Практические истории из наших SRE-будней. Часть 3
Рады продолжить цикл статей с подборками из недавних вызовов, случившихся в нашей повседневной практике эксплуатации. Для этого мы описываем свои мысли и действия, которые привели к их успешному преодолению.

Новый выпуск посвящён опыту с неожиданно затянувшейся миграцией одного Linux-сервера, знакомству с Kubernetes-оператором для ClickHouse, способу ускорить восстановление данных в сломавшейся реплике PostgreSQL и последствиями обновления CockroachDB. Если вы тоже думаете, что это может быть полезно или хотя бы просто интересно, добро пожаловать под кат!
История №1. Затянувшийся перенос сервера в виртуальную машину
План миграции
Казалось, что может пойти не так, если требуется перенести legacy-приложение с железного сервера в виртуальную машину? У приложения и его инфраструктуры привычный, хорошо понятный стек: Linux, PHP, Apache, Gearman, MySQL. Причины для миграции тоже обычны: клиент захотел уменьшить плату за хостинг, отказавшись от реального сервера, на котором остался только вспомогательный сервис (парсер соцсетей).
 Вообще говоря, конечно, бывают и другие причины для миграции (например, многочисленные удобства в последующем обслуживании инфраструктуры и её масштабирования), но не буду заострять на этом внимание.
Вообще говоря, конечно, бывают и другие причины для миграции (например, многочисленные удобства в последующем обслуживании инфраструктуры и её масштабирования), но не буду заострять на этом внимание.
Неожиданно для себя, при написании статьи, я обнаружил, что на хабре нет статьи с описанием миграции серверов в виртуальные машины без привязки к какой-нибудь технологии виртуализации. В найденных вариантах показана миграция средствами «снаружи», а мы же расскажем о привычном для нас способе переноса «изнутри».
Общий план выглядит следующим образом:
- Произвести очистку сервера, поняв, сколько ресурсов требуется.
- Подготовить виртуальный сервер, выделить память, ядра, зарезервировать IP-адреса.
- Если требуется минимальный простой — организовать внешний балансировщик, который можно переключить на свежесозданный виртуальный сервер, или же запустить копию приложения.
- Произвести начальную загрузку с образа выбранной ОС/дистрибутива, содержащего все необходимые драйверы, чтобы скопировать данные в виртуальную машину тем или иным способом.
- Создать chroot, чтобы исправить загрузчик системы.
- Переключить пользовательские запросы или сервисные задачи на новую систему.
Что ж, воспользуемся таким планом в очередной раз, попутно выясняя, какие нестандартные ситуации, оказывается, могут возникать.
Подготовка к миграции
Перед началом непосредственного переезда мы решили почистить сервер. На нем было занято 300 Гб диска, однако среди них удалось найти давно потерявшие актуальность бэкапы, совсем старые логи, а также излишки в базе данных (см. ниже). В результате файловую систему удалось оптимизировать до 60 Гб.
Отдельно хочется рассказать про «похудение» MySQL. Дело в том, что MySQL изначально была версии 5.5 и настроена без innodb_file_per_table. Из-за этого, как многие могут догадаться, файл ibdata1 разросся до 40 Гб. В таких ситуациях нам всегда помогает pt-online-schema-change (входит в состав Percona Toolkit).
Достаточно проверить таблицы, которые находятся в shared innodb tablespace:
SELECT i.name FROM information_schema.INNODB_SYS_TABLES i WHERE i.space = 0;
… после чего запустить упомянутую команду pt-online-schema-change, которая позволяет совершать различные действия над таблицами без простоя и поможет нам совершить OPTIMIZE без простоя для всех найденных таблиц:
pt-online-schema-change --alter "ENGINE=InnoDB" D=mydb,t=test --execute
Если файл ibdata1 не слишком велик, то его можно оставить. Чтобы полностью избавиться от мусора в файле ibdata1, потребуется сделать mysqldump со всех баз, оставив только базы mysql и performance_schema. Теперь можно остановить MySQL и удалить ibdata1.
После перезапуска MySQL создаст недостающие файлы системного namespace InnoDB. Загружаем данные в MySQL и готово.
Подготовка дисков и копирование
Казалось бы, теперь можно произвести перенос данных с помощью dd, однако в данном случае это не представлялось возможным. На сервере был созданный с md RAID 1, который не хотелось бы видеть на виртуальной машине, так как её разделы создаются в Volume Group, которая создана на RAID 10. Кроме того, разделы были очень большие, хотя занято было не более 15% места. Поэтому было принято решение переносить виртуальную машину, используя rsync. Такая операция нас не пугает: мы часто мигрировали серверы подобным образом, хотя это и несколько сложнее, чем перенос всех разделов с использованием dd.
Что потребуется сделать? Тут нет особой тайны, так как некоторые шаги полностью соответствуют действиям при копировании диска с dd:
- Создаем виртуальную машину нужного размера и загружаемся с systemrescuecd.
- Делаем разбивку диска, аналогичную серверу. Обычно нужен root-раздел и boot — с этим поможет
parted. Допустим, у нас есть диск/dev/vda:parted /dev/vda mklabel gpt mkpart P1 ext3 1MiB 4MiB t 1 bios_grub mkpart P2 ext3 4MiB 1024MiB mkpart P3 ext3 1024MiB 100% t 3 lvm - Создадим на разделах файловые системы. Обычно мы используем ext3 для boot и ext4 для root.
- Монтируем разделы в
/mnt, в который будем chroot’иться:mount /dev/vda2 /mnt mkdir -p /mnt/boot mount /dev/vda1 /mnt/boot - Подключим сеть. Актуальные версии systemrescuecd построены на ArchLinux и предполагают настройку системы через nmcli:
nmcli con add con-name lan1 ifname em1 type ethernet ip4 192.168.100.100/24 gw4 192.168.100.1 ipv4.dns "8.8.8.8 8.8.4.4" nmcli con up lan1 - Копируем данные:
rsync -avz --delete --progress --exclude "dev/*" --exclude "proc/*" --exclude "sys/*" rsync://old_ip/root/ /mnt/ - Затем монтируем dev, proc, sys:
mount -t proc proc /mnt/proc mount -t sysfs sys /mnt/sys mount --bind /dev /mnt/dev - Зайдем в полученный chroot:
chroot /mnt bash - Поправим
fstab, изменив адреса точек монтирование на актуальные. - Теперь надо восстановить загрузчик:
- Восстановим загрузочный сектор:
grub-install /dev/vda - Обновим конфиг grub:
update-grub
- Восстановим загрузочный сектор:
- Обновим initramfs:
update-initramfs -k all -u - Перезагрузим виртуалку и загрузим перенесенную систему.
Используя этот алгоритм, мы перенесли сотни виртуальных машин и серверов, однако в этот раз что-то пошло не так…
Проблема и её решение
Система упорно помнила различные дисковые подразделы, которые были до переноса на сервере. Проблем разобраться с mdadm не было — достаточно просто удалить файл /etc/mdadm/mdadm.conf и запустить update-initramfs.

Однако система все равно пыталась найти еще и /dev/mapped/vg0-swap. Оказалось, что initrd пытается подключить swap из-за конфига, который добавляет Debian installer. Удаляем лишний файл, собираем initramfs, перезагружаемся — и снова попадаем в консоль busybox.
Поинтересуемся у системы, видит ли она наши диски. lsblk выдает пустоту, да и поиск файлов устройств в /dev/disk/by-uuid/ не даёт результатов. Выяснилось, что ядро Debian Jessie 3.16 скомпилировано без поддержки virtio-устройств (точнее, сама поддержка, конечно, доступна, но для этого нужно загрузить соответствующие модули).
К счастью, модули добавляются в initrd без проблем: нужные модули можно либо прописать в /etc/initramfs-tools/modules, либо изменить политику добавления модулей в /etc/initramfs-tools/initramfs.conf на MODULES=most.

Однако магии и в этот раз не произошло. Даже несмотря на наличие модулей система не видела диски:
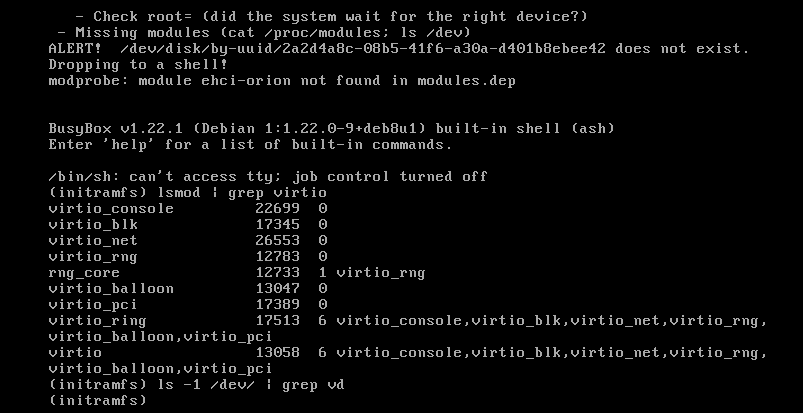
Пришлось в настройках виртуальной машины переключить диски с шины Virtio на SCSI — такое действие позволило загрузить виртуальную машину.
В загруженной системе отсутствовала сеть. Попытки подключить сетевые драйверы (модуль virtio_net) ни к чему не привели.
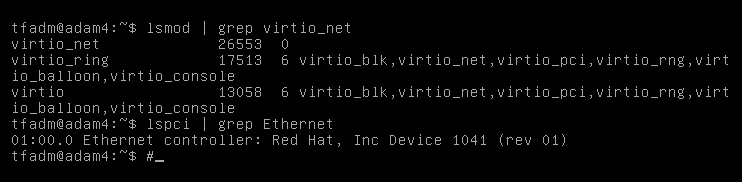
Дабы не усложнять задачу и не затягивать переключение, было решено переключить и сетевые адаптеры на эмуляцию реального железа — сетевой карты Intel e1000e. Виртуальная машина была остановлена, драйвер изменён, однако при запуске мы получили ошибку: failed to find romfile "efi-e1000.rom".
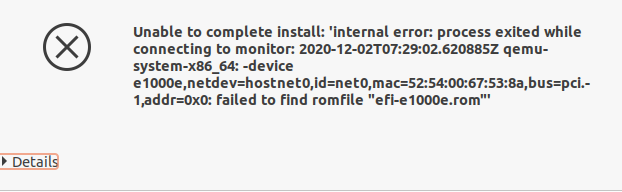
Поиск дал интересный результат: ROM-файл был потерян в Debian некоторое время назад и возвращать его в пакет коллеги не собирались. Однако этот же файл фигурирует в пакете ipxe-qemu, откуда и был с успехом взят. Оказалось, достаточно распаковать этот пакет (ipxe-qemu) и скопировать /usr/lib/ipxe/qemu/efi-e1000.rom в /usr/share/qemu/efi-e1000e.rom. После этого виртуальная машина с эмулированным адаптером начала стартовать.
Вы думаете, это всё? Конечно же, нет, когда в деле замешан e1000e… Данный драйвер известен тем, что может под нагрузкой начать перезапускать сетевой адаптер. Именно это и произошло, когда мы стали загружать базу данных для приложения. Пришлось прибегнуть к старому способу с отключение «аппаратного» offload:
ethtool -K eth0 gso off gro off tso off
Только после этого стало возможным нормализовать работу системы и наконец-то запустить приложение. Наверняка возможен и другой путь, однако его поиск скорее всего занял бы больше времени, что не входило ни в наши интересы, ни в область понимания клиента: ведь на миграцию был заложен конкретный срок.
История №2. Безопасность для Kubernetes-оператора ClickHouse
Не так давно мы начали использовать ClickHouse operator от Altinity. Данный оператор позволяет гибко разворачивать кластеры ClickHouse в Kubernetes:
- с репликацией — для повышенной надёжности;
- с шардами — для горизонтального масштабирования.
Однако мы столкнулись с неожиданной проблемой: невозможностью задать пароль для юзера default, который используется для работы remote_servers по умолчанию. Всё дело в том, что в шаблонах генерации конфигов кластера нет возможности определения пароля для remote_servers. По этой причине невозможна одновременная работа с distributed-таблицами — она будет падать с ошибкой:
[2020-11-25 15:00:20] Code: 516, e.displayText() = DB::Exception: Received from chi-cluster-cluster-0-0:9000. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name.
К счастью, ClickHouse позволяет сделать whitelist с использованием rDNS, IP, host regexp Так можнодобавить в конфиг кластера следующее:
users:
default/networks/host_regexp: (chi-cluster-[^.]+\d+-\d+|clickhouse\-cluster)\.clickhouse\.svc\.cluster\.local$
Тогда кластер сможет нормально функционировать. В репозитории оператора есть issue по этому поводу (мы не забыли добавить туда и свой workaround). Однако не похоже, что там будут какие-то движения в ближайшее время — из-за того, что потребуется хранить пароли в конфигурации remote_servers.
История №3. Ускоренная перезаливка реплик PostgreSQL
К сожалению, ничто не вечно и любая техника стареет. А это приводит к различным сбоям. Один из таких сбоев произошел на реплике баз данных PostgreSQL: отказал один из дисков и массив перешёл в режим read only.
После замены диска и восстановления работы сервера встал вопрос: как же быстро ввести его в строй, учитывая, что база у проекта довольно объемна (более 2 терабайт)?
Дело осложнялось тем, что репликация была заведена без слотов репликации, а за время, пока сервер приводили в чувство, все необходимые WAL-сегменты были удалены. Архивацией WAL в проекте никто не озаботился и момент для её включения был упущен. К слову, сами слоты репликации представляют угрозу в версиях PostgreSQL ниже 13, т.к. могут занять всё место на диске (а неопытный инженер о них даже не вспомнит). С 13-й версии PgSQL размер слота уже можно ограничить директивой max_slot_wal_keep_size.
Итак, казалось бы, надо вооружаться pg_basebackup и переливать базу с нуля, но по нашим подсчетам такая операция заняла бы 9 дней, и всё это время основной сервер БД работал бы без резерва. Что же делать? У нас же есть почти актуальные файлы, некоторые из которых база вообще не трогает, так как это старые партиции партицированных таблиц… Но pg_basebackup требует чистой директории для начала копирования. Вот бы изобрести метод, который бы позволил докачать базу!…
И тут я вспомнил про исходный метод, которым мы снимали бэкапы еще во времена PostgreSQL 9.1. Он описывается в статье документации про Continuous Archiving and Point-in-Time Recovery. Суть его крайне проста и основана на том, что можно копировать файлы PgSQL, если вызвать команду pg_start_backup, а после процедуры копирования — pg_stop_backup. В голове созрел следующий план:
- Создадим слот репликации для реплики командой на мастере:
SELECT pg_create_physical_replication_slot('replica', true);
Важно, чтобы при создании второй аргумент функции был именноtrue— тогда база начнёт немедленно собирать сегменты WAL в этот слот, а не будет ждать первого подключения к нему. - Выполним команду на мастере:
SELECT pg_start_backup('copy', true);
Снова важно, чтобы при создании второй аргумент функции был именноtrue— тогда база немедленно выполнит checkpoint и можно будет начать копирование. - Скопируем базу на реплику. Мы для этой цели использовали rsync:
rsynс -avz --delete --progress rsync://leader_ip/root/var/lib/postgresql/10/main/ /var/lib/postgresql/10/main/
С такими параметрами запуска rsync заменит изменившиеся файлы. - По окончании копирования на мастере выполним:
SELECT pg_stop_backup(); - На реплике положим такой
recovery.confс указанием нашего слота:standby_mode = 'on' primary_conninfo = 'user=rep host=master_ip port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres target_session_attrs=any' recovery_target_timeline = 'latest' primary_slot_name = replica - Запустим реплику.
- Удалим слот репликации на реплике, так как он так же скопируется с мастера:
SELECT pg_drop_replication_slot('replica'); - Проверим, что она появилась в системной таблице
pg_stat_replication.
Однако один момент я всё-таки упустил. Мы выполнили копирование всех WAL-файлов, которые были на мастере. А значит — даже тех, которые не требовались. Поэтому на следующий день после перелива реплики… место на сервере с репликой начало заканчиваться. И пришлось думать над тем, как удалить бесхозные сегменты WAL.
Мы знаем, что checkpoint_timeout равен 1 часу. Следовательно, надо удалить все файлы старше 1 часа, но от какого момента? Для этого на мастере делаем запрос:
SELECT pg_walfile_name(replay_lsn) from pg_stat_replication;
pg_walfile_name
--------------------------
0000000200022107000000C8
(1 row)
Исходя из него сверяем временную метку файла:
stat /var/lib/postgresql/10/main/pg_wal/0000000200022107000000C8
...
Access: 2020-12-02 13:11:20.409309421 +0300
Modify: 2020-12-02 13:11:20.409309421 +0300
Change: 2020-12-02 13:11:20.409309421 +0300
… у удаляем все файлы старше. С этим помогут find и bash:
# Вычислим смещение
deleteBefore=`expr $(date --date='2020-12-02 13:11:20' +%s) - 3600`
mins2keep=`expr $(expr $(expr $(date +%s) - $deleteBefore) / 60) + 1`
# Удалим файлы размером 16 МБ (стандартный размер сегмента WAL),
# которые старше, чем mins2keep
find /var/lib/postgresql/10/main/pg_wal/ -size 16M -type f -mmin +$mins2keep -delete
Вот и всё: реплика была перелита за 12 часов (вместо 9 дней), функционирует и очищена от мусора.
История №4. CockroachDB не тормозит?
После обновления CockroachDB до версии 20.2.x мы столкнулись с проблемами производительности. Они выражались в долгом старте приложения и общем снижении производительности некоторых типов запросов. На CockroachDB 20.1.8 подобного поведения не наблюдалось.
Изначально имелось предположение, что дело в сетевых проблемах в кластере Kubernetes. Однако подтвердить его не удалось: cеть чувствовала себя отлично.
В процессе дальнейшего изучения было обнаружено, что на производительность влияет наличие в кластере CockroachDB базы приложения Keycloak. Решили включить журналирование медленных логов — кстати, в CockroachDB это делается командами:
SET CLUSTER SETTING sql.log.slow_query.latency_threshold = '100ms';
SET CLUSTER SETTING sql.log.slow_query.internal_queries.enabled = 'true';
Благодаря этому стало ясно, что используемый в приложении драйвер PostgreSQL JDBC при старте делает запросы к pg_catalog, а наличие базы Keyсloak сильно влияет на скорость работы этих запросов. Мы пробовали загрузить несколько копий базы и с каждый загруженным экземпляром скорость работы pg_catalog падала всё ниже и ниже:
I201130 10:52:27.993894 5920071 sql/exec_log.go:225 ⋮ [n3,client=‹10.111.7.3:38470›,hostssl,user=‹db1›] 3 112.396ms ‹exec› ‹"PostgreSQL JDBC Driver"› ‹{}› ‹"SELECT typinput = 'array_in'::REGPROC AS is_array, typtype, typname FROM pg_catalog.pg_type LEFT JOIN (SELECT ns.oid AS nspoid, ns.nspname, r.r FROM pg_namespace AS ns JOIN (SELECT s.r, (current_schemas(false))[s.r] AS nspname FROM ROWS FROM (generate_series(1, array_upper(current_schemas(false), 1))) AS s (r)) AS r USING (nspname)) AS sp ON sp.nspoid = typnamespace WHERE typname = $1 ORDER BY sp.r, pg_type.oid DESC"› ‹{$1:"'jsonb'"}› 1 ‹""› 0 ‹{ LATENCY_THRESHOLD }›
Вот тот же запрос, но с загруженной проблемной базой:
I201130 10:36:00.786376 5085793 sql/exec_log.go:225 ⋮ [n2,client=‹192.168.114.18:21850›,hostssl,user=‹db1›] 67 520.064ms ‹exec› ‹"PostgreSQL JDBC Driver"› ‹{}› ‹"SELECT typinput = 'array_in'::REGPROC AS is_array, typtype, typname FROM pg_catalog.pg_type LEFT JOIN (SELECT ns.oid AS nspoid, ns.nspname, r.r FROM pg_namespace AS ns JOIN (SELECT s.r, (current_schemas(false))[s.r] AS nspname FROM ROWS FROM (generate_series(1, array_upper(current_schemas(false), 1))) AS s (r)) AS r USING (nspname)) AS sp ON sp.nspoid = typnamespace WHERE typname = $1 ORDER BY sp.r, pg_type.oid DESC"› ‹{$1:"'jsonb'"}› 1 ‹""› 0 ‹{ LATENCY_THRESHOLD }›
Получается, что тормозили системные таблицы CockroachDB.
После того, как клиент подтвердил проблемы с производительностью уже в облачной инсталляции CockroachDB, источник проблемы стал проясняться: было похоже на улучшенную поддержку SQL, что появилась в релизе 20.2. План запросов к схеме pg_catalog заметно отличался от 20.1.8, и мы стали свидетелями регрессии.
Собрав все факты, сделали issue на GitHub, где разработчики после нескольких попыток воспроизведения проблемы смогли подтвердить её и пообещали решить в скором времени. Исходя из этого клиент принял решение переходить на новую версию, так как сейчас баг мешает нам только при старте, увеличивая время старта инстанса приложения.
ОБНОВЛЕНО (уже после написания статьи): Проблемы были исправлены в релизе CockroachDB 20.2.3 в Pull Request 57574.
Заключение
Как видно, иногда даже очевидные и простые операции могут повлечь за собой головную боль. Но выход всё равно можно найти, не так ли?… Надеюсь, эти истории помогут и другим инженерам в повседневной работе. Stay tuned!
P.S.
Читайте также в нашем блоге:
