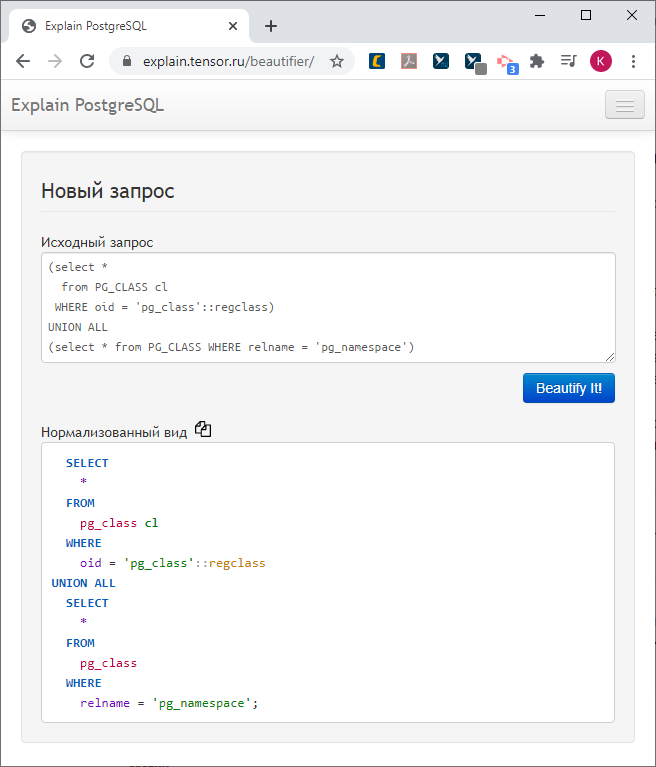
PostgreSQL Query Profiler: как сопоставить план и запрос
Многие, кто уже пользуется explain.tensor.ru — нашим сервисом визуализации планов PostgreSQL, возможно, не в курсе одной из его суперсособностей — превращать сложно читаемый кусок лога сервера…

… в красиво оформленный запрос с контекстными подсказками по соответствующим узлам плана:

В этой расшифровке второй части своего доклада на PGConf.Russia 2020 я расскажу, как нам удалось это сделать.
С транскриптом первой части, посвященной типовым проблемам производительности запросов и их решениям, можно ознакомиться в статье «Рецепты для хворающих SQL-запросов».
Сначала займемся раскраской — и раскрашивать будем уже не план, его мы уже разукрасили, он у нас уже красивый и понятный, а запрос.
Нам показалось, что вот так неформатированной «простыней» вытащенный из лога запрос выглядит очень уж некрасиво и потому — неудобно.
Особенно, когда разработчики в коде «клеят» тело запроса (это, конечно, антипаттерн, но бывает) в одну строку. Жуть!
Давайте это нарисуем как-то более красиво.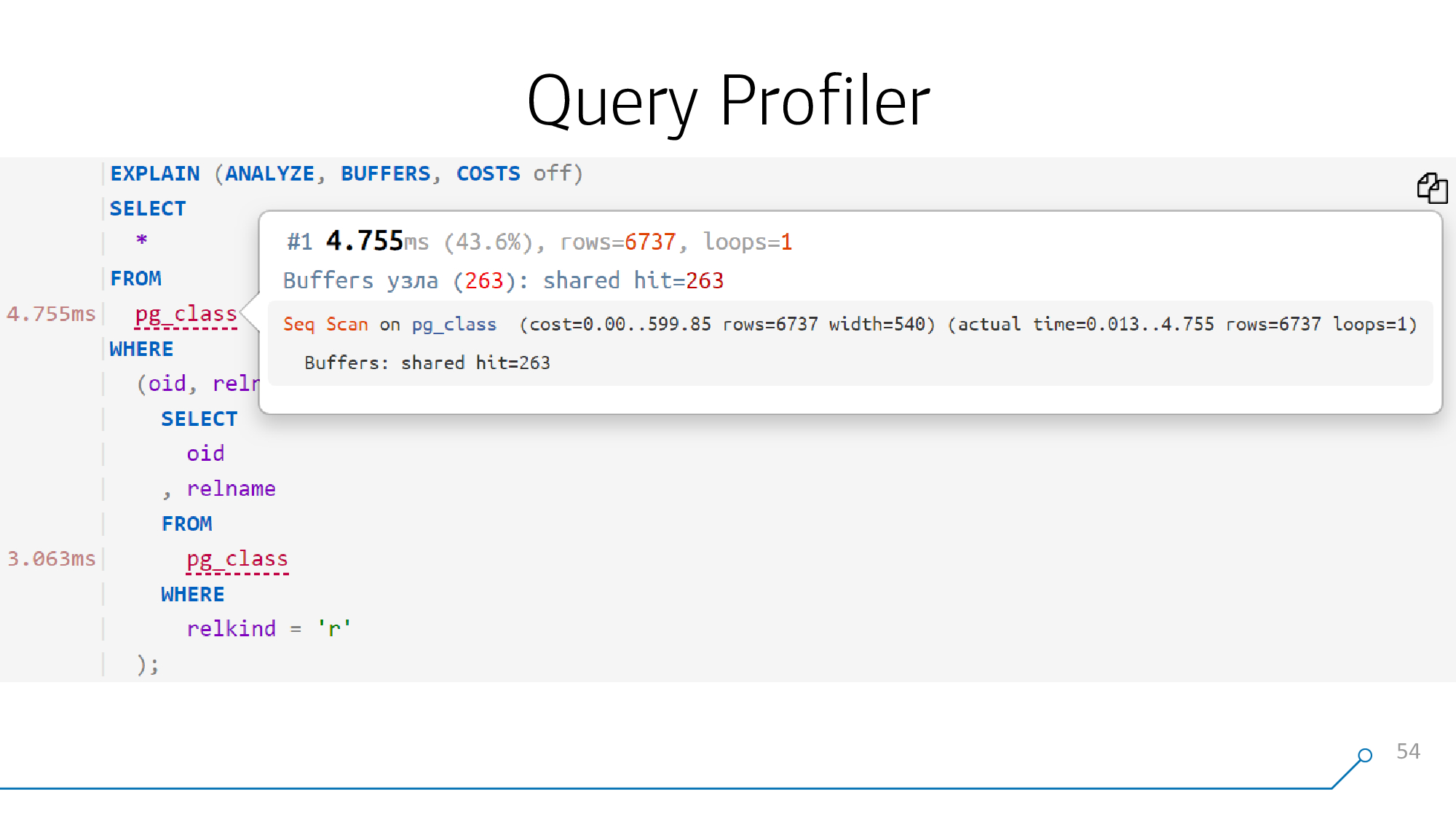
А если мы сможем это нарисовать красиво, то есть разобрать и собрать обратно тело запроса, то потом сможем и к каждому объекту этого запроса «прицепить» подсказку — что происходило в соответствующей точке плана.
Синтаксическое дерево запроса
Чтобы это сделать, запрос сначала нужно разобрать.
Поскольку, у нас ядро системы работает на NodeJS, то мы сделали к нему модулек, можете на GitHub его найти. На самом деле, это является расширенными «биндингами» к внутренностям парсера самого PostgreSQL. То есть просто бинарно скомпилирована грамматика и к ней сделаны биндинги со стороны NodeJS. Мы взяли за основу чужие модули — тут тайны никакой большой нет.
Скармливаем тело запроса на вход нашей функции — на выходе получаем разобранное синтаксическое дерево в виде JSON-объекта.
Теперь по этому дереву можно пробежаться в обратную сторону и собрать запрос с теми отступами, раскраской, форматированием, которое нам хочется. Нет, это не настраивается, но нам показалось, что именно так будет удобно.
Сопоставление узлов запроса и плана
Теперь посмотрим, как можно совместить план, который мы разобрали на первом шаге, и запрос, который разобрали на втором.
Давайте возьмем простой пример — у нас есть запрос, который формирует CTE и два раза из нее читает. Он генерирует такой план.
CTE
Если на него внимательно посмотреть, что до 12-й версии (или начиная с нее с ключевым словом MATERIALIZED) формирование CTE является безусловным барьером для планировщика.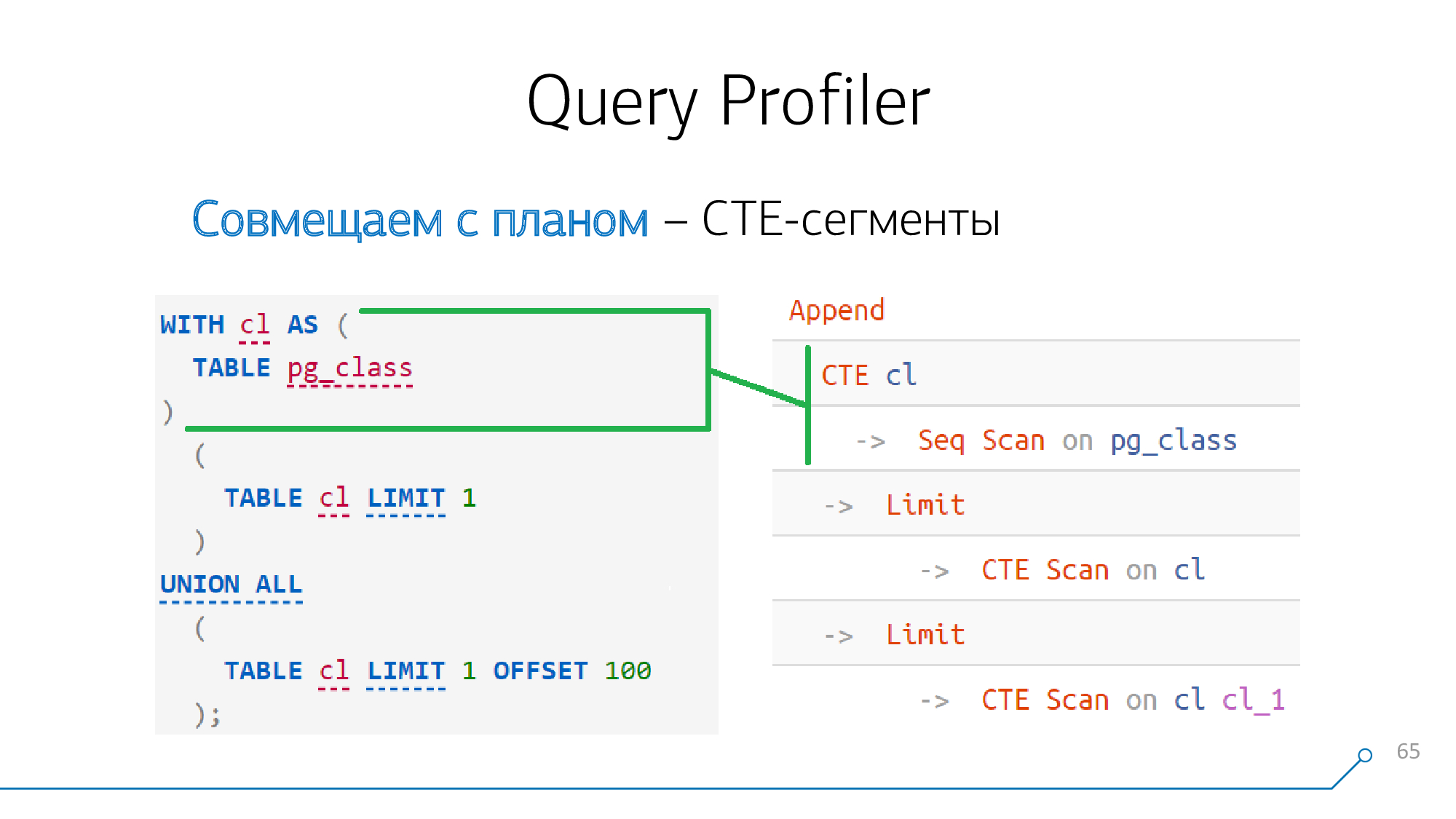
А, значит, если мы видим где-то в запросе генерацию CTE и где-то в плане узел CTE, то эти узлы однозначно между собой «бьются», мы можем сразу же их совместить.
Задача «со звездочкой»: CTE бывают вложенные.
Бывают очень плохо вложенные, и даже одноименные. Например, вы можете внутри CTE A сделать CTE X, и на том же уровне внутри CTE B сделать опять CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...
При сопоставлении вы должны это понимать. Понимать это «глазами» — даже видя план, даже видя тело запроса — очень тяжело. Если у вас генерация CTE сложная, вложенная, запросы большие — тогда и вовсе неосознаваемо.
UNION
Если у нас в запросе есть ключевое слово UNION [ALL] (оператор соединения двух выборок), то ему в плане соответствует либо узел Append, либо какой-нибудь Recursive Union.
То, что «сверху» над UNION — это первый потомок нашего узла, что «снизу» — второй. Если через UNION у нас «поклеено» несколько блоков сразу, то Append-узел все равно будет только один, а вот детей у него будет не два, а много — по порядку как они идут, соответственно:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Задача «со звездочкой»: внутри генерации рекурсивной выборки (WITH RECURSIVE) тоже может быть больше одного UNION. Но всегда рекурсивным является только самый последний блок после последнего UNION. Все, что выше — это один, но другой UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2, тут кончается генерация стартового состояния рекурсии
UNION ALL
(...) -- #3, только этот блок рекурсивный и может содержать обращение к T
)
...
Такие примеры тоже надо уметь «расклеивать». Вот в этом примере мы видим, что UNION-сегментов в нашем запросе было 3 штуки. Соответственно, одному UNION соответствует Append-узел, а другому — Recursive Union.
Чтение-запись данных
Все, разложили, теперь мы знаем, какой кусочек запроса какому кусочку плана соответствует. И в этих кусочках мы можем легко и непринужденно найти те объекты, которые «читаются».
С точки зрения запроса мы не знаем — таблица это или CTE, но обозначаются они одинаковым узлом RangeVar. А в плане «читается» — это тоже достаточно ограниченный набор узлов:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
Структуру плана и запроса мы знаем, соответствие блоков знаем, имена объектов знаем — делаем однозначное сопоставление.
Опять-таки задача «со звездочкой». Берем запрос, выполняем, у нас никаких алиасов нет — мы просто два раза из одной CTE почитали.
Смотрим в план — что за беда? Почему у нас алиас вылез? Мы его не заказывали. Откуда он такой «номерной»?
PostgreSQL сам его добавляет. Надо просто понимать, что именно такой алиас для нас для целей сопоставления с планом никакого смысла не несет, он просто здесь добавлен. Не будем на него обращать внимания.
Вторая задача «со звездочкой»: если у нас идет чтение из секционированной таблицы, то мы получим узел Append или Merge Append, который будет состоять из большого количества «детей», и каждый из которых будет каким-то Scan'ом из таблицы-секции: Seq Scan, Bitmap Heap Scan или Index Scan. Но, в любом случае, эти «дети» будут не сложными запросами — так эти узлы и можно отличать от Append при UNION.
Такие узлы мы тоже понимаем, собираем «в одну кучку» и говорим:»все, что ты читал из megatable — это вот тут и вниз по дереву».
«Простые» узлы получения данных

Values Scan в плане соответствует VALUES в запросе.
Result — это запрос без FROM вроде SELECT 1. Или когда у вас заведомо ложное выражение в WHERE-блоке (тогда возникает атрибут One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- или 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan «мапятся» на одноименные SRF.
А вот с вложенными запросами все сложнее — к сожалению, они не всегда превращаются в InitPlan/SubPlan. Иногда они превращаются в ... Join или ... Anti Join, особенно когда вы пишете что-то вроде WHERE NOT EXISTS .... И вот там совмещать не всегда получается — в тексте плана соответствующих узлам плана операторов нет.
Опять-таки задача «со звездочкой»: несколько VALUES в запросе. В этом случае и в плане вы получите несколько узлов Values Scan.
Отличить их один от другого помогут «номерные» суффиксы — он добавляется именно в порядке нахождения соответствующих VALUES-блоков по ходу запроса сверху вниз.
Обработка данных
Вроде все в нашем запросе разобрали — остался только Limit.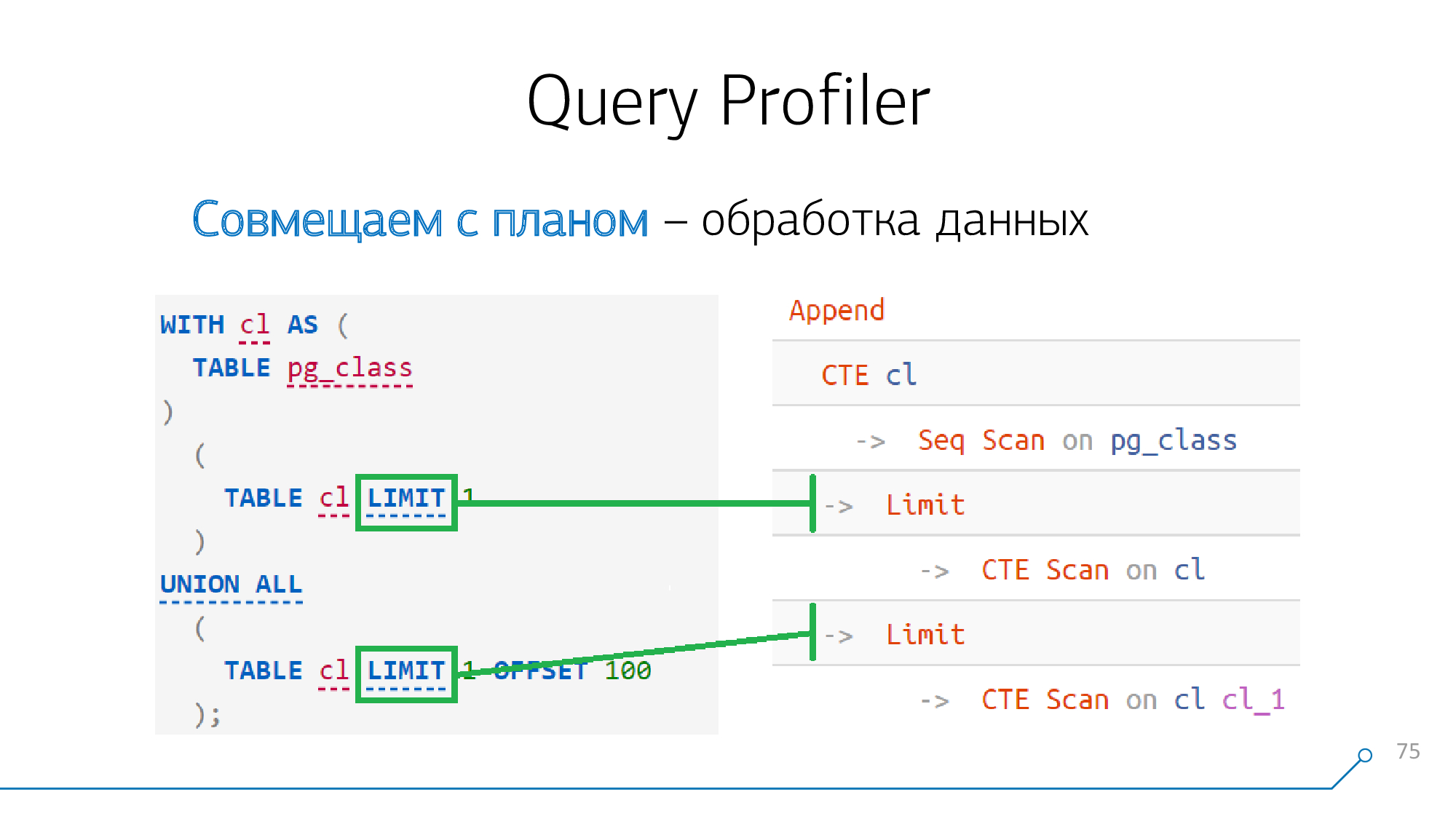
Но тут все просто — такие узлы как Limit, Sort, Aggregate, WindowAgg, Unique «мапятся» один-в-один на соответствующие операторы в запросе, если они там есть. Тут никаких «звездочек» и сложностей нет.
JOIN
Сложности возникают, когда мы хотим совместить JOIN между собой. Это сделать не всегда, но можно.
С точки зрения парсера запроса, у нас есть узел JoinExpr, у которого ровно два потомка — левый и правый. Это, соответственно, то что «над» вашим JOIN и то что «под» ним в запросе написано.
А с точки зрения плана это два потомка у какого-то * Loop/* Join-узла. Nested Loop, Hash Anti Join, … — вот что-то такое.
Воспользуемся простой логикой: если у нас есть таблички A и B, которые «джойнятся» между собой в плане, то в запросе они могли быть расположены либо A-JOIN-B, либо B-JOIN-A. Попробуем совместить так, попробуем совместить наоборот, и так пока такие пары не кончатся.
Возьмем наше синтаксическое дерево, возьмем наш план, посмотрим на них… непохоже! 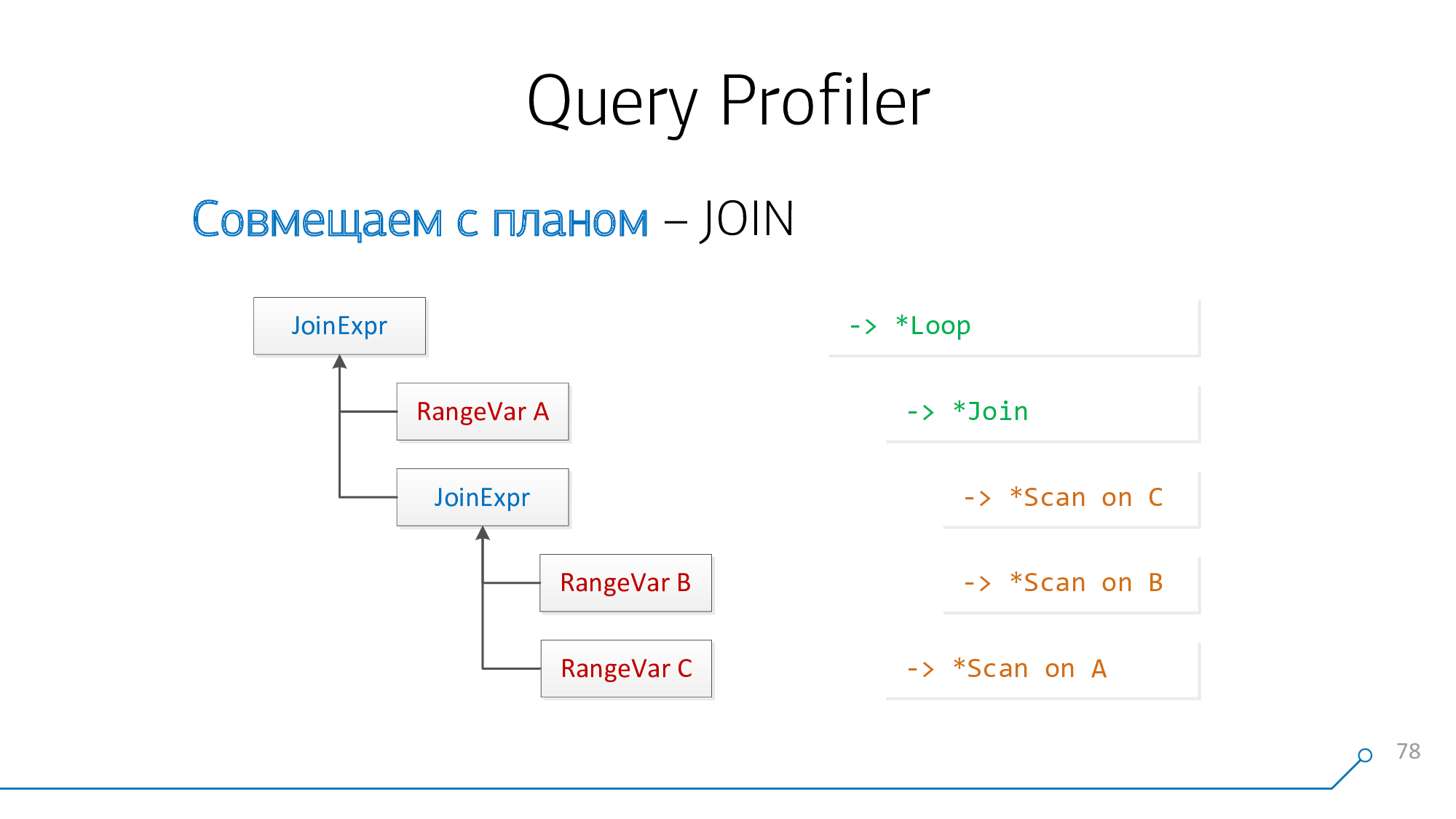
Перерисуем в виде графов — о, уже стало что-то на что-то похоже! 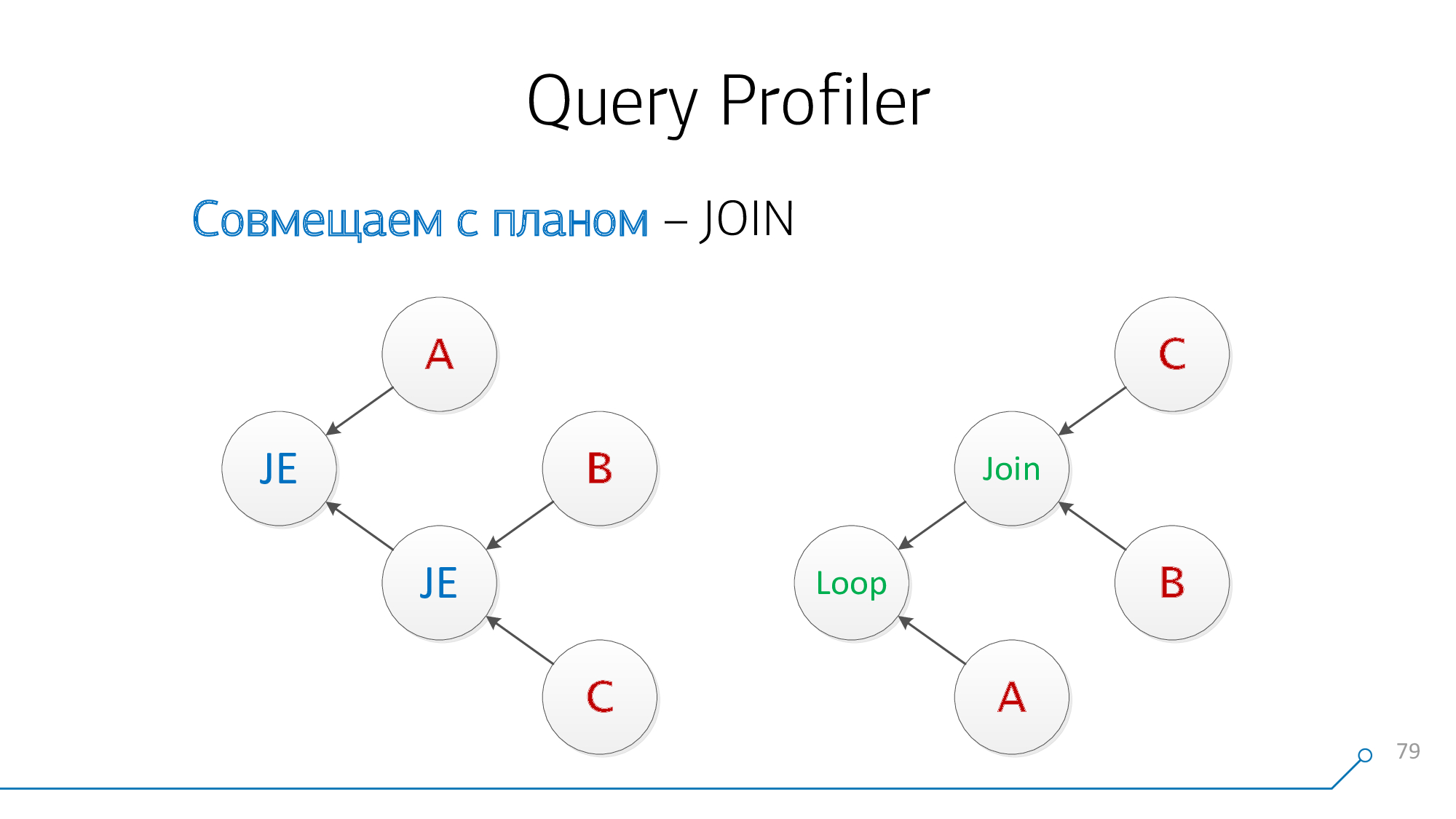
Давайте обратим внимание, что у нас есть узлы, у которых одновременно есть дети B и C — нам неважно в каком порядке. Совместим их и перевернем картинку узла.
Посмотрим еще раз. Теперь у нас есть узлы с детьми A и пары (B + C) — совместим и их.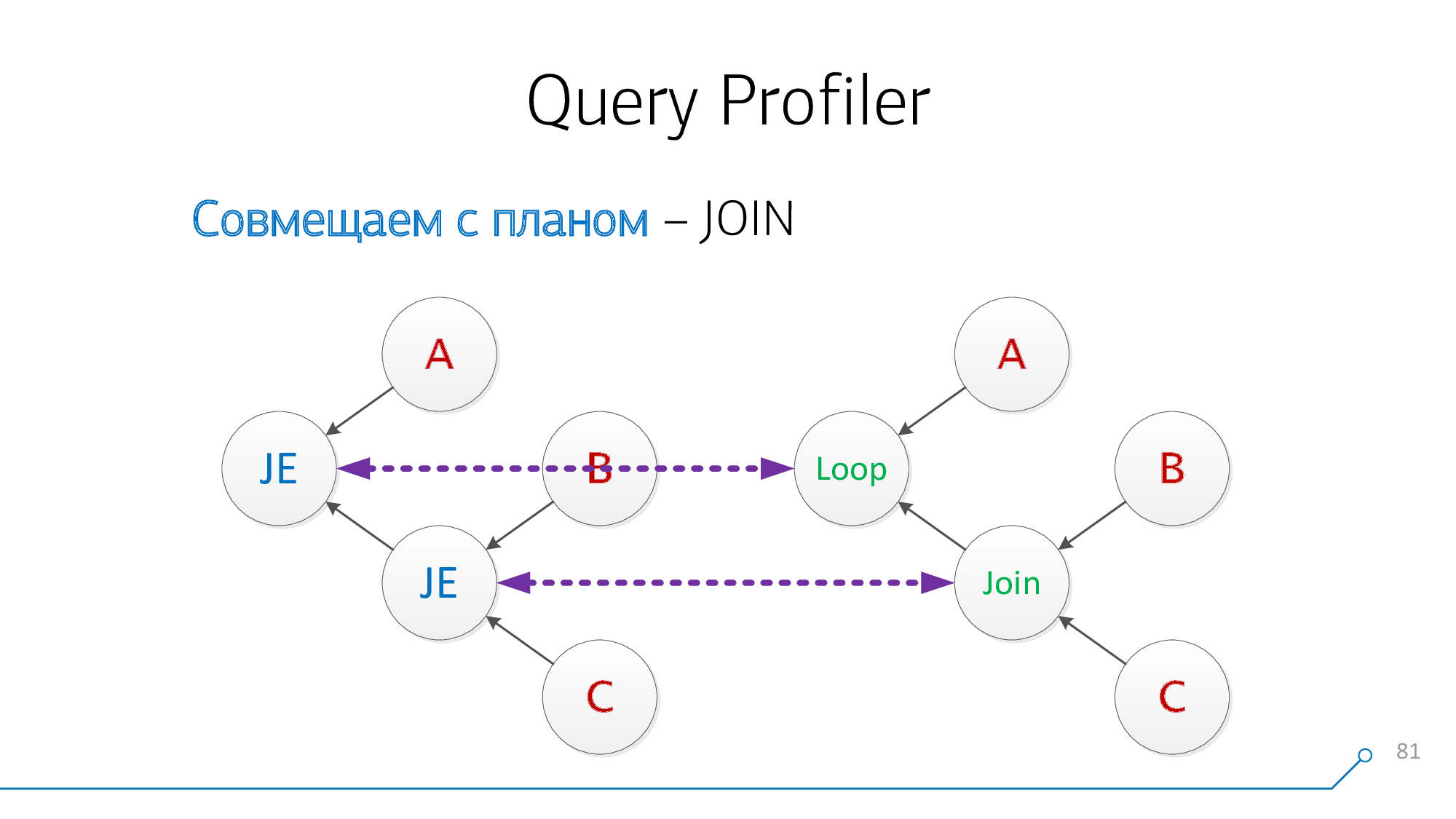
Отлично! Получается, что мы эти два JOIN из запроса с узлами плана удачно совместили.
Увы, эта задача решается не всегда.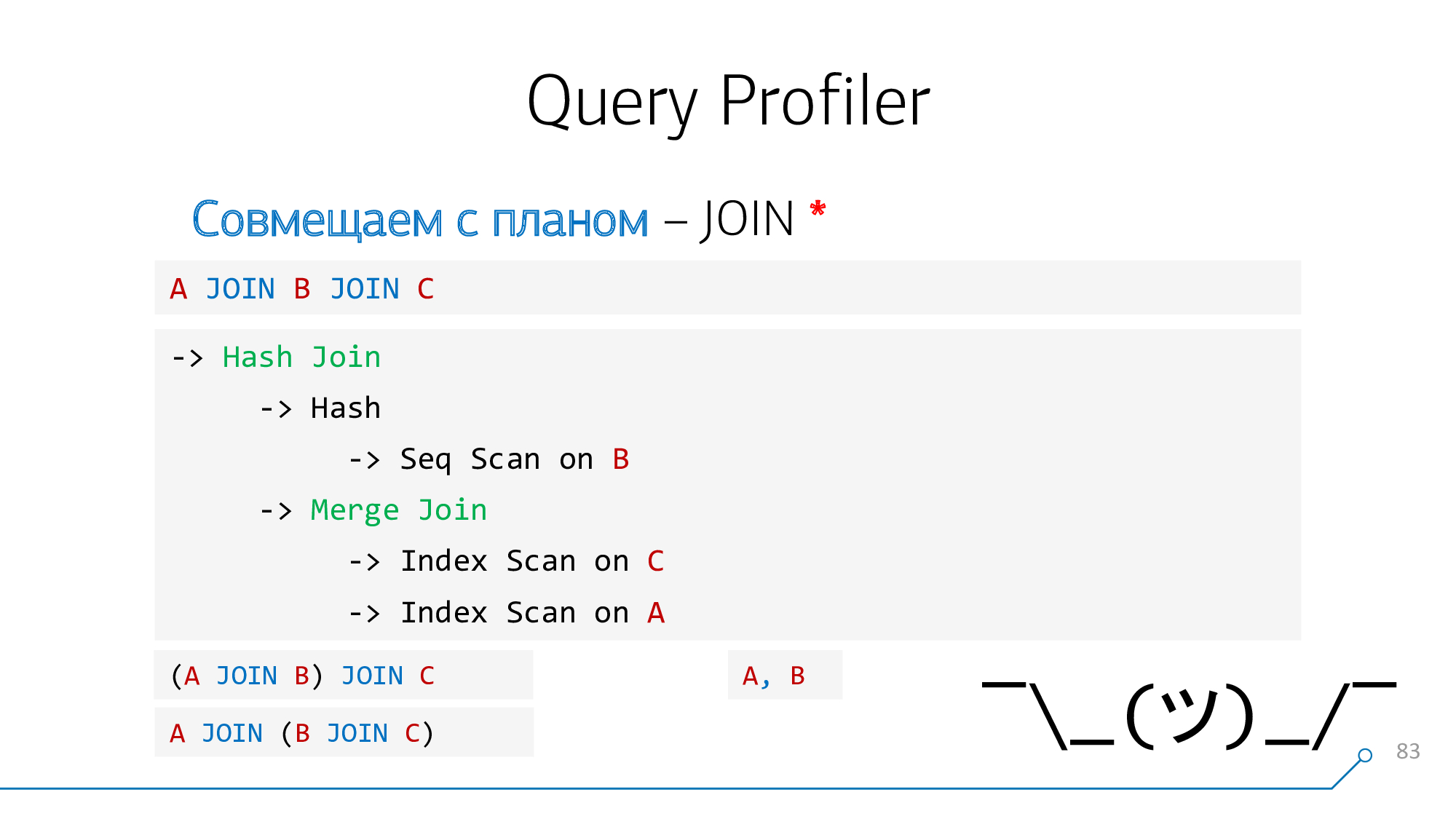
Например, если в запросе A JOIN B JOIN C, а в плане в первую очередь соединились «крайние» узлы A и C. А в запросе нет такого оператора, нам нечего подсветить, не к чему привязать подсказку. То же самое с «запятой», когда вы пишете A, B.
Но, в большинстве случаев, почти все узлы удается «развязать» и получить вот такой профайлинг слева по времени — буквально, как в Google Chrome, когда вы код на JavaScript анализируете. Вы видите сколько времени каждая строка и каждый оператор «выполнялись».
А чтобы вам всем этим было удобнее пользоваться, мы сделали хранение архива, где вы можете сохранить и потом найти свои планы вместе с ассоциированными запросами или с кем-то поделиться ссылкой.
Если же вам надо просто привести нечитаемый запрос в адекватный вид, воспользуйтесь нашим «нормализатором».