Python в атомной энергетике: сообразительные нейроморфы, предсказание поломок и анализ нормативки
Атомная энергетика — отрасль наукоёмкая. Python со своими инструментами для анализа данных и построения ИИ как раз подходит АЭС, здесь с ним можно решать амбициозные задачи на острие науки о данных. Поэтому Хабр решил разузнать побольше про Python в Росатоме. И попросил меня помочь.
Меня зовут Тимур Тукаев, я IT-редактор. Начал писать о технологиях в 2007, когда поставил свой первый Linux. Увлечён идеями свободного ПО и open source, программирую на Kotlin, делаю о нём топики в JetBrains Academy.
Я пообщался с тремя инженерами Росатома и выяснил, для чего в корпорации используют Python.
Для начала кратко представлю ребят. Все они решают в Росатоме задачи, связанные с Python.
 Денис Ларионов
Денис ЛарионовНачальник отдела искусственного интеллекта компании «Цифрум» (Росатом). Руководит перспективным направлением по созданию нейроморфной системы искусственного интеллекта. Популяризатор науки, автор научно-исследовательских работ, наставник профессиональных конкурсов, соревнований, хакатонов в области IT.
 Дмитрий Распопов
Дмитрий Распопов Эксперт отдела искусственного интеллекта компании «Цифрум» (Росатом), старший преподаватель отделения ядерной физики и технологий в НИЯУ «МИФИ». Занимается предиктивной аналитикой и исследованиями в области искусственного интеллекта, принимает участие в профессиональных чемпионатах. Заместитель менеджера компетенции «Машинное обучение и большие данные» по отраслевой линейке чемпионатов DigitalSkills, серебряный призёр на 45-м мировом чемпионате по профессиональному мастерству по стандартам WorldSkills (Казань, 2019 г.), бронзовый призёр на чемпионате стран БРИКС по профессиональному мастерству Belt & Road and BRICS Skills Development and Technology Innovation Competition (Фошань, КНР, 2019 г.).
 Андрей Буйновский
Андрей Буйновский Инженер группы подготовки данных компании «Цифрум» (Росатом). Занимается обработкой текстов на естественном языке (natural language processing, NLP). Призёр IT-чемпионатов.
Сначала мы поговорим о «Цифруме» и их работе с нейроморфами — здесь Python помогает создавать новый тип нейросетей.
Дальше побеседуем о своевременном ремонте оборудования с помощью предиктивной модели, построенной тоже на Python.
И наконец, посмотрим, как Python и его библиотеки классифицируют запутанные ГОСТы и нормативы, по которым строятся и работают АЭС.
Ребята не только со мной поговорили, но ещё и поделились классными ссылками по своим темам — их можно найти в конце статьи.
Задача 1. Как Росатом с помощью Python и нейроморфов учит датчики работать без сервера, а роботов — быстро принимать решения
Классические ИИ-решения даже сейчас создаются на основе архитектуры фон Неймана. С нервной системой человека они имеют мало общего. Нейронные сети не работают как биологический мозг. Разрыв в эффективности вычислений колоссальный: грубо говоря, самый мощный компьютер распознаёт на фотографии кошку на три порядка хуже, чем средний человеческий мозг. Разрыв в производительности есть всегда, хоть и зависит от типа задачи.
Подробнее о сравнительных характеристиках классических нейросетей и нейроморфов — с графиками, методологией и более научным языком — можно прочитать в статье на английском (прямая ссылка на pdf) или на русском (чтобы скачать альманах, надо заполнить форму).
Чем нейроморфные вычисления отличаются от классического ИИ
Сократить или даже устранить разрыв могут нейроморфные сети. Нейроморфная инженерия предлагает использовать данные, известные нам о структуре и работе мозга, в создании вычислительных систем. Давайте сравним нейроморфный подход с фон-неймановской архитектурой. Вот обычный компьютер складывает два числа:
Берёт из памяти число и помещает в регистр процессора.
Берёт из памяти второе число и помещает в регистр процессора.
Выполняет операцию.
Берёт результат вычисления из третьего регистра процессора и помещает в память.
Главная отличительная черта биологических систем в том, что, в отличие от фон-неймановской архитектуры, вычисления и память не разделены шиной данных. Память как бы размазана по весам связей между нейронами (in-memory computing). Вычисления происходят непрерывно, когда нейроны получают сигнал на вход и генерируют выходной сигнал.
Существует и близкий к биологическому подход near-memory computing, когда вычисления и память разделены, но в памяти размечаются элементарные вычислители. Благодаря этому часть вычислений можно переложить на память.
В Росатоме с 2020 года нейроморфами занимается компания «Цифрум»: за направление отвечает небольшая команда из трёх человек.
Принцип Росатома — быть на шаг впереди, получать прикладные результаты от перспективных технологий — энергоэффективных вычислений на конечных устройствах, которые труднодостижимы в классических решениях искусственного интеллекта. Например, вычисления на новых физических принципах и киборгизация.
Денис Ларионов
Для чего нейроморфы Росатому
«Цифрум» работает с нейроморфами по трём направлениям:
Всё, что связано с обучением и интеллектуальными задачами непосредственно на самом устройстве. Например, умные сенсоры и датчики, которые могут работать без привязки к серверу. Носимые сенсоры, способные определять токсичность воздуха, энергоэффективное зрение для БПЛА и систем слежения, умные камеры и коммуникационные устройства, которые минимизируют потоки данных, визуальная вибродиагностика, а в перспективе — ещё и чипы без батарейки для интеграции в нервную систему человека.
На современном железе мы столкнёмся с проблемой: энергоэффективный датчик надо лишить мозгов — он будет просто посылать данные на сервер. А умному нужна большая батарейка, чтобы сохранить скорость вычислений и возможность интеллектуальных действий. Нейроморфы решают проблему: даже со слабенькой батарейкой могут делать сложные вычисления.
Например, исследователи из китайского проекта Tianjic создали систему управления движением велосипеда, которая способна видеть, слышать, планировать маршрут, балансировать — и всё это на одном чипе со скоростью 1 278 MACGOPS (giga MAC operations per second) на один ватт.
Системы, где требуется быстрое принятие решений. Самый распространённый кейс — робототехника, где надо регулировать множество параметров в реальном времени, чтобы всё оставалось под контролем, а процесс был предсказуем.
Создание практически бесконечно масштабируемых нейросетей. В классической ИИ-системе при увеличении размера сети (то есть количества нейронов) резко растёт потребность в аппаратных ресурсах. С нейроморфными системами такой проблемы нет: рост ресурсов более линейный за счёт полностью асинхронной модели вычислений и отсутствия ограничений, обусловленных законом Амдала. Снимается ограничение на количество нейронов: в классическом варианте выше сотни миллиардов не осилишь, здесь может быть и в тысячу раз больше.
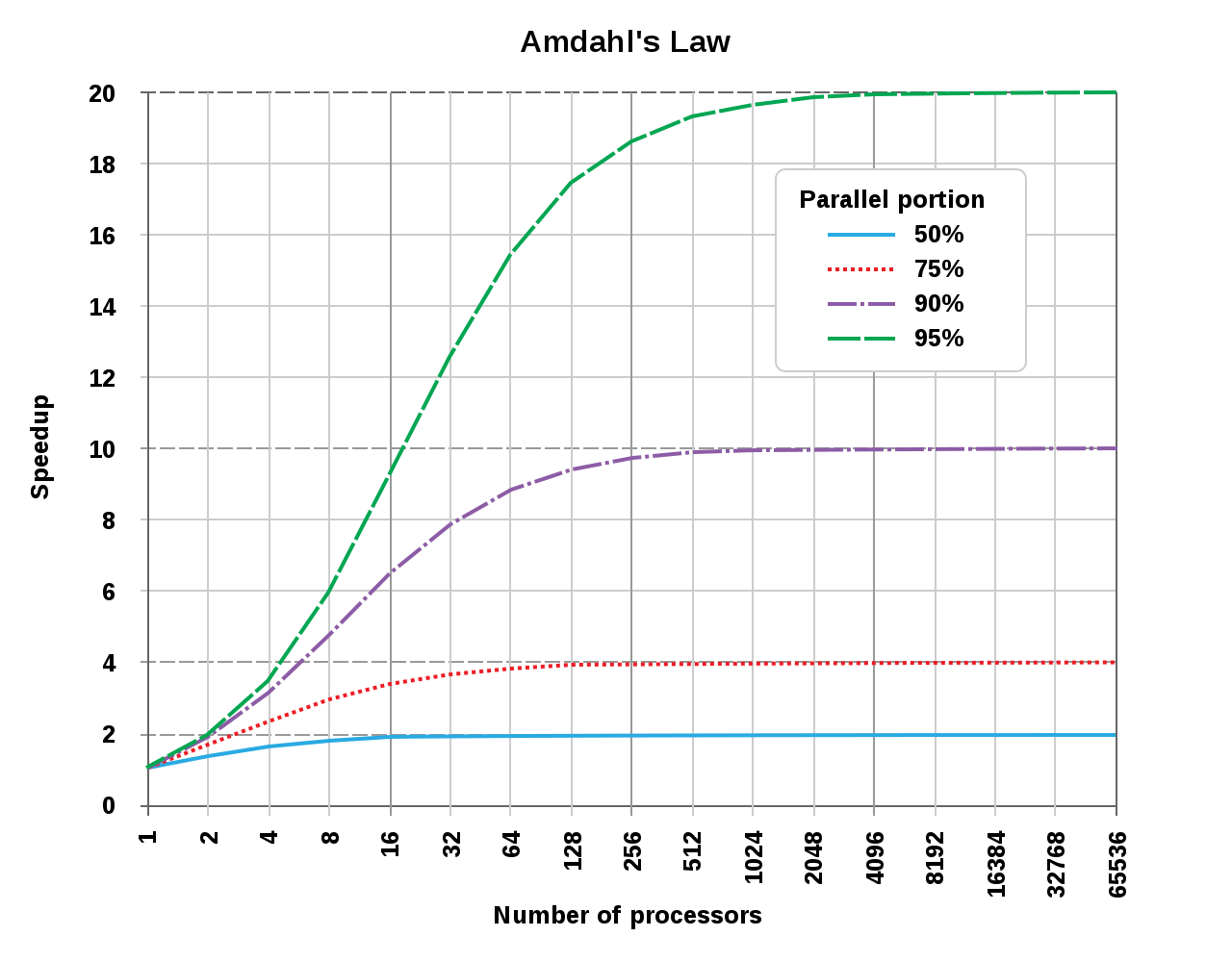 График, который иллюстрирует закон Амдала. Источник: Википедия
График, который иллюстрирует закон Амдала. Источник: Википедия
Мы в «Цифруме» исследуем алгоритмы обучения импульсных сетей на C++ и Python. Если всё получится, будем создавать свой микропроцессор на собственной, не-фон-неймановской архитектуре.
Денис Ларионов
Стек и необходимые знания
Иногда код приходится писать на C++, напрямую взаимодействовать с CUDA, реализовывать свои вычислительные примитивы, но чаще мы работаем на более высоком уровне абстракции, и тогда уже отличным инструментом является Python.
Если мы экспериментируем с небольшой сетью (несколько сотен импульсных нейронов), то удобство и скорость разработки на Python оказываются важнее эффективности вычислений и скорости работы, которые может дать С++. Кроме того, в экосистеме Python много полезных библиотек и фреймворков.
Например, мы используем фреймворк Brian 2 — проводим вычисления на самом высоком уровне абстракции. Brian 2 может понимать дифференциальные уравнения, написанные в виде строки в специальной нотации. Это позволяет описать практически любую динамику системы, однако плата за такую гибкость — низкая производительность.
В общем, выбирая фреймворк для моделирования импульсных нейронных сетей, мы всегда ищем компромисс между возможностями, ограничениями и удобством использования.
У нас есть и свои интересные открытые разработки. На Kaggle выложена работа о том, как с помощью импульсных сетей решить задачу распознавания рукописных цифр. Код можно запустить, поиграться с ним, изучить.
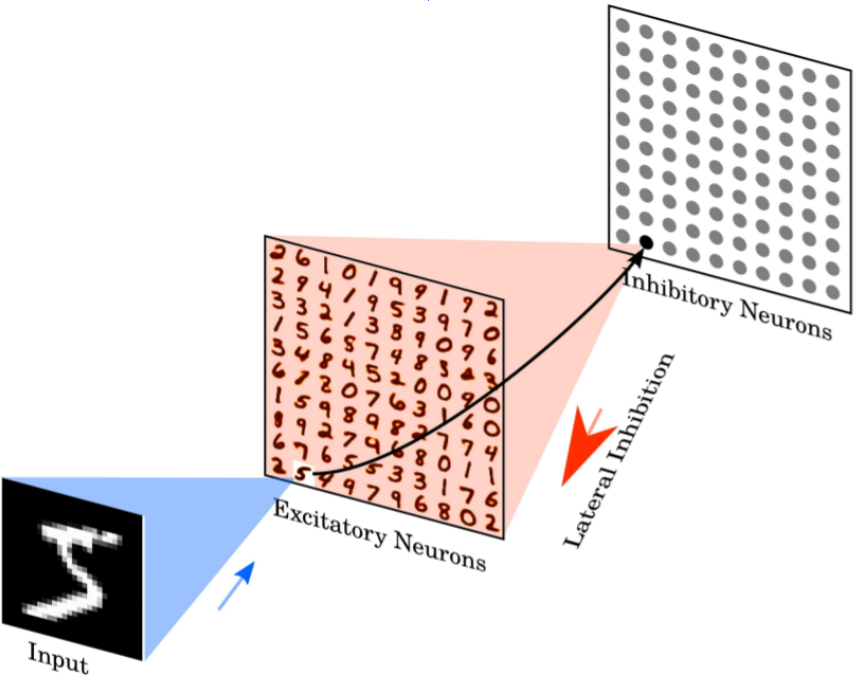 Схема того, как решается задача распознавания рукописных чисел. Источник: https://www.kaggle.com/code/dlarionov/mnist-spiking-neural-network
Схема того, как решается задача распознавания рукописных чисел. Источник: https://www.kaggle.com/code/dlarionov/mnist-spiking-neural-network
Ещё мы построили такую модель: есть система с прямоугольной рамкой и случайно перемещающимся там шариком. Задача системы — настраивать рамку так, чтобы шарик всё время оказывался в самом центре. Мы эту задачу решили с помощью нейроморфов, а для этого пришлось написать эмулятор событийного сенсора: он выложен в открытом доступе на GitHub.
Денис Ларионов
Есть и критичные знания для работы в команде, которые диктуются спецификой нейроморфных систем:
Биология. Нужно понимать биологов, уметь задавать им вопросы. Достаточный фундамент даст курс Synapses, Neurons and Brains от Иерусалимского университета.
Работа современных вычислительных систем, проектирование цифровых микросхем. Важна эрудиция в железе. Надо понимать, как устроены современные вычислительные архитектуры CPU, GPU. Какие у них есть проблемы, как эти проблемы решать. В идеале — способность спроектировать цифровую схему, эмулировать на ней алгоритм.
Математика: машинное обучение и смежные дисциплины. Важно понимать, как работают классические нейронки, их подходы и проблемы. Видеть, когда нейроморфы уместны, а когда лучше построить гибридное решение или даже классическую сеть.
Задача 2. Как Python помогает предсказывать циклы ремонта оборудования атомных электростанций
Оборудование на АЭС — дорогое, бесперебойная работа критически важна. Конечно, техника требует ремонта. Что если научиться заранее определять, где и когда он нужен? Тогда можно прогнозировать остаточный ресурс, увеличить межремонтные интервалы, снизить количество внеплановых остановок.
Мы решили написать модель предиктивной аналитики, основанной на временных рядах, и с ней предсказывать появление аномалий в работе оборудования.
Временной ряд — исторические данные по набору параметров процесса. Каждая единица такого набора называется измерением или отсчётом. У каждого отсчёта указывается время или порядковый номер измерения. В отличие от выборки он учитывает взаимосвязь изменения параметров и состояния процесса во времени.
Дмитрий Распопов
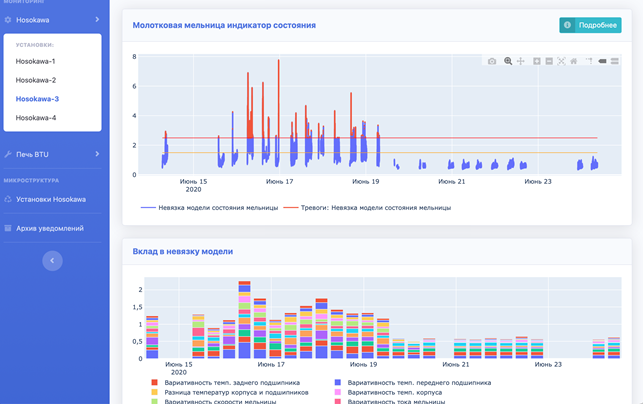 Иллюстрация работы моделей. Индикатор технического состояния вверху смотрит на различие параметров во время нормального и аномального режимов работы оборудования. Внизу показаны параметры, которые оказывают наибольшее влияние на модель. Фото: Росатом.
Иллюстрация работы моделей. Индикатор технического состояния вверху смотрит на различие параметров во время нормального и аномального режимов работы оборудования. Внизу показаны параметры, которые оказывают наибольшее влияние на модель. Фото: Росатом.
Система предиктивной аналитики выстраивается для конкретного предприятия — она не универсальна, ведь набор оборудования и условия эксплуатации могут сильно отличаться. Например, мы уже успели поработать с грануляторами Hosokawa, турбогенераторами, электролизерами, конвекционными линейными печами BTU, ГЦНА (главные циркуляционные насосные агрегаты). Однако несмотря на специфичность, саму модель, которая анализирует состояние оборудования, можно переиспользовать: достаточно её заново откалибровать, настроить и дообучить на конкретных установках.
Этапы разработки модели предиктивной аналитики
Шаг 1. Накапливаем исторические данные с датчиков
На каждой АЭС есть автоматизированная система управления технологическим процессом (АСУ ТП). Она собирает и хранит данные с датчиков. Температура, давление, ток, напряжение, мощность, активная/реактивная вибрация, скорость вращения и так далее. Их и берёт команда разработки.
Бывает, что на предприятиях централизованно собирается недостаточно данных для аналитики, нет единой системы сбора и хранения данных — тогда мы такую систему выстраиваем и внедряем сбор всех необходимых показаний. То есть параллельно решаем и инфраструктурные задачи для отдельных предприятий.
Дмитрий Распопов
Шаг 2. Накапливаем и обрабатываем данные из журналов технического обслуживания и ремонта (ТОиР)
В журналы ТОиР заносятся сведения о состоянии оборудования за время эксплуатации: они помогают понять, какие бывают поломки, насколько они серьёзны, когда, с какой периодичностью могут произойти. После этого команда предиктивной аналитики выявляет самые важные поломки с точки зрения контроля технического состояния оборудования — для каждой установки он будет специфическим. При этом текст журналов обрабатывается вручную: одни и те же сущности операторы установок могут называть по-разному, сокращать названия или разбивать один ремонт на несколько записей. А ещё команда разработки плотно общается с изготовителями оборудования и экспертами, которые работают на этом оборудовании или обслуживают и ремонтируют его.
Шаг 3. Выбираем данные для анализа
Команда разработки получает данные с журналов и датчиков и решает, какие показатели стоит использовать для предиктивной аналитики, а какие — нет, выявляет зависимости, ищет «говорящие» сигналы. Для этого использует логику, результаты предыдущих исследований и предварительный анализ конкретного оборудования.
Шаг 4. Строим математическую модель раннего обнаружения отклонений в работе оборудования
Сначала анализ проводят люди, а после них в дело вступает обученная математическая модель. Она накладывает модель нормального состояния оборудования на временной ряд реальных данных и ищет несоответствия. Все показатели, которые превышают пороговые значения, классифицируются как аномалии в работе оборудования. Среди них выбираются самые информативные сигналы, и модель проверяет, есть ли между ними и возможными будущими поломками чёткая корреляция. Алгоритм выявляет паттерны и делает предсказания: какие узлы потребуют замены или небольшого ремонта, когда, сколько времени в запасе.
После обучения модель может мониторить состояние оборудования и корректировать планы на техобслуживание и ремонт. Это помогает оптимизировать затраты на их проведение, предотвратить преждевременный выход из строя отдельных элементов и уменьшить количество внеплановых ремонтов.
Причём предсказания делаются задолго до того, как операторы установок могли бы заметить неладное: система учитывает слабые сигналы, совокупность которых в контексте состояния оборудования, прошедших ремонтов и замен деталей как раз и даёт прогноз. То есть можно действовать проактивно, избегать простоев, а не просто реагировать на случившееся.
Простой пример: мы написали модель для грануляторов Hosokawa. С помощью неё можно выполнять прогноз остаточного ресурса по косвенным признакам. Одним из информативных признаков, влияющих на деградацию шнека, была его скорость вращения. Во время анализа данных и построения модели выяснилось, что чем больше скорость вращения, тем сильнее износ установки. Косвенные признаки при должном упорстве можно найти у любого оборудования.
Дмитрий Распопов
Шаг 5. Операторы получают результаты аналитики
Данные идут к конечным пользователям. А те заранее закупают какие-то запчасти, проводят дополнительное ТО и т. д.
Задача оценки остаточного ресурса считается одной из самых трудных. Существует множество подходов к её решению, каждый из которых может быть лучше или хуже на разных данных. Нам удалось подойти к решению этой задачи, выявив косвенные признаки, влияющие на исчерпание остаточного ресурса.
Дмитрий Распопов
Стек лаборатории и необходимые знания
Языки и инструменты помимо Python: SQL, Java, JavaScript.
Математика: математический анализ, линейная алгебра, статистика, теория вероятностей, дискретная математика, различные методы оптимизации, алгоритмы.
Образование: техническое образование с упором на АЭС, построение предиктивных моделей для оборудования АЭС требует понимания проблематики.
Библиотеки и фреймворки для создания моделей: TensorFlow, Keras, XGBoost, CatBoost, PyTorch. Для анализа данных Pandas, NumPy.
Библиотеки и фреймворки для графиков и дашбордов: Matplotlib, Seaborn, Plotly.
Библиотеки для работы с временными рядами: Prophet, Statsmodels, Sktime, Tslearn, Tsfresh, Darts, Karts, Merlion, PyTorch Forecasting, Graykite и многие другие.
Также команда разрабатывает собственные функции для решения специфических задач, связанных с данными.
Задача 3. Как Python помогает анализировать проектную документацию, ГОСТы и внутренние стандарты
В атомной промышленности много нормативной документации. ГОСТы, внутренние инструкции, регламенты, допуски… В Росатоме есть даже свой институт стандартизации. В документах описаны требования к процессам, материалам, эксплуатации оборудования. Все эти регламенты постоянно нужны в работе.
АЭС Росатома должна соответствовать куче требований: от марок бетона до устойчивости конструкций перед природными катаклизмами. Они записаны в тысяче нормативных актов, от федерального ГОСТа до локального стандарта. Собрать их воедино, отделить конкретные требования от описательной части, ничего не забыть — непросто.
Например, существует ГОСТ по производству бетона для создания опалубки: 25 страниц, 27 ссылок на другие ГОСТы, в которых тоже есть ссылки. В общей сложности нужно обработать несколько тысяч страниц. И это капля в море нормативной документации, которую используют в Росатоме.
Причём документация в основном бумажная. Работать с ней неудобно, даже когда есть сканы. Росатом взял амбициозную задачу — перевести эти документы в единый внутренний формат системы управления требованиями. Он должен быть удобен и людям, и программным системам. Чтобы в пару кликов собрать все требования под новые проекты, сформировать чек-листы и создать проектную документацию.
Перед командой группы подготовки данных встала такая задача:
Разметка уже существующей документации под формат системы управления требованиями. Это задача по обработке текстов на естественном языке (NLP, natural language processing). Раньше этой работой занимались эксперты — они вручную обрабатывали документы, классифицировали, разбивали по абзацам и элементам: требования, информацию, таблицы, рисунки.
Может показаться, что это легко сделать уже существующими программами и модулями для распознавания текста и документов. Но документация в АЭС — слишком специфическая и сложная. Поэтому мы делаем решение в разметке текста с нуля на Python. Это универсальный язык для быстрой проверки идей и сборки приложений. Относительно неторопливый Python показывает себя отлично.
Используем и готовые компоненты: библиотека Pymorphy, фронтенд приложения на Django, маленький тестовый образец для экспериментов на Flask. Но алгоритм — полностью самописный, без scikit-learn и других инструментов, на основе семантического анализ текста. Иногда юзаем Tesseract, но ограниченно: у него недостаточно высока точность распознавания. Картинки обрабатываем с OpenCV.
Python знают многие — и притом хорошо. Но нам важно ещё придумать и реализовать на нём интересные алгоритмы. Нужны кругозор, насмотренность, творческая жилка, способность играть в команде, не замыкаться в себе и узкой задаче — и, конечно, отличное знание алгоритмов.
Андрей Буйновский
Как устроено распознавание документации
Для пользователя есть веб-приложение с GUI. В него закидывают документы.
Их разбирает алгоритм: присваивает определённый тип по классификатору, потом анализирует и классифицирует каждый компонент — абзацы текста, таблицы, инфографику, рисунки.
Мы обучали алгоритм на уже размеченных документах. Нормативка сильно формализована, на выходе получилось очень качественное и точное решение. Точность распознавания выше 99%, скорость выше ручной обработки в пять раз. Это при том, что эксперты всё ещё разбирают иллюстрации и таблицы, визируют, перепроверяют текстовые данные. К тому же алгоритм не устаёт и не отвлекается — никакого человеческого фактора.
Андрей Буйновский
После элементы собираются в сводную таблицу базы данных. Каждому присваивается определённый класс. Выстраиваются взаимосвязи между ними: что за чем следует, в каких местах расположены иллюстрации и таблицы.
 Результат оцифровки нормативной документации: текст разбит на фрагменты и компоненты с уникальными ID и классами. Источник: Росатом
Результат оцифровки нормативной документации: текст разбит на фрагменты и компоненты с уникальными ID и классами. Источник: Росатом
Почему таблицы, инфографика и рисунки всё равно обрабатываются экспертами? Цена небольшой ошибки в распознавании таких регламентных элементов чрезвычайно высока: мы ведь говорим про АЭС. Ошиблись на тысячную долю процента в таблице с допустимыми параметрами? Вышли за их границу при эксплуатации и капитально нарушили работу станции.
Готовая таблица в базе данных — это уже нативный формат внутренней системы управления требованиями Росатома. Ещё в системе есть возможность экспорта документов в другие популярные форматы.
Пока мы писали своё решение, появилось несколько удачных компонентов и алгоритмов, подходящих для других проектов. Например, алгоритм классификации на основе семантического анализа. Он, по сути, может анализировать практически любые текстовые источники, делать на их основе обобщения и выводы. Это открывает огромные возможности в аналитике информации.
Андрей Буйновский
Что почитать и посмотреть
Нейроморфы
Предиктивные модели в промышленности
Коллекция ссылок на кейсы о применении машинного обучения в промышленности
Хакатоны, в которых принимает участие команда отдела искусственного интеллекта «Цифрума»
Natural language processing
Наши соцсети (там больше о наших исследованиях)
Заключение
Пока популярность Python в проектах, связанных с искусственным интеллектом, нейронными сетями, машинным обучением и другими хайповыми направлениями продолжает расти. Вряд ли в ближайшие годы его положение смогут оспорить новые языки и технологии. Тем более, вокруг него успел сложиться мощный и разнообразный тулинг: одних только библиотек и фреймворков более 10 000.
А какой стек для задач в ML, AI, NN используете вы? Устраивает ли вас Python, видите ли вы проблемы в его экосистеме или предпочитаете другие технологии: тот же JS с его TensorFlowJS, R, Julia, C++, Kotlin или что-то ещё?
Кстати, если у вас есть вопросы по описанным проектам и технологиям — не стесняйтесь, ребята из Росатома мониторят комментарии и постараются ответить на них.
