Нейросети, датасеты, VQА: разбираем результаты соревнования Fusion Brain Challenge с конференции AIJ 2021
Привет, Хабр! Сегодня мы расскажем об интересных задачах соревнования Fusion Brain Challenge с международной конференции AIJ 2021 по искусственному интеллекту, нейросетям и смежным темам. Цель проведения ― собрать на одной площадке представителей международных организаций, бизнеса, научного сообщества и технических специалистов. В рамках конференции проводятся и соревнования.
Одно из них, Fusion Brain Challenge, хотелось бы особо отметить ― уж очень интересные задачи, связанные с нейросетями, multitask-моделями, обработкой данных, решались на этом соревновании. Подробности (а их немало, так что вы можете почерпнуть что-то для себя), как всегда, ― под катом.

Кратко о конференции
Если вам интересно, что это за конференция такая, то ниже ― её описание. Если хотите приступить сразу к разбору задач с соревнования, можете смело пролистывать этот раздел и наслаждаться техническими подробностями.
Итак, конференция AIJ 2021 ― знаковое событие в ИИ-отрасли. В 2019 году по числу участников конференция попала в топ-5 мировых конференций, а в 2020 она стала крупнейшим профильным онлайн-мероприятием по числу регистраций.
В 2021 году в ней приняли участие около 250 спикеров со всего мира, 50 keynote-спикеров, также было проведено 20+ тематических стримов. Конференция получила 40+ млн просмотров в сети.
Для примера ― вопросы, которые обсуждались на конференции в ноябре 2021 года:
Применение технологий ИИ в обществе, бизнесе и на уровне государства.
Вопросы этики и регулирования искусственного интеллекта.
Актуальные практики внедрения ИИ в финансах, ретейле, медицине, промышленности, образовании и других сферах.
Роль технологии в области ESG и устойчивого развития.
Новейшие научные разработки в сфере искусственного интеллекта.
Выступления спикеров из разных регионов России.
Практические воркшопы и демонстрации разработок.
В рамках Fusion Brain Challenge на конференции AIJ 2021 задача Visual Question Answering (VQA) была одной из ключевых, её предлагалось решить с помощью единой multitask-модели.
Для чего нужен бенчмарк VQA и что он собой представляет
Сейчас наиболее изучены нейронные сети, решающие задачи в рамках одной модальности. Мультимодальные нейросети при этом справедливо становятся трендом и требуют к себе повышенного внимания. Необходимо создавать бенчмарки (как, например, свежий зарубежный multibench) для оценки качества и дальнейшего развития мультимодальных моделей, ведь способность обрабатывать сразу несколько модальностей ― большой шаг в сторону развития сильного ИИ.
Мы попытались предложить собственное решение, создав датасеты для задач VQA и ZsOD (Zero-shot Object Detection). Ниже расскажем о первом датасете.
Решение задачи Visual Question Answering предполагает генерацию текстового ответа на вопрос, касающийся контента изображения. Модель, получая на вход изображение и вопрос на естественном языке, должна на выходе выдать корректный ответ на соответствующем вопросу языке (в нашем случае ― русском или английском). Вопросы могут относиться к различным областям изображения, включая как основные объекты, так и детали фона.
Для оценки качества предсказания мы использовали метрику Accuracy, которая показывает долю точных совпадений среди пар предсказанных и истинных ответов, то есть отражает отношение числа совпавших ответов (когда модель предсказала верный ответ) к общему числу ответов. Эта метрика изменяется от 0 до 1, где 0 ― наихудшее значение, 1 ― наилучшее.
Нюансы задачи и технические подробности
Решение задачи усложняется её специфичностью. Так, например, информации на русском языке по задаче практически не существует (во всяком случае, её не было в момент, когда мы приступили к решению), как и необходимых в нашем случае инструкций. Да, есть ссылки на зарубежные датасеты, но без подробностей. В качестве публичной тестовой выборки было решено взять часть англоязычного VQA v2 и при составлении приватного тестового датасета ориентироваться на этот источник. Вооружившись этим «путеводным камнем», оставалось начать протаптывать свою дорожку через тёмную чащу вопросов и ответов.
А дорожка была нелегка и терниста. Дело в том, что задача усложняется множеством нюансов, которые требовалось донести до каждого, кто приступит в итоге к разметке. Скажем, если аннотаторы зададут истинным только один вариант ответа, а модель предскажет его корректный синоним, мы незаслуженно засчитаем ошибку и получим неверное значение Accuracy.

Также важно было привести задаваемые ответы к одинаковой форме (начальной), чтобы истинный и предсказанный моделью ответы сравнивались исключительно по смыслу. Сначала мы хотели просить разметчиков задавать ответы в начальной форме, но столкнулись со множеством вопросов и путаницей, поэтому решили вопрос с помощью постобработки, а именно нормализации, проведённой морфологическим анализатором.

Все числительные в вопросах и ответах мы просили задавать цифрами. При этом, как и в случае оригинального датасета VQA v2, в скрипте оценки был словарь соответствия числительных, выраженных словами (и слов со схожей семантикой, например «нисколько»), и цифр. На этапе обработки предсказаний модели все ответы приводились к цифровому виду.

Ещё одно правило: если вопрос задан к изображённой надписи, язык ответа должен соответствовать языку надписи вне зависимости от языка вопроса (в таких случаях задача, по сути, сводилась к Text Recognition in the Wild).

Дополнительно мы упомянули, что не стоит задавать абстрактные вопросы, ответа на которые нельзя получить непосредственно из содержания изображения. Например, по фото мы не можем понять, почему никто не гуляет по тротуару. Но понимаем, однако, что машины размыты из-за движения.

Мы также обращали внимание разметчиков на то, что вопросы не подразумевают несколько вариантов формулировок. Если уже спросили, какого цвета шторы, не стоит менять местами слова и добавлять аналогичный вопрос просто для количества.

Спасение разметчиков
Всё это было здорово, но людям нужны примеры, ориентиры. Шпаргалка, куда можно подглядывать и откуда черпать вдохновение. И мы пошли по лёгкому пути: из публичного тестового датасета по ключевым словам выделили условные 9 групп вопросов во избежание большого числа повторов, серьёзных различий между публичной и приватной частью, а также для охвата различных доменов.
Вот они вместе с примерами:





num ― сколько? как много? how many? how much? what number? (вопросы о количестве чего-либо на изображении; ответ, вероятнее всего, подразумевает число)

time ― сколько времени? какое время? what time? what season? when? (вопросы, связанные с определением времени на часах, времени года, времени суток)



Инструмент, процесс, контроль
С примерами и объяснением нюансов процесс должен был пойти быстро. Оставалось только определиться с инструментом. От CVAT было решено отказаться ради экономии времени на разметку номинальных bounding box«ов (ведь они не были нужны в этой задаче). Мысль вторая ― запилить бот в Telegram, который бы поочерёдно выдавал изображения и требовал нужное количество пар вопросов-ответов. Но хотелось дать разметчикам больше свободы, предоставить возможность переходить сначала к более простым или, наоборот, сложным вариантам, при этом не перегружая функционал. Тут на помощь пришла ещё одна идея ― старый добрый файл Excel и небольшие папки с изображениями, примерно по 10 в каждой. Всё это мы сложили в общее рабочее пространство и посредством менеджера задач ClickUp предложили ребятам самим назначать себя на обработку выбранных папок. На каждое изображение необходимо было придумать 6 пар вопросов и подходящих к ним ответов.
Процесс действительно начался довольно бодро. С русским языком быстрее, с английским ― чуть медленнее, но постепенно за каждой папкой был закреплён ответственный сотрудник, так что появилась возможность отслеживать стадии прогресса по статусам.
После разметки, конечно, мы направили полученные данные на следующий этап ― валидацию. Второй разметчик, сокрушаясь и охая (но на деле ― получая от этого истинное удовольствие), правил ошибки первого, а третий выбирал окончательный вариант и каждым действием продвигал проект всё ближе к успеху.
Главное ― необходимый результат был получен достаточно быстро и относительно безболезненно (редкий нервный тик на лицах валидаторов не в счёт).
А что в итоге?
Дальше можно посмотреть на графики. Под категорией »-1» остались редкие примеры, которые не удалось по ключевым словам отнести к какой-либо из групп. Приватная часть удалась сбалансированнее и чище публичной:

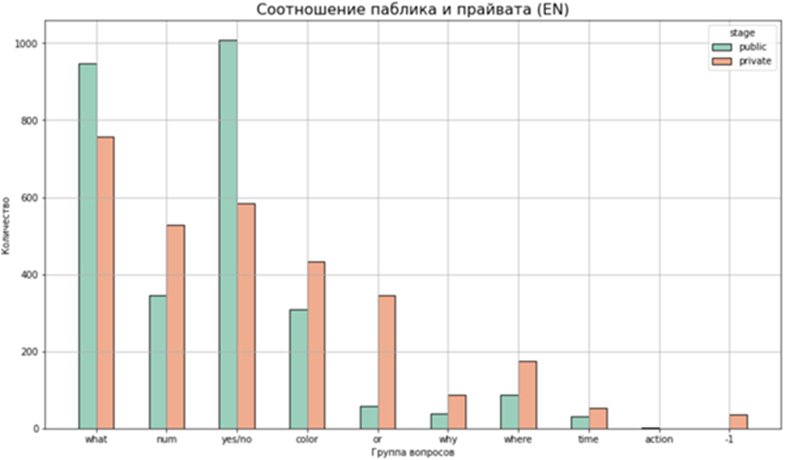
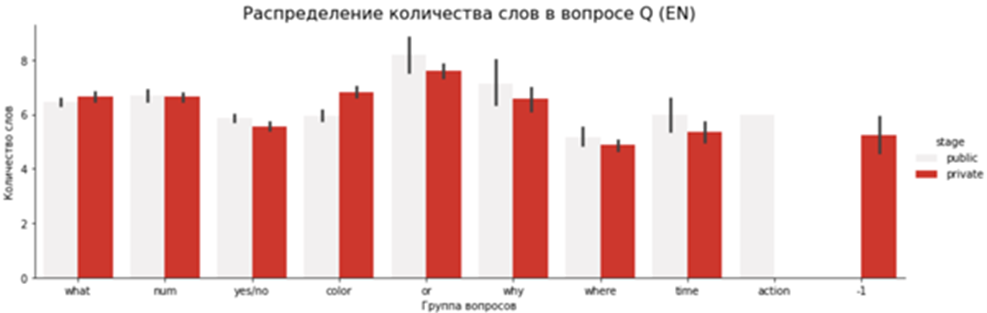
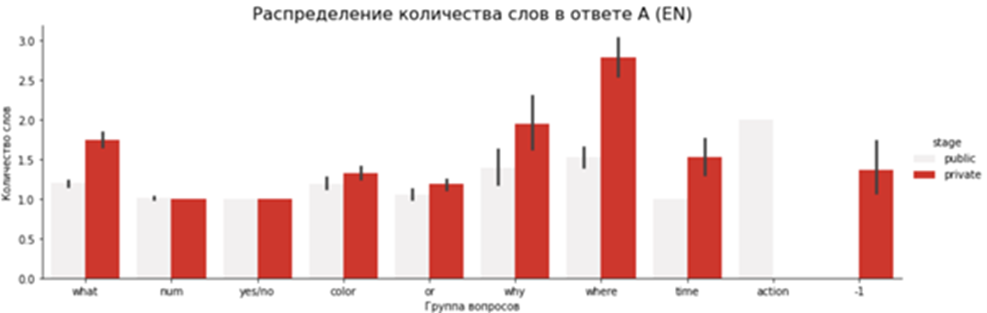
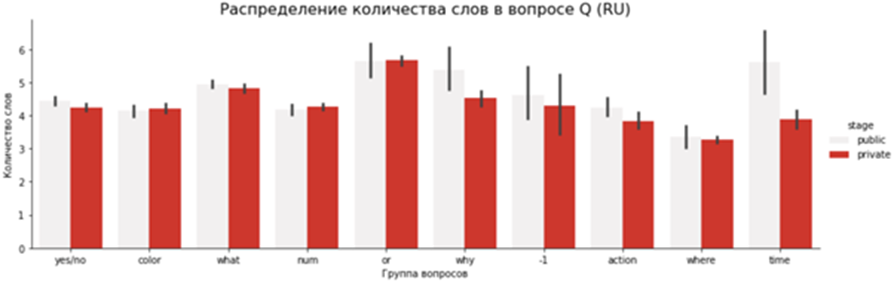
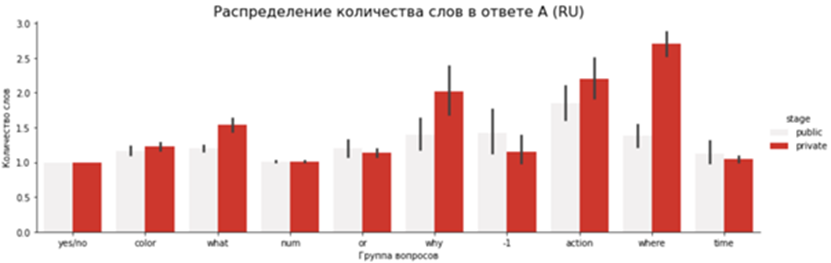
Теперь самое время узнать, как наш датасет показал себя в деле, а именно, какие результаты показали на нём модели участников.
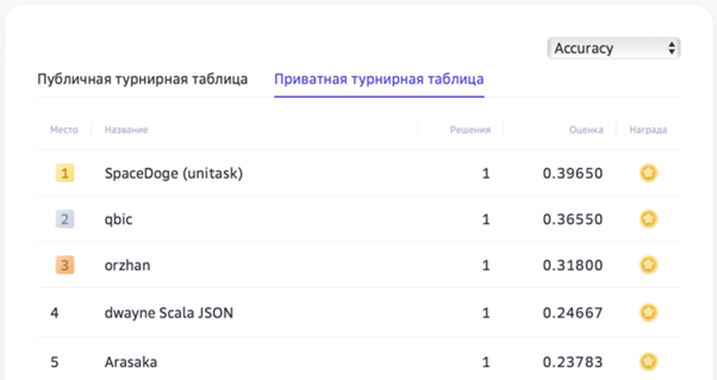
Итоговый рейтинг участников AI Journey Contest 2021
(Подзадача VQA соревнования Fusion Brain Challenge)
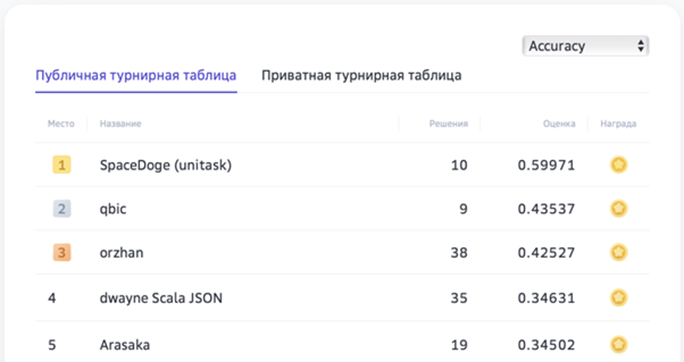
Участник SpaceDoge, чей подход оказался лучшим по подзадачам VQA и ZsOD, использовал MDETR ― мультимодальную архитектуру, которая работает с текстом (описанием или вопросом) и изображением end-to-end. В качестве картиночного энкодера использовался EfficientNet, в качестве текстового ― RoBERTa, а для непосредственного предсказания текстов и bbox«ов ― Transformer.
Второе место занял qbic, который также выбрал MDETR (текстовые признаки извлекались с помощью BART, визуальные ― с помощью EfficientNet-B3) для решения подзадач VQA и ZsOD. Изначально модель обучалась на английских и переведённых датасетах MS-COCO и VisualGenome, затем для решения VQA было проведено дообучение на английских и переведённых датасетах VQA v2 и GQA. Предсказание ответа участник реализовал через классификатор: использовались параллельные списки русских и английских ответов, нужный список выбирался по языку вопроса. Надо отметить, что по общему количеству баллов за все подзадачи qbic стал победителем контеста Fusion Brain Challenge 2021.
Наконец, участник orzhan оказался на третьем месте по решению подзадачи VQA, используя предобученный англоязычный VL-T5 ― архитектуру на основе языковой модели T5, текстовый энкодер которой превращён в мультимодальный путём включения визуальных признаков, полученных с помощью Faster R-CNN. VL-T5 тренировался на нескольких vision-and-language задачах, включая VQA. Для решения русскоязычных заданий участник встроил машинный перевод. Финальная оценка по всем подзадачам позволила orzhan занять2 место.
Наш приватный тестовый датасет вполне неплохо соответствовал публичному: оценки участников ожидаемо просели, но в допустимых пределах. Интересно, что из трёх лидеров только один использовал генеративный подход, но эта модель в итоге уступила MDETR, основанному на классификации.
Спасибо, что дочитали/проскроллили до конца. Надеемся, статья или её фрагменты будут полезны и снимут некоторые вопросы в ваших собственных скитаниях по тернистым дорожкам VQA. Хочется верить, что эта статья также станет маленьким вкладом в развитие сильного ИИ.
