Примеры реальных патчей в PostgreSQL: часть 3 из N
Сегодня я хотел бы вновь рассказать о некоторых патчах, принятых за последнее время в PostgreSQL (а также утилиту pg_filedump). Аналогичные статьи, опубликованные на Хабре ранее, набрали достаточно много плюсиков, что заставляет думать, что они представляют для кого-то интерес. Если вы пропустили предыдущие статьи, вот они — раз, два, три. Несмотря на то, что рассмотренные патчи были написаны мной, не стоит забывать о вкладе людей, которые их ревьювили и тестировали. Проделанная этими людьми работа зачастую оказывается больше и сложнее работы самого автора. Особо активное участие в разработке рассмотренных пачтей приняли Федор Сигаев, Robert Haas, Tom Lane, Дмитрий Иванов, Григорий Смолкин, Andres Freund, Анастасия Лубенникова и Tels.
11. pg_filedump: возвращение ненулевого кода возврата в случае ошибок
Напомню, что утилита pg_filedump предназначена для декодирования сегментов таблиц и вывода информации о заголовках страниц и кортежей. Было замечено, что при несовпадении контрольных сумм страниц с их содержимым, pg_filedump выводит соответствующее предупреждение, однако возвращает нулевой код возврата. Что как бы не совсем правильно, особенно если утилита используется в shell-скриптах.
Патч исправляет эту ситуацию. Теперь pg_filedump возвращает ненулевой код при обнаружении любых ошибок, как в контрольных суммах, так и любых других:
+/* Program exit code */
+static int exitCode = 0;
+
/***
* Function Prototypes
*/
@@ -191,6 +194,7 @@ ConsumeOptions(int numOptions, char **options)
{
rc = OPT_RC_INVALID;
printf("Error: Missing range start identifier.\n");
+ exitCode = 1;
break;
}
@@ -205,6 +209,7 @@ ConsumeOptions(int numOptions, char **options)
rc = OPT_RC_INVALID;
printf("Error: Invalid range start identifier <%s>.\n",
optionString);
+ exitCode = 1;
break;
}
(...и так далее...)
@@ -1746,5 +1823,5 @@ main(int argv, char **argc)
if (buffer)
free(buffer);
- exit(0);
+ exit(exitCode);
}Патч: 1c9dd6b728810ea7d2f196e6e15064017e4b9eef
12. Улучшение документации о внутреннем представлении типа timestamp
Документация к типу timestamp гласила:
When timestamp values are stored as eight-byte integers
(currently the default), microsecond precision is available over
the full range of values. When timestamp values are
stored as double precision floating-point numbers instead (a
deprecated compile-time option), the effective limit of precision
might be less than 6. timestamp values are stored as
seconds before or after midnight 2000-01-01. [...] В ходе работы над рассмотренным в следующем раздеде патчем было замечено, что приведенный текст создает неверное представление. На самом деле, по умолчанию timestamp хранит время в микросекундах. Если же пользователь выбрал устаревшее представление в виде чисел с плавающей точкой, тогда действительно время хранится в секундах.
После недолгого обсуждения в рассылке вводящий в заблуждение кусок документации был переписан.
Патч: 44f7afba79348883da110642d230a13003b75f62
13. pg_filedump: частичное восстановление данных
Этот патч был подробно рассмотрен в заметке Пример восстановления таблиц PostgreSQL с помощью новой мега фичи pg_filedump, поэтому здесь я не буду на нем подробно останавливаться. TL; DR версия — теперь при помощи pg_filedump можно восстановить по крайней мере какую-то часть данных из таблицы, даже в случае, если инстанс PostgreSQL не запускается.
Патч: 52fa0201f97808d518c64bcb9696f2a350678aa5
14. pg_filedump: декодирование каталожных таблиц
Как и предыдущему патчу, этому была посвящена целая отельная статья Еще одна новая фича pg_filedump: восстанавливаем каталог PostgreSQL. TL; DR версия для тех, кто все равно не собирается ее читать — раньше pg_filedump не поддерживал некоторые типы, используемые в каталожных таблицах. После применения этого патча стало возможным декодировать таблицы каталога, а следовательно и восстановить схему базы данных, если она нам не известна.
Патч: 5c5ba458fa154183d11d43218adf1504873728fd
15а. Ускорение партицирования: исправление батлнека в find_tabstat_entry () / get_tabstat_entry ()
В PostgreSQL 10, который на момент написания этих строк разрабатывается и находится в состоянии фичфриза, была добавлена возможность декларативного партицирования таблиц. То есть, теперь таблицу можно разбить на несколько физических таблиц по хэшу или ренджам. Это было возможно и ранее при помощи наследования таблиц, но было менее удобно и в целом выглядело как грязный хак. Примеры использования декларативного партицирования можно найти здесь и здесь.
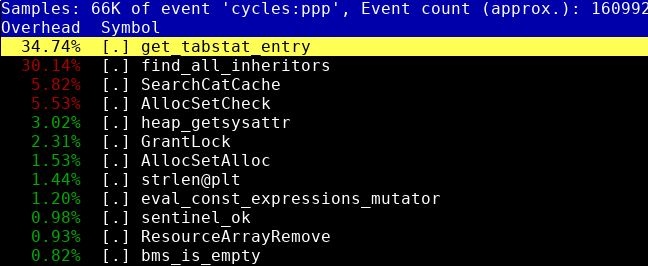
Ну вот я и подумал, а создам-ка я побольше (скажем, 10 000) партиций и посмотрю, где будет тормозить. Теме профилирования кода на C/C++ ранее я посвящал целую статью, даже несколько, если считать статьи про DTrace, SystemTap и HeapTrack. Кроме того, на эту тему я делал доклад на HighLoad++ 2016, видеозапись которого лежит на YouTube. Поэтому на описании процесса здесь я подробно останавливаться не буду. Скажу только, что perf top показал два явных батлнека, которые вы можете видеть на иллюстрации в начале данной статьи.
Так вот, патч исправляет первый из этих батлнеков. Оказалось, что статистика по таблицам использует небольшой аллокатор памяти, построенный на списках. Поиск по идентификатору таблицы структуры PgStat_TableStatus, соответствующей таблице, производился путем сканирования этого списка, что работает не очень хорошо, когда таблиц 10 000. Добавление хэш-таблицы, отображающей идентификатор таблицы в указатель на структуру, моментально устранило батлнек.
Патч: 090010f2ec9b1f9ac1124dc628b89586f911b641
15 б. Ускорение партицирования: исправление батлнека в find_all_inheritors ()
Аналогичная проблема присутствовала и в процедуре рекурсивного поиска всех наследников заданной таблицы. Немногие знают, что PostgreSQL поддерживает множественное наследование таблиц. Поэтому при обходе дочерних таблиц процедура проходит по списку ранее посещенных таблиц. Если очередной таблицы в списке нет, она в него добавляется. Если она там уже есть, у таблицы увеличивается счетчик родителей. Список всех дочерних таблиц и число их родителей возвращается из процедуры в качестве результата.
Как вы уже могли догадаться, батлнек снова был устранен добавлением хэш-таблицы для ускорения поиска по списку. По моим бенчмаркам два патча суммарно ускорили декларативное партицирование на 64%. Интересно, что патчи ускоряют его не только при большом количестве партиций, но и когда партиций всего лишь несколько штук. Хотя в последнем случае, конечно же, эффект не так заметен.
Патч: 827d6f977940952ebef4bd21fb0f97be4e20c0c4
Заключение
Как и ранее, цель всех этих статей — показать, что в разработке РСУБД, в частности PostgreSQL, несмотря на крайнюю интересность процесса, нет чего-то волшебного или прямо-таки непостижимо сложного. Хочется надеяться, что эта серия статей сможет мотивировать пару-тройку человек принять участие в разработке PostgreSQL, в качестве хобби, или же профессионально.
В частности, компания Postgres Professional, в которой я сейчас работаю, перманентно нанимает, притом, не только программистов, но и, к примеру, QA и DBA. Как уже было отмечено, качественные тестирование и code review в нашем деле зачастую оказываются важнее написания кода.
