кто ее помнит здесь? Помните уровни: физический, канальный, сетевой, транспортный, какая-то чушь, какой-то бред и прикладной, да?
Да, оно было разработано очень давно, и как-то мы жили с этой уровневой моделью. QUIC — это эксперимент по устранению самой по себе уровневой системы сети. Он объединяет в себе шифрование, транcпорт, надежную доставку данных. Все это не в уровневой структуре, а в комбайне, где каждый компонент имеет доступ к API других компонентов.

Цитируя одного из дизайнеров протокола QUIC Кристиана Гюитема: «Одно из главных преимуществ QUIC с архитектурной точки зрения — это отсутствие уровневой структуры». У нас есть и acknowledgement, и flow control, и шифрование, и вся криптография, — все это полностью в одном транспорте, и наши транспортные инновации подразумевают доступ всего этого напрямую к сетевому API, поэтому уровневую архитектуру в QUIC’е мы не хотим.

Разговор в рабочей группе об этом пошел из-за того, что в начале марта другой дизайнер протокола QUIC, а именно Эрик Рескорла, решил предложить на обсуждение вариант, в котором из QUIC убирается все шифрование, вообще. Остается только транспортная функция, которая работает поверх DTLS. DTLS, в свою очередь, — это TLS поверх UDP, в сумме получается: QUIC поверх TLS поверх UDP.
Откуда возникло такое предложение? Кстати, Рескорла написал большой документ, но вовсе не для того, чтобы это стало стандартом — это был предмет для обсуждения потому, что в процессе дизайна архитектуры QUIC, в процессе тестирования интероперабельности и реализации, возникло очень много проблем. В основном, связанных с «потоком 0». Что такое «поток 0» в QUIC?
Это такая же идея, как из HTTP/2: у нас есть одно соединение, внутри него у нас есть несколько мультиплексируемых потоков. По дизайну QUIC, напоминаю, что шифрование обеспечивается тем же протоколом, сделано это было следующим образом: открывается поток №0, магический поток №0, который отвечает за установку соединения, рукопожатия и шифрования, после чего этот поток 0 шифруется и все остальные шифруются тоже. С этим возникло достаточно много проблем, они перечислены в списке рассылки, там 10 пунктов, я не буду останавливаться, выделю только один, который мне очень нравится.

www.ietf.org/mail-archive/web/quic/current/msg03498.html
Проблема, связанная с потоком 0, одна из, состоит в том, что в случае, если у нас идет потеря пакета, нам нужно их перепосылать, а значит на стороне сервера, например, соединение уже будет отмечено, как шифрованное, а пакет потерян, но нам нужно их перепосылать все-равно… имплементация может случайно шифровать пакеты.

И еще раз: СЛУЧАЙНО ШИФРОВАТЬ ПАКЕТЫ.
Это довольно сложно прокомментировать, кроме того, чтобы рассказать, как это все на самом деле дизайнится. В разработке QUIC фактически используется эрзац agile-подход — это не то, чтобы кто-то написал железобетонный стандарт, который пара итераций — выпустил, нет.

Работа происходит следующим образом:
1. Запускается черновик стандарта №5,
2. В списках рассылки на IETF-встречах — 3 в год — проходит обсуждение, потом на хакатонах проходит реализация, interop testing, собирается обратная связь.
3. Google внедряет какие-то из изменений в Chrome, в собственной инфраструктуре, анализирует последствия и далее счетчик инкрементируется и появляется стандарт 6.
Сейчас, напоминаю, 12 версия.
Что здесь важно?
Во-первых, минусы мы только что увидели, но есть и плюсы. В этом процессе, на самом деле, можно участвовать. Feedback собирается со всех вовлеченных сторон: если у вас друг геймер, если вы думаете, что вы в игровой индустрии можете взять и поменять UDP, поставить QUIC, и все будет работать — нет, не будет. Но на данный момент вы можете на это повлиять, с этим можно как-то работать.

И это, на самом деле, общая такая история. Feedback от вас ожидается, т.е. все хотят его видеть. Что более важно — Google разрабатывает протокол, в него какие-то идеи вкладывает для своих целей. Компании, которые занимаются другими вещами, если это не совсем типичные веб, гейминг или мобильные приложения, SEO то же самое. Компании, которые этим занимаются, они не могут по умолчанию рассчитывать, что протокол будет учитывать их интересы не только потому, что это никого не интересует, а потому, что никто просто не знает про эти интересы. Это просто явка с повинной.
Это опять вопрос ко мне, почему мы, как Qrator Labs, не участвовали в разработке протокола HTTP/2 и не сказали никому про реверс прокси, но Cloudflare и Nginx тоже там не участвовали. Пока в этом не участвует индустрия, разработкой занимаются Google, Facebook, какие-то еще компании и академики. В около-IETF’ной тусовке слово «академик» — оно не похвальное. Оно звучит как шизофреник и ипохондрик, «он из академии». Люди часто приходят без каких-либо задач, без понимания практических задач, но вписываются туда, потому что так проще на PhD наработать. В этом, конечно, нужно участвовать и вариантов других нет.

Возвращаясь к QUIC: итак, протокол реализован в user space, на мобильных устройствах существует… «Реализован в user space» — давайте поговорим об этом. Как у нас вообще был устроен транспорт до того, как начали придумывать QUIC. Как он устроен сейчас в продакшене. Есть протокол TCP, если мы говорим про веб.
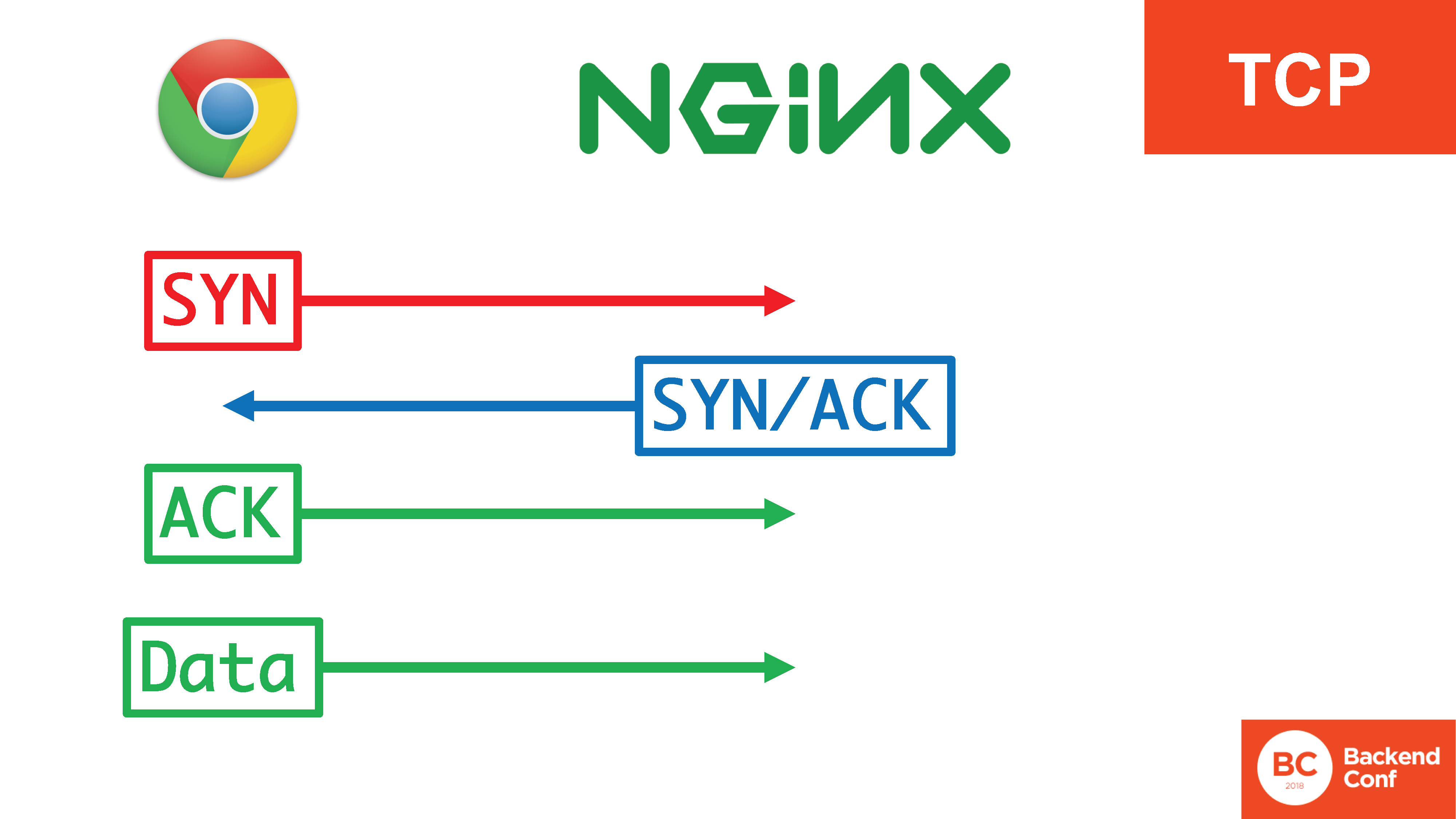
В протоколе TCP есть такая штука, как тройное рукопожатие: SYN, SYN/ACK, ACK. Она нужна для целого ряда вещей: чтобы не позволять использовать сервер для атак на других, чтобы успешнее фильтровать определенные атаки на проток TCP, такие как SYN flood. В протоколе есть тройное рукопожатие. Только после того, как 3 сегмента тройного рукопожатия прошли, у нас начинается посылка данных.
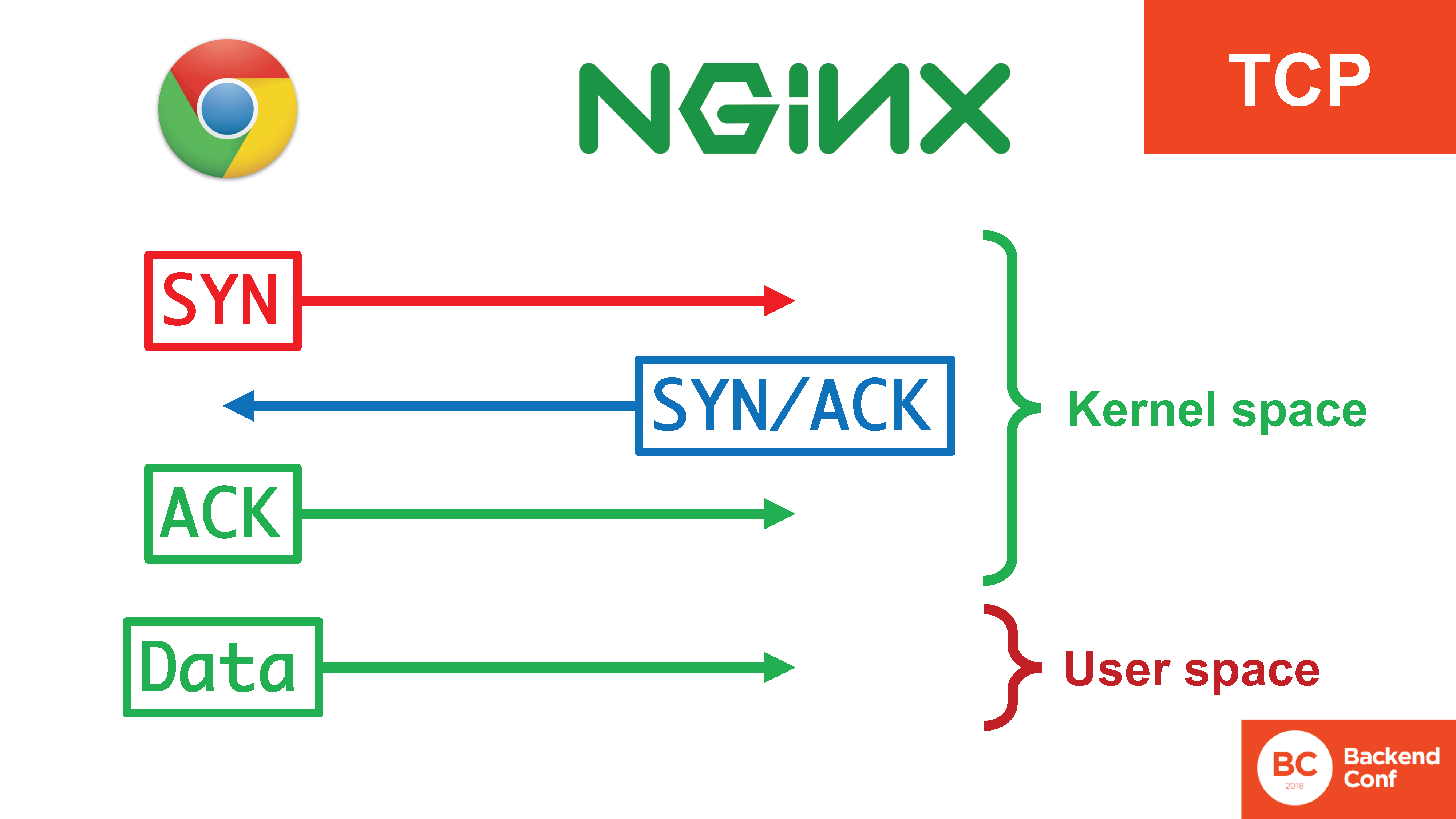
При этом тут 4 действия, 3 из которых происходят в ядре, происходят они достаточно эффективно, а в user space попадают уже данные, когда соединение установлено.
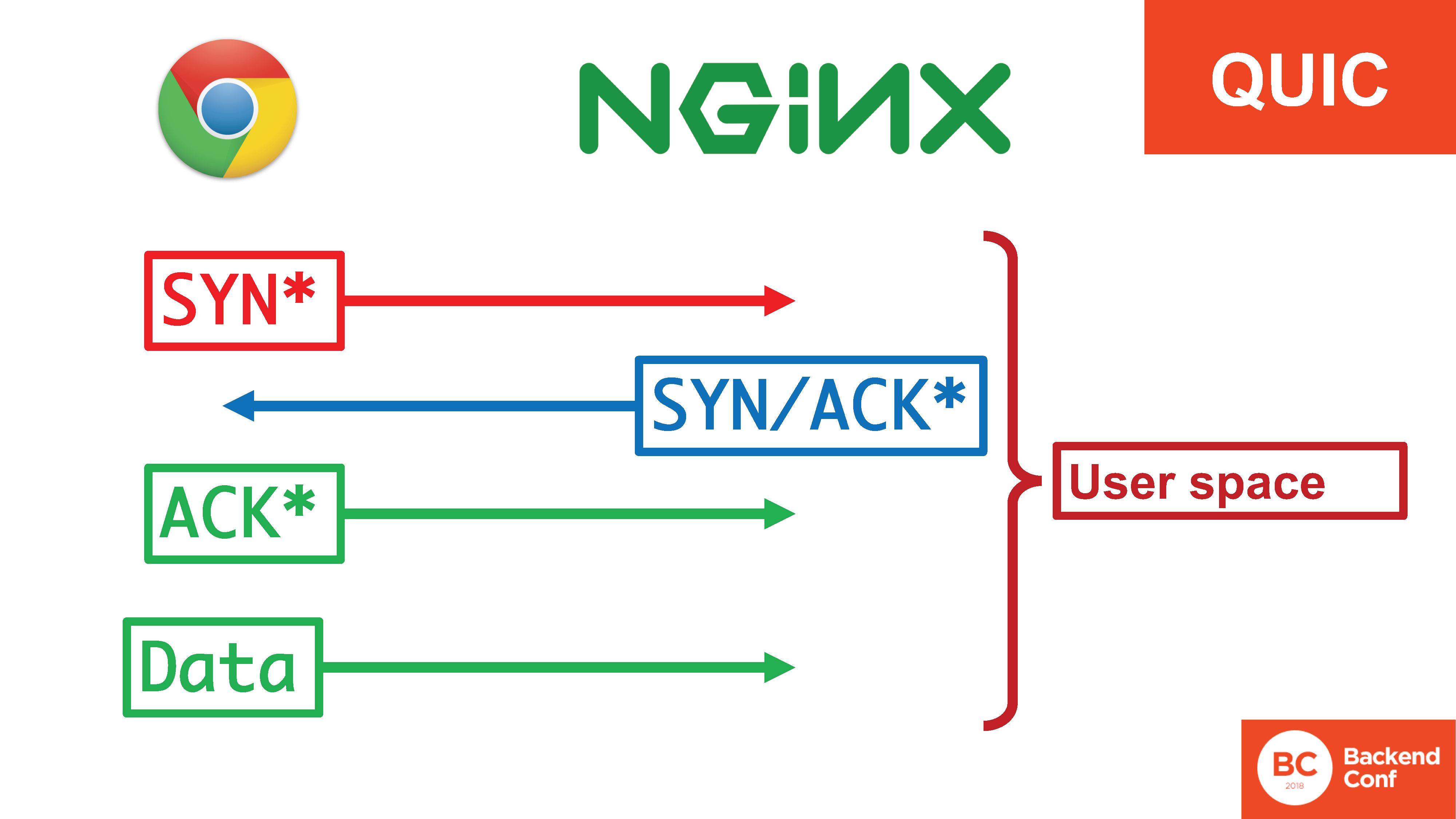
В ситуации с QUIC всё это счастье в юзерспейсе. Тут звездочка стоит, потому что там терминология не совсем SYN, SYN/ACK, но, по сути, это тот же самый хендшейк, только переехавший полностью в user space. Если летит 20 Гбит/с флуда и раньше в TCP их можно было обработать в ядре SYN-куками, то теперь их нужно обрабатывать в user space, т.е. они пролетают все ядро и через вcе контекст свичи их нужно так как-то поддерживать.
Почему сделано так? Почему QUIC это протокол user space’овый? Хотя транспортный, казалось бы, самое место ему где-то на системном уровне.

Потому что, опять же, это интерес Google и других участников рабочей группы. Они хотят видеть новый протокол внедренным — они не хотят ждать, когда все операционные системы в округе обновятся. Если он реализован в user space, его можно использовать уже сейчас. То, что нужно будет потратить очень много ресурсов на стороне сервера для Google не проблема. Где-то было хорошее высказывание о том, что для решения большинства проблем с производительностью на бэкенде современного интернета, нужно у Google просто половину серверов конфисковать (лучше ¾). Что не лишено какого-то здравого смысла, потому что Google, действительно, на такие мелочи не разменивается.

www.ietf.org/mail-archive/web/quic/current/msg03736.html
На экране буквальная цитата из рассылки QUIC, где проходило обсуждение как раз о том, что протокол планируется к реализации в user space. Это буквальная цитата: «Мы хотим деплоить QUIC на любую машину без поддержки операционной системы. Если у кого будут проблемы с производительностью, то они унесут это все в ядро». QUIC уже настолько развесистый, что уносить это в ядро с шифрованием, со всем остальным уже страшновато, но рабочая группа на эту тему тоже особо не запаривается.

Причем как этот подход используется на стороне клиента я могу понять. Тот же подход используется на стороне сервера. Теоретически, в этом случае QUIC действительно стоило бы уносить в ядро, но, опять же, работа над этим не ведется, а когда она будет закончена, мы уже все седыми будем, потому что я не планирую жить вечно. И когда это произойдет не очень понятно.
Говоря про ядро Linux, нельзя не упомянуть, что одним из главных смыслов существования QUIC было то, что он реализован поверх легковесного протокола UDP, и благодаря этому работает более эффективно, более быстро и тогда вообще зачем нам TCP, когда он такой большой и громоздкий.

vger.kernel.org/netconf2017_files/rx_hardening_and_udp_gso.pdf
Тут представлена другая ссылка на бенчмарк. Выясняется, что отправка UDP датаграмм в Linux дороже, чем отправка TCP-потока, причем существенно дороже, заметно дороже. Там есть 2 главных момента, то есть много моментов, но только два главных момента:
1. Lookup по таблице маршрутизации занимает больше времени в случае UDP-датаграммы.
2. Штука под названием «large segment offload».
В TCP мы поток можем сгрузить — мы не обязаны его сегментировать по сегментам на CPU, в то время как в UDP у нас только датаграмма, у нас нет потока. В данный момент разработчики ядра думают, что с этим делать, но, по большому счету, на данный момент, TCP работает на посылке больших данных, не влезающих в один пакет, эффективнее, чем UDP, на котором основан QUIC.

www.ietf.org/mail-archive/web/quic/current/msg03720.html
Вот это опять же цитата сотрудника Google, я, в частности, тоже задавал ему этот вопрос. Ответом было, что мы можем просто винить Linux, говорить, что под Windows, наверное, не так все плохо, но нет. Утверждается, что на любой платформе, на которой Google деплоил QUIC, есть проблема с повышенной стоимостью, с точки зрения центрального процессора, отправки UDP-пакета против TCP-потока. То есть это не просто Linux, а это общий подход.

Что приводит нас к одной простой мысли: хватит говорить про QUIC, достаточно растоптали его, хватит. Простая идея, которую нужно отсюда вынести — это то, что перед внедрением любого нового протокола вместо старого: HTTP/2 против HTTP/1.1, QUIC вместо TCP, шифрование DNS, IPv6 вместо IPv4… первое, что нужно сделать, перед принятием решения и выкладкой на продакшен — это, естественно, бенчмаркинг.
Не верьте никому, кто говорит, что протокол «можно просто поменять/включил/нажал кнопку» — нет! Никогда такого не будет и не было никогда, и не будет в будущем и никто такое не гарантирует.
Поэтому только бенчмарк, и, естественно, что если вы этого не сделаете, вы развернете его, то, конечно, гарантию вам никто не предоставит.

Кстати, про IPv6. Дело в том, что во времена IPv6, когда он разрабатывался, протоколы разрабатывались как-то более прямолинейно, т.е. без agile-технологий, но их адаптация в интернете все-равно заняла очень большое существенное время. И, на данный момент, все еще продолжается, и все еще висит на уровне 10–20% в случае IPv6. Причем в зависимости от страны, потому что в России еще ниже. На пути внедрения IPv6 было решено очень много проблем.
Кто знает, что такое Happy Eyeballs? Happy Eyeballs — это протокол, тоже являющийся стандартом, выпущенным IETF, хотя не протокол (хорошо) — подход, который заключается в том, что было очень много проблем, связанных с IPv6, да таких когда жаловались пользователи.
Ты берешь, закрываешь ноутбук, выходишь из дома, где у тебя есть IPv6, приходишь в кафе, открываешь — IPv6 там нет и ничего не работает, потому что кэши браузера и операционной системы — все это продолжает смотреть в IPv6, а локальной связности там нет. Был придуман подход, под названием «Happy Eyeballs» — если в течении 3/10 секунды мы не нашли IPv6 соединения, не смогли соединиться, мы откатываемся на IPv4.
Костыль, но работает, вроде бы, почти всегда, но! Постоянно возникают мистические проблемы с реализацией. В частности, одна из самых популярных проблем почему-то была почему-то с iPad, которые из IPv6 в IPv4 и обратно переключались существенно медленнее, чем за 0.3 секунды: около 1 секунды — 1 минуты.
Даже в какой-то момент было безумное предложение на 99 IETF в Праге: «а давайте Happy Eyeballs будет в каждой сети по syslog’у на централизованный сервер, если проблемы — что-нибудь отправлять». Собирать syslog со всех подключенных устройств — никто, конечно, на это не согласился. Просто это показатель того, что проблем достаточно много. Другие проблемы связаны, это борьба со всякими злонамеренными активностями, потому что локальная сеть в IPv6 — это /64 и очень много адресов, которые атакующий может начать перебирать, их нужно вовремя агрегировать и все такое. Этим нужно как-то занимать, это все должно быть реализовано.
В результате, мы все равно получили проблемы с внедрением, которые не только выражаются в том, что кто-то IPv6 медленно внедряет — нет; его начали отключать обратно. Обратно переходить в IPv4. Потому что и без проблем тяжело было обосновать менеджменту преимущества перехода, но еще и когда включили, то пользователи начали на это жаловаться — сразу все, нет. Это такой пример, когда даже протокол, который разработан был с видом на внедрение, все-равно вызывает дичайшие проблемы с внедрением, которые выражаются в головомойке техническому департаменту. Представьте, что произойдет при внедрении протоколов, которые не были рассчитаны на широкомасштабное внедрение.
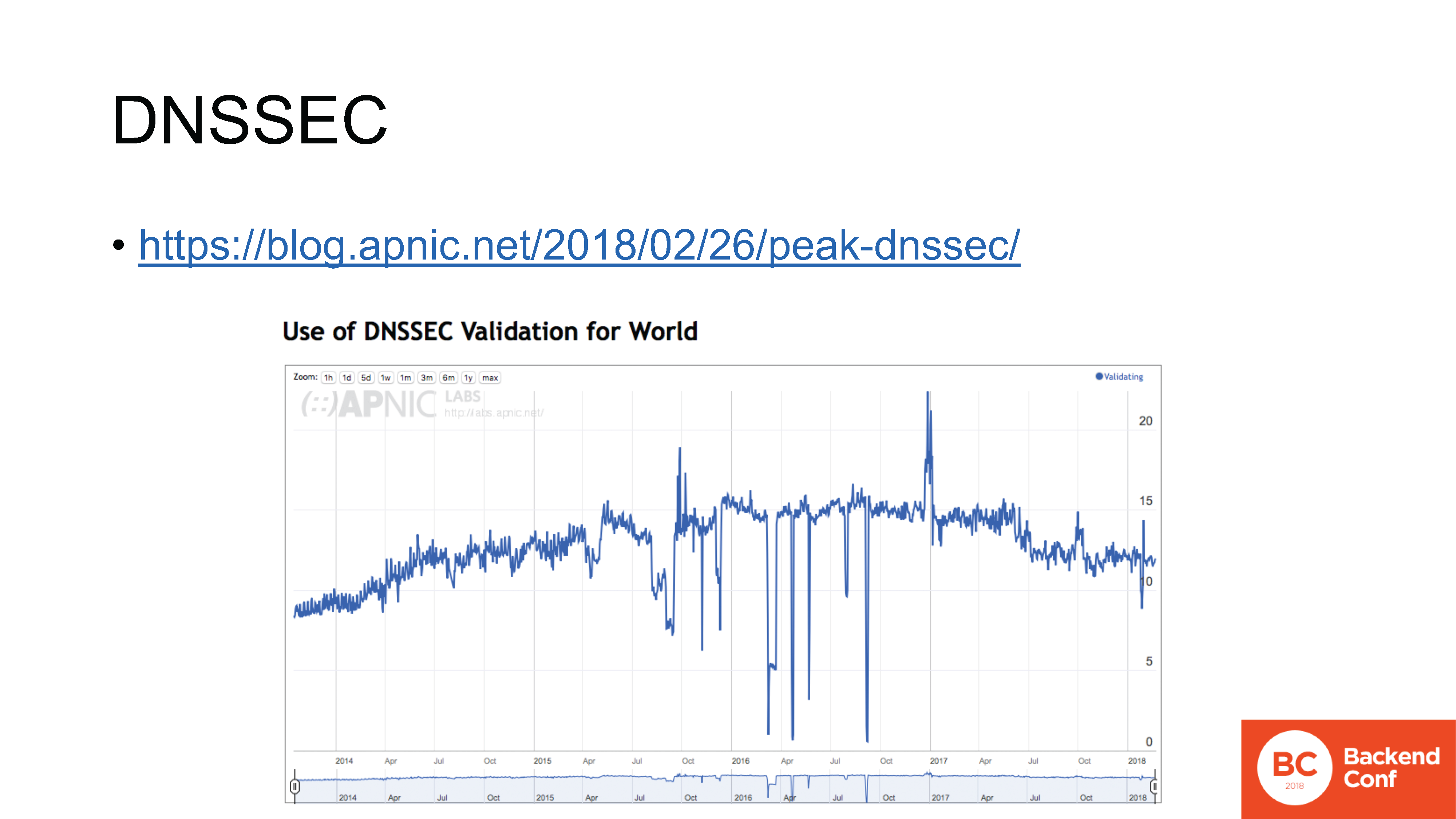
blog.apnic.net/2018/02/26/peak-dnssec
Другой пример на эту тему — DNSSEC. Я не буду просить вас поднять руки, чтобы узнать, у кого оно есть, потому что знаю, что ни у кого нет.
Принятие IPv6 с одной стороны растет, с другой стороны с ним есть проблемы, но оно хотя бы идет. Начиная с конца прошлого года внедрение DNSSEC в мире замедлилось и пошел в обратном направлении…
На этом графике мы видим ежедневное количество интернет-пользователей по замерам Apnic Labs, использующих резолверы, которые валидирует DNSSEC. Здесь очень четко виден медвежий тренд: вот он стартует после последнего пика и этот пик — октябрь 2016 г.
У DNSSEC есть цель, есть правильные задачи, но его развертывание фактически остановилось и пошел какой-то обратный процесс, который еще предстоит расследовать, откуда он взялся.

datatracker.ietf.org/meeting/101/materials/slides-101-dnsop-sessa-the-dns-camel-01
Вообще с DNS очень много проблем. В рабочей группе IETF DNSop сейчас 3 председателя, 15 черновиков «в полете» — они готовятся к выходу как стандарты. DNS, в частности, научились передавать поверх всего, поверх TCP он работал давно, но еще нужно людям показать, как это правильно делать. Его начали пускать поверх TLS, поверх HTTPS, поверх QUIC.
Все это выглядело совершенно замечательно, пока люди не начали это реализовывать, и у них не начало болеть в пятой точке. Опять же, в марте 2017 г., тут есть ссылка, разработчики Open DNS привезли презентацию, под названием «DNS Camel» или «верблюд DNS».
Насколько еще мы можем нагрузить этого верблюда, прежде чем очередная хворостинка сломает ему хребет? Это общий подход к тому, как мы видим сейчас дизайн, т.е. фичи добавляются, фич очень много, они друг с другом интерферируют по-разному. И не всегда предсказуемым образом, и не всегда авторы реализации понимают все возможные точки интерференции. Внедрение каждой такой новой фичи, реализация, внедрение в продакшен — это еще набор точек отказа в каждом месте, где происходит такая интерференция. Без бенчмарка, без мониторинга — никуда.
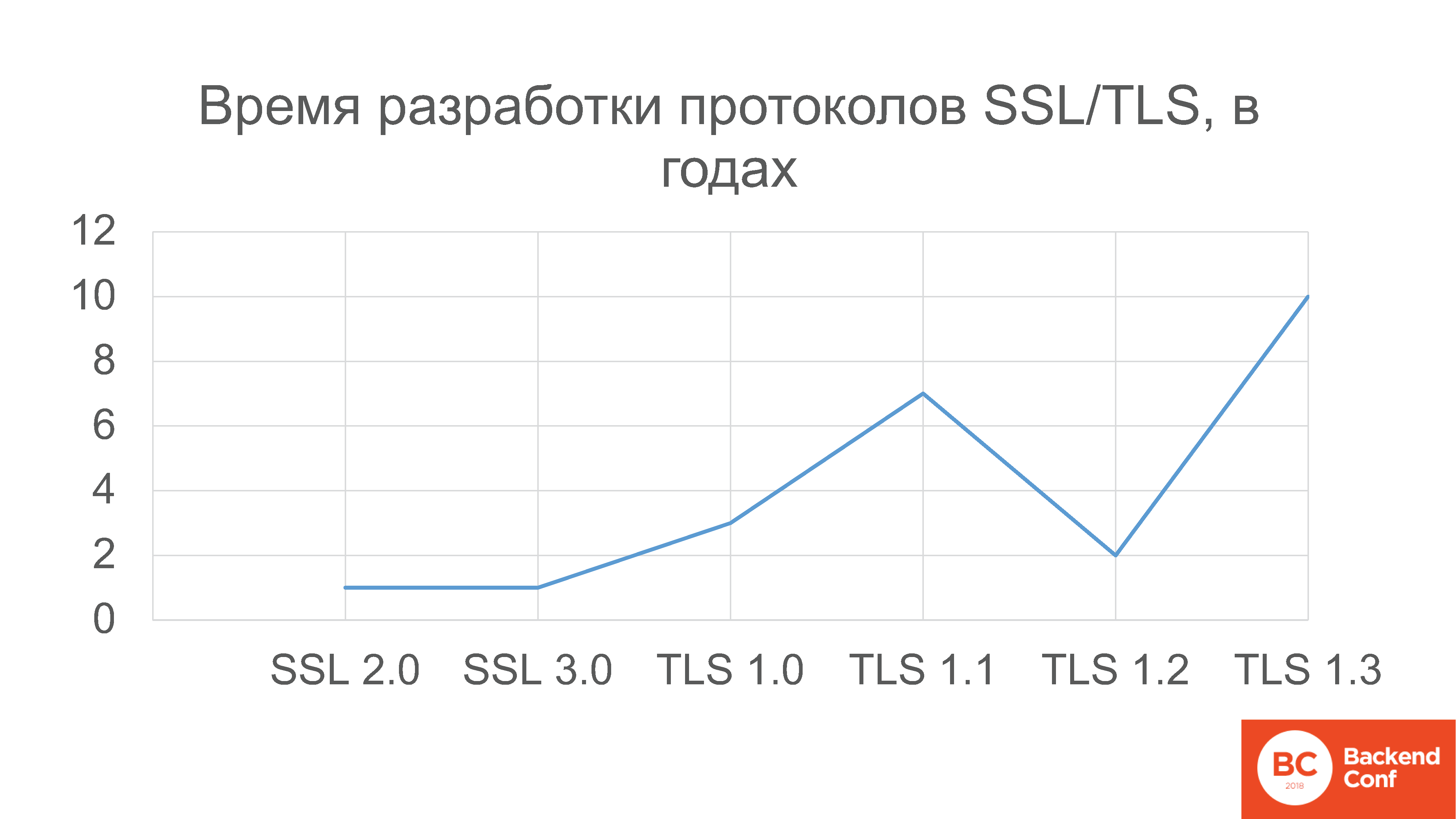
Почему важно участвовать во всем этом процессе? Потому что стандарт IETF — «RFC» — это все-таки стандарт. Есть вот такая хорошая статистика — это сроки разработки различных версий протоколов шифрования SSl и TLS.
Обратите внимание, что версионирование SSL начинается с номера 2, потому что там версии 0.9 и 1.0 — никогда не были выпущены в production, они были более дырявыми, чем Netscape мог позволить себе выпустить. Поэтому история началась с протокола SSL 2.0, который разрабатывался год, потом SSL 3.0 разрабатывался один год.
Потом TLS 1.0 разрабатывался 3 года, версия 1.1 — 7 лет, 1.2 разрабатывался 2 года, потому что там не такие большие изменения были, но последняя версия была выпущена в марте этого года — 27-й черновик, кстати — разрабатывалась 10 лет.
В соответствующей рабочей группе в определенный момент на эту тему была большая паника, потому что выяснилось, что TLS 1.3 ломает очень много юзкейсов, в частности, в финансовых организациях, с их мониторингом, файрволлами. Но изменить это, придя к осознанию уже на стадии восемнадцатого черновика не смогли даже такие крупные компании, как United States Bank. Они ничего не успели с этим сделать, потому что, когда ты приходишь на вечеринку в момент, когда всем уже раздают счет, ты не можешь ожидать, что к отсутствию у тебя денег отнесутся с пониманием. Поэтому, если в каком-то протоколе — это опять вопрос к обратной связи — есть/будут/появляются фичи, которые вам не подходят, единственным вариантом является вовремя это отследить и вовремя в это вмешаться, потому что в противном случае оно так и будет выпущено, и придется строить костыли вокруг этого.

Это (на слайде), собственно, и есть 3 вывода из всего этого процесса. Первый, как я говорил, — внедрение нового протокола это не просто в конфигурации «что-то подкрутить», это расписанный план внедрения, оценка целесообразности с обязательными бенчмарками, как в реальности это все себя поведет. Пункт номер два: протоколы не инопланетянами разрабатываются, они не даны нам свыше, в этом процессе можно и нужно участвовать, потому что за вас никто ваши юзкейсы продвигать не будет. И третье, действительно, фидбэк нужен, но самое главное, что …. Google не злой, он просто преследует свои собственные цели, у него нет задачи разрабатывать протокол для вас и за вас, это можете сделать только вы.
Поэтому, в общем случае, внедрение чего-то нового взамен чего-то старого, несмотря на количество хвалебных статей в блогах, начинается с того, что необходимо внедрится не просто в деплоймент, а в процесс дизайна протокола — посмотреть, как оно работает, только после этого принимать взвешенное решение.
Спасибо!
