PostgreSQL, RED, Golden Signals: руководство к действию
Методы наблюдения Golden Signals и RED являются шаблонами при построении мониторинга сервисов и определяют ключевые метрики которые нужны при наблюдении. Раньше об этих методах знали исключительно администраторы мониторинга или SRE-инженеры. Сейчас тема инструментирования приложений уже не является чем-то новым и об этих методах знают более-менее все.
В этом посте я порассуждаю о том как в мониторинге покрыть PostgreSQL используя методы RED и Golden Signals. Подсистема мониторинга в Postgres реализована в те времена когда RED и Golden Signals еще не было и на мой скромный взгляд в ней есть некоторые недостатки и с ходу натянуть RED или Golden Signals на Postgres может показаться непростой задачей. В этом посте я постараюсь коротко рассмотреть возможности которые предоставляет Postgres для реализации наблюдения по методам RED/Golden Signals и дам конкретные направления к тому чтобы реализовать это. К тому же это на так сложно как можно подумать.
Я относительно давно знаком с RED и Golden Signals и есть несколько причин почему стоит использовать эти методы:
мониторинг по этим методам позволяет быстро (но при этом поверхностно) определить все ли в порядке с сервисом.
при наличии широкого покрытия другими метриками, при исследовании проблемы можно углубляться в нужном направлении исключая менее важные.
они более-менее универсальны и применимы как к веб-сервисам, так и к системным сервисам которые не ориентированы на прямую работу с пользователем.
являются хорошим началом чтобы закрыть базовые потребности в мониторинге для любого сервиса.
В общем случае, если перед тобой непонятный сервис который надо замониторить, то просто берем RED или Golden Signals и как по списку настраиваем сбор нужной информации и отдачу метрик. На выходе получаем базовый минимум (в виде дашборда) который в целом дает достаточное представление о том хорошо или плохо работает сервис. Далее уже можно реализовать более детальные или сервис-специфичные вещи. Но впрочем у этих методов есть и недостатки, поэтому не стоит думать что эти методы закроют все возможные потребности в метриках.
Что ж надеюсь получилось убедительно, давайте перейдем к Postgres’у.
Суть RED и Golden Signals это измерение количественных характеристик проходящего через сервис трафика, на примере RED это:
Request rate — количество запросов в секунду.
Request errors — количество ошибочных запросов в секунду.
Request duration — время затраченное на выполнение запросов (в идеале гистограмма с распределением количества запросов по времени выполнения).
В Golden Signals примерно всё тоже самое (и вообще он появился первым), но другими словами (Latency, Traffic, Errors), плюс там присутствует Saturation — объем работы который не может быть обслужен в данный момент, но его надо сделать, поэтому он поставлен в очередь.
Несмотря на то что оба этих метода были предложены для наблюдения за HTTP (микро)сервисами, их можно использовать и для наблюдения за другими запросо-ориентированными сервисами, включая и СУБД. Любую СУБД можно представить как сервис который обслуживает запросы от клиентов (Requests), запросы могут выполняться как успешно так и с ошибками (Errors), запросы выполняются определенное время (Duration), доступ к ресурсам осуществляется конкурентно с использованием блокировок и доступ может быть ограничен в результате чего выстроится очередь ожидающих (Saturation).
Небольшое отступление. Перед тем как продолжить, стоит определиться что будет подразумеваться под «запросом». Обычный SQL-запрос или SQL-транзакция? Под отдельным запросом будет считаться SQL-запрос, т.к. приложение оперирует именно отдельными командами и лишь при необходимости может выстраивать их в транзакции, следовательно 1 запрос = 1 SQL-команда. Также с точки зрения собственной наблюдаемости приложение может должно иметь собственные RED метрики и дополнительно снабжать каждую SQL-команду метаданными о ней (request_id, информация об отправителе, метод/контроллер и т.п.).
Requests
Начнем по порядку, R — requests. Запросы это клиентская активность, нет клиентов — нет запросов. Для наблюдения за клиентской активностью в Postgres есть несколько представлений (views). Но пока интерес представляет лишь одна из них.
pg_stat_statements. Это отдельное расширение которое нужно отдельно настроить и включить. В этом представлении собрана per-statement статистика, и для каждого statement (запроса) есть поле calls которое показывает количество вызовов этого конкретного запроса. Сумма всех calls показывает количество обработанных запросов. Важно отметить что в pg_stat_statements фиксируются только успешно выполненные запросы.
Однако с pg_stat_statements есть нюанс. У расширения есть настраиваемый режим трекинга — параметр pg_stat_statements.track указывает о том как выполнять подсчет. У параметра доступно 2 значения. Первое значение »top» указывает считать только прямые вызовы запросов. И второе значение »all» указывает считать вызовы вложенные в хранимые процедуры и функции. С точки зрения наблюдения за запросами предпочтительно иметь значение »top», т.к. если клиент отправляет запрос на вызов хранимой функции, то все вложенные в функцию запросы, выполняются на стороне СУБД и не могут считаться отдельными запросами от приложения.
Чтобы получить данные достаточно сделать довольно простой запрос к pg_stat_statements.
SELECT sum(calls) FROM pg_stat_statements;Полученную цифру нужно обернуть в метрику с помощью тех инструментов которые приняты в конкретной экосистеме мониторинга. Например в случае Prometheus, это задача реализуется экспортером, в Zabbix это будет UserParameter.
А еще в голову может прийти мысль использовать pg_stat_activity или pg_stat_database. Отбрасываем эту мысль, pg_stat_activity не подходит для подсчета запросов, т.к. показывает снимки (snapshot) активности в момент обращения к ней, и то что происходит между обращениями остается неизвестным. Во второй же хоть и есть интересное поля типа xact_commit, но оно не совсем подходит для нашей задачи т.к. оперирует транзакциями. Впрочем, мы воспользуемся этим представлением дальше.
Errors
Для оценки количества ошибок или там скажем «запросов которые завершились ошибкой» вернемся к ранее упомянутой pg_stat_database. В этом представлении есть поле xact_rollback которое является счетчиком откатов транзакций. Откат как правило случается из-за ошибки запроса внутри транзакции, либо приложение может вызвать откат явно. Поэтому достаточно всего лишь одной ошибки внутри транзакции чтобы привести к откату всей транзакции. А сейчас важный момент, отдельно выполненная SQL-команда (даже если она явно не обернута в блок BEGIN … END) также считается транзакцией и ошибка при выполнении команды также будет фиксироваться в xact_rollback. Отсюда следует что поля xact_rollback достаточно чтобы фиксировать ошибки при выполнении запросов.
Для получения информации опять же не требуется глубоких познаний в SQL.
SELECT sum(xact_rollback) FROM pg_stat_database;Однако тут есть небольшой недостаток, такой подход показывает ошибки только связанные с обработкой запросов. Но в течение всего времени функционирования СУБД, могут возникать и другие ошибки не связанные с обработкой запросов. Хотя такие ошибки случаются редко, но всё равно важно знать о них. К сожалению пока в Postgres нет представления которое бы предоставляло удобный интерфейс к статистике ошибок и такая информация может быть получена только из журналов.
Duration
Для подсчета времени выполнения запросов нам снова понадобится pg_stat_statements и конкретно поле total_time. Это поле показывает в миллисекундах время выполнения (включая ожидание) для каждого типа запросов. Соответственно чтобы получить суммарное время выполнения запросов нужно сложить total_time всех запросов.
SELECT sum(total_time) FROM pg_stat_statements;Значение будет в миллисекундах, при желании можно домножить, т.к. например в Prometheus принято приводить время к секундам. В идеале конечно хотелось бы иметь гистограмму с распределением количества запросов по временным диапазонам, но pg_stat_statements под капотом выполняется свою агрегацию и наружу отдает только агрегаты. Помимо total_time ещеесть min_time, max_time, mean_time, stddev_time. Начиная с версии 13 добавлены новые поля которые показывают время планирования запросов. Но это уже DBA-specific вещи, о них может как-нибудь в другой раз.
Saturation
Последний пункт это насыщенность (saturation), которого нет в RED методе, но который присутствует в Golden Signals. Напомню что насыщенность (она же сатурация) это ситуация когда выполнение запроса отложено в очередь, следовательно в контексте обработки запросов в СУБД нам важно видеть ситуации когда запросы не обрабатываются (при этом нет и ошибок).
Немного теории
Количество одновременных подключений к базе ограничено значением параметра max_connections. Однако на практике редко кто доходит до этого ограничения, обычно проблемы начинаются раньше. Чтобы достичь состояния сатурации, достаточно выполнить два условия: 1) нужны idle транзакции 2) нужен более-менее устойчивый tps с запросами на запись внутри. Если выполнить эти два условия, то проблемная ситуация как правило выглядит так: приложение в транзакции обновляет строки в таблице, оставляет транзакцию открытой (чтоб вернуться к ней позже), но уже не возвращается. Конкурентные обновления встают в очередь и ждут когда завершится первая транзакция. Новые запросы приходят и встают в очередь вытесняя всех остальных, до тех пор пока не будет достигнут лимит max_connections, после чего все новые запросы будут отклонены с ошибкой. Либо пока первая транзакция не завершит работу сама или принудительно администратором.
Для обнаружения ситуаций когда запросы откладываются нам понадобится представление pg_stat_activity. Это не идеальный вариант, однако за ничего лучшего пока нет, будем использовать то что есть.
Почему не самое лучшее?
До этого момента для снятия статистики рассматривались счетчики (COUNTER) которые в фоновом режиме накапливают информацию. Счетчики удобны тем что «не теряют» информацию (сброс счетчика или его переполнение не в счет, это явление все-таки редкое). Если значение счетчика менялось быстро или наоборот медленно это можно увидеть построив частотный график. Представление pg_stat_activity по сути представляет собой набор GAUGES (шкала) и показывает актуальные данные только в момент обращения. Следовательно неизвестно что происходило в момент между обращениями. А происходить могло много чего — например при OLTP нагрузке, в одной секунде могут быть выполнены тысячи запросов/транзакций и при работе с GAUGE мы просто этого не узнаем. Это существенный недостаток метрик типа GAUGES.
Если закрыть глаза на недостатки GAUGE, то в целом минутной гранулярности при снятии значений нам хватит чтобы фиксировать проблемы. А если есть возможность снимать значения чаще, то это хорошо. Итак нам понадобится:
SELECT
count(*) FILTER (WHERE state IS NOT NULL) AS total,
count(*) FILTER (WHERE state = 'idle') AS idle,
count(*) FILTER (WHERE state IN ('idle in transaction', 'idle in transaction (aborted)')) AS idle_in_xact,
count(*) FILTER (WHERE state = 'active') AS active,
count(*) FILTER (WHERE wait_event_type = 'Lock') AS waiting,
count(*) FILTER (WHERE state IN ('fastpath function call','disabled')) AS others
FROM pg_stat_activity WHERE backend_type = 'client backend';Также потребуется информация о том как долго транзакции находятся в простое и как долго находится в ожидании самый первый в очереди. Для этого потребуются поля xact_start — время начала транзакции, и state_change — время перехода из предыдущего состояния в текущее — по сути это время перехода в active режим с последующим ожиданием.
SELECT coalesce(max(extract(epoch FROM clock_timestamp() - xact_start)),0) AS max_idle_seconds
FROM pg_stat_activity
WHERE state IN ('idle in transaction', 'idle in transaction (aborted)');SELECT coalesce(max(extract(epoch FROM clock_timestamp() - state_change)),0) AS max_idle_seconds
FROM pg_stat_activity
WHERE wait_event_type = 'Lock';Как вы могли заметить здесь запросы уже чуть подлиннее предыдущих, но в целом ничего сложного. Все полученные значения также нужно обернуть в метрики. Через метрики насыщенности важно:
отслеживать массовые появления состояний idle in transactions и waiting и оперативно устранять причины их появления.
отслеживать любое даже единичное появления долгих idle транзакций.
отслеживать появление долгого ожидания клиентов.
Итого
Чтобы добавить метрики для наблюдения за Postgres’ом по методам RED или Golden Signals понадобится базовое знание SQL и несколько представлений. Нужные источники данных находятся в разных представлениях, что слегка неудобно, но и не так страшно. Итак, request rate берется на основе pg_stat_statements.calls. Request errors на основе pg_stat_database.xact_rollback. Request duration на основе pg_stat_statements.total_time. Saturation на основе state, wait_event_type, xact_start, state_change из pg_stat_activity.
На выходе у вас должно получиться 6 метрик, на основе которых можно составить небольшой обзорный дашборд из пары-тройки панелей и графиков которые в будущем можно снабдить drilldown-ссылками на более детальные дашборды/графики. По сути это отправная точка начиная с которой можно двигаться дальше и постепенно расширять мониторинг Postgres’а.
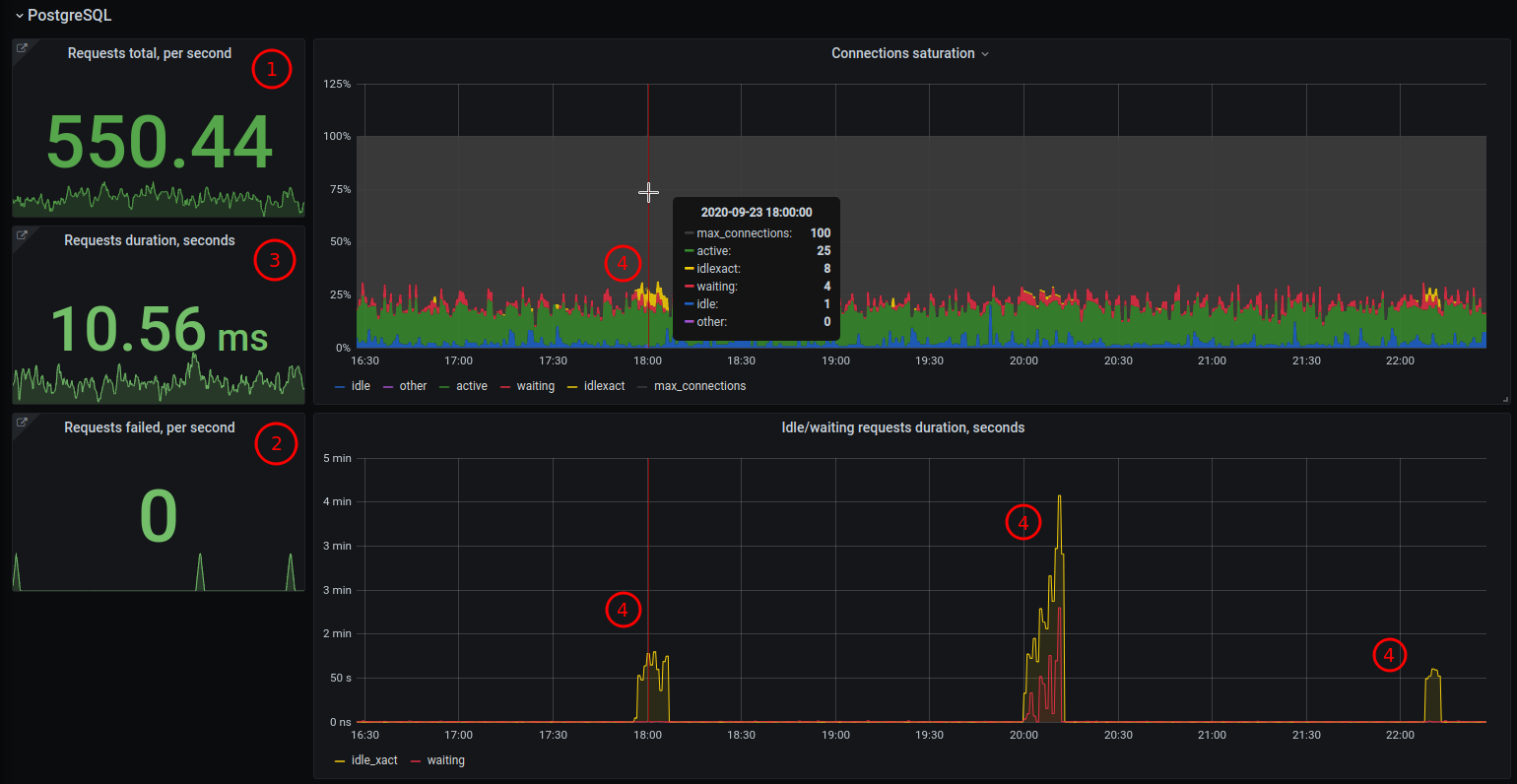 Примерно в таком ключе можно организовать дашборд.
Примерно в таком ключе можно организовать дашборд.
Как пользоваться таким дашбордом?
смотрим на Requests. Если их меньше или больше обычного, ищем причины почему так. Откуда и почему пришла нагрузка, не сломался ли кэш или наоборот почему так мало нагрузки, живы ли приложения.
смотрим на Errors. Нету ошибок хорошо, есть ошибки — повод заглянуть в кибану/логи и посмотреть что за ошибки и устранить их.
смотрим на Duration. Если растет время, идем разбираться с запросами. Какие запросы выполняются дальше остальных и почему.
смотрим на Saturation. Появились idle транзакции или waiting и ползут вверх, идем в БД и разбираемся откуда они. Для системного решения скорей всего придется чинить приложение, в качестве временного ad-hoc решения принудительно завершаем idle транзакции.
Вот как-то так.
Еще добавлю что мы в Weaponry отслеживаем эти вещи и если ваш Postgres злоупотребляет ошибками, idle транзакциями или блокировками, то Weaponry подскажет что делать.
Если вы еще хотите узнать что-то о мониторинге около-Postgres’а, пишите об этом в комментариях.
