Простое CPU ядро на ПЛИС
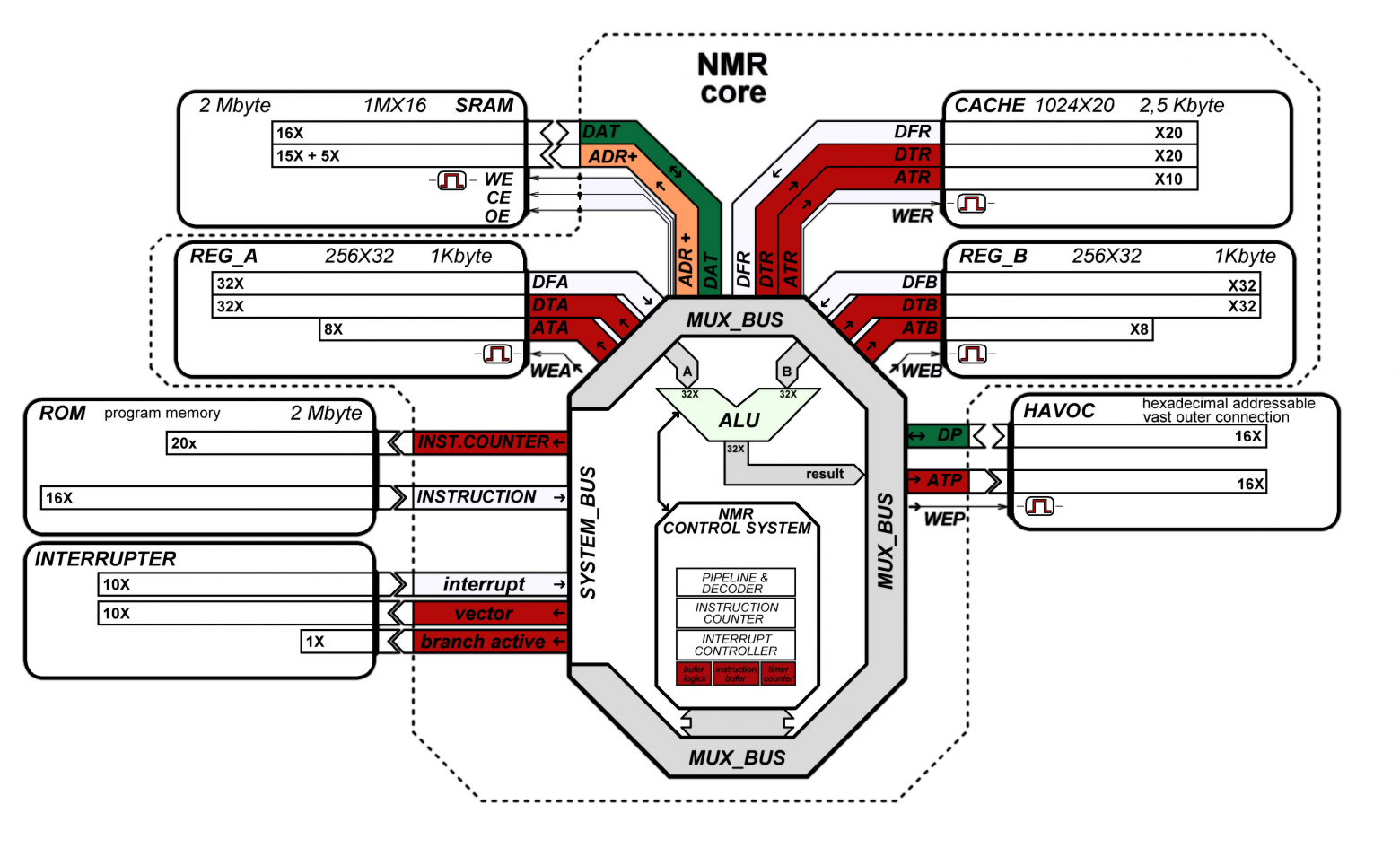
Рисунок 1 — функциональная блок схема «NMR»
Интереса ради сделал максимально простенькое процессорное ядро, о чем, собственно, и хочу рассказать, может кому-то пригодится, планирую в небольшом цикле статей представить наработки по этому проекту в открытой форме от HDL до разнообразных плат в модульном формате под это дело.
Для себя поставил такое ТЗ:
Описание максимально унифицированное, написанное одним файлом и без замудрёных конструкций, дабы легко переезжать с ПЛИСЫ на ПЛИСУ;
По возможности минимально занимаемый объем, а если быть точнее: необходимо все впихнуть в такую старенькую микросхемку как EPF10K100;
Адаптировать ядро под работу с внешними микросхемами одна для программы вторая в качестве ОЗУ. На их роль выбрал распространенные 16 битные микросхемы SRAM.
А главное: полная свобода фантазии и нестандартный подход.
Ладно, не буду много лить воды зачем это и куда, просто прикола ради, и убить время — ночное время. Творилось все это действо по ночам отсюда кстати и название ядра — NIGHTMARE для краткости NMR. Итак, после множества ночных кошмаров появилась такая вот паукообразная структура, показанная на рисунке 1.
Ядро имеет гарвардскую архитектуру и содержит отдельные шину команд, шину данных и шину периферии. Разрядность адреса памяти программ составляет 20 бит, разрядность шины инструкций 16 бит, однако сами инструкции могут иметь различную длину: 16 бит, или 32 бита. Структура командного слова представлена на рисунке 2.

Рисунок 2 — командное слово ядра «NMR»
Система команд и архитектура «NMR» разработаны специально для работы с внешней памятью программ, организованной в слова по 16 бит. Разделение некоторых команд на две ячейки предусмотрено архитектурой ядра и не отражается на программе, так как система управления процессором по типу команды, автоматически определяет смещение адреса.
Предполагается, что внешняя память программ работает на более низкой частоте, относительно самого ядра. Поэтому в организации системы команд процессора и его внутренней архитектуры реализован подход, позволяющий начать выполнение команды еще до её полного считывания. Инструкции выполняется на конвейере параллельно со считыванием частей команд из памяти, что существенно повышает быстродействие процессора, так как память перестает быть узким местом и длительность процессорного такта в среднем соответствует длительности считывания 32-битного командного слова из памяти программ.
Так как объем логических элементов ограничен, а никаких требований о производительности я себе не ставил, было принято решение повсеместно использовать доступную ПЛИСу встроенную ОЗУ. Так архитектурой ядра предусмотрены два блока регистров общего назначения: REG_A и REG_B, они 32 битные и почти равноправные с точки зрения выполнения инструкций. Каждый такой блок содержит 256 32-х битных регистра. Кроме РОН существует возможность подкрутить к ядру свободную (оставшуюся в том числе от периферии) ОЗУ, которая будет выполнять роль, своего рода, КЕШ (CACHE), т.к. доступ к ней все же быстрее чем ко внешней ИМС ОЗУ. КЕШ находится в общем для ОЗУ адресном пространстве (младшая часть), но имеет расширенный функционал, а так же расширенную шину данных до 20 бит (напоминаю что внешняя ОЗУ выбрана 16 битной). Перечисленные особенности КЕШ делают его удобным местом для хранения адресов перехода и возврата, т.е. местом для работы с адресами памяти программ. Внешняя ИМС ОЗУ предполагается идентичной ИМС для хранения программ и имеет 21-битную шину адреса. Адресное пространство ОЗУ показано на рисунке 3 и содержит 4 области:
Младший сектор КЕШ ОЗУ, позволяющий операции: «marckRAM#» и «jampRAM#», данная область максимально оптимизирована для организации СТЕКа подпрограмм и инструкций вызова и перехода.
КЕШ ОЗУ, в базовой конфигурации (адаптированной для EPF10K100) содержит менее 1023 слов (включая младшую область). Весь доступный КЕШ имеет разрядность слова 20 бит, что соответствует разрядности шины адреса счетчика инструкций «instruction_counter». Объем КЕШ ОЗУ может быть увеличен (в диапазоне 1К — 32К слов) для других семейств FPGA.
Адресация свыше 32767 слова должна быть помечена маркером в 16-м бите адреса ОЗУ. В таком случае будет доступна область внешней ОЗУ в размере 32768 слов по 16 бит (скорость доступа к внешней ОЗУ, определяется параметрами примененной ИМС SRAM).
Старшая область шины адреса ОЗУ определяет используемый сектор внешней ИМС ОЗУ, и может принимать значения от 0 (0 — полмолчания) до 31.
Таким образом, организован доступ к 2-Мбайт ОЗУ, с 2,5КБ высокоскоростной КЕШ и остальной областью внешней SRAM, разделенной на сектора, что позволяет организовывать защищенный режим для 32 потоков.
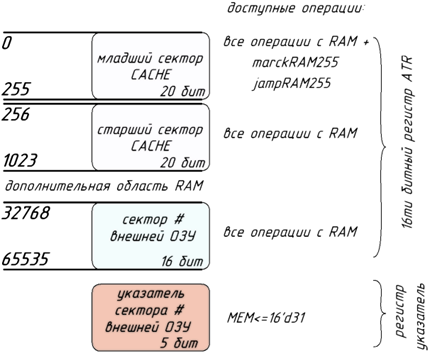
Рисунок 3 — Организация адресного пространства ОЗУ «NMR»
Архитектурой предусмотрен простенький механизм прерывания, для этого в ядро входит 10 битная шина от источника прерывания или контроллера. Контроллер прерываний решено сделать внешним модулем, ибо его функционал от проекта к проекту может очень сильно изменятся. Ядро на первой стадии процессорного такта проверяет наличие запроса на прерывание, и наличие флага о нахождении в прерывании, сохраняет адрес возврата в системный регистр и считывает из памяти программ по вектору из шины прерываний адрес перехода на подпрограмму соответствующего прерывания. Таким образом младшая область памяти программ 1–1023 слова содержит адреса подпрограмм соответствующих прерываний.
Периферия подключается к ядру по выделенной шине. Шина адреса периферии является однонаправленной: от ядра к устройствам. Шина данных периферии является двунаправленной с Z состоянием по умолчанию. Состояние шины данных задается выставленным адресом на шине адреса периферии, либо во время передачи от ядра в периферию, т.е. всегда контролируется ядром.Организация периферии и логика использования обшей шины данных показаны на рисунке 4.
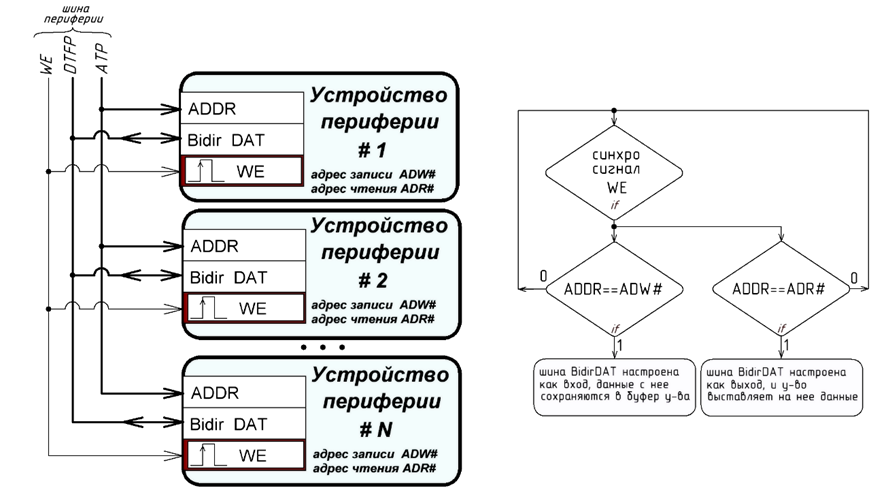
Рисунок 4 — Организация периферии и логика доступа к двунаправленной шине данных
При передаче от ядра, выставляется необходимый адрес периферийного устройства, а на шину данных заносятся передаваемые данные, на следующий такт генерируется синхронизирующий импульс разращения записи «WE».
Ядро «NMR» универсально и было испытано на разных ИМС ПЛИС, полученные характеристики ядра сведены в таблицу 1.
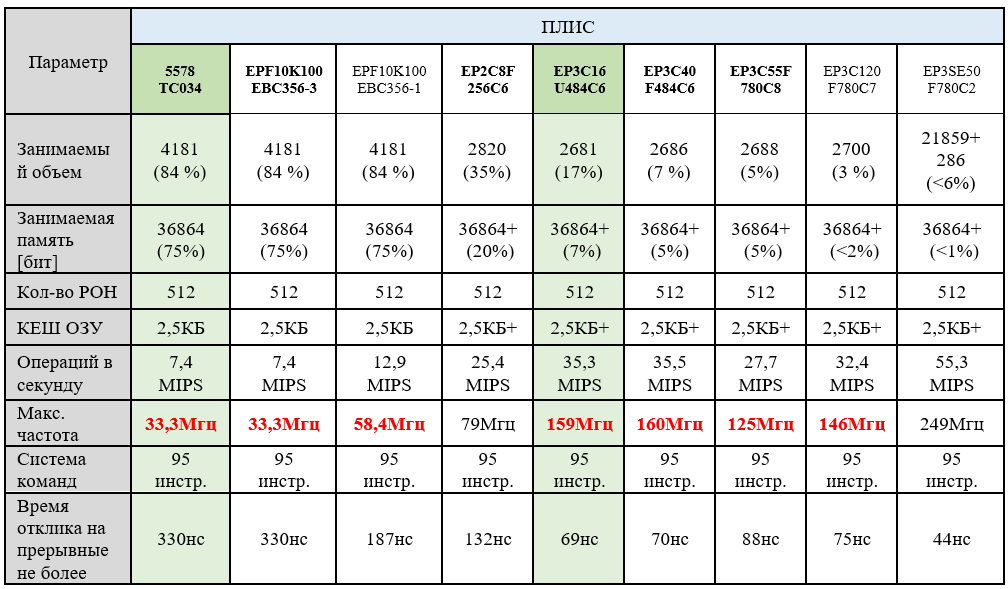
Таблица 1 — характеристики ядра «NMR_V 32I» в FPGA разных поколений
Для испытаний и отладки «NMR» по мере его развития разрабатывались разные платы и встраиваемые модули актуальная версия такого модуля Flexible Microcontroller Unit «FMU» специально разработанная под ядро «NMR», структура модуля показана на рисунке 5.
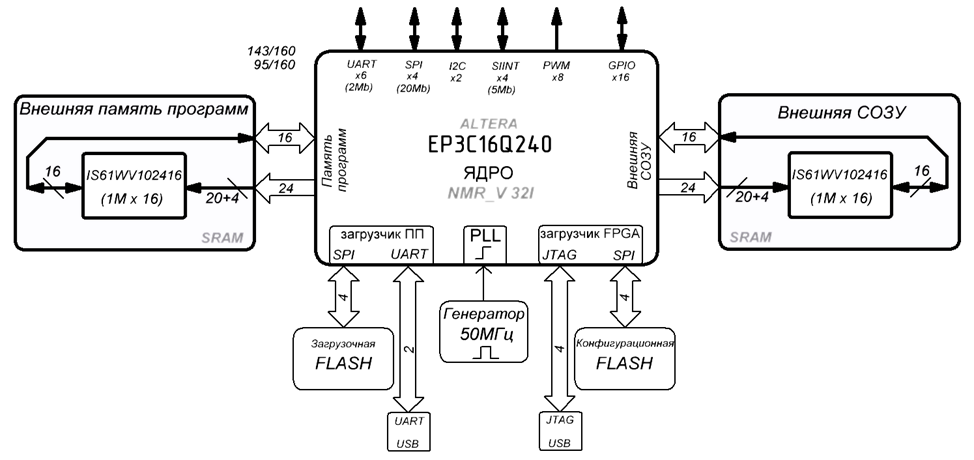
Рисунок 5 — Отладочная система на ядре «NMR» с использованием Cyclone3
Далее на рисунках 6–9 представлена архитектура системы команд:
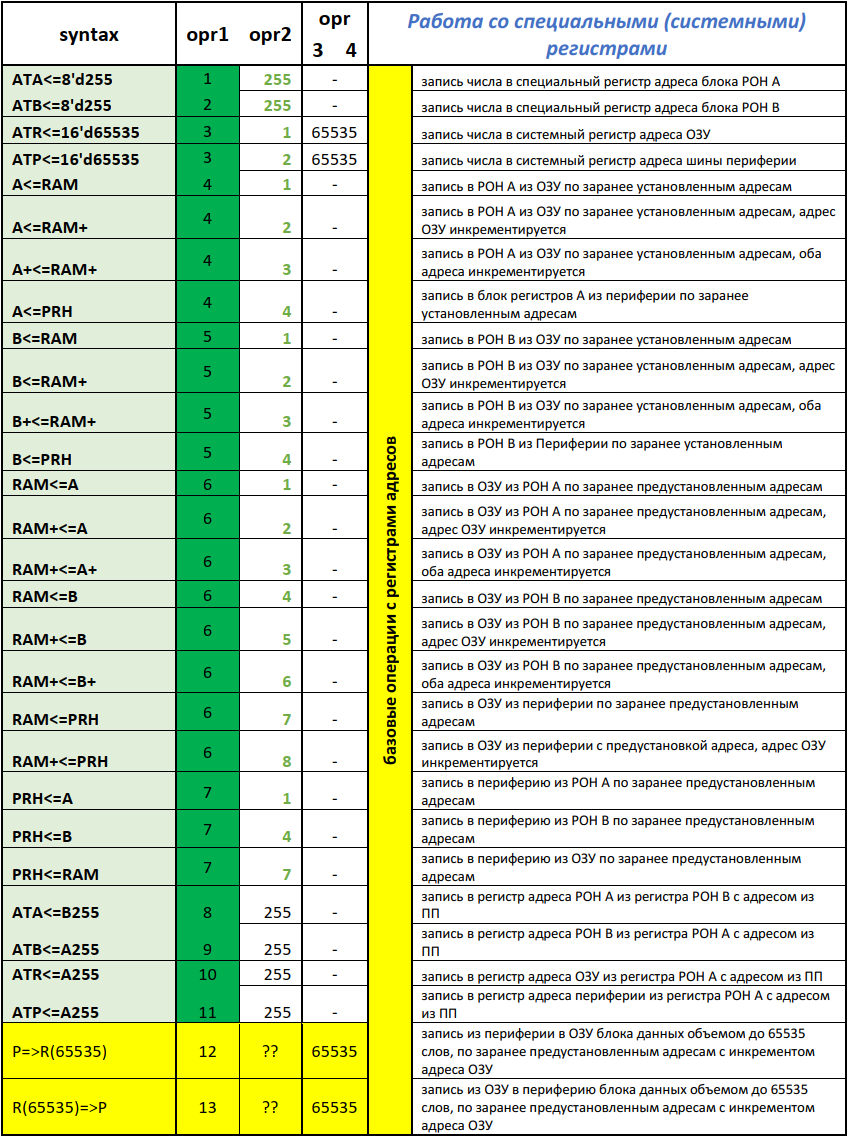
Рисунок 6 — Архитектура системы команд «NMR» для работы с системными регистрами и реализации косвенной адресации
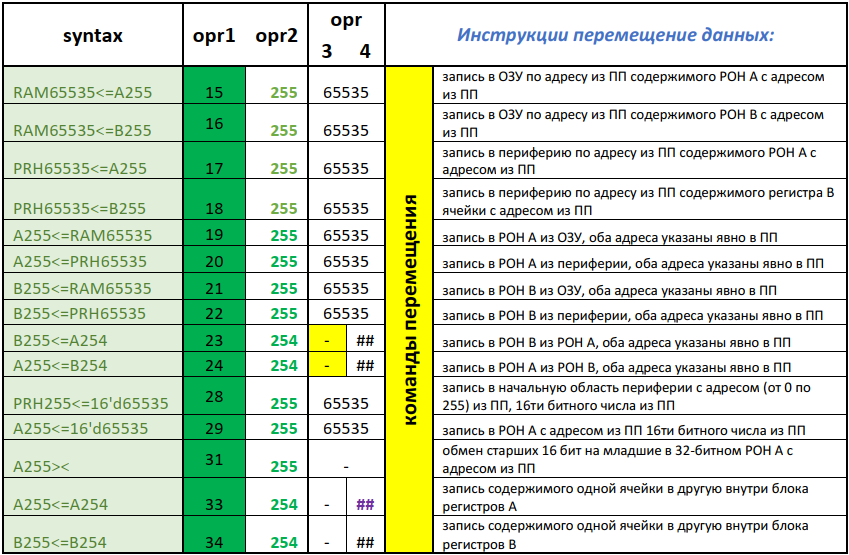
Рисунок 7 — Архитектура системы команд «NMR» для простого перемещения данных (системные регистры адреса задаются системой управления автоматически)
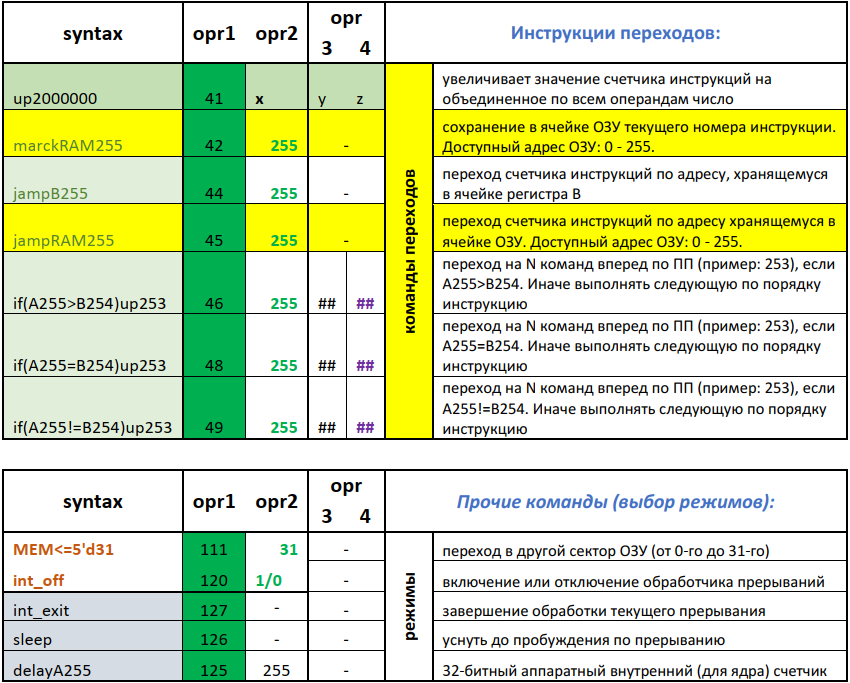
Рисунок 8 — Архитектура системы команд «NMR» для реализации переходов и задания режимов
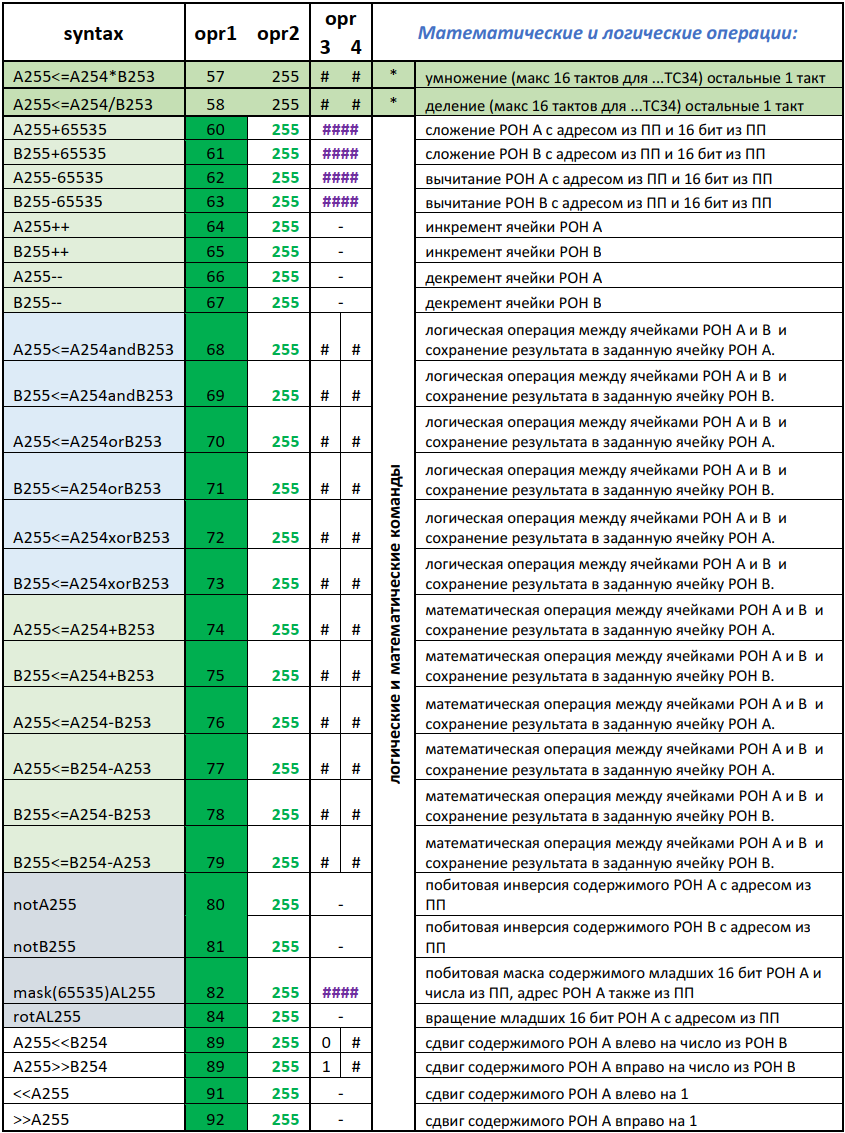
Рисунок 9 — Архитектура системы команд «NMR» для реализации логических и математических операций
На рисунке 10 представлен файл верхнего уровня — контроллера на NMR с элементами отладки, в общем рисунок полезен как иллюстрация подключения ядра и памяти, а также организации выводов/вводов.
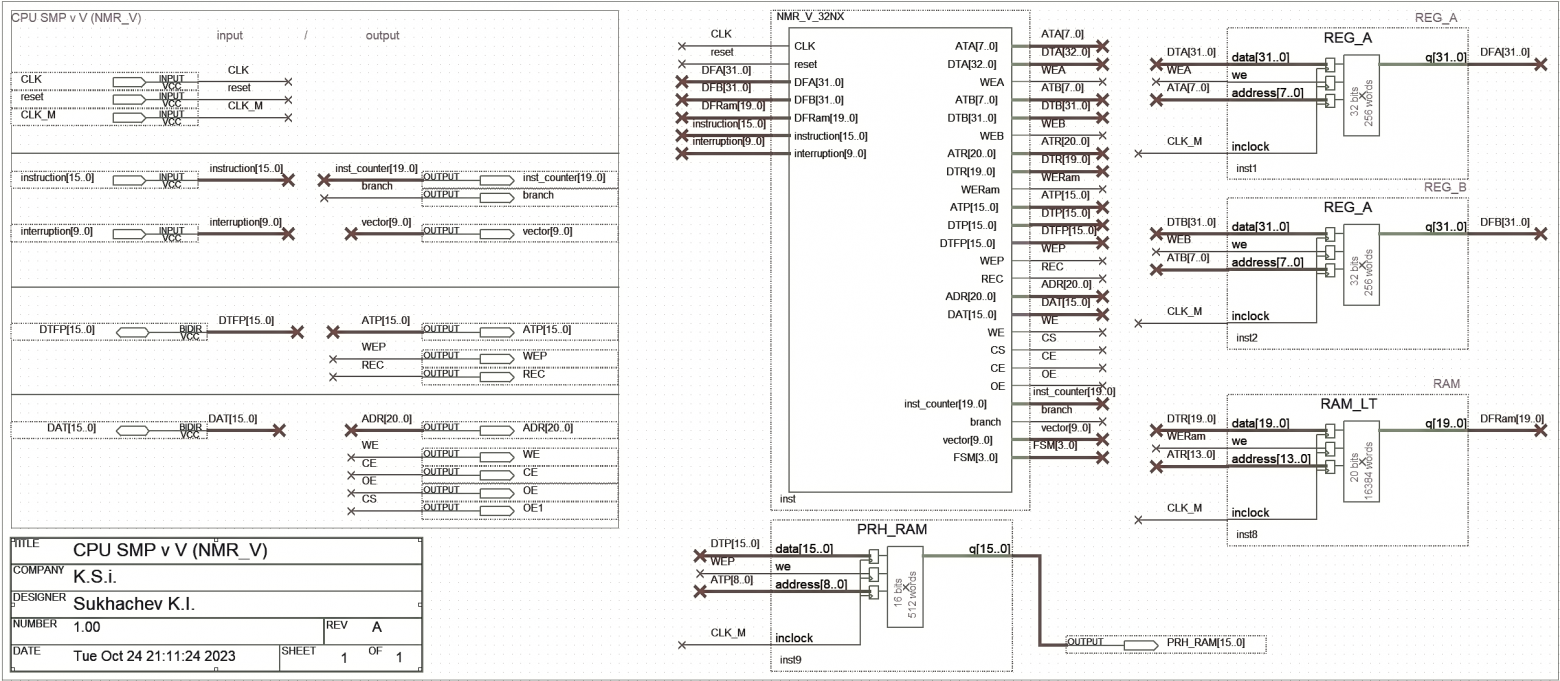
Рисунок 10 — Файл верхнего уровня минимальной обвязки «NMR» ядра из Quartus II
Это первая статья тут (как в принципе, так и из запланированного цикла), возможно есть куча недочетов, плюс не нашел как прикреплять файлы — например с HDL описанием самого ядра, если что проект открытый и буду рад поделиться со всеми наработками для его потенциального развития.
