Проектирование новостной ленты в социальных сетях
 Так сложилось, что за последние пару лет я успел поучаствовать в разработке нескольких социальных сетей. Главная задача, которую приходилось решать в каждом из этих проектов, заключалась в формировании новостной ленты пользователя. При чём важным условием была возможность масштабирования этой ленты в условиях роста числа пользователей (точнее, числа связей между ними) и, как следствие, — количества контента, который они деливерят друг другу.
Так сложилось, что за последние пару лет я успел поучаствовать в разработке нескольких социальных сетей. Главная задача, которую приходилось решать в каждом из этих проектов, заключалась в формировании новостной ленты пользователя. При чём важным условием была возможность масштабирования этой ленты в условиях роста числа пользователей (точнее, числа связей между ними) и, как следствие, — количества контента, который они деливерят друг другу.
Мой рассказ будет о том, как я, превозмогая трудности, решал задачу формирования новостной ленты. А также я расскажу о подходах, которые наработали ребята из проекта Socialite, и которыми они поделились на MongoDB World.
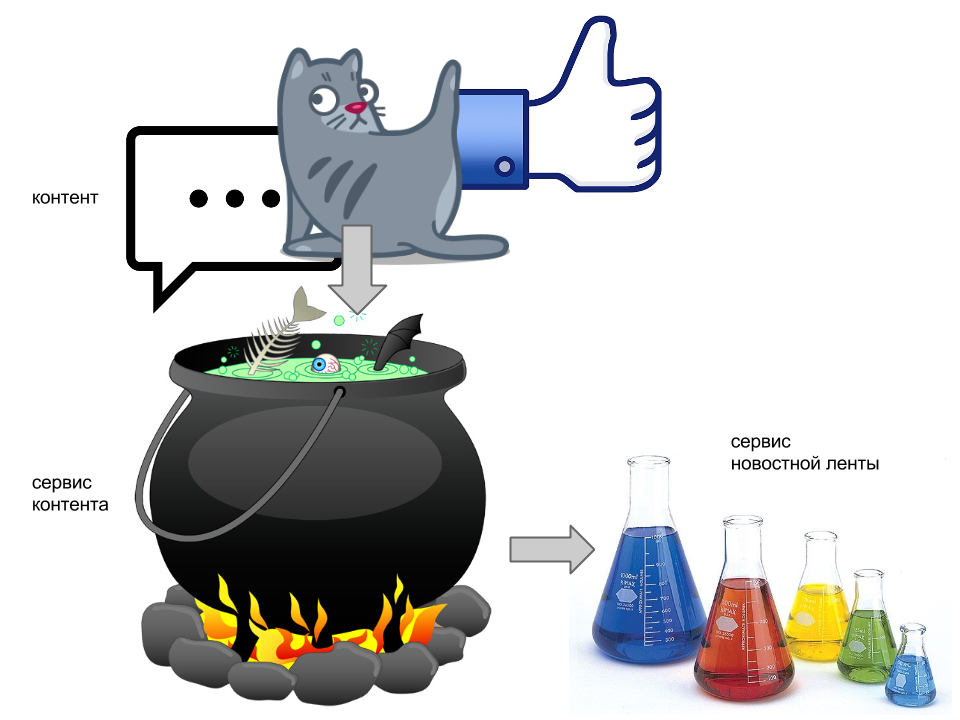
Итак, для начала абсолютно банальная информация о том, что любая новостная лента формируется из активности пользователей, с которыми мы дружим (либо которых мы фолловим/читаем/etc). Следовательно, задача формирования ленты — это задача доставки контента от автора его фолловерам. Лента, как правило, состоит из совершенно разношёрстного контента: котиков, коубов, комедийных видео, каких-то текстовых статусов и прочего. Поверх этого мы имеем репосты, комменты, лайки, тегирование пользователей на этих самых статусах/фоточках/видео. Следовательно, основные задачи, которые возникает перед разработчиками социальной сети — это:1. Агрегация всей активности, всего контента, который постят пользователи. Назовём это условно сервисом контента. На пост-хэллоуинской картинке выше, он изображён кипящим магическим котлом, который переваривает и агрегирует всевозможные разношёрстные объекты в коллекцию более-менее однородных документов.
2. Доставка пользовательского контента его фолловерам. Поручим этот процесс сервису ленты, который представлен колбочками. Таким образом, когда пользователь хочет почитать свою ленту, он идёт за своей персональной колбочкой, берёт её, с ней подходит к котелку и мы наливаем ему нужный кусочек контента.
Вроде бы проще некуда. Давайте более детально рассмотрим подходы в реализации формирования персональной новостной ленты (другими словами, доставки контента от автора его читателям). Пару-тройку интересных трудностей я вам гарантирую.
Данный подход предусматривает формирование ленты на лету. Т.е. когда пользователь запрашивает свою новостную ленту, мы вытягиваем из нашего контент сервиса записи людей, на которых подписан пользователь, сортируем их по времени и получаем новостную ленту. Вот, в общем-то, и всё. Я думаю, что это наиболее очевидный и интуитивно-понятный подход. На схеме выглядит он примерно так: 
Когда пользователь постит что-то новое, процесс абсолютно тривиален: необходимо сделать всего одну запись в сервис контента. Эта простота и неудивительна, т.к. доставка ленты идёт при чтении, а значит всё самое интересное именно там.
ОК, переходим к чтению ленты. Чтобы сформировать ленту для конкретного пользователя, нужно взять список людей, на которых он подписан. С этим списком мы идём к контент сервису и вытягиваем посты этих людей. Конечно, необязательно брать прям все-все записи, как правило, можно взять какую-то часть из этого, необходимую для формирования начала ленты или следующей её части. Но в любом случае размер получаемых данных будет много больше того, что мы в итоге вернём пользователю. Связано это с тем, что активность наших друзей совершенно неравномерная и заранее мы не знаем, сколько постов надо взять от каждого из них, чтобы показать нужную часть ленты.
Но это ещё не самая большая проблема данного подхода. Очевидно, что по мере роста сети, быстрее остальных будет расти коллекция контента. И рано или поздно наступит необходимость шардировать эту коллекцию. И, естественно, шардирование будет происходить по авторам контента (например, по их ID). Так вот, самый большой минус данного подхода заключается в том, что наш запрос будет затрагивать очень большое количество произвольных шардов. Если вы конечно не фолловите одного человека.
Давайте теперь тезисно подведём итоги по доставке лены на чтение.
Из плюсов:
Простата реализации. Именно поэтому такой подход хорошо использовать «по дефолту». Например, для того, чтобы быстро сделать работающую демоверсию, Proof on Concept, etc.
Отсутствие необходимости в дополнительном хранилище для копий контента у фолловеров.
Теперь о минусах: Чтение ленты затрагивает многие шарды, что без сомнения скажется на скорости такой выборки.
А это, скорее всего, потянет за собой необходимость дополнительного индексирования.
Необходимость выбирать контент с «запасом».
Давайте подойдём к проблеме немного с другой стороны. Что если для каждого пользователя хранить уже готовую новостную ленту и обновлять её каждый раз, когда его друзья будут постить что-то новое? Другими словами, мы будем делать копию каждого поста автора в «материализованную» ленту его подписчиков. Этот подход чуть менее очевиден, но ничего сверх сложного в нём тоже нет. Самое важное в нём — это найти оптимальную модель хранения этой самой «материализованной» ленты у каждого пользователя.
И так, что же происходит когда пользователь постит что-то новое? Как и в предыдущем случае, пост отправляется в сервис контента. Но теперь мы дополнительно делаем копию поста в ленту каждого подписчика (на самом деле, на этой картинке стрелочки, идущие в сервис ленты, должны начинаться не из поста автора, а из сервиса контента). Таким образом, у каждого пользователя формируются уже готовые для чтения персональные ленты. Очень важно так же и то, что при шардировании данных из сервиса ленты, использоваться будут ID подписчиков, а не авторов (как в случае с сервисом контента). Соответственно теперь читать ленту мы будем из одного шарда и это даст значительное ускорение.
На первый взгляд может показаться, что создание копий поста для каждого подписчика (особенно если их десятки тысяч) может получиться весьма небыстрым делаем. Но ведь мы разрабатываем не лайв-чат, поэтому совершенно не страшно, если процесс клонирования будет занимать даже несколько минут. Ведь мы можем делать всё эту работу асинхронно, в отличии от чтения. Т.е. пользователю совершенно не обязательно ждать, пока его запись продублируется в ленту каждого его подписчика.
Есть ещё один, куда более ощутимый недостаток — это необходимость где-то хранить все наши «материализованные» ленты. Т.е. это необходимость в дополнительном сторадже. И если у пользователя есть 15.000 фолловеров, то это означает, что весь его контент будет постоянно храниться в 15.000 тысячах копий. И это выглядит уже совсем не круто.
И кратенько о преимуществах и недостатках.
Из плюсов:
Лента формируется чтением одного или нескольких документов. Количество документов будет зависеть от выбранной модели хранения ленты, об немного позже. Легко исключать неактивных юзеров из процесса предсоздания лент. О минусах: Доставка копий большому количеству подписчиков может происходить довольно долго. Необходимость в дополнительном хранилище для «материализованных» лент. Как вы догадываетесь, просто так мириться с проблемами мы не будем, тем более скролл ещё только на середине статьи :-) И здесь нам на помощь приходят ребята из MongoDB Labs, которые разработали целых 3 модели хранения «материализованных» лент. Каждая из этих моделей так или иначе решает описанные выше недостатки.Забегая немного вперёд скажу, что первые две модели предполагают хранения персональной ленты за весь период её существования. Т.е. при этих двух подходах мы храним абсолютно все записи, которые когда-либо попадали в ленту. Таким образом, первые два подхода, в отличии от третьего, не решают проблему «разбухания» данных. Но, с другой стороны, они позволяют очень быстро отдавать пользователю не только топ ленты, но и все её последующие части, вплоть до самого конца. Конечно, пользователи редко скролят ленту в самый низ, но всё зависит от конкретного проекта и требований.
Группируем по времени
Эта модель подразумевает, что все посты в ленте за определённый временной интервал (час/день/etc.), группируются в одном документе. Такой документ ребята из MongoDB Labs называют «бакетом». В нашей же пост-хэллоуинской стилистике они изображены колбочками: 
Пример с MongoDB Documents { »_id»: {«user»: «vasya», «time»: 516935}, «timeline»: [ {»_id»: ObjectId (»…dc1»), «author»: «masha», «post»: «How are you?»}, {»_id»: ObjectId (»…dd2»), «author»: «petya», «post»: «Let’s go drinking!»} ] }, { »_id»: {«user»: «petya», «time»: 516934}, «timeline»: [ {»_id»: ObjectId (»…dc1»), «author»: «dimon», «post»: «My name is Dimon.»} ] }, { »_id»: {«user»: «vasya», «time»: 516934}, «timeline»: [ {»_id»: ObjectId (»…da7»), «author»: «masha», «post»: «Hi, Vasya!»} ] } Всё что мы делаем, это округляем текущее время (например, берём начало каждого часа/дня), берём ID фолловера, и upsert’ом записываем каждый новый пост в свой бакет. Таким образом, все посты за определённый интервал времени будут сгруппированы для каждого подписчика в одном документе.
Если за прошлый день люди, на которых вы подписаны, написали 23 поста, то во вчерашнем бакете вашего пользователя будет ровно 23 записи. Если же, например, за последние 10 дней новых постов не было, то и новые бакеты создаваться не будут. Так что в определённых случаях этот подход будет весьма удобен.
Самым главным недостатком модели является то, что создаваемые бакеты будут непредсказуемого размера. Например, в пятницу все постят пятничные коубы, и у вас в бакете будет несколько сотен записей. А на следующий день все спят, и в вашем субботнем бакете будет 1–2 записи. Это плохо тем, что вы не знаете, сколько документов вам надо прочитать для того, чтобы сформировать нужную часть ленты (даже начало). А ещё можно банально превысить максимальный размер документа в 16Мб.
Группируем по размеру
Если непредсказуемость размера бакетов критична для вашего проекта, тогда формировать бакеты нужно по количеству записей в них.
Пример с MongoDB Documents { »_id»: ObjectId (»…122»), «user»: «vasya», «size»: 3, «timeline»: [ {»_id»: ObjectId (»…dc1»), «author»: «masha», «post»: «How are you?»}, {»_id»: ObjectId (»…dd2»), «author»: «petya», «post»: «Let’s go drinking!»}, {»_id»: ObjectId (»…da7»), «author»: «petya», «post»: «Hi, Vasya!»} ] }, { »_id»: ObjectId (»…011»), «user»: «petya», «size»: 1, «timeline»: [ {»_id»: ObjectId (»…dc1»), «author»: «dimon», «post»: «My name is Dimon.»} ] } Приведу пример. Установим лимит на бакет в 50 записей. Тогда первые 50 постов мы записываем в первый бакет пользователя. Когда настаёт черёд 51-го поста, создаём второй бакет для этого же пользователя, и пишем туда этот и следующие 50 постов. И так далее. Таким нехитрым образом мы решили проблему с нестабильным и непредсказуемым размером. Но такая модель работает на запись примерно в 2 раза медленнее, чем предыдущая. Связанно это с тем, что при записи каждого нового поста необходимо проверять достигли ли мы установленного лимита или нет. И если достигли, то создавать новый бакет и писать в уже в него.
Так что с одной стороны этот подход решает проблемы предыдущего, а с другой создаёт новые. Поэтому выбор модели будет зависеть от конкретных требований к вашей системе.
Кэшируем топ
И, наконец, последняя модель хранения ленты, которая должна решить все-все накопившиеся проблемы. Или, по крайней мере, сбалансировать их.
Пример с MongoDB Documents { «user»: «vasya», «timeline»: [ {»_id»: ObjectId (»…dc1»), «author»: «masha», «post»: «How are you?»}, {»_id»: ObjectId (»…dd2»), «author»: «petya», «post»: «Let’s go drinking!»}, {»_id»: ObjectId (»…da7»), «author»: «petya», «post»: «Hi, Vasya!»} ] }, { «user»: «petya», «timeline»: [ {»_id»: ObjectId (»…dc1»), «author»: «dimon», «post»: «My name is Dimon.»} ] } Основная идея этой модели заключается в том, что мы кэшируем некоторое количество последних постов, а не храним всю историю. Т.е. по сути бакете будет представлять из себя capped-array, хранящий некоторое количество записей. В MongoDB (начиная с версии 2.4) это делается очень просто используя операторы $push и $slice.
Плюсов от такого подхода сразу несколько. Во-первых, нам надо обновлять всего один документ. При чём апдейт этот будет очень быстрый, т.к. в нём отсутствуют какие-либо проверки, в отличии от предыдущей модели. Во-вторых, для получения ленты нам надо читать опять-таки всего один документ.
Далее. Если пользователь длительное время не заходит в наш сервис, то мы можем просто удалить его кэш. Таким образом, мы исключим неактивных пользователей из процесса создания «материализованных» лент, высвобождая ресурсы наших серверов. Если же неактивный пользователь вдруг решит вернуться, скажем через год, мы легко создадим для него новенький кэш. Заполнить его актуальными постами можно используя fallback в простую доставку на чтение.
Таким образом, данная модель является отличным балансом между тем, чтобы хранить всё ленту для каждого пользователя и тем, чтобы строить эту ленту на каждый запрос.
Embedding vs Linking И ещё один важный момент касательно хранения ленты в кэше: хранить контент постов или только ссылку? Подход с хранением полной копии постов прямо в бакете будет хорош, если контент постов будет небольшого и главное известного размера. В качестве идеального примера можно привести Twitter с его 140-символьными статусами.
В общем же случае выигрывает второй подход, когда мы храним ID поста и, возможно, какие-то мета-данные (например, ID автора, дату публикации и прочее). Контент же вытягивается только при необходимости. При чём сделать это имея ID поста можно очень легко и быстро.
В XXI веке на каждого лентяя существует примерно 100500 приложений на каждый случай жизни. Соответственно, для каждого разработчика существует чуть меньше чем 100500 сервисов. Клёвый сервис управления лентой живёт здесь.На этом у меня всё. Хочу лишь сказать о том, что серебряной пули для решения всех проблем формирования новостной ленты ожидаемо не нашлось. Но мы рассмотрели целую кучу решений и подходов, каждый из которых будет хорошо работать в своей конкретной ситуации.
