PostgreSQL Antipatterns: где скаляру в GiST место?
 Картинка из статьи Егора Рогова
Картинка из статьи Егора Рогова
В PostgreSQL есть «волшебный» тип индекса GiST, который позволяет быстро искать разные сложные вещи — от интервалов до массивов и даже реализовывать полнотекстовый поиск.
Про его внутреннее устройство и возможности подробно рассказывал Егор Рогов, а я в статье «PostgreSQL Antipatterns: работаем с отрезками в «кровавом энтерпрайзе» показал, как с помощью расширения btree_gist он позволяет решать типовые бизнес-задачи.
Одной из таких задач является поиск отрезков внутри сегмента со скалярным идентификатором. И если для btree очевидно, что поле с меньшей кардинальностью должно стоять в индексе раньше — индекс от этого и меньше и быстрее (см. «DBA: находим бесполезные индексы»), то так ли это однозначно для btree_gist?
Давайте создадим модель, где миллион интервалов дат распределен по тысяче сегментов:
CREATE TABLE ranges(
segment
integer
, dtb -- начало интервала
date
, dte -- окончание интервала
date
);
INSERT INTO ranges(
segment
, dtb
, dte
)
SELECT
(random() * 1e3)::integer -- 1K сегментов
, dtb
, dtb + (random() * 1e3)::integer -- 1K возможных дат окончания
FROM
(
SELECT
now()::date - (random() * 1e3)::integer dtb -- 1K возможных дат начала
FROM
generate_series(1, 1e6) -- 1M интервалов
) T;
ANALYZE ranges; -- не забываем собрать статистикуАктивируем расширение btree_gist и создадим пару индексов:
CREATE EXTENSION btree_gist;
CREATE INDEX ranges_seg_rng ON ranges USING gist(segment, daterange(dtb, dte, '[]'));
CREATE INDEX ranges_rng_seg ON ranges USING gist(daterange(dtb, dte, '[]'), segment);Давайте сначала дадим выбрать PostgreSQL, какой из этих индексов ему «нравится» больше:
EXPLAIN (ANALYZE, BUFFERS, SUMMARY off)
SELECT
*
FROM
ranges
WHERE
segment = 1 AND -- искомый сегмент
daterange(dtb, dte, '[]') @> '2020-01-01'::date; -- интервалы, включающие точку (range, segment)
(range, segment)
0.240ms и 67 buffers, когда ищем по range_rng_seg.
Удалим этот индекс, чтобы заведомо использовался второй и повторим тот же запрос:
DROP INDEX ranges_rng_seg; (segment, range)
(segment, range)
0.198ms и 72 buffers при поиске по range_seg_rng. Читать приходится чуть больше, но зато мы получаем +20% к скорости выполнения.
Чтобы понять, откуда больше данных, давайте посмотрим на размеры наших индексов:
SELECT
relname
, pg_size_pretty(pg_relation_size(oid)) sz
FROM
pg_class
WHERE
relname ~ 'ranges'
ORDER BY
relname; relname | sz
ranges | 42 MB
ranges_rng_seg | 68 MB
ranges_seg_rng | 78 MB -- +15%, однако!Чтобы понять, почему так получилось, вспомним исходные положения задачи: 1K случайных дат начала интервала и для каждой из них 1K случайных дат конца, итого примерно миллион комбинаций на миллион записей — то есть у нас все значения daterange в таблице статистически уникальны.
Если попробовать представить визуально данный вариант, то индекс (segment, range) будет выглядеть как несколько независимых «GiST-плоскостей» точек-интервалов:
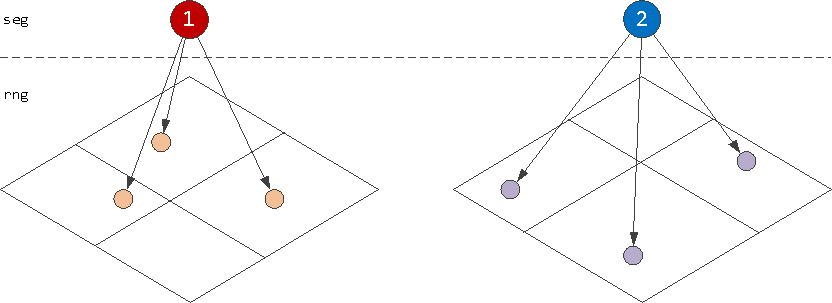 (segment, range)
(segment, range)
А вот у (range, segment) будет всего одна такая «плоскость»:
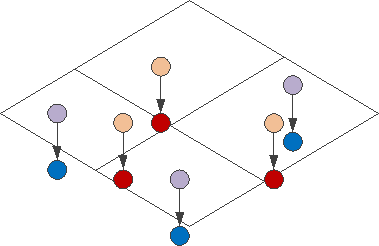
Соответственно, тут мы экономим на служебных узлах GiST-дерева в каждой «плоскости» (поэтому размер индекса меньше), но зато искать в нем приходится намного больше (и дольше), чтобы потом отбросить несоответствующие условию по сегменту.
Убедимся в своих предположениях:
SELECT
count(*) FILTER(WHERE segment = 1) seg
, count(*) FILTER(WHERE daterange(dtb, dte, '[]') @> '2020-01-01'::date) rng
FROM
ranges; seg | rng
968 | 58839То есть в случае (seg, rng) мы ищем интервал среди ~1K других, а при (rng, seg) мы отбрасываем 99.9% неподходящих сегментов.
Итого: если у вас сложное поле GiST-индекса имеет большую уникальность значений (а это почти всегда так для тех типов, которые имеет смысл так индексировать), а скалярное — существенно меньшую, то его разумнее ставить в начале.
