Prometheus + Grafana: 4 golden signals и другие подходы к мониторингу

С мониторингом, как с кораблем. Конечно, успех в обоих случаях зависит не только от названия. Чтобы все не потонуло, важно помнить о базовых вещах на старте.
В этой статье мы хотим подробнее разобрать подходы к мониторингу и посмотреть на стек Prometheus и Grafana. Материал поможет расширить ваш кругозор, если вы недавно начали или только собираетесь работать с мониторингом.
Зачем нам мониторинг?
Прежде, чем говорить о конкретных инструментах, давайте дадим определение мониторингу. По версии книги «Site Reliability Engineering. Надежность и безотказность как в Google»:
Мониторинг — это сбор, обработка, агрегирование и отображение количественных показателей системы в реальном времени.
Пока все понятно. У нас есть система, мы с нее собираем показатели — количество ошибок, количество запросов, потребляемой памяти и все, что вам угодно. Далее мы это визуализируем, смотрим и на основе полученных данных делаем выводы.
Зачем же нам все это нужно? Как правило, мониторинг и вся инфраструктура observability, логирование, трейсинг стоит денег. Бывает даже так, что вся инфраструктура мониторинга стоит дороже продакшена, так как требует поддержки, обновления и улучшения. Плюс возможны ложные срабатывания, когда система мониторинга поднимает вас в пять утра из-за какой-нибудь одной ошибки.
Недостатков можно перечислить бесчисленное множество, но, первое и самое важное, мониторинг дает нам понимание того, как ведет себя приложение в продакшн среде. На самом деле этот ответ подойдет на любой вопрос вида «а зачем нужен какой-то конкретный кусок observability типа трейсинга и логирования». Таким образом:
Мониторинг повышает уровень прозрачности. Мы понимаем, как ведет себя приложение в проде, сколько трафика через нас проходит, сколько мы ресурсов потребляем, где у нас ошибки и какие они.
Хорошая система мониторинга оповещает нас о проблемах, а идеальная делает это еще до того, как с ними столкнулись наши реальные пользователи и бизнес понес репутационные и финансовые потери.
Мониторинг раскрывает перед нами аналитические возможности. Это долгосрочный и ретроспективный анализ. В первом случае — это всяческие истории про capacity planning. Мы понимаем, как наше приложение или наша система растет, как нам дальше масштабироваться. В случае с ретроспективой, вы сможете ответить на вопрос, почему система все-таки упала, что пошло не так, как вели себя метрики при инциденте, были ли ошибки.
Мониторинг не ответит вам на вопрос, сколько pod’ов нужно добавить в Kubernetes, чтобы стало хорошо, но он вам предоставит достаточное количество информации, чтобы вы на этот вопрос ответили сами.
Таким образом, мониторинг делает нашу систему надежнее за счет повышения прозрачности происходящего с системой. Мы быстрее восстанавливаемся после падений, потому что своевременно реагируем на проблемы.
Подходы
Глобально подходы к мониторингу делятся на две группы и по своему принципу схожи с методами тестирования:
Whitebox. Наблюдение за доступными внутри системы показателями. Это технические метрики, которые пользователи системы не могут увидеть снаружи.
Blackbox. Наблюдение поведения со стороны пользователя. Примером Blackbox мониторинга может быть пробер, который раз в 30 секунд проверяет, доступен ли сайт, открывается ли страница, и за какое время она это делает. Если не открывается или открывается очень долго, он вам звонит и оповещает о проблеме. Здесь нужно понимать, что, если вам звонит Blackbox мониторинг, то ваши пользователи скорее всего уже столкнулись с проблемами, поэтому чинить все нужно безотлагательно.
Про Blackbox мониторинг часто незаслуженно забывают. Мы вас призываем так не делать, хотя сегодня мы оставляем его за скобками и реализуем только Whitebox.
Далее подходы разбиваются по принципу ответа на вопрос — какие метрики нам собирать.
Есть три популярных подхода к сбору метрик:
— latency. Задержка или время выполнения HTTP запроса, в зависимости от приложения.
— traffic. Объем трафика или какой-то объем нагрузки, который вы обрабатываете прямо сейчас, обычно это RPS, RPM и тд.
— errors. Частота ошибок или количество ошибок. Это могут быть некорректные коды ответа, исключения в приложении и тд.
— saturation (загруженность или насыщенность). Эта метрика помогает отвечать на вопрос, на сколько загружено наше приложение. Допустим оно обрабатывает 150 запросов в секунду, а можем ли мы обработать 200 или 250 или мы уже загружены под 100% и больше не получится? Отметим, что многие приложения и системы деградируют еще сильно до того, как saturation достиг 100%.
— Rate. Аналог трафика
— Errors, про которые мы говорили выше
— Duration. Анализ latency
— Utilization. Использование какого-то критического для вашего приложения ресурса.
— Saturation. По версии USE, это какой-то объем работы, который стоит в очереди, потому что мы уперлись в полку по utilization. То есть какая-то работа, которую мы не можем взять, потому что кончились ресурсы.
— Errors
Ни один из этих подходов не используется в чистом виде. Как правило, их применяют в комбинации, плюс к ним сверху добавляются другие метрики. Как правило, бизнесовых, в зависимости от домена.
Может возникнуть логичный вопрос — если ни один подход в чистом виде не применяют, зачем они вообще нужны? Причины две:
подходы можно взять за основу, если вы строите систему мониторинга с нуля или переделываете ее. У вас есть база, с которой вы можете стартовать и постепенно ее наращивать.
подобные подходы снимают когнитивную нагрузку с SRE-инженеров, девопсов, админов и разработчиков. Работать с системой, в которой каждый компонент отдает 3 — 4 унифицированные одинаковые метрики, а потом уже какую-то всю остальную специфику, гораздо проще. Расследовать и тюнить проблемы при таком подходе тоже гораздо легче.
Если мы возьмем все эти три подхода и раскидаем на отрезок, с одной стороны которого будет Blackbox, а со стороны другого Whitebox, то ближе всего к Blackbox у нас ляжет RED. Почти все эти метрики наши реальные пользователи могут видеть, кроме оценки нагрузки и объема трафика. К Whitebox ближе всего буде USE, потому что у пользователя нет доступа к технически метрикам по расходу памяти, нагрузке носителей и тд. Между ними, как максимально комплексный, ляжет 4 golden signals.
Подходы. Latency
Частый камень преткновения, когда люди на своих графиках наблюдают не поведение своего приложения, а условную температуру на луне. Для начала давайте представим, что у нас есть какая-то система мониторинга, написанная нами на коленке. Она раз в 30 секунд ходит к главной странице нашего сервиса, замеряет latency и кладет в какое-то собственное хранилище. Допустим, за 5 проб у нас образовался следующий временной ряд:

Решается это визиуализацией того, сколько запросов и в какие тайминги у нас выпадает. При помощи мониторинга мы отвечаем на вопросы: сколько запросов у нас уложилось в 200 ms, 300 ms, 500 ms и тд. А теперь давайте перейдем от сухой теории к конкретным инструментам, которые помогут вам собрать и визуализировать метрики.
Первая и самая очевидная мысль, как оценить latency — взять среднее и наблюдать за ним, может быть разбить его потом по endpoint и тд. Что произойдет, если мы возьмем среднее? Среднее из 5 запросов у нас получится 400 ms. Не самый быстрый сайт, не самое приятный response time, но жить можно. Самое страшное здесь, что эти 400 ms от нас абсолютно скрывают секундный спайк. Нам кажется, что с нашим сервисом все нормально и в моменте делать ничего не нужно.
Поэтому стандартно от latency берется квантиль. Если вы откроете определение квантиля где-нибудь в Википедии, вам это все покажется ужасным, вы закроете эту историю и больше туда никогда не вернетесь. Давайте разберемся, что такое квантиль простыми словами.
Квантиль (q) — это некая величина, в которую укладывается определенный процент ваших измерений. Если мы говорим, что 99-й квартиль по response time 200 ms, это значит, что 99% наших запросов выполняются за время, которое меньше либо равно 200 ms. Соответственно, то же самое с 95%, 50% и тд. Какой-то процент наших запросов по response time укладывается в какое-то количество миллисекунд.
Если мы возьмем тот же временной ряд и посчитаем квантиль, то 99 q в нашем случае будет 972 ms, а 95 q = 860 ms. Это уже выглядит как хороший повод задуматься и посмотреть, а что же происходит с приложением. Считать квантиль вручную не обязательно, за вас все сделает система мониторинга.
На самом деле квантиль не идеален. У него есть как минимум две распространенные проблемы. Первая звучит обычно, как «у удава толстый хвост». Например, мы с вами говорим, что у нас квантиль 95, 99, и тд. У нас явно покрыт не весь процент запросов, какой-то кусочек остается непокрытым. Мы с вами не знаем, что происходит в этих остатках. Компенсируется это как правило тем, что мы просто мониторим несколько квантилей и помним про эту проблему.
Вторая проблема менее тривиальная. Мы не всегда знаем распределение таймингов запросов внутри квантиля. Если же мы опять говорим, что наш 99 q = 500 ms. Мы не всегда знаем и не всегда можем оценить, как там внутри распределены запросы. То что лежит внутри этих 500 ms, куда оно смещено, ближе к нижней границе (0 ms) или к верхней (500 ms). Мы можем пропустить момент деградации нашего сервиса, хотя квантиль не поменялся.
Это видно на примере. Если мы вернемся к той же системе мониторинга. Допустим один единственный response time у нас будет 200 ms, а остальные улетели в 700+, потому что нашему сервису совсем плохо. Наши квантили не сильно поменялись против прошлого примера, но с точки зрения пользователя, сервис стал работать гораздо медленнее. Все наши запросы внутри квантиля сместились к тысяче.

Решается это визиуализацией того, сколько запросов и в какие тайминги у нас выпадает. При помощи мониторинга мы отвечаем на вопросы: сколько запросов у нас уложилось в 200 ms, 300 ms, 500 ms и тд. А теперь давайте перейдем от сухой теории к конкретным инструментам, которые помогут вам собрать и визуализировать метрики.
Prometheus + Grafana
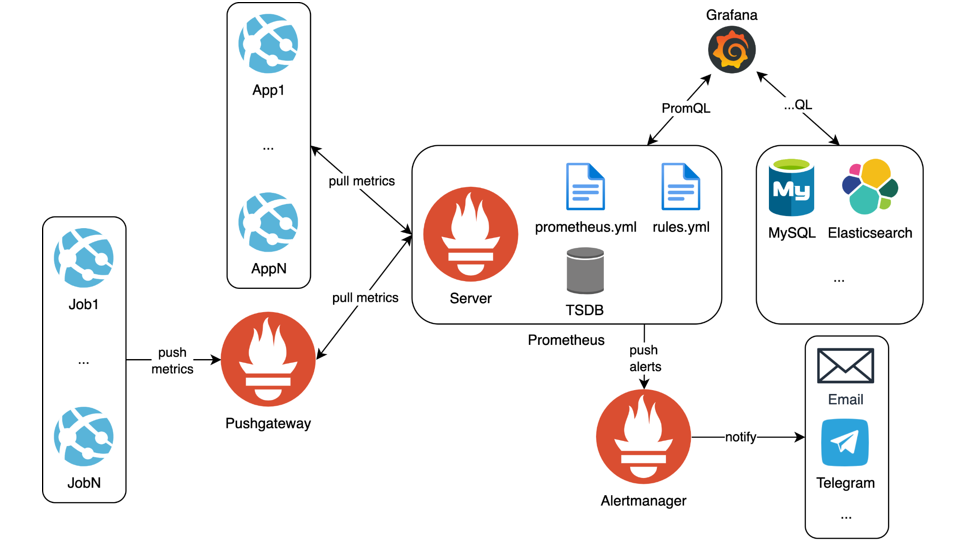
Схема работы Prometheus в паре с Grafana
В основании мониторинга лежит Prometheus сервер. Этот инструмент ответственен за сборку и хранение метрик. Рядом с ним есть хранилище TSDB, которое предоставляет сам Prometheus. Первое, что нужно знать про это хранилище, оно быстрое и оптимизированное, но не надежное. Это, конечно, не значит, что оно ломается и падает. Это значит, что оно никак не реплицируется, оно по дефолту никак не бэкапится и не рассчитано на длительное хранение большого количества метрик.
На нашей практике мы хранили метрики 2 месяца, больше полугода точно не стоит. Если вы хотите хранить что-то годами, обратите внимание на другие решения: VictoriaMetrics, Thanos и тд.
За сервером у нас как правило ходит две конфигурации, это prometheus.yml и rules.yml. prometheus.yml отвечает на вопрос, откуда и как собирать метрики. Prometheus во время сборки может какую-то часть метрик отбрасывать, какую-то переименовать, как-то поменять. В rules.yml, как правило, описаны правила алертов, которые Prometheus раз в какое-то время проверяет. Если какое-то условие в этих алертах выполняется, то этот алерт отправляется в Alertmanager, который ходит рядом с Prometheus и уже решает, какой конкретно алерт куда отправлять.
Подытожим, Prometheus сервер собирает и хранит метрики, отправляет алерты. Откуда собирать метрики описано в конфиге. Prometheus берет оттуда те самые перечисленные таргеты, проходится по ним, к каждому таргету делает HTTP запрос, забирает ответы и хранит их у себя в базе в течение какого-то времени. На основе того, что хранится в базе, он проверяет условия алертов и в случае чего отправляет в Alertmanager.
Как мы видим, Prometheus работает по pull-модели. Также вы можете реализовать push-модель. Например, у вас есть job’ы, которые ходят редко, но их тоже нужно мониторить при помощи Prometheus. При этом вы не хотите, чтобы они были постоянно запущены и потребляли ресурсы. Для таких задач Prometheus предоставляет Pushgateway. Он представляет собой адаптер, в который ваше приложение может пушить метрики, а Prometheus потом точно так же их соберет.
Итак, мы собрали метрики и нам было бы неплохо их увидеть. В этом нам поможет Grafana, которая позволяет нам визуализировать метрики из огромного количества источников, включая Prometheus.
Prometheus. Модель данных
Модель данных Prometheus очень простая и гибкая — данные хранятся в виде временных рядов. Каждый временной ряд идентифицируется именем и набором лейблов (пары, ключ, значение и т.д.).

Здесь можно сделать нетривиальный и неочевидный вывод. Так как каждый временной ряд идентифицируется уникальным набором лейблов и именем, то Prometheus боится высокой кардинальности.
Мы не просто так добавили здесь три дополнительных примера с лейблом «query». В каждом случае значение этого лейбла уникальное. Так как значение уникальное, то каждая такая вещь образует отдельный временной ряд, который отдельно хранится в TSDB. Prometheus этого не любит.
Если у вас много уникальных значений, то Prometheus ваш рано или поздно начнет потреблять большое количество памяти, медленно работать и в итоге упадет. Поэтому призываем вас не складывать лейблы в какие-то уникальные значения. Старайтесь делать лейблы плюс минус одинаковыми и друг на друга похожими.
На этой модели данных у нас построено четыре типа метрик, с которыми мы работаем.


Итоги
Мы посмотрели на подходы к мониторингу. У нас, как и в тестировании, есть Whitebox и Blackbox, то есть мы можем мониторить систему приложение и снаружи, и изнутри. Также мы имеем три базовых подхода по сбору метрик: 4 golden signals, RED и USE. Как правило, они используются комплексно с дополнительной кучей специфичных для домена метрик. Чтобы не пропустить деградацию вместо среднего от latency используйте квантиль.
Практика
После того, как мы разобрались с теорией, давайте в режиме реального времени поднимем окружение для сбора метрик Prometheus+Grafana и настроим в нем сбор и отображение четырех метрик (Latency, Traffic, Errors, Saturation), которые показывают состояние приложения и посмотрим не его исходный код.
Пошаговый разбор (с 36 минуты): https://slurm.club/42nioYb
Сопроводительные материалы:
https://www.robustperception.io/
https://github.com/s-buhar0v/4-golden…
https://prometheus.io/docs/prometheus…
Как вы могли заметить, мониторинг в Grafana дает множество преимуществ: визуализацию метрик, создание и настройка дашбордов, интеграцию с различными источниками данных, автоматизацию мониторинга, оптимизацию производительности и не только.
Всех, кто хочет обеспечить, контролировать и поддерживать надежную работу сервиса, мы приглашаем на наш курс «Мониторинг в Grafana», который стартует 27 апреля. Вы научитесь работать со связкой Prometheus+Grafana, разбираться в работе системы и читать созданные графики.

После курса вы получите практические знания и навыки, которые сразу сможете применять на вашей работе. Научитесь эффективно собирать, хранить, отображать и анализировать метрики и логи в режиме реального времени, используя наиболее современные инструменты.
