Простые highload паттерны на Go
Привет, Хабр! Меня зовут Агаджанян Давид, хочу поделиться некоторыми инженерами рекомендациями, которые часто на моем опыте помогали держать highload нагрузку не прибегая к хардкору. Примеры будут на Go. Эти подходы довольно хорошо известны, но как мне кажется они недооценены и многие этими подходами пренебрегают. Если вы впервые видите их, то рекомендую хотя бы попробовать реализовать в своих проектах и провести бенчмарки, возможно вы будете приятно удивлены. Этих подходов в 90% случаях мне хватало за глаза, когда требовалось быстро и кратно увеличить перфоманс приложения в короткие сроки. Ну и конечно же делитесь своим опытом к каким подходам для оптимизаций вы прибегаете в первую очередь, буду рад взять себе интересное на заметку
Refresh-ahead caching
Если по бизнес логике вашего приложения допустимо отдавать данные не первой свежести, то кешируйте их в приложении и отдавайте как есть. А сами данные обновляйте в фоне
Пример: у вас есть главная страница со списком популярных фильмов, обновляете вы этот список редко, да и если отдадите устаревший, то в лучшем случае никто не заметит, в худшем никто не пострадает. Так почему бы просто не взять и не закешировать этот список прямо в приложении?
Концепт: закешировать список популярных фильмов в памяти и отдавать как есть, при этом в фоне запустить воркер, который раз в N секунд обновит данные в памяти
 refresh-ahead caching
refresh-ahead caching
Реализация: ниже код, но если вам удобнее смотреть в github, welcome
package main
import (
"context"
"encoding/json"
"net/http"
"sync"
"time"
)
type Movie struct {
Title string `json:"Title"`
}
type CachedPopularItems struct {
lock sync.RWMutex
Movies []Movie
}
func main() {
ctx := context.Background()
// initializing cache and fill
cache := CachedPopularItems{}
cache.Movies = getPopularMoviesFromDB()
go func() {
timer := time.NewTicker(1 * time.Second)
defer timer.Stop()
// initializing background job
for {
select {
// refreshing cache
case <-timer.C:
movies := getPopularMoviesFromDB()
// updating cache struct
cache.lock.Lock()
cache.Movies = movies
cache.lock.Unlock()
// app is terminating
case <-ctx.Done():
break
}
}
}()
http.HandleFunc("/getPopularMovies", func(writer http.ResponseWriter, request *http.Request) {
cache.lock.RLock()
movies := cache.Movies
cache.lock.RUnlock()
bytes, _ := json.Marshal(movies)
writer.Header().Add("Content-Type", "application/json")
writer.Write(bytes)
})
_ = http.ListenAndServe(":8890", nil)
}
// Getting from DB
func getPopularMoviesFromDB() []Movie {
// simulation request to database with latency
time.Sleep(5 * time.Second)
return []Movie{{Title: "Avatar"}, {Title: "I Am Legend"}, {Title: "The Wolf of Wall Street"}}
}Плюсы
Никакой логики, пришел запрос, сразу отдали ответ
Снимается нагрузка на хранилище, особенно если запрос тяжеловесный
Снимается сетевой поход в хранилище
Узкое горлышко приложения в таком случае — это кол-во открытых соединений и сетевой канал
В случае если хранилище будет недоступно, пользователи все равно будут получать данные
Минусы
Подходит только для тех данных, которые можно отдавать в устаревшем состоянии
В простой реализации подходит только для простых справочных данных, если запросы имеют вариативность, то внедрить этот механизм та еще задача
Этот и другие подходы к кешированию можно прочитать в известном справочнике system-design-primer
Do once, give it to everyone
Если много пользователей приходят одновременно в сервис за одной и той же информацией, зачем ее выполнять в лучшем случае дважды, а в худшем тысячи раз?
Пример: у вас есть приложение с книгами, какие-то книги смотрят чаще, какие-то реже, и бывает такое, что на страницу определенных книг приходится высокая нагрузка, отследить причину пиков не удается, а ресурсы сэкономить хочется
Концепт: научиться считать хеш-код задачи, которую требуется сделать с учетом входных данных, выполнять ее один раз и отдавать ее всем запросившим. На примере ниже видно что одно и та же книга запрошена дважды, можно пойти в хранилище один раз и отдать ее обоим запросившим клиентам
 do once, give it to everyone
do once, give it to everyone
Реализация: реализация на Go в github
package main
import (
"encoding/json"
"fmt"
"math/rand"
"net/http"
"strconv"
"strings"
"time"
"golang.org/x/sync/singleflight"
)
type Book struct {
ID int
Title string `json:"Title"`
}
func main() {
// Struct for syncing work
s := singleflight.Group{}
http.HandleFunc("/getBook/", func(writer http.ResponseWriter, request *http.Request) {
bookID, _ := strconv.Atoi(strings.TrimLeft(request.RequestURI, "/getBook/"))
workHash := fmt.Sprintf("book:%d", bookID)
// Doing work with same hash once
result, _, _ := s.Do(workHash, func() (interface{}, error) {
return getBookFromDB(bookID), nil
})
book := result.(Book)
bytes, _ := json.Marshal(book)
writer.Header().Add("Content-Type", "application/json")
writer.Write(bytes)
})
_ = http.ListenAndServe(":8890", nil)
}
// Getting from DB
func getBookFromDB(id int) Book {
// simulation request to database with latency
time.Sleep(1 * time.Second)
return Book{ID: id, Title: randSeq(rand.Intn(30))}
}
var letters = []rune("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
// Random string generator
func randSeq(n int) string {
b := make([]rune, n)
for i := range b {
b[i] = letters[rand.Intn(len(letters))]
}
return string(b)
}Плюсы
Предотвращение дублирования повторяющихся параллельных задач
Экономия ресурсов CPU/Сети
Минусы
Worker pool
Вам хорошо известна пропускная способность вашего приложения и нагрузка, которую вам необходимо обрабатывать или саму задачу можно разбить на подзадачи и запараллелить
Пример 1: у вас есть сервис, который выполняет сложные вычислительные операции и инициализация объектов для выполнения — дорогая операция, поэтому необходимо подготовиться заранее, при этом нужно ограничить количество одновременно выполняемых вычислений
Пример 2: у вас есть сервис, который на один запрос выполняет множество операций (батч запрос) и их можно выполнить параллельно, собрав результаты в единый отчет
Концепт: на старте приложения инициализировать N воркеров, которые будут выполнять полезную работу, и сбрасывать состояние объектов воркера после завершения задачи
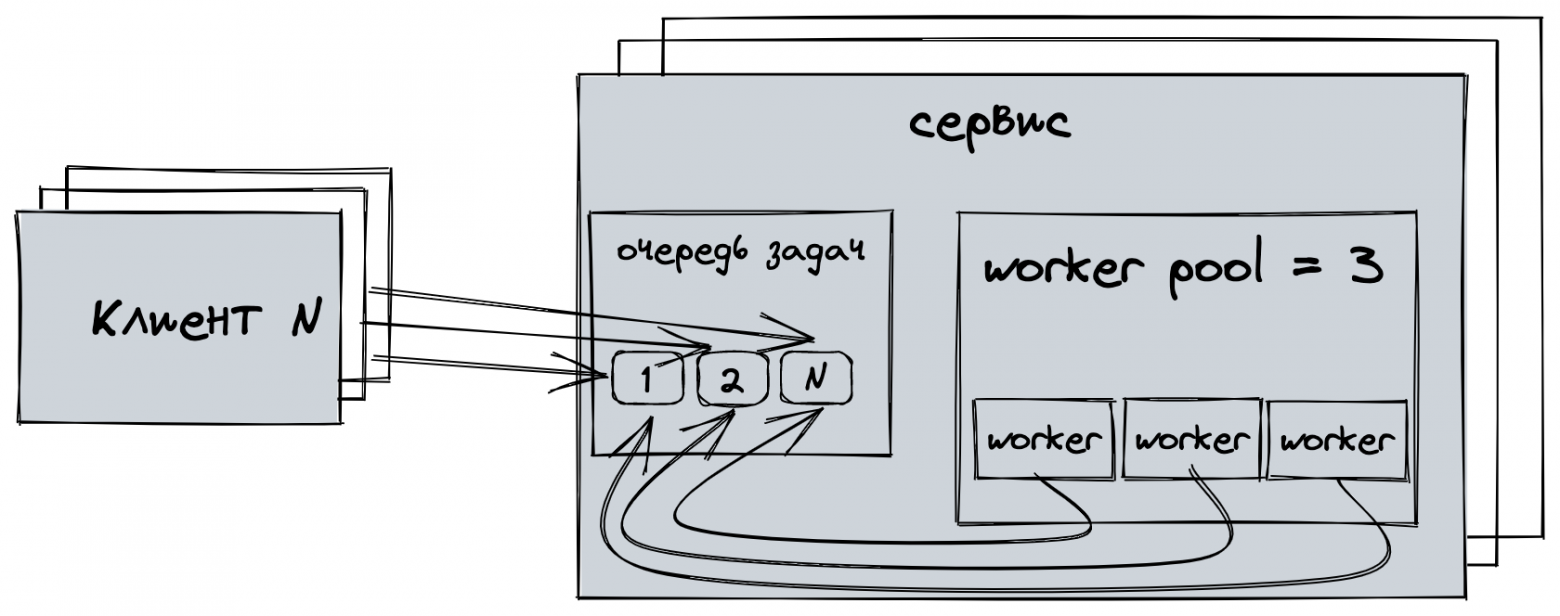 worker pool
worker pool
Реализация: реализация на Go в github
package main
import (
"context"
"encoding/json"
"math/rand"
"net/http"
"time"
)
type WorkerPool struct {
jobs chan WorkJob
}
func (w *WorkerPool) StartWorker() {
go func() {
for {
work := <-w.jobs
// simulating work
time.Sleep(1 * time.Second)
status := false
if work.ID%10 > 5 {
status = true
}
work.Result <- WorkJobResult{Status: status}
}
}()
}
// Adding work job to queue
func (w *WorkerPool) AddJob(ctx context.Context, id int) <-chan WorkJobResult {
resultChan := make(chan WorkJobResult, 1)
select {
// trying to add wor job
case w.jobs <- WorkJob{ID: id, Result: resultChan}:
// in case if request is aborted
case <-ctx.Done():
return nil
}
// return chan where consumer can read result
return resultChan
}
type WorkJob struct {
ID int
Result chan WorkJobResult
}
type WorkJobResult struct {
Status bool
}
func main() {
// worker pool with three workers
wp := WorkerPool{
jobs: make(chan WorkJob, 3),
}
wp.StartWorker()
wp.StartWorker()
wp.StartWorker()
http.HandleFunc("/handle", func(writer http.ResponseWriter, request *http.Request) {
resultsChan := make([]<-chan WorkJobResult, 0)
for i := 0; i < 10; i++ {
resultChan := wp.AddJob(context.Background(), rand.Intn(100))
resultsChan = append(resultsChan, resultChan)
}
status := false
for _, res := range resultsChan {
resStatus := <-res
status = status && resStatus.Status
}
bytes, _ := json.Marshal(status)
writer.Write(bytes)
})
_ = http.ListenAndServe(":8890", nil)
}Плюсы
Ограничение пропускной способности приложения
Параллельное выполнение подзадач
Экономия ресурсов, так как вы можете переиспользовать в worker pool объекты между задачами и не генерировать лишнего мусора
Минусы
Итог
Делитесь своими любимыми практиками, буду рад открыть что-то новое. Буду признателен любым конструктивным замечаниям. Спасибо!
