Профилирование и оптимизация программ на Go
Введение
В этой статье я расскажу, как профилировать и оптимизировать приложения на языке Go с использованием встроенных и общих инструментов, доступных в ОС Linux.
Что такое профайлинг и оптимизация? Если ваша программа работает недостаточно быстро, использует слишком много памяти, неоптимально использует процессор, вы хотите понять, в чем дело, и исправить — это и есть профайлинг и оптимизация.
Я привел такое определение, чтобы сразу отсечь вопросы некорректной работы приложения. В этой статье мы не будем говорить о проблемах мультитредового программирования, о дата-рейсах (англ. data race), о поиске ошибок (англ. debugging). Для всего этого в Go есть свои утилиты и подходы, но оставим эту тему на будущее.

Процессор
Начнем сегодняшний обзор с процессора.
В Go существует встроенный профайлер, сделанный по образу и подобию профайлера из набора утилит gperftools для C/C++. Более того, написанный на Go аналог утилиты pprof, предназначенной для визуализации результатов профилирования, стал теперь основной версией и рекомендуется для визуализации как для Go, так и для C/C++.
Если говорить о классификации, то профайлер Go является «семплирующим» (англ. sampling profiler). Это значит, что с какой-то периодичностью мы прерываем работу программы, берем стек-трейс, записываем его куда-то, а в конце, на основе того, как часто в стек-трейсах встречаются разные функции, мы понимаем, какие из них использовали больше ресурсов процессора, а какие меньше.
Практически все утилиты и профайлеры Go мы можем запускать несколькими способами, некоторые из которых описаны в этой статье.
Давайте начнем с примера, а после поговорим подробнее.
Пример
package perftest
import (
"regexp"
"strings"
"testing"
)
var haystack = `Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras accumsan nisl et iaculis fringilla. Integer sapien orci, facilisis ut venenatis nec, suscipit at massa. Cras suscipit lectus non neque molestie, et imperdiet sem ultricies. Donec sit amet mattis nisi, efficitur posuere enim. Aliquam erat volutpat. Curabitur mattis nunc nisi, eu maximus dui facilisis in. Quisque vel tortor mauris. Praesent tellus sapien, vestibulum nec purus ut, luctus egestas odio. Ut ac ipsum non ipsum elementum pretium in id enim. Aenean eu augue fringilla, molestie orci et, tincidunt ipsum.
Nullam maximus odio vitae augue fermentum laoreet eget scelerisque ligula. Praesent pretium eu lacus in ornare. Maecenas fermentum id sapien non faucibus. Donec est tellus, auctor eu iaculis quis, accumsan vitae ligula. Fusce dolor nisl, pharetra eu facilisis non, hendrerit ac turpis. Pellentesque imperdiet aliquam quam in luctus. Curabitur ut orci sodales, faucibus nunc ac, maximus odio. Vivamus vitae nulla posuere, pellentesque quam posuere`
func BenchmarkSubstring(b *testing.B) {
for i := 0; i < b.N; i++ {
strings.Contains(haystack, "auctor")
}
}
func BenchmarkRegex(b *testing.B) {
for i := 0; i < b.N; i++ {
regexp.MatchString("auctor", haystack)
}
}
Перед вами два бенчмарка, каждый из которых N раз делает поиск подстроки в строке. Один делает это с использованием пакета регулярных выражений, а другой — с использованием пакета strings. Ищем слово auctor.
Запустим бенчмарк и посмотрим на результаты.
$ go test -bench=.
testing: warning: no tests to run
BenchmarkSubstring-8 10000000 194 ns/op
BenchmarkRegex-8 200000 7516 ns/op
PASS
ok github.com/mkevac/perftest00 3.789s
Результат ожидаемый, т.к. регулярные выражения — гораздо более мощный и потому медленный инструмент, но давайте попробуем отпрофилировать этот код.
Самый простой способ воспользоваться профайлером в данном случае — запустить тот же самый бенчмарк с дополнительным параметром -cpuprofile cpu.out. В результате в директории появится файл cpu.out с результатами профилирования и бинарник, который необходим для получения символов, дизассемблирования и т.д.
Бинарник на самом деле создается всегда, но в обычном случае он создается во временной директории и удаляется сразу после выполнения бенчмарка. В случае же запуска с профилированием результирующий бинарник не удаляется.
Итак, запустим бенчмарк BenchmarkRegex с профилированием:
$ GOGC=off go test -bench=BenchmarkRegex -cpuprofile cpu.out
testing: warning: no tests to run
BenchmarkRegex-8 200000 6773 ns/op
PASS
ok github.com/mkevac/perftest00 1.491s
Как вы видите, я запустил бенчмарк с префиксом GOGC=off в начале. Переменная окружения GOGC, выставленная в off, отключает garbage collector. Я это сделал осознанно, чтобы garbage collector и его стек-трейсы не отвлекали нас от хода моего рассказа.
Кстати, отключение GC для недолго живущих скриптов и программ — отличное решение, которое может уменьшить время работы программы в разы. И не только в Go. Для PHP мы тоже иногда используем этот «финт», насколько я знаю. По сути, мы уменьшаем время работы за счет используемой памяти на сервере.
Воспользуемся теперь утилитой pprof, чтобы визуализировать граф вызовов.
$ go tool pprof perftest00.test cpu.out
Самым простым способом получить граф является команда web, которая автоматически сохраняет SVG-картинку во временную директорию и запускает браузер, чтобы ее показать.
Если вы работаете на удаленном сервере, то этот вариант не пройдет. Вам нужно или прокинуть X-сервер, используя ключ -Y для SSH, или сохранить SVG-файл на диск командой go tool pprof -svg ./perftest00.test ./cpu.out > cpu.svg, скопировать его к себе на компьютер и там открыть.
В случае OSX, как у меня, вам нужно будет установить X сервер XQuartz, чтобы прокидывание через SSH сработало.
Посмотрим на получившийся граф вызовов.
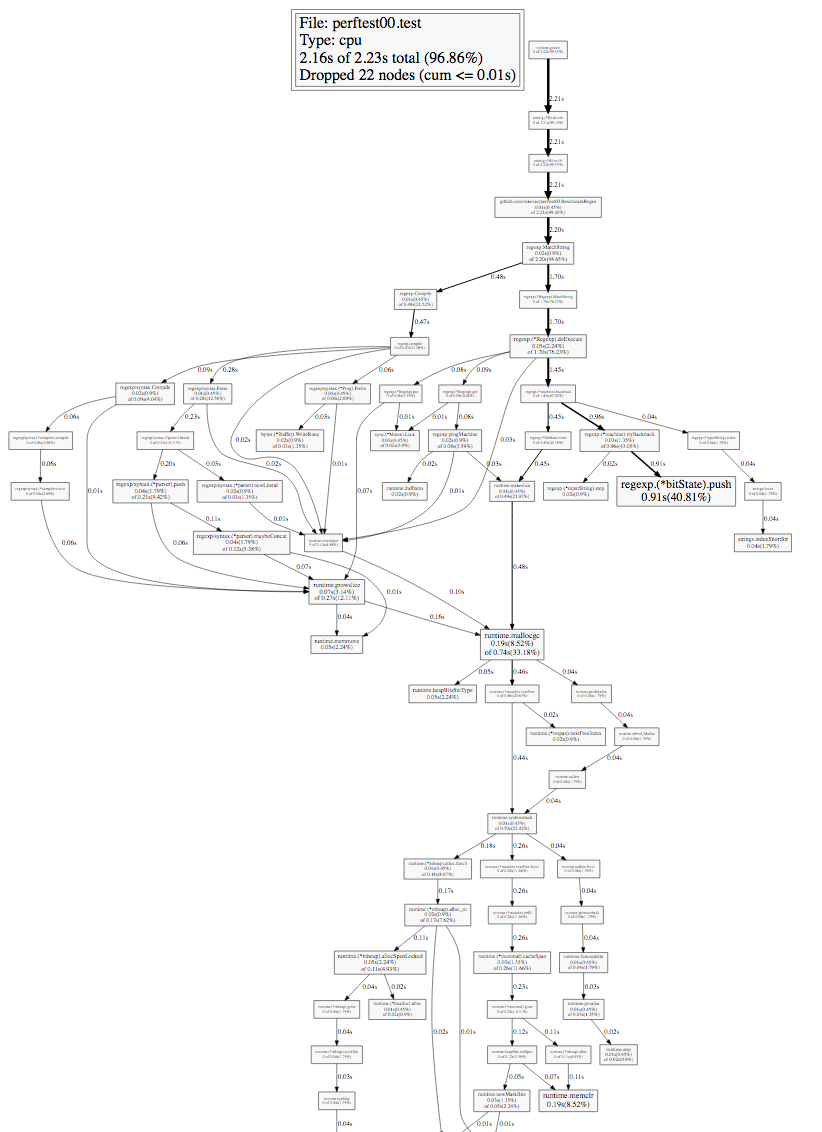
Изучая такой граф, в первую очередь нужно обращать внимание на толщину ребер (стрелочек) и на размер узлов графа (квадратиков). На ребрах подписано время: сколько времени данный узел или любой из ниже лежащих узлов находился в стек-трейсе во время профилирования.
Давайте пойдем по жирным стрелочкам с самого первого (верхнего) узла и дойдем до первой развилки.
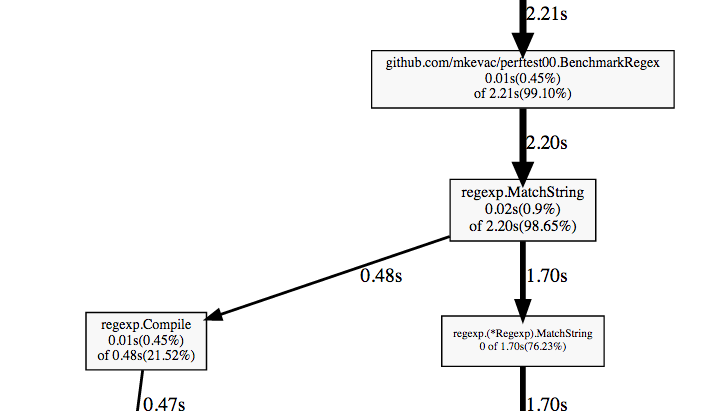
Мы видим нашу функцию BenchmarkRegex, видим функцию regexp.MatchString, которую мы вызываем, и видим, что она раздваивается.
Если вы когда-нибудь использовали регулярные выражения, то вы, скорее всего, знаете, что большинство реализаций разделяет процесс на этап компиляции изначального строкового представления регулярного выражения в какой-то промежуточный вариант и на собственно использование этого промежуточного варианта.
Напрашивается тривиальная оптимизация: делать компиляцию единожды, а не многократно.
Сделаем это:
package perftest
import (
"regexp"
"strings"
"testing"
)
var haystack = `Lorem ipsum dolor sit amet, consectetur adipiscing
[...]
Vivamus vitae nulla posuere, pellentesque quam posuere`
var pattern = regexp.MustCompile("auctor")
func BenchmarkSubstring(b *testing.B) {
for i := 0; i < b.N; i++ {
strings.Contains(haystack, "auctor")
}
}
func BenchmarkRegex(b *testing.B) {
for i := 0; i < b.N; i++ {
pattern.MatchString(haystack)
}
}
И посмотрим, что изменилось:
$ go test -bench=.
testing: warning: no tests to run
BenchmarkSubstring-8 10000000 170 ns/op
BenchmarkRegex-8 5000000 297 ns/op
PASS
ok github.com/mkevac/perftest01 3.685s
Как видно, вариант с регулярными выражениями ускорился на порядок и вплотную приблизился к варианту с простым поиском подстроки.
А как же изменился граф вызовов? Он стал «сильно проще», т.к. теперь компиляция делается только один раз. Более того, вызов компиляции вообще не попал в граф, т.к. профилирование является семплирующим.
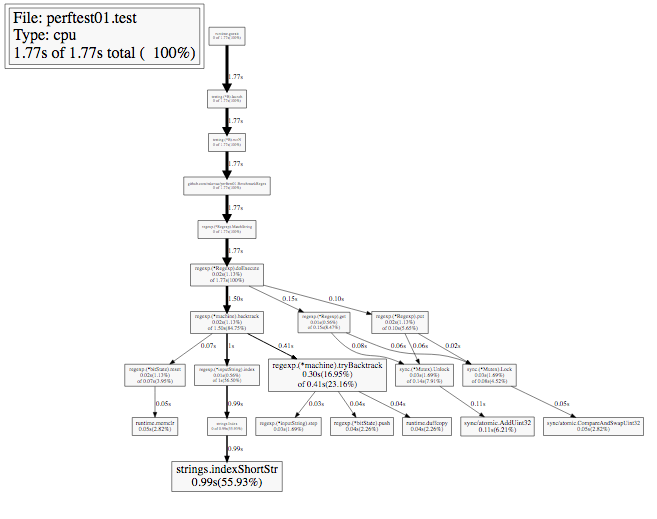
Отлично. Давайте посмотрим, какие еще способы у нас есть, для того чтобы запускать Go-профилировщик CPU.
Способы запуска профайлера
Один из способов мы уже увидели — это параметр -cpuprofile для команды go test.
Мы также можем запускать профайлер вручную, используя функции pprof.StartCPUProfile () и pprof.StopCPUProfile (). Немного проще воспользоваться очень удобной оберткой над этими функциями от Дейва Чейни (англ. Dave Cheney) (https://github.com/pkg/profile), которая создаст за вас файл, будет писать в него и т.п.
И еще одним замечательным методом является использование пакета net/http/pprof. Если вы импортируете его, то он автоматически добавит HTTP-обработчик для URL /debug/pprof, и вы сможете профилировать работающую программу удаленно, используя тот же самый go tool pprof. Давайте посмотрим, как это выглядит.
Напишем простенький пример:
package main
import (
"net/http"
_ "net/http/pprof"
)
func cpuhogger() {
var acc uint64
for {
acc += 1
if acc&1 == 0 {
acc <<= 1
}
}
}
func main() {
go http.ListenAndServe("0.0.0.0:8080", nil)
cpuhogger()
}
Как видно, мы импортировали пакет net/http/pprof и запустили HTTP-сервер командой http.ListenAndServe (). Этого достаточно, чтобы использовать профайлер во время работы программы.
Давайте теперь запустим программу и воспользуемся профайлером:
$ go tool pprof http://localhost:8080/debug/pprof/profile?seconds=5
Как видно, мы просто передаем утилите pprof путь к хендлеру, по которому «слушает» профайлер. Дополнительно можно передать время работы профайлера (по умолчанию 30 секунд).
Команда web работает отлично, команда top работает отлично, но вот list и disasm говорят, что нет информации об исходниках программы:
(pprof) web
(pprof) top
4.99s of 4.99s total ( 100%)
flat flat% sum% cum cum%
4.99s 100% 100% 4.99s 100% main.cpuhogger
0 0% 100% 4.99s 100% runtime.goexit
0 0% 100% 4.99s 100% runtime.main
(pprof) list cpuhogger
Total: 4.99s
No source information for main.cpuhogger
Чтобы получить информацию об исходниках, нам нужно запустить pprof немного иначе. Нужно передать ему и путь к бинарнику:
$ go tool pprof pproftest http://localhost:8080/debug/pprof/profile?seconds=5
Теперь мы можем воспользоваться и list, и disasm и убедиться, что реальность совпадает с ожиданиями.
(pprof) list cpuhogger
Total: 4.97s
ROUTINE ======================== main.cpuhogger in /home/marko/goprojects/src/github.com/mkevac/pproftest/main.go
4.97s 4.97s (flat, cum) 100% of Total
. . 6:)
. . 7:
. . 8:func cpuhogger() {
. . 9: var acc uint64
. . 10: for {
2.29s 2.29s 11: acc += 1
1.14s 1.14s 12: if acc&1 == 0 {
1.54s 1.54s 13: acc <<= 1
. . 14: }
. . 15: }
. . 16:}
. . 17:
. . 18:func main() {
(pprof) disasm cpuhogger
Total: 4.97s
ROUTINE ======================== main.cpuhogger
4.97s 4.97s (flat, cum) 100% of Total
. . 401000: XORL AX, AX
1.75s 1.75s 401002: INCQ AX
1.14s 1.14s 401005: TESTQ $0x1, AX
. . 40100b: JNE 0x401002
1.54s 1.54s 40100d: SHLQ $0x1, AX
540ms 540ms 401010: JMP 0x401002
. . 401012: INT $0x3
Давайте ради интереса копнем поглубже. Мы выкачаем то, что возвращает URL самостоятельно:
$ curl http://localhost:8080/debug/pprof/profile?seconds=5 -o /tmp/cpu.log
Мы видим, что внутри /tmp/cpu.log такие же бинарные данные, какие возвращаются при использовании go tool test -cpuprofile или StartCPUProfile (). «Натравим» команду strings на этот бинарный файл и поймем, что внутри нет названий функций или так называемых символов.
$ strings /tmp/cpu.log | grep cpuhogger
Откуда же тогда в первом случае, когда мы запускали pprof без бинарника, были получены имена функций? Оказывается, при импорте net/http/pprof добавляется еще один URL /debug/pprof/symbol, который по адресу функции возвращает ее название. С помощью запросов к этому URL команда pprof получает имена функций.
Но этот URL не возвращает ни исходный код функции, ни дизасемблированный. Для дизасемблирования нам нужен бинарник, а для исходного кода нам нужен и бинарник, и собственно исходный код на диске.
Будьте внимательны: передаваемый бинарник и исходный код должны быть именно те, которые запущены. Иначе вы можете получить совсем не те данные, которые ожидаете, и будете искать проблемы там, где их нет.
Как работает pprof?
Давайте из любопытства посмотрим, как именно работает pprof и какие недостатки имеет используемый подход.
Для того чтобы обеспечить работу многих программ одновременно, современные десктопные и серверные операционные системы реализуют так называемую вытесняющую многозадачность. Программе выделяется определенный временной промежуток и определенный процессор, на котором она работает. По истечении этого времени ОС вытесняет программу и запускает на ее месте другую, если она готова к работе.
Но как именно реализована возможность прерывания? Ведь ОС — почти такая же программа. Все дело в том, что ОС просит железо посылать ей сигнал с определенной периодичностью и назначает на этот сигнал обработчик. Когда сигнал приходит, процессор останавливает все, что в данный момент работает на нем, и запускает заданный обработчик. В этом обработчике ОС может вытеснить или не вытеснить текущий процесс, заменить его другим и т.д.
По такому же принципу работает и профайлер Go. Go runtime просит ОС посылать сигнал (man setitimer) с определенной периодичностью и назначает на этот сигнал обработчик. Обработчик берет стек-трейс всех горутин (англ. goroutines), какую-то дополнительную информацию, записывает ее в буфер и выходит.
Именно с багом в процессе доставки сигналов определенным тредам и связана проблема с предыдущими версиями OS X.
Каковы же недостатки данного подхода?
- Каждый сигнал — это изменение контекста. Вещь довольно затратная в наше время. Поэтому на текущий момент реалистично получить не более 500 сигналов в секунду. Стандартное значение в Go сейчас — 100 в секунду. Иногда этого мало.
- Для нестандартных сборок, например, с использованием -buildmode=c-archive или -buildmode=c-shared, профайлер работать по умолчанию не будет. Это связано с тем, что сигнал SIGPROF, который посылает ОС, придет в основной поток программы, который не контролируется Go.
- Процесс user space, которым является программа на Go, не может получить ядерный стек-трейс. Неоптимальности и проблемы иногда кроются и в ядре.
Основное преимущество, конечно, в том, что Go runtime обладает полной информацией о своем внутреннем устройстве. Внешние средства, например, по умолчанию ничего не знают о горутинах. Для них существуют только процессы и треды.
Системные профайлеры
Мы посмотрели, как работает встроенный профайлер Go. Давайте посмотрим, насколько применимы стандартные Linux-профайлеры perf и SystemTap.
Возьмем самую первую программу из статьи, только превратим ее из бенчмарков в обычную программу, работающую бесконечно.
package main
import (
"regexp"
"strings"
)
var haystack = `Lorem ipsum dolor sit amet, consectetur adipiscing [...]
Vivamus vitae nulla posuere, pellentesque quam posuere`
func UsingSubstring() bool {
found := strings.Contains(haystack, "auctor")
return found
}
func UsingRegex() bool {
found, _ := regexp.MatchString("auctor", haystack)
return found
}
func main() {
go func() {
for {
UsingSubstring()
}
}()
for {
UsingRegex()
}
}
SystemTap
SystemTap — очень мощный профайлер, который позволяет писать небольшие программки на псевдоязыке. Эта программка в дальнейшем автоматически преобразовывается в С, собирается в виде ядерного модуля Linux, грузится, работает и выгружается.
Посмотрим, видит ли SystemTap наши функции:
$ stap -l 'process("systemtap").function("main.*")'
process("systemtap").function("main.UsingRegex@main.go:16")
process("systemtap").function("main.UsingSubstring@main.go:11")
process("systemtap").function("main.init@main.go:32")
process("systemtap").function("main.main.func1@main.go:22")
process("systemtap").function("main.main@main.go:21")
Видит. Все наши функции имеют префикс main, как и ожидается.
Давайте попробуем замерить время работы наших двух функций и вывести результаты в виде гистограммы.
Напишем следующий простой скрипт на SystemTap-языке. Он запоминает время на входе в функцию, замеряет время на выходе, вычисляет разницу и сохраняет ее. После завершения работы он эту информацию печатает.
global etime
global intervals
probe $1.call {
etime = gettimeofday_ns()
}
probe $1.return {
intervals <<< (gettimeofday_ns() - etime)/1000
}
probe end {
printf("Duration min:%dus avg:%dus max:%dus count:%d\n",
@min(intervals), @avg(intervals), @max(intervals),
@count(intervals))
printf("Duration (us):\n")
print(@hist_log(intervals));
printf("\n")
}
Запустим программу в одном терминале и stap — в другом.
$ sudo stap main.stap 'process("systemtap").function("main.UsingSubstring")'
^CDuration min:0us avg:1us max:586us count:1628362
Duration (us):
value |-------------------------------------------------- count
0 | 10
1 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 1443040
2 |@@@@@ 173089
4 | 6982
8 | 4321
16 | 631
32 | 197
64 | 74
128 | 13
256 | 4
512 | 1
1024 | 0
2048 | 0
Мы получили результат, но программа при этом упала с ошибкой, проработав совсем чуть-чуть.
$ ./systemtap
runtime: unexpected return pc for main.UsingSubstring called from 0x7fffffffe000
fatal error: unknown caller pc
runtime stack:
runtime.throw(0x494e40, 0x11)
/home/marko/go/src/runtime/panic.go:566 +0x8b
runtime.gentraceback(0xffffffffffffffff, 0xc8200337a8, 0x0, 0xc820001d40, 0x0, 0x0, 0x7fffffff, 0x7fff2fa88030, 0x0, 0x0, ...)
/home/marko/go/src/runtime/traceback.go:311 +0x138c
runtime.scanstack(0xc820001d40)
/home/marko/go/src/runtime/mgcmark.go:755 +0x249
runtime.scang(0xc820001d40)
/home/marko/go/src/runtime/proc.go:836 +0x132
runtime.markroot.func1()
/home/marko/go/src/runtime/mgcmark.go:234 +0x55
runtime.systemstack(0x4e4f00)
/home/marko/go/src/runtime/asm_amd64.s:298 +0x79
runtime.mstart()
/home/marko/go/src/runtime/proc.go:1087
Я нашел ветку про это на go-nuts, и решения пока нет. Cудя по всему, то, как SystemTap изменяет код программы, чтобы перехватывать функции, не нравится Go runtime при получении стек-трейса в GC.
Такая же проблема присутствует и в C++ при обработке исключений. Uretprobes не идеальна.
Хорошо, но получается, что если не использовать .return пробу, то все в порядке? Попробуем.
Вот программа, которая берет случайные числа, преобразует их в строку и кладет в буфер:
package main
import (
"bytes"
"fmt"
"math/rand"
"time"
)
func ToString(number int) string {
return fmt.Sprintf("%d", number)
}
func main() {
r := rand.New(rand.NewSource(time.Now().UnixNano()))
var buf bytes.Buffer
for i := 0; i < 1000; i++ {
value := r.Int() % 1000
value = value - 500
buf.WriteString(ToString(value))
}
}
Напишем скриптик, строящий распределение чисел, которые мы преобразовываем в строку.
global intervals
probe process("systemtap02").function("main.ToString").call {
intervals <<< $number
}
probe end {
printf("Variables min:%dus avg:%dus max:%dus count:%d\n",
@min(intervals), @avg(intervals), @max(intervals),
@count(intervals))
printf("Variables:\n")
print(@hist_log(intervals));
printf("\n")
}
Программа, в отличие от предыдущей, не использует .return-пробу, но зато берет и использует аргумент number.
Запустим и посмотрим, что получилось:
$ sudo stap main.stap -c ./systemtap02
Variables min:-499us avg:8us max:497us count:1000
Variables:
value |-------------------------------------------------- count
-1024 | 0
-512 | 0
-256 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 249
-128 |@@@@@@@@@@@@@@@@@@@@ 121
-64 |@@@@@@@@@@ 60
-32 |@@@@@@ 36
-16 |@@ 12
-8 |@ 8
-4 | 5
-2 | 3
-1 | 2
0 | 2
1 | 2
2 | 3
4 |@ 7
8 | 4
16 |@@@ 20
32 |@@@@@ 33
64 |@@@@@@@ 44
128 |@@@@@@@@@@@@@@@@@@ 110
256 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 279
512 | 0
1024 | 0
У нас получился красивый график с распределением.
Perf
Утилита perf и подсистема perf_events являются на данный момент профайлером по умолчанию в Linux. Исходники и разработка проходят в основном репозитории ядра и идут вровень с ядром.
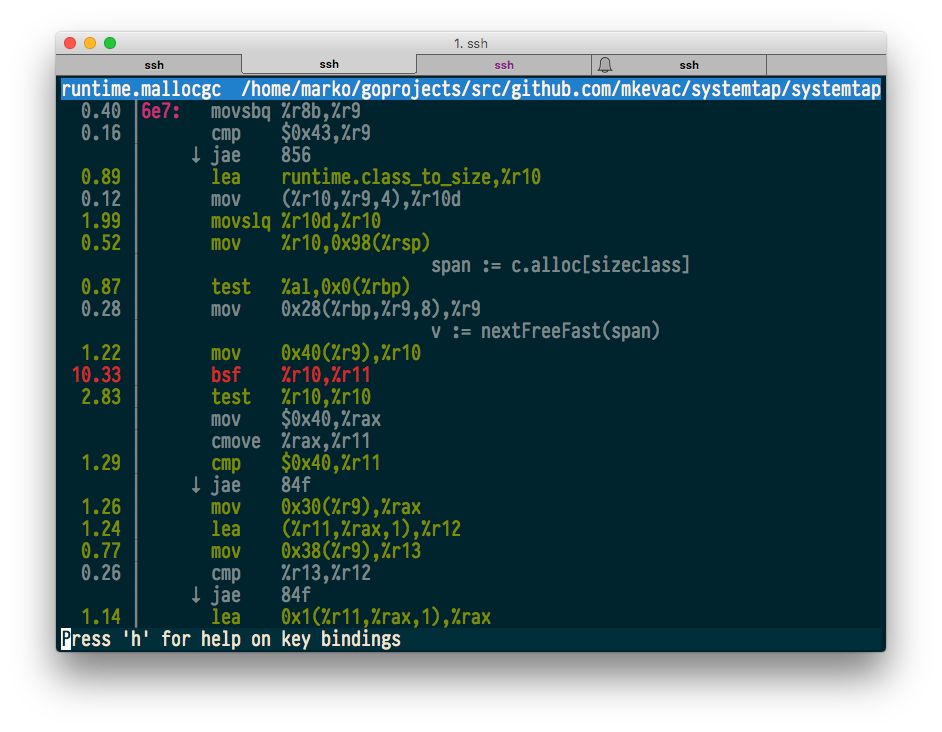
perf top — команда, которая, аналогично top, в реальном времени показывает самый «горячий» код. Запустим нашу тестовую программу и посмотрим, что покажет perf top.
$ sudo perf top -p $(pidof systemtap)
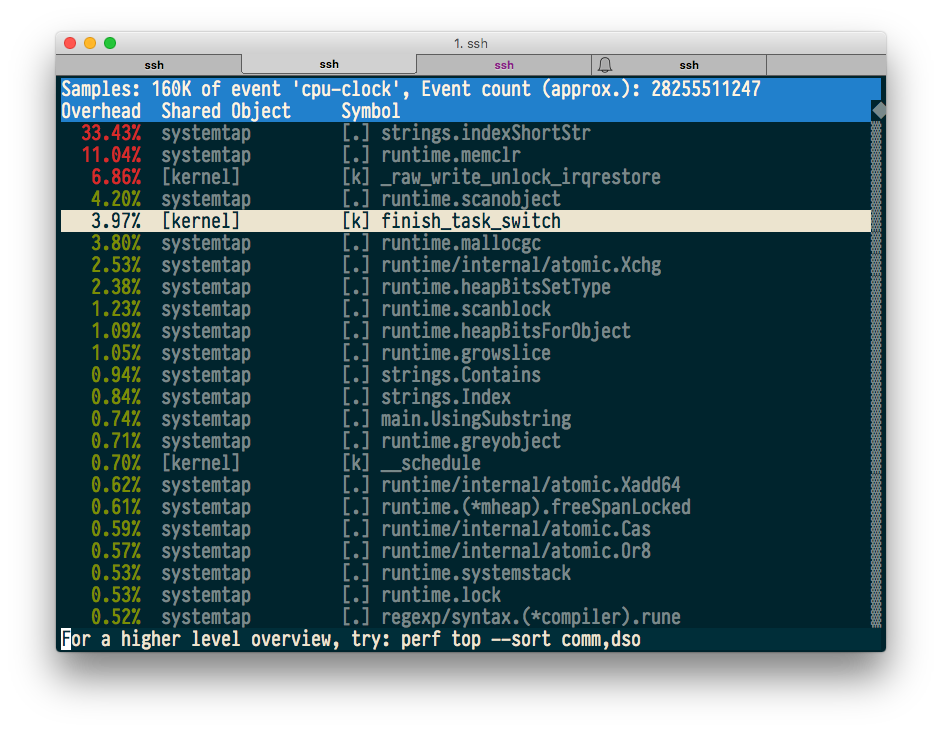
Похоже, все отлично, и даже работают аннотации с исходным и машинным кодом.
Попробуем теперь построить так называемый FlameGraph, который был популяризован Бренданом Греггом (англ. Brendan Gregg). Брендан сейчас работает в Netflix и является одним из основных популяризаторов и «двигателем» инноваций в области профилирования для Linux.
Опять же, запустим программу и соберем стек-трейсы за 10 секунд в файл:
$ sudo perf record -F 99 -g -p $(pidof systemtap) -- sleep 10
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.149 MB perf.data (1719 samples) ]
Воспользуемся утилитами от Брендана для преобразования данных perf в FlameGraph.
$ sudo perf script | ~/tmp/FlameGraph/stackcollapse-perf.pl > out.perf-folded
$ ~/tmp/FlameGraph/flamegraph.pl out.perf-folded > perf-kernel.svg
И вот что у нас получилось:
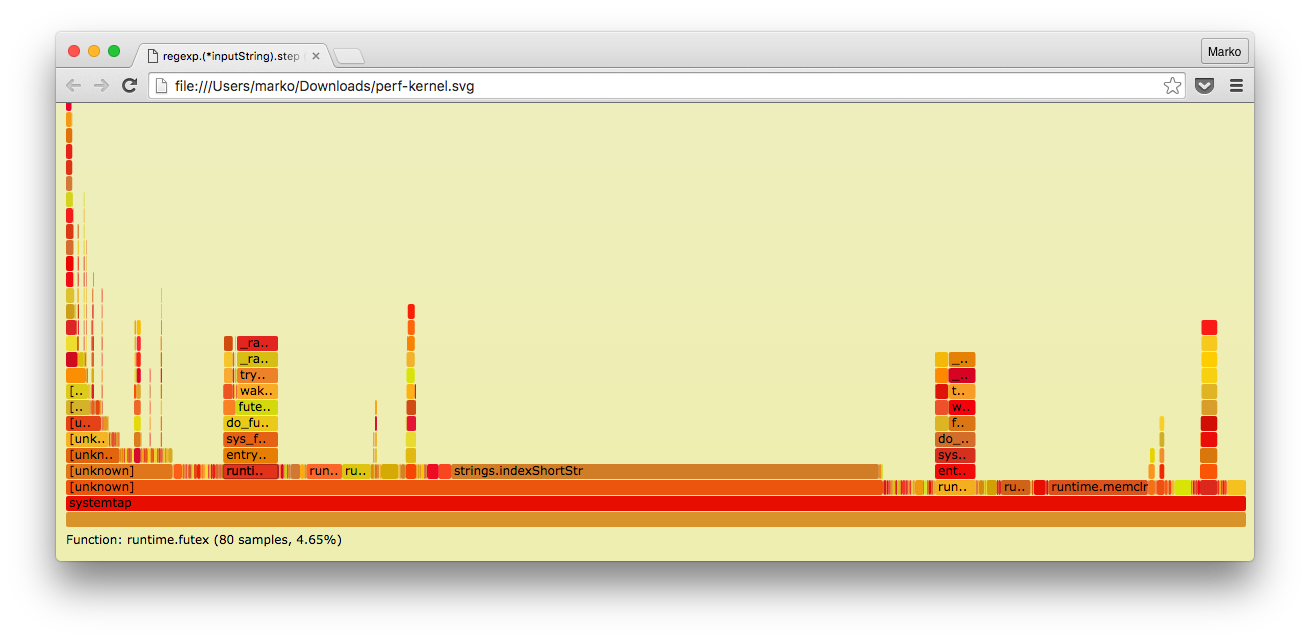
Как видно, в отличие от встроенного в Go профайлера, здесь у нас есть и стек-трейс ядра.
Память
Если бы мы программировали на С или С++, как бы мы профилировали использование памяти?
В мире С/C++ есть Valgrind — утилита, которая предназначена для поиска ошибок при использовании памяти: утечка, выход за границу массива, использование уже освобожденной памяти и много еще чего. Все это нам не нужно, т.к. в Go отсутствие таких проблем гарантировано (кроме случая использования cgo, конечно).
Но Valgrind еще и умеет показывать потребление памяти в виде удобного временного графика с помощью встроенной подсистемы Massif.
Если взять простенькую программу на С, которая просто выделяет, а потом освобождает 20 MiB памяти
#include
#include
#include
int main() {
const size_t MB = 1024*1024;
const unsigned count = 20;
char **buf = calloc(count, sizeof(*buf));
for (unsigned i = 0; i < count; i++) {
buf[i] = calloc(1, MB);
memset(buf[i], 0xFF, MB);
sleep(1);
}
for (unsigned i = 0; i < count; i++) {
free(buf[i]);
sleep(1);
}
free(buf);
}
и запустить ее под Massif, то мы получим примерно такой график с стек-трейсами в тех местах, где были инициированы выделения памяти:
--------------------------------------------------------------------------------
Command: ./main
Massif arguments: --pages-as-heap=yes --time-unit=ms
ms_print arguments: massif.out.15091
--------------------------------------------------------------------------------
MB
26.20^ ::
| ::: #
| @@: : #::
| ::@ : : #: ::
| ::::: @ : : #: : ::::
| :: : : @ : : #: : : : ::
| :::: : : @ : : #: : : : : :
| ::::: :: : : @ : : #: : : : : :::::
| ::: : : :: : : @ : : #: : : : : :: : @@
| ::: : : : :: : : @ : : #: : : : : :: : @ ::
| ::@: : : : : :: : : @ : : #: : : : : :: : @ : :::
| ::: @: : : : : :: : : @ : : #: : : : : :: : @ : : :::
| ::: : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: ::
| ::: : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : ::
| ::::: : : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : : ::::
|:: : : : : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : : : : :
|@: : : : : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : : : : :@
|@: : : : : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : : : : :@
|@: : : : : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : : : : :@
|@: : : : : : @: : : : : :: : : @ : : #: : : : : :: : @ : : :: : : : : :@
0 +----------------------------------------------------------------------->s
0 39.13
Number of snapshots: 66
Detailed snapshots: [9, 10, 20, 22, 32, 42, 45 (peak), 55, 65]
Работает Massif таким образом, что переопределяет основные функции для работы с памятью (malloc, calloc, realloc, memalign, new, new[]) на свои.
Go же не использует ни одну из этих функций. В исходниках Go реализован собственный аллокатор, который запрашивает память напрямую у ОС с помощью системных вызовов mmap или sbrk, и уже ее разбивает самостоятельно на более мелкие кусочки.
Valgrind умеет ловить mmap/sbrk, если его попросить специальным параметром командной строки, но это все равно бесполезно, т.к., во-первых, мы не увидим эти самые более мелкие выделения и освобождения и, во-вторых, мы не сможем понять, к какой памяти уже нет ссылок, а какая все еще «живая».
Другие распространенные утилиты в мире С/C++ тоже практически бесполезны, т.к. большинство из них работает аналогичным образом, т.е. путем перехвата функций выделения и освобождения памяти.
Варианта, по сути, два:
- теоретически мы можем перехватывать функции выделения и освобождения памяти из Go runtime чем-то внешним по отношению к Go-программе (например, perf или SystemTap) и попробовать что-то понять на основе этих вызовов;
- использовать встроенный в Go runtime-учет использования памяти.
Go умеет собирать информацию о выделениях памяти с определенной периодичностью. Эту периодичность можно задавать вручную, но по умолчанию она составляет 1 раз на 512 килобайт выделенной памяти.
Как обычно, давайте посмотрим на пример.
Пример
Аналогично процессорному профилированию, профилирование памяти можно запускать, используя go test, прямые вызовы runtime.MemProfile () или с помощью пакета net/http/pprof. В этот раз давайте воспользуемся последним вариантом.
Итак, перед вами программа, которая в одной из горутин постоянно выделяет массивы и сохраняет их в другом массиве, а в другой горутине делает то же самое, но периодически «забывает» про массив массивов:
package main
import (
"net/http"
_ "net/http/pprof"
"time"
)
func allocAndKeep() {
var b [][]byte
for {
b = append(b, make([]byte, 1024))
time.Sleep(time.Millisecond)
}
}
func allocAndLeave() {
var b [][]byte
for {
b = append(b, make([]byte, 1024))
if len(b) == 20 {
b = nil
}
time.Sleep(time.Millisecond)
}
}
func main() {
go allocAndKeep()
go allocAndLeave()
http.ListenAndServe("0.0.0.0:8080", nil)
}
Т.е. мы ожидаем, что одна из функций вызывает постоянный рост потребления памяти, а другая постоянно генерирует мусор для сборщика, но рост не вызывает.
Давайте посмотрим, что говорит профайлер.
В случае профилирования памяти для go tool pprof есть четыре основных параметра, о которых нужно знать:
- alloc_space — количество аллоцированных байт;
- alloc_objects — количество аллоцированных объектов;
- inuse_space — количество живых байт;
- inuse_objects — количество живых объектов.
Первые два показывают количество всех аллокаций в байтах и объектах, а вторые — только количество живых аллокаций в текущий момент.
В данном случае мы ожидаем, что inuse покажет только функцию allocAndKeep (), , а alloc покажет обе функции:
$ go tool pprof -inuse_space memtest http://localhost:8080/debug/pprof/heap
Fetching profile from http://localhost:8080/debug/pprof/heap
Saved profile in /home/marko/pprof/pprof.memtest.localhost:8080.inuse_objects.inuse_space.005.pb.gz
Entering interactive mode (type "help" for commands)
(pprof) top
15.36MB of 15.36MB total ( 100%)
Dropped 2 nodes (cum <= 0.08MB)
flat flat% sum% cum cum%
15.36MB 100% 100% 15.36MB 100% main.allocAndKeep
0 0% 100% 15.36MB 100% runtime.goexit
$ go tool pprof -alloc_space memtest http://localhost:8080/debug/pprof/heap
Fetching profile from http://localhost:8080/debug/pprof/heap
Saved profile in /home/marko/pprof/pprof.memtest.localhost:8080.alloc_objects.alloc_space.008.pb.gz
Entering interactive mode (type "help" for commands)
(pprof) top
54.49MB of 54.49MB total ( 100%)
Dropped 8 nodes (cum <= 0.27MB)
flat flat% sum% cum cum%
27.97MB 51.33% 51.33% 29.47MB 54.08% main.allocAndKeep
23.52MB 43.17% 94.49% 25.02MB 45.92% main.allocAndLeave
3MB 5.51% 100% 3MB 5.51% time.Sleep
0 0% 100% 54.49MB 100% runtime.goexit
Похоже на правду. Но мы также видим, что наш Sleep () почему-то тоже выделяет память. Рассмотрим подробнее.
(pprof) list time.Sleep
Total: 54.49MB
ROUTINE ======================== time.Sleep in /home/marko/go/src/runtime/time.go
3MB 3MB (flat, cum) 5.51% of Total
. . 48:func timeSleep(ns int64) {
. . 49: if ns <= 0 {
. . 50: return
. . 51: }
. . 52:
3MB 3MB 53: t := new(timer)
. . 54: t.when = nanotime() + ns
. . 55: t.f = goroutineReady
. . 56: t.arg = getg()
. . 57: lock(&timers.lock)
. . 58: addtimerLocked(t)
Да, как оказалось, встроенная функция time.Sleep () явно выделяет память командой new ().
Неявное выделение (1)
Вроде бы все просто в случае, когда явно видно, что вот оно — выделение памяти. Но давайте рассмотрим пару примеров, когда выделение не совсем очевидно.
Возьмем простенький пример, где мы заполняем буфер строчками.
package printtest
import (
"bytes"
"fmt"
"testing"
)
func BenchmarkPrint(b *testing.B) {
var buf bytes.Buffer
var s string = "test string"
for i := 0; i < b.N; i++ {
buf.Reset()
fmt.Fprintf(&buf, "string is: %s", s)
}
}
В данном примере мы заполняем буфер с помощью функции fmt.Fprintf ().
Бенчмарк с параметром -benchmem говорит утилите test выводить в том числе и количество аллокаций.
$ go test -bench=. -benchmem
testing: warning: no tests to run
BenchmarkPrint-8 10000000 128 ns/op 16 B/op 1 allocs/op
PASS
ok github.com/mkevac/converttest 1.420s
Итак, у нас 1 аллокация на операцию размером в 16 байт. Что это за аллокация?
Запустим профайлер следующей командой:
$ go test -bench=. -memprofile=mem.out -memprofilerate=1
Здесь memprofilerate задает частоту, с которой программа будет сохранять информацию об аллокациях. Единица в данном случае говорит о том, что сохранять надо все до единой аллокации. Разумеется, в продакшене такая частота будет губительна для производительности. Но сейчас можно.
Посмотрим на выделения следующей командой:
$ go tool pprof -alloc_space converttest.test mem.out
(pprof) top
15.41MB of 15.48MB total (99.59%)
Dropped 73 nodes (cum <= 0.08MB)
flat flat% sum% cum cum%
15.41MB 99.59% 99.59% 15.43MB 99.67% github.com/mkevac/converttest.BenchmarkPrint
0 0% 99.59% 15.47MB 99.93% runtime.goexit
0 0% 99.59% 15.42MB 99.66% testing.(*B).launch
0 0% 99.59% 15.43MB 99.67% testing.(*B).runN
Так, наша функция выделила в сумме 15 MiB памяти. Где?
(pprof) list BenchmarkPrint
Total: 15.48MB
ROUTINE ======================== github.com/mkevac/converttest.BenchmarkPrint in /home/marko/goprojects/src/github.com/mkevac/converttest/convert_test.go
15.41MB 15.43MB (flat, cum) 99.67% of Total
. . 9:func BenchmarkPrint(b *testing.B) {
. . 10: var buf bytes.Buffer
. . 11: var s string = "test string"
. . 12: for i := 0; i < b.N; i++ {
. . 13: buf.Reset()
15.41MB 15.43MB 14: fmt.Fprintf(&buf, "string is: %s", s)
. . 15: }
. . 16:}
Все произошло в функции fmt.Fprintf (). Хорошо. А где?
(pprof) list fmt.Fprintf
Total: 15.48MB
ROUTINE ======================== fmt.Fprintf in /home/marko/go/src/fmt/print.go
0 12.02kB (flat, cum) 0.076% of Total
. . 175:// These routines end in 'f' and take a format string.
. . 176:
. . 177:// Fprintf formats according to a format specifier and writes to w.
. . 178:// It returns the number of bytes written and any write error encountered.
. . 179:func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) {
. 11.55kB 180: p := newPrinter()
. 480B 181: p.doPrintf(format, a)
. . 182: n, err = w.Write(p.buf)
. . 183: p.free()
. . 184: return
. . 185:}
. . 186:
Вот где. А, нет, погодите… Что-то с цифрами не то. До этого мы видели 15 мегабайт, а здесь 12 килобайт. Что-то не сходится.
Посмотрим на нашу функцию в дизасемблированном виде:
. . 466edb: CALL bytes.(*Buffer).Reset(SB)
. . 466ee0: LEAQ 0x98b6b(IP), AX
. . 466ee7: MOVQ AX, 0x70(SP)
. . 466eec: MOVQ $0xb, 0x78(SP)
. . 466ef5: MOVQ $0x0, 0x60(SP)
. . 466efe: MOVQ $0x0, 0x68(SP)
. . 466f07: LEAQ 0x70d92(IP), AX
. . 466f0e: MOVQ AX, 0(SP)
. . 466f12: LEAQ 0x70(SP), AX
. . 466f17: MOVQ AX, 0x8(SP)
. . 466f1c: MOVQ $0x0, 0x10(SP)
15.41MB 15.41MB 466f25: CALL runtime.convT2E(SB)
. . 466f2a: MOVQ 0x18(SP), AX
. . 466f2f: MOVQ 0x20(SP), CX
. . 466f34: MOVQ AX, 0x60(SP)
. . 466f39: MOVQ CX, 0x68(SP)
. . 466f3e: LEAQ 0x10b35b(IP), AX
. . 466f45: MOVQ AX, 0(SP)
. . 466f49: MOVQ 0x58(SP), AX
. . 466f4e: MOVQ AX, 0x8(SP)
. . 466f53: LEAQ 0x99046(IP), CX
. . 466f5a: MOVQ CX, 0x10(SP)
. . 466f5f: MOVQ $0xd, 0x18(SP)
. . 466f68: LEAQ 0x60(SP), CX
. . 466f6d: MOVQ CX, 0x20(SP)
. . 466f72: MOVQ $0x1, 0x28(SP)
. . 466f7b: MOVQ $0x1, 0x30(SP)
. 12.02kB 466f84: CALL fmt.Fprintf(SB)
Какая-то функция runtime.convT2E выделила всю эту память. Что это?
Давайте посмотрим на то, как определена функция fmt.Fprintf ():
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
Поскольку функция должна принимать любой тип, ее аргументы определены как пустой интерфейс. Пустой интерфейс, по сути, это аналог void* в С.
Но мы не можем просто «скастовать» все что угодно в интерфейс, т.к. мы потеряем информацию о типе. Все что угодно в интерфейс надо преобразовать, и это преобразование иногда требует дополнительной памяти? Почему? Давайте погрузимся немного глубже в типы языка Go.
В Go существуют встроенные типы, такие как string, chan, func, slice, interface и т.д. Каждый из них имеет в памяти определенную структуру.
Давайте посмотрим, что представляет из себя string, т.к. именно этот случай мы рассматриваем:
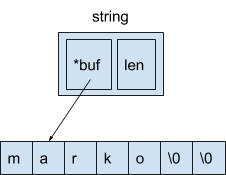
Строка — это 16 байт. Первые 8 байт — указатель на иммутабельный массив, в котором, собственно, лежит строчка, а вторые 8 байт — длина строки.
А теперь посмотрим на interface. Interface в памяти тоже представляет собой два 8-байтных куска.

Первые 8 байт — указатель на внутреннюю структуру, содержащую информацию о типе, а вторые 8 байт — собственно указатель на объект.
Если бы мы сделали
var s string = "marko"
var a interface{} = &s
то никакой дополнительной памяти нам не нужно, ведь мы можем сразу во вторые 8 байт интерфейса положить указатель на строку.
Но это не наш случай. Мы приравниваем к интерфейсу не указатель, а значение:
var s string = "marko"
var a interface{} = s
В таком случае Go приходится выделить дополнительную промежуточную структуру с помощью функции runtime.convT2E.
Результат выглядит следующим образом:
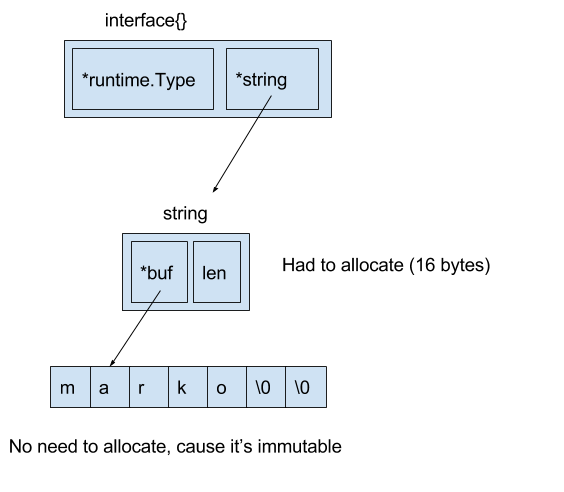
Именно эти 16 байт мы видели в выводе go test.
Давайте теперь попробуем избавиться от этого «лишнего» выделения памяти.
Мы заменяем fmt.Fprintf на последовательную запись в буфер конкретно строк:
package main
import (
"bytes"
"testing"
)
func BenchmarkPrint(b *testing.B) {
var buf bytes.Buffer
var s string = "test string"
for i := 0; i < b.N; i++ {
buf.Reset()
buf.WriteString("string is: ")
buf.WriteString(s)
}
}
И ожидаемо получим 0 выделений:
$ go test -bench=BenchmarkPrint -benchmem
testing: warning: no tests to run
BenchmarkPrint-8 50000000 27.5 ns/op 0 B/op 0 allocs/op
PASS
ok github.com/mkevac/converttest01 1.413s
Заодно код ускорился в 4 раза.
Неявное выделение (2)
Второй пример должен быть близок «сишникам» и тем, кто использует cgo. Ведь в С строка (char *) и массив байт — это, по сути, одно и то же. Можно безболезненно конвертировать одно в другое, разве что о нулевом байте в конце позаботиться.
В Go, как мы уже видели, это не так. Строка — это не просто указатель на массив, это также и длина.
Поэтому простенькая программа типа
package main
import (
"fmt"
)
func main() {
var array = []byte{'m', 'a', 'r', 'k', 'o'}
if string(array) == "marko" {
fmt.Println("equal")
}
}
приводила к выделению памяти, чтобы преобразовать массив в строку. На самом деле это так и было до недавнего времени. git-blame говорит, что Дмитрий Вьюков починил этот кейс. А точнее, сделал так, что если наша переменная не используется за пределами функции (do not escapes to heap), то можно выделить память для нее на стеке, а не в куче.
Этот кейс очень хорошо подводит нас к важной мысли. Любые оптимизации, которые мы делаем, любые нюансы, о которых мы знаем, в ближайшее время могут устареть. Разработчики языка ежедневно улучшают компилятор и runtime. Я надеюсь, что моя статья даст вам достаточно инструментов, чтобы вы могли проверять свои гипотезы, добираться до сути, а не бездумно следовать советам из интернета 2010 года, которые могут быть не только бесполезны, но и вредны в текущий момент.
Но вернемся к нашему примеру.
Чтобы все-таки привести пример, мне пришлось немного обмануть Go-компилятор и убедить его, что строка escapes to heap.
Давайте посмотрим на него:
package main
import (
"bytes"
"testing"
"unsafe"
)
var s string
func BenchmarkConvert(b *testing.B) {
var buf bytes.Buffer
var array = []byte{'m', 'a', 'r', 'k', 'o', 0}
for i := 0; i < b.N; i++ {
buf.Reset()
s = string(array)
buf.WriteString(s)
}
}
$ go test -bench=. -benchmem
testing: warning: no tests to run
BenchmarkConvert-8 30000000 42.1 ns/op 8 B/op 1 allocs/op
Так
