Профессиональный Postgres
Мы продолжаем публиковать видео и расшифровки лучших докладов с конференции PGConf.Russia 2019. Доклад Олега Бартунова на тему «Профессиональный Postgres» открывал пленарную часть конференции. В нем раскрыта история СУБД Postgres, российский вклад в разработку, особенности архитектуры.
Предыдущие материалы этой серии: «Типичные ошибки при работе с PostgreSQL» Ивана Фролкова, части 1 и 2.

Я буду рассказывать про профессиональный Postgres. Прошу не путать с компанией, которую я представляю сейчас — Postgres Professional.

Я действительно буду говорить о том, как Postgres, начинавшийся как любительская академическая разработка, стал профессиональным — таким, как мы его видим сейчас. Выскажу исключительно свое персональное мнение, оно не отражает мнение ни нашей компании, ни каких-либо групп.
Так получилось, что я использую и занимаюсь Postgres не урывками, а непрерывно с 1995-го года по сегодняшний день. Вся его история прошла на моих глазах, я участник основных событий.
История
На этом слайде я кратко обозначил те проекты, в которых принимал участие. Многие из них вам знакомы. А историю Postgres начну сразу с картинки, которую я нарисовал много-много лет назад и потом ее только дорисовывал — число версий всё увеличивается и увеличивается. Она отражает эволюцию реляционных баз данных. Слева, если кто не знает, это Майкл Стоунбрейкер, которого называют отцом Postgres. Внизу наши первые «ядерные» разработчики. Человек сидящий справа — это Вадим Михеев из Красноярска, он был одним из первых core-разработчиков.
Начну рассказ о реляционной модели с IBM, которая внесла гигантский вклад в индустрию. Именно в IBM работал Эдгар Кодд, из ее недр появилась первая white paper по IBM System R — это была первая реляционная база. Майк Стоунбрейкер работал в то время в Бёркли. Он прочитал эту статью и вместе со своими ребятами загорелся: надо сделать базу данных.

В те годы — в начале 70-х годов — как вы подозреваете, компьютеров было не много. На всё отделение Computer science университета Бёркли была одна PDP-11, и все студенты и преподаватели дрались за машинное время. В основном эта машина использовалась для расчетов. Я сам так работал, когда был молодым: отдаешь оператору задачу, он ее запускает. Но студенты и разработчики хотели интерактивной работы. Это была наша мечта — сидеть за пультом, вводить программы, отлаживать их. И когда Майк Стоунбрейкер со своими приятелями сделали первую базу, они назвали ее Ingres — INteractive Grafic REtrieval System. Люди не понимали: почему interactive? А это просто реализовалась мечта ее разработчиков. У них был консольный клиент, с помощью которого можно было работать с Ingres-ом. Он дал очень много нашей индустрии. Вы видите, сколько там стрелочек от Ingres? Это те базы данных, на которые он повлиял, которые шарили его код. У Майкла Стоунбрейкера было очень много учеников-разработчиков, которые ушли и разработали потом Sybase и MS SQL, NonStop SQL, Illustra, Informix.
Когда Ingres развился настолько, что стал интересным с коммерческой точки зрения, образовалась компания Illustra (это был 1992-й год), и код СУБД Illustra был куплен компанией Informix, которая была позже съедена IBM, и таким образом этот код ушел в DB2. Но что заинтересовало IBM в Ingres? В первую очередь расширяемость — те революционные идеи, которые Майкл Стоунбрейкер заложил с самого начала, думая о том, что база данных должна быть готова к решению любых бизнес-задач. А для этого нужно, чтобы в базу можно было добавить свои типы данных, access-методы и функции. Сейчас нам, постгресистам, это кажется естественным. В те годы это была революция. Именно со времен Ingres и Postgres эти фичи, эта функциональность стали де-факто стандартом для всех реляционных баз данных. Сейчас все базы данных имеют пользовательские функции, а когда Стоунбрейкер писал, что пользовательские функции нужны, компания Oracle, например, кричала о том, что это опасно, и что так делать нельзя потому, что пользователи могут навредить данным. Сейчас мы видим, что пользовательские функции существуют во всех базах данных, что можно делать свои агрегаты и типы данных.

Postgres развивался как академическая разработка, а это значит: есть профессор, у него есть грант на разработку, студенты и аспиранты, которые с ним работают. Серьезную базу, готовую для продакшн, так сделать нельзя. Тем не менее в последнюю версию из Бёркли — Postgres95 — уже был добавлен язык SQL. Студенты-разработчики в это время уже стали работать в компании Illustra, делали Informix и потеряли интерес к проекту. Они сказали: у нас есть Postgres95, забирайте его, кому нужно! Я это всё прекрасно помню потому, что сам был одним из тех, кто получил это письмо: был mailing list, а в нем меньше 400 человек подписчиков. Сообщество Postgres95 начиналось с этих 400 человек. Мы все дружно проголосовали за то, что берем этот проект. У нас нашелся энтузиаст, который поднял CVS-сервер, и мы перетащили всё в Панаму, так как серверы были там.
История PostgreSQL [дальше просто Postgres] начинается с версии 6.0, так как версии 1, 4, 5 были еще Postgres95. В 1997-м году 3 апреля появился наш логотип — слон. До этого у нас были разные животные. У меня на страничке, например, долгое время был гепард, намекавший, что Postgres очень быстрый. Потом в mailing list-е подняли вопрос: нашей большой базе данных нужно серьезное животное. И кто-то написал: давайте это будет слон. Все дружно проголосовали, потом наши ребята из Санкт-Петербурга нарисовали этот логотип. Изначально это был слон в алмазе — если поковыряетесь в машине времени, то увидите его. Слона выбрали потому, что у слонов очень хорошая память. Даже у Агаты Кристи есть такая повесть «Слоны могут помнить»: там слон очень мстительный, лет пятьдесят он помнил обиду, а потом задавил обидчика. Бриллиант потом откололи, рисунок векторизовали, и в результате получился вот этот слон. Так что это один из первых российских вкладов в Postgres.
 Гепарда сменил Слоник в бриллианте:
Гепарда сменил Слоник в бриллианте: 
Этапы развития Postgres
Первой задачей была стабилизация его работы. Сообщество переняло исходные коды академических разработчиков. Чего там только не было! Начали всё это перелопачивать, чтобы компилировалось прилично. Я выделил на этом слайде 1997-й год, версию 6.1 — в ней появилась интернационализация. Выделил не потому, что я сам это делал (это действительно был мой первый патч), а потому, что важный этап. Вы уже привыкли, что Postgres работает с любым языком, в любых локалях — во всем мире. А тогда он понимал только ASCII, то есть никаких 8-х битов, никаких европейских языков, никакого русского. Обнаружив это, я, следуя принципам open-source, просто взял и сделал поддержку локалей. И благодаря этой работе Postgres пошел в мир. После меня японец Тацуо Ишии [Tatsuo Ishii] сделал поддержку мультибайтных кодировок, и Postgres стал по-настоящему всемирным.
В 2005-м году была введена поддержка Windows. Я помню эти горячие споры, когда в mailing list-е это обсуждали. Все разработчики были нормальные люди, они работали под Unix. Вы вот сейчас хлопаете, и точно так же народ реагировал и тогда. И голосовал против. Это длилась годами. Более того, SRA Computers выпустили на несколько лет раньше свой Powergres — нативный порт на Windows. Но это было чисто японское изделие. Когда в 2005-м году в 8-й версии у нас появилась поддержка Windows, оказалось, что это сильный шаг: сообщество распухло. Появилось очень много людей и очень много глупых вопросов, но сообщество стало большое, мы схватили виндузовых пользователей.
В 2010-м году у нас появилась встроенная репликация. Это — боль. Я помню, сколько лет люди боролись за то, чтобы репликация была в Postgres. Сначала все говорили: нам не нужна репликация, это не дело базы данных, это дело внешних утилит. Если кто помнит, Slony сделал Ян Вик [Jan Wieck]. Кстати, «слони» тоже из русского языка пришли: Ян спросил меня, как будет по-русски «много слонов», и я ответил: «слоны». Вот он и сделал Slony. Эти слоны работали как логическая репликация на триггерах, настройка их была кошмаром — ветераны помнят. Более того, все долго слушали Тома Лейна [Tom Lane], который, помню, отчаянно кричал: зачем нам усложнять код репликацией, если это можно сделать снаружи базы? Но в результате встроенная репликация все-таки появилась. Это дало сразу колоссальное количество enterprise-пользователей потому, что до этого такие пользователи говорили: как нам вообще жить без репликации? Это невозможно!
В 2014-м году появился jsonb. Это работа моя, Федора Сигаева и Александра Короткова. И тоже народ кричал: зачем нам это нужно? Вообще, у нас уже был hstore, который мы сделали 2003-м году, а 2006-м он вошел в Postgres. Люди им прекрасно пользовались по всему миру, любили его, и, если в google набрать hstore, появлялось гигантское количество документов. Очень популярное расширение. И мы всячески пропагандировали идею неструктурированных данных в Postgres. С самого начала моей работы я как раз этим интересовался и, когда мы сделали jsonb, я получил массу писем с благодарностями и вопросами. А сообщество получило NoSQL-пользователей! До jsonb люди, зомбированые хайпом, шли в key-value базы данных. При этом они вынуждены были жертвовать целостностью, ACID-ностью. А мы им дали возможность, ничем не жертвуя, работать с их прекрасным json-ом. Комьюнити опять резко выросло.
В 2016-м году у нас появилось параллельное выполнение запросов. Если кто не знает, это, конечно, не для OLTP. Если у вас загруженная машина, то все ядра и так заняты. Параллельное выполнение запросов ценно для OLAP-пользователей. И они это оценили, то есть в сообщество начало прибывать и какое-то количество OLAP-юзеров.
Дальше шли накопительные процессы. В 2017-м году мы получили логическую репликацию и декларативное партицирование — это был тоже большой и серьезный шаг потому, что логическая репликация дала возможность делать очень и очень интересные системы, люди получили неограниченную свободу для своей фантазии и начали делать кластеры. С помощью декларативного партицирования стало возможно не вручную, а с помощью языка SQL создавать партиции.
В 2018-м году в 11-й версии мы получили JIT. Кто не знает, это Just In Time compiler: вы компилируете запросы, и это действительно может очень сильно ускорить выполнение. Это важно для ускорения медленных запросов потому, что быстрые запросы и так быстрые, а overhead на компиляцию все-таки существенный.
В 2019-м году самое основное, что мы ожидаем, это pluggable storage, API для того, чтобы разработчики могли создавать свои хранилища, один из примеров которых это zheap — хранилище, которое разрабатывает компания EnterpriseDB.
А вот и наша разработка: SQL/JSON. Я очень надеялся, что Саша Коротков закоммитит его до конференции, но там обнаружились какие-то проблемы, и мы теперь надеемся, что все-таки в этом году мы получим SQL/JSON. Люди ждут его уже два года [сейчас закоммичена значительная часть патча SQL/JSON: jsonpath, об этом написано подробно здесь].

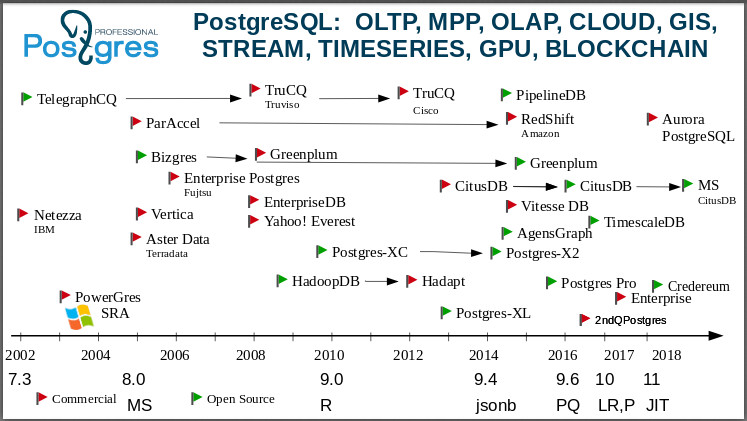
Дальше я перехожу к слайду, который показывает: Postgres — это универсальная база данных. Эту картинку можно изучать часами, рассказать кучу историй о возникновении компаний, о поглощении, о смерти компаний. Я начну с 2000-го года. Один из первых форков Postgres — IBM-овская Netezza. Вы только представьте себе: «Голубой гигант» взял код Postgres и соорудил для поддержки своих BI базу для OLAP!
Вот форк TelegraphCQ: уже в 2000-м году на основе Postgres в Бёркли люди делали стриминговую базу данных. Если кто не знает, это база данных, которая не интересуется самими данными, а интересуются их агрегатами. Сейчас очень много задач, где не нужно знать каждое значение, допустим, температуру в какой-то точке, а нужно среднее значение в данном регионе. И в TelegraphCQ взяли эту идею (возникшую тоже в Бёркли), одну из самых передовых идей того времени, и разработали базу на основе Postgres. Дальше она эволюционировала, и в 2008-м году на ее основе выпущен был уже коммерческий продукт — база TruCQ, сейчас ее владелец Cisco.
Я забыл сказать, что на этой страничке не все форки, их в раза в два больше. Я выбрал наиболее важные и интересные, чтобы не загромождать картинку. На страничке в postgresql-вики перечислены все форки. Кто знает опенсорсную базу данных, у которой было бы столько форков? Таких баз нет.
Postgres отличается от других баз не только своей функциональностью, но и тем, что у нее
очень интересное сообщество, оно нормально принимает форки. В мире опенсорс принято считать: я сделал форк потому, что обиделся — вы меня не поддержали, вот я и решил вести собственную разработку. В постгресовом мире появление форка означает: какие то люди или какая-то компания решили сделать некоторый прототип и проверить придуманную ими функциональность, поэкспериментировать. А если повезет, то и сделать коммерческую базу, которую можно будет продавать клиентам, предоставлять им сервис и так далее. При этом, как правило, разработчики всех этих форков возвращают свои наработки и патчи в сообщество. Продукт нашей компании тоже форк, и понятно, что мы кучу патчей вернули обратно в сообщество. В последней, 11-й версии мы вернули сообществу более 100 патчей. Если посмотрите в ее release notes, то там будет 25 фамилий наших сотрудников. Это нормальное поведение в сообществе. Мы используем комьюнити-версию и делаем свой форк для того, чтобы проверять свои идеи или давать клиентам функциональность раньше, чем сообщество созреет для ее принятия. Форки в Postgres-сообществе очень даже приветствуются.
Известная Vertica возникла из C-Store — тоже выросла из Postgres. Некоторые люди утверждают, что в Vertica вообще не было исходников из Postgres, а была только поддержка постгресового протокола. Но тем не менее принято причислять ее к постгресовым форкам.
Greenplum. Сейчас вы можете скачать его и использовать как кластер. Он возник из Bizgres — массивно-параллельной базы данных. Потом она была куплена компанией Greenplum, стала и долго оставалась коммерческой. Но вы видите, что где-то в 2015-м году они поняли, что мир изменился: мир идет к открытым протоколам, к открытым сообществам, открытым базам данных. И открыли коды Greenplum. Сейчас они активно догоняют Postgres потому, что за это время отстали, конечно, очень сильно. Они отпочковались на 8.2, а сейчас говорят, что догнали 9.6.
Всеми нами любимый и нелюбимый Amazon. Вы знаете, как он возник. Это происходило на моих глазах. Была компания, был ParAccel с векторной обработкой, тоже на Postgres — продукт сообщества, открытый. В 2012-м году хитрый Amazon купил исходники и буквально через полгода объявил, что вот у нас в Amazon-е теперь есть RDS. Мы их тогда расспрашивали, они долго мялись, но потом все же выяснилось, что это Postgres. RDS до сих пор живет, и это один из самых популярных популярных сервисов Amazon-а, у них там порядка 7000 баз крутятся. Но они на этом не успокоились, и в 2010 появилась Amazon Aurora — Postgres 10 с переписанным сториджем, который вшит прямо в инфраструктуру Amazon, в их распределенное хранилище.
Посмотрите теперь на Teradata. Большая, старая добрая компания, которая занималась аналитикой, OLAP-ом. После «восьмерки» [PostgreSQL 8.0] возникла Aster Data.
Hadoop: у нас Postgres на Hadoop — HadoopDB. Через некоторое время она стала закрытой базой Hadapt, принадлежащей Teradata. Если вы увидите Hadapt, знайте, что внутри там Postgres.
Очень интересная судьба у Citus. Все знают, что это распределенный Postgres для онлайн-аналитики. Он не поддерживает транзакции. Citus Data был стартапом, а Citus была с закрытыми исходниками — отдельная база данных. Через некоторое время люди поняли, что лучше жить с сообществом, открыться. И они очень много сделали, чтобы стать просто расширением (extension) Postgres. Плюс они начали делать бизнес уже на предоставлении своих облачных услуг. Вы все уже знаете: здесь написано MS Citus потому, что Microsoft их купил, буквально недели две назад. Наверное, для того, чтобы поддержать Postgres на своей Azure, то есть Microsoft тоже играет в эти игры. У них на Azure крутится Postgres, и команда разработчиков Citus присоединилась к разработчикам MS.
Вообще в последнее время процессы покупки постгресовых компаний пошли интенсивно. Буквально после того, как Microsoft купил Citus, другая постгресовая компания — credativ — купила компанию OmniTI, чтобы усилить свое присутствие на рынке. Это две достаточно известные, добротные компании. А компания Amazon купила компанию OpenSCG. Постгресовый мир сейчас меняется, и я дальше покажу, почему такой большой интерес к Postgres.
Нашумевшая TimescaleDB тоже была отдельной базой данных, но и она теперь расширение: вы берете Postgres и устанавливаете timescaledb как расширение и получаете базу данных, которая рвет всяческие специализированные базы данных.
Еще имеется Postgres XL, имеются кластеры, которые развиваются.
Сюда вот, в 2015-й год, я поставил наш форк: Postgres Pro. У нас есть Postgres Pro Enterprise, имеется сертифицированная версия, мы поддерживаем »1С» из коробки и мы признанны компанией »1С». Если кто хочет попробовать Postgres Pro Enterprise, то можно бесплатно взять дистрибутив для тестирования, а если понадобится для работы, то вы можете его купить.
Мы сделали Credereum — прототип базы данных с поддержкой блокчейна. Теперь ждем, когда народ созреет для того, чтобы начать ее использовать.
Видите, какая большая и интересная картина. Я даже не говорю про Yehoo! Everest с колоночным хранением, с петабайтами данных в Yahoo! — это был 2008-й год. Они даже спонсировали нашу конференцию в Канаде, приезжали туда, у меня где-то даже майка оттуда имеется :)
Есть еще PipelineDB. Она тоже начиналась как база с закрытыми исходниками, а сейчас это тоже просто расширение. Мы видим, что Citus, TimescaleDB и PipelineDB это как бы отдельные базы данных, но при этом они существуют как расширения, то есть вы берете стандартный Postgres и компилите расширение. PipelineDB это продолжение идеи стримовых баз данных. Хотите работать со стримами? Берёте Postgres, берёте PipelineDB и можно работать.
Кроме того, есть расширения, которые позволяют работать с GPU. Видите заголовок? Я показал, что есть экосистема, которая охватывает большое количество разных типов данных и нагрузок. Поэтому мы говорим, что Postgres это универсальная база данных.
Любимая народом база

На следующем слайде большие имена. Все самые известные облака мира поддерживают Postgres. У нас в России Postgres поддерживают большие госкомпании. Они пользуются им, а мы их обслуживаем в качестве наших клиентов.

Сейчас уже много расширений и много приложений, поэтому Postgres хорош как база данных, с которой начинается проект. Я всегда говорю стартаперам: ребята, не надо брать NoSQL базу данных. Я понимаю, что вам очень хочется, но начните с Postgres. Если вам не будет хватать чего-то, вы всегда сможете отцепить какой-нибудь сервис и отдать его специализированной базе данных. Кроме универсальности у Postgres есть еще одно достоинство: очень либеральная лицензия BSD, которая позволит делать что угодно со своей базой данных.
Всё, что вы видите на этом слайде, доступно благодаря тому, что Postgres — расширяемая база данных, причем эта расширяемость заложена сразу, прямо в архитектуре базы данных. Когда Майкл Стоунбрейкер писал про Postgres в своей первой статье о нём (она написана им в 1984-м году, здесь я цитирую статью 1987-го года), он уже говорил о расширяемости как важнейшей составляющей функциональности базы данных. И это, как говорится, уже проверено временем. Можно добавлять свои функции, свои типы данных, операторы, индексные доступы (то есть оптимизированные access-методы), вы можете писать ваши процедуры на очень большом количестве языков. У нас имеется Foreign Data Wrapper (FDW), то есть интерфейсы для работы с разными хранилищами, файлами, можно коннектиться к Oracle, MySQL и другим базам.
Хочу привести пример из собственного личного опыта. Я работал с Postgres и, когда мне чего-то не хватало в Postgres, мы с коллегами просто добавляли эту функциональность. Нам нужно было работать, например, с русским языком, и мы сделали 8-битную локаль. Это был проект Rambler. Кстати, он был тогда в топ-5. Rambler был первым крупным мировым проектом, который встал на Postgres. Массивы в Postgres были с самого начала, но они были такие, что с ними ничего нельзя было делать, это была просто текстовая строчка, в которой хранились массивы. Мы добавили операторы, сделали индексы, и сейчас массивы это неотъемлемая часть функциональности Postgres, и многие из вас используют их, совершенно не задумываясь о том, насколько они быстро работают — и это нормально. Раньше говорили, что массивы это уже не традиционная реляционная модель, не удовлетворяет классическим нормальным формам. Сейчас люди уже привыкли пользоваться массивами.

Когда нам понадобился полнотекстовый поиск, мы его сделали. Когда нам потребовалось хранить данные разной природы, мы сделали расширение hstore, и многие люди стали его использовать: он давал возможность строить гибкие схемы БД, чтобы можно было диплоиться раньше и быстрее. Мы сделали GIN-индекс, чтобы полнотекстовый поиск работал быстро. Сделали триграммы (pg_trgm). Сделали NoSQL. И всё это на моей памяти, всё из собственных нужд.

Расширяемость как раз и делает Postgres уникальной базой, универсальной базой данных, с которой можно начинать работать и не бояться, что вы останетесь без поддержки. Посмотрите, сколько у нас здесь людей — это уже рынок! Несмотря на то, что сейчас хайп — графовые базы данных, документные базы, time series и так далее, — посмотрите: большинство по-прежнему использует реляционные базы данных. Они доминируют, это 75% рынка баз данных, а остальные — это экзотические базы данных, мелочь по сравнению с реляционными.

Если вы посмотрите соотношение баз данных open source с коммерческими, то, по
данным DB-Engines, мы увидим, что количество баз open source почти равно числу коммерческих баз. И мы видим, что open source базы данных (синяя линия) растут, а коммерческие (красная) падают. Это направление развития всего ИТ-сообщества, направление к открытости. Сейчас, конечно, неприлично ссылаться на Gartner, но я всё равно скажу: они предсказывают, что к 2022-му году 70% будут использовать открытые базы данных и до 50% существующих систем будут мигрировать на open source.
Посмотрите на вот эту пузомерку: мы видим, что Postgres названа базой данных 2018-го года. В прошлом году она тоже была 1-ая по независимым оценкам экспертов DB-Engines. Рэнкинг показывает, что Postgres действительно впереди планеты всей. Он находится в абсолютном исчислении на 4-м месте, но посмотрите, как он растет. Уверенно, хорошо. На слайде это синяя линия. Остальные — MySQL, Oracle, MS SQL — либо балансирует на своем уровне, либо начинает загибаться.

Hacker news — все вы, наверное, читаете его или Y Combinator — там периодически проводят опросы, там компании публикуют свои вакансии, и с некоторых пор ведут статистику. Вы видите, что начиная где-то с 2014-го года, Postgres опережает всех. Был 1-м MySQL, но Postgres потихоньку вырос, и теперь среди всего хакерского сообщества (в хорошем смысле слова) он тоже превалирует и растет дальше.

В Stack Overflow тоже каждый год проводят опросы. По most used наш Postgres находится на хорошем, третьем месте. По most loved — на втором. Это любимая база данных. Redis это не реляционная база данных, а из реляционных Postgres самая любимая. Я не привел здесь картинку most dreaded — самая ужасная база данных, но вы, наверно догадываетесь, кто на первом месте. «База икс», как ее любят называть в России.

Есть обзор и по России, опрос на всеми нами уважаемой конференции HighLoad++. Проводился не нами, его делал Олег Бунин. Получилось: в России Postgres база данных №1.

Мы второй раз просим HH.ru, чтобы они с нами делились статистикой по вакансиям Postgres. 9 лет назад Postgres отставал от Oracle в 10 раз, все кричали: давайте нам ораклистов. И мы видим, что в прошлом году мы сравнялись, а дальше в 2018-м году был рост. И если вы волнуетесь о том, где найти работу, то смотрите: 2 тысячи вакансий на HH.ru это Postgres. Не волнуйтесь, работы хватит.

Для того чтобы было лучше видно, я сделал картинку, где показал вакансии Postgres относительно вакансий Oracle. Было меньше единички, начиная с 2018-го они уже вровень, и сейчас Postgres-а уже стало чуть-чуть больше. Пока немного удручает, что абсолютное число вакансий Oracle тоже растет, чего в принципе не должно быть. Но, как говорится, сидим у берега реки и смотрим: когда же мимо проплывет труп врага. Мы просто делаем свое дело.

Российское сообщество Postgres
Это самое организованное сообщество в России, я больше таких не встречал. Очень много ресурсов, чатов, где мы все общаемся по делу. Мы проводим конференции — две большие конференции: в Санкт-Петербурге и в Москве, квартирники, мы участвуем во всех крупных международных конференциях, проводим курсы.

Фактически это курсы сообщества. Их подготовила наша компания, но они свободно доступны любому из вас, смотрите на youtube наш канал или зайдите на наш сайт в раздел «Образование», там для свободного скачивания лежат курсы DBA1, DBA2, DBA3, девелоперские курсы.
А сейчас мы запускаем сертификацию — это то, что просят компании, они хотят иметь сертифицированных специалистов. И работодатель будет знать: вы сертифицированный специалист.

Очень часто спрашивают:, а насколько Postgres российский? Вопрос немного неправильно поставлен: Postgres — международный. Но о российском флаге я немного скажу. Вы видите на слайде, что сделал Вадим Михеев. Тем, кто знает Postgres, понятно, что для этой базы значат MVCC, WAL, VACUUM и так далее. Это всё российский вклад. Сейчас ведущих разработчиков Postgres трое, из них двое — коммиттеры. На слайде вы видите, что сделано довольно много. Если смотреть мажорные фичи из release notes, то вы увидите наш вклад. Российский вклад есть и достаточно существенный. Мы работали с самого начала и продолжаем работать с сообществом — уже на уровне кампании.

А еще вклад компании — это книжки. У нас имеются 2 университетских курса по Postgres. Вы можете пойти в магазин и эти книжки купить, вы можете преподавать по этим курсам, сдавать экзамены и так далее. У нас имеются книжки для начинающих, которые раздаются, в том числе здесь. Очень полезная хорошая книжка. Мы ее даже перевели на английский язык.
Профессиональный Postgres
Перейдем к основному. Академический Postgres, когда он начинался, был рассчитан на несколько десятков пользователей. Комьюнити Postgres95 было меньше 400 человек. Cообщество состояло в основном из разработчиков и было еще немного пользователей. При этом — интересная деталь — разработчики были, в основном, и заказчиками, и исполнителями. Например, когда мне это было нужно, я разрабатывал для себя и, одновременно, делился со всеми. То есть комьюнити разрабатывало для комьюнити.
Начиная с 2000-го года, чуть раньше, начали появляться первые постгресовые компании: GreatBridge, 2ndQuadrant, EDB. Они уже нанимали full-time разработчиков, которые работали на сообщество. Появились первые энтерпрайзные форки и первые энтерпрайзные кастомеры. Привело это к тому, что к 2015-му году основное количество — да практически все ведущие разработчики — уже были организованы в какие-то компании. В 2015-м году образовалась наша компания: мы были последними свободными фрилансерами-разработчиками. Сейчас таких практически не осталось. Постгресовое сообщество изменилась, стало энтерпрайзным, и теперь уже эти компании драйвят разработку. Это хорошо потому, что эти компании проводят то, что необходимо энтерпрайзу. Сообщество является тормозом в хорошем смысле: оно тестирует фичи, осуждает или принимает новые фичи, оно объединяет всех нас. А Postgres стал enterprise ready, его с удовольствием используют большие компании, он стал профессиональным.

Этот слайд про будущее, как я его вижу. С появлением pluggable storage будут появляться новые хранилища: append-only, read-only, column storage — что хотите (я вот, например, мечтаю о паркетном). Будет поддержка векторных операций. Сегодня, кстати, будет доклад про них. Будет поддерживаться блокчейн. Никуда от этого не деться, раз мы переходим на цифровую экономику, на безбумажные технологии. Нужно будет использовать электронные подписи и нужно будет уметь удостоверять вашу базу данных, убеждаться, что никто ничего не подменил, и блокчейн для этого очень хорошо подходит.


Дальше: адаптивный Postgres. Это немного грустная для вас тема, но она еще довольно далека от вас. Дело в том, что DBA, вообще говоря, достаточно дорогой ресурс, и скоро базы данных не будут нуждаться в них. Базы будут достаточно умными и сами себя будут конфигурировать и подстраивать. Но это будет еще лет через десять, наверное. У нас еще много времени.

И понятно, что в Postgres будет нативная поддержка клаудов, облачных хранилищ — без этого нам просто не выжить. И, конечно, вот он, последний слайд:
ВСЁ, ЧТО ВАМ НАДО, ЭТО — POSTGRES!

Спасибо за внимание.
