Про микросервисы на примерах
Решили сделать статью без воды и картинок про микросервисы, чтобы любой начинающий аналитик мог понять, а что же это такое на самом деле. И конечно такая статья должны быть с практикой, а не копипастой из разных книг и статей, которую все друг другу рассказывают на собеседованиях.
Итак, эта статья не для разработчиков и опытных архитекторов, а для аналитиков, которые хотят понять, а что же такое микросервисы на самом деле. Пример здесь максимально простой и не претендует на хороший стиль написания кода. Чтобы его запустить не нужно обладать вообще никаким ИТ‑бэкграундом и не нужно настраивать никакие IDE.

Примечание. Если хотите сразу попробовать и не читать, как устроен сервис, переходите по ссылке — там исходники и инструкция. Также эту ссылку продублировал в конце, если захотите попробовать тренажёр уже после прочтения.
Немного теории о программах
Микросервис — это программа.
А в современных реалиях программа — это набор классов. Таким образом, микросервис в самом простом случае — это один класс, хоть это и грубое приближение.
Если не вдаваться в теорию, то класс — это описание данных и функций, которые работают с этими данными.
Функции называются методами класса, а данные — полями класса.
Можно принять такое приближение: класс — это набор полей (данных) и методов (функций).
Когда программа скомпилирована (переведена из исходного кода в некий исполняемый файл, который запускается на компьютере) и начинает выполняться, то компьютер размещает у себя в памяти объекты (копии) каких-то классов. Поля (данные) и методы (функции) хранятся в оперативной памяти в момент выполнения программы. Поля заполняются реальными значениями.
Ну и, соответственно, работа программы заключается в вызове каких-то методов класса, с передачей им на вход дополнительных данных (методы работают с внешними данными, которые поступают им на вход, а не только с полями).
Это очень примитивное описание, тем не менее, достаточное для базового понимания процесса работы кода.
Таким образом, микросервис можно описать так: это входные данные, затем внутренняя логика по работе с этими данными, и результат этой работы: выходные данные (ответ сервиса).
Получается, что микросервис принимает на вход какие-то параметры, что-то с ними делает (он также может сам сходить за дополнительными данными в какую-то внешнюю систему), а потом возвращает результат в ту систему, которая его вызвала.
Теория закончена. Приступим к описанию работы тренажёра.
Как тренажёр работает?
Есть два микросервиса на Flask.
Примечание. Это Python-фрэймворк, про который можно почитать в материале «Разработка web-приложения на Flask»
Первый микросервис ходит в HH.ru и по шаблону достает оттуда вакансии — осуществляет вызов во внешнюю систему, другими словами. Второй микросервис берёт эти полученные данные и записывает их в файл.
Сейчас поговорим про первый микросервис. Он простой. Собственно, вот его код.
#Создали объект класса Flask (микросервис)
app = flask.Flask(__name__)
#Прописали функцию и путь, по которой ее можно вызвать
@app.route(‘/api/1.0/getVacsByName/’ , methods=[‘GET’ , ‘POST’] )
def getVacsByName():
#Загрузили параметры запроса из конфигурационного файла
dct = request.json
config_dir = dct[‘config_dir’]
file = open(config_dir , ‘r’ , encoding=”utf-8”)
content = file.readlines()
pars = {}
url = content[0].split(‘\n’)[0]
storage = content[1].split(‘:’)[1].split(‘\n’)[0]
for i in range(2, len(content)):
st = content[i]
value = st.split(‘:’)[1].split(‘\n’)[0]
key = st.split(‘:’)[0]
#print(key, " " , value)
if(value.isdigit()):
pars[key] = int(value)
else:
pars[key] = (value)
# Посылаем запрос к API сайта
req = requests.get(url, pars)
# Декодируем его ответ, чтобы кириллица отображалась корректно
data = req.content.decode() req.close()
#Вернули ответ наружу
return dataВторой микросервис ещё проще.
#Создали объект класса (микросервис)
app = flask.Flask(__name__)
#Прописали функцию и путь, по которой ее можно вызвать
@app.route(‘/api/1.0/StoreToFile/’ , method=[‘POST’] )
def StoreToFile():
#Получили данные в формате json из запроса
Frame = request.json#словарь
dr = Frame[‘dir’]
#Считали директорию для сохранения ответа и перечень данных, которые надо #сохранить
with open(dr) as f:
lines = f.read().splitlines()
dr_tosave = lines[0]
lines.remove(dr_tosave)
cols = lines
#Записали результат в DataFrame
res = pd.DataFrame(Frame[‘items’])[cols]
#Сохранили результат
res.to_excel(dr_tosave)
print(dr_tosave)
return Frame
Управление сервисами мы (Андрей Эндерс, я, и мой коллега Александр Кочин), и сделали простым, чтобы было два конфигурационных файла. В одном файле задаются параметры того, что мы хотим из HH.ru получить. Во втором указываем куда и как это добро сохранять.
Ещё немного о том, как он работает
Вот я указал конфигурационный файл, в котором прописаны параметры запроса.
dr = {
"config_dir”: ‘C:/Users/Selecty/Desktop/project/cin/config.txt’
}
Что в нём находится? Вот это:
https://api.hh.ru/vacancies
text:системный аналитик
area:2
page:0
per_page:100Здесь указан сайт, к которому мы будем обращаться. Остальные строки — параметры того, что мы ищем (все это входные параметры микросервиса). Например, здесь мы ищем системного аналитика в Питере (код города 2), с первой страницы по 100 вакансий.
Что теперь происходит?
Подгружаем разные полезные библиотеки, конфиг, вызываем первый микросервис…
req = requests.post(‘http://127.0.0.1:5000/api/1.0/getVacsByName’, json = dr)
Frame = json.loads(req.text)…и получаем ответ.
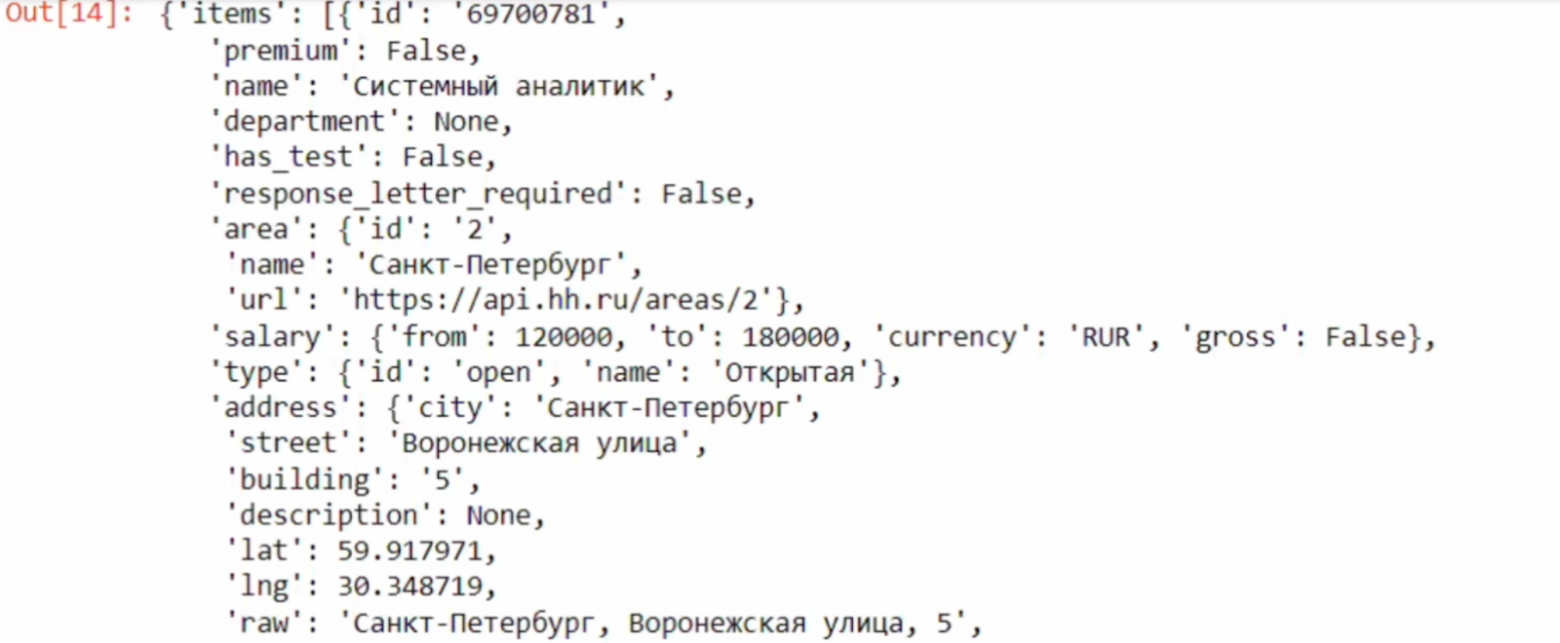
Здесь полный ответ, много системной информации, потому что мы хотим получить полезные данные.
Что делаем дальше?
Превращаем ответ в JSON, который удобен программной среде. В этот же JSON добавим директорию конфига, где лежат параметры для сохранения.
Frame = json.loads(req.text)
Frame[‘dir’] = ‘C:Users/Selecty|Desktop/project/cout/config.txt’Здесь у нас прописан путь в тот файл, куда мы хотим сохранить результаты, какие столбцы вакансий мы хотим отбирать, задаём параметры фильтрации: id, name, area, salary и прочее.
Дёргаем второй микросервис.
req = requests.post( ‘http://127.0.0.1:5001/api/1.0/StoreToFile’ , json = Frame )
Frame = req.json()
И заходим туда, куда хотим сохранить. Вот он нам сохранил результат.

Выглядит, конечно, некрасиво, но видно и название вакансии, и ID города, и контактную информацию и прочее.
Зачем это всё?
По умолчанию, микросервисы системный аналитик должен знать. Но как знания появятся, если только в книжке или на Хабре прочитал? Поэтому я и решил, что лучше сделать реальный микросервис, чтобы каждый мог получить представление.
Идея тренажера в том, чтобы без громоздкой логики было понятно, как эта теория работает на практике: как один микросервис ходит, а другой записывает, что такое API и тому подобные вещи.
Если хотите попробовать
Это учебный проект, он никакой логики за собой не несет.
Не нужно Swagger«а, нет спецификации, но зато можно видеть как все работает.
Не нужно никакой среды, в этом плюс Jupiter и Python, мы просто запускаем всё через браузер. Дальше можно модифицировать код и смотреть, как это работает .
➡️ ➡️ ➡️ Исходники доступны по ссылке: заходите, читайте инструкцию, пользуйтесь.
А ещё, был бы интересен ваш опыт использования. Если напишете в комментариях об этом — будет интересно.
Рекомендуем почитать [подборка от редактора]
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
