Псевдо-случайное изображение (на примере страницы 404ой ошибки)
Однажды автор этого поста работал над одним заказом по разработке простенько сайта и тогда появилась идея — придать всем страницам некой уникальности и запоминаемости — использовать уникальные фоновые текстуры или элементы дизайна (активно использовался parallax-scrolling). Так как в тот момент дедлайн был довольно близок, а идея — в зачаточном состоянии, было реализовано намного проще — простыми заготовками, но идея выброшена не была.Спустя некоторое время случайно наткнулся на мертвую ссылку, которая вела на несуществующий Tumblr-блог, и страница ошибки сразу привлекла внимание. Обновив страничку фоновое изображение (в виде gif-анимации) сменилось — внимание ещё более усилилось. Почитав исходники стало понятно что все изображения «прописаны» статично, но это натолкнуло на другую идею, о которой вы узнаете под катом.
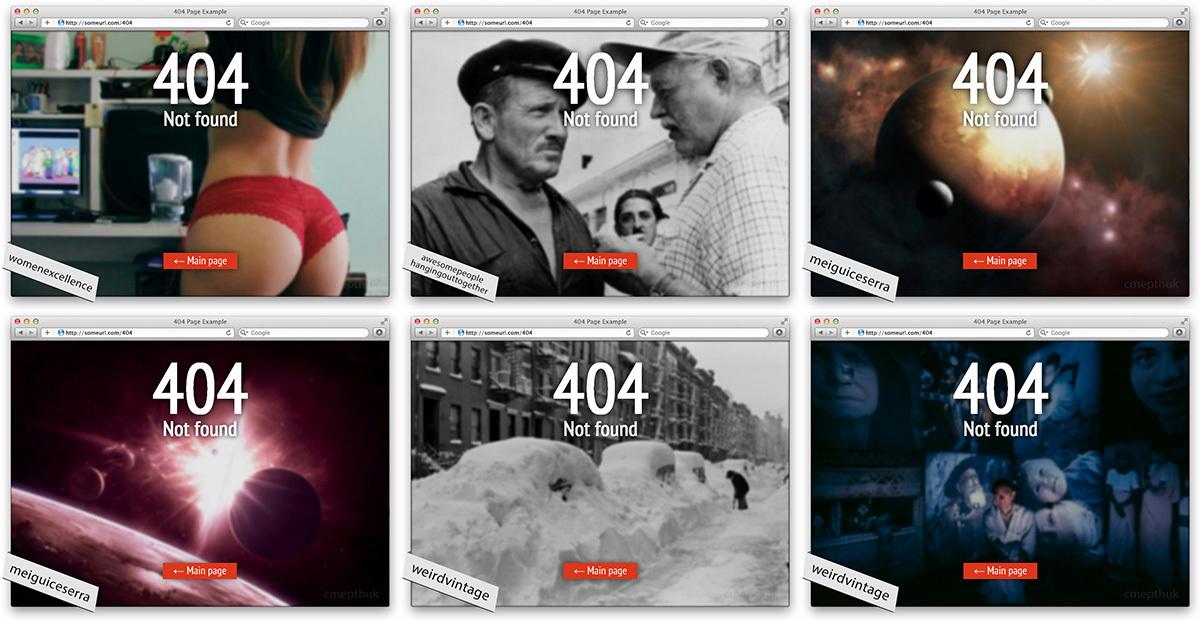 Идея заключалась в следующем: «Почему бы нам в случае, когда необходимо оформить какую-либо страницу (в частности сервисную — вход, выход, ошибка), или просто получить тематическое изображение для оформления контента, не использовать псевдо-случайные изображения? «Семантически под «псевдо-случайными» я имею в виду изображения определенной тематики (или имеющие между собой какие-либо общие черты), но с течением времени результат «выпадения» был бы в той или иной степени уникальным.
Идея заключалась в следующем: «Почему бы нам в случае, когда необходимо оформить какую-либо страницу (в частности сервисную — вход, выход, ошибка), или просто получить тематическое изображение для оформления контента, не использовать псевдо-случайные изображения? «Семантически под «псевдо-случайными» я имею в виду изображения определенной тематики (или имеющие между собой какие-либо общие черты), но с течением времени результат «выпадения» был бы в той или иной степени уникальным.
Возможные методы решения:
Парсинг результатов поиска (google, yandex) по картинкам; Парсинг хостингов картинок, имеющие деление изображений по тегам или критериям; Инстаграм и сервисы иже с ним; Использовать средства блог-платформ, имеющих акцент на фото-контент. Парсинг результатов поисковых запросов отпал по причинам встречающейся низкой релевантности, большого количества «мусора», а сами изображения хранятся черт знает где. Хостинг картинок — как-то не сложилось (может быть и зря) сразу. Инстаграм — низкое качество изображений (640×640 точек) и сложность в запросах для получения релевантных ответов. Так и остался крайний вариант — блог-платформы.Не скажу что выбор был мучительный, так как сам на Tumblr веду пару блогов и в курсе относительно статистики. В том числе — статистики постов:
 Плюсы данного решения:
Плюсы данного решения:
Изображения в тематических блогах придерживаются своего концепта в 9 из 10 случаев; При наличии корпоративного или личного блога на этом же сервисе изображения можно брать прямо из него, получается довольно прикольно; Нет необходимости беспокоиться об актуальности; Изображения находятся в открытом доступе; Tumblr отлично дружит с ifttt. Минусы: Если брать контент не у блога с устоявшимся форматом, есть вероятность получить изображение лысого мужика в наколках не соответствующее формату; Теперь остается дело за малым — получить сами картинки. Хочется отдельно выразить благодарность разработчикам этой платформы, так как апи для получения и выборки контента очень прост и качественно реализован. Работу по получению и разбору данных было решено возложить на клиента (что без каких-либо сложностей переписывается на любой серверный язык). В итоге у меня получился следующий пример (дабы сократить длину поста css обернут в спойлер):
Формируем и отправляем Ajax-запрос к API Tumblr-a; Проверяем статус ответа и проходимся по каждому посту; Если это фото-пост, то проходимся по каждому изображению; Если изображение нам подходит (например — тип, минимальный размер, соотношение сторон), то добавляем его в итоговый массив; Если по завершению прохода нужное количество изображений не собрано — рекурсивно запускаемся снова, но с новым отступом. Результат работы примера выглядит следующим образом (одно изображение — один показ):
 И несколько слов о том, в каком виде у нас возвращаемые данные:
И несколько слов о том, в каком виде у нас возвращаемые данные: 
Плюсы данной реализации:
Если захочется использовать gif-изображение — изменяем искомое расширение (строка ~178) и пересматриваем проверку размеров изображений;
Чтобы изменить источник изображений — необходимо изменить один вызов функции;
При отключенном JavaScript — выведем изображение из заготовки (см. );
Доступны различные размеры изображений;
Работает даже в IE6 (при выключенном 'debug' — режиме, строка ~153);
Легко «допилить» под себя.
И минусы: В среднем получение и разбор данных (получалось 1…2 запроса, 10 изображений) во время тестов занимал порядка 0,4…1 секунды, что довольно долго;
Необходимость таскать JQuery.
 Эпилог
Данный метод может замечательно вписаться в небольшие сайты, портфолио, студии, блоги. Не нуждается в поддержке, легко интегрируется в готовые решения, не нагружает сервер. Вполне реально использовать в шаблонах для наполнения тестовым контентом (несколько строк на jQuery по замене 'src' у ). Буду рад, если кому-то помог, или навел на другую стоящую мысль.
Эпилог
Данный метод может замечательно вписаться в небольшие сайты, портфолио, студии, блоги. Не нуждается в поддержке, легко интегрируется в готовые решения, не нагружает сервер. Вполне реально использовать в шаблонах для наполнения тестовым контентом (несколько строк на jQuery по замене 'src' у ). Буду рад, если кому-то помог, или навел на другую стоящую мысль.
