PostgreSQL 13: happy pagination WITH TIES
На прошедшей неделе вышло сразу две статьи (от Hubert 'depesz' Lubaczewski и автора самого патча Alvaro Herrera), посвященные реализованной в грядущей версии PostgreSQL 13 поддержке опции WITH TIES из стандарта SQL:2008:
OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES }Что это, и как оно избавляет от проблем с реализацией пейджинга, о которых я рассказывал в статье «PostgreSQL Antipatterns: навигация по реестру»?
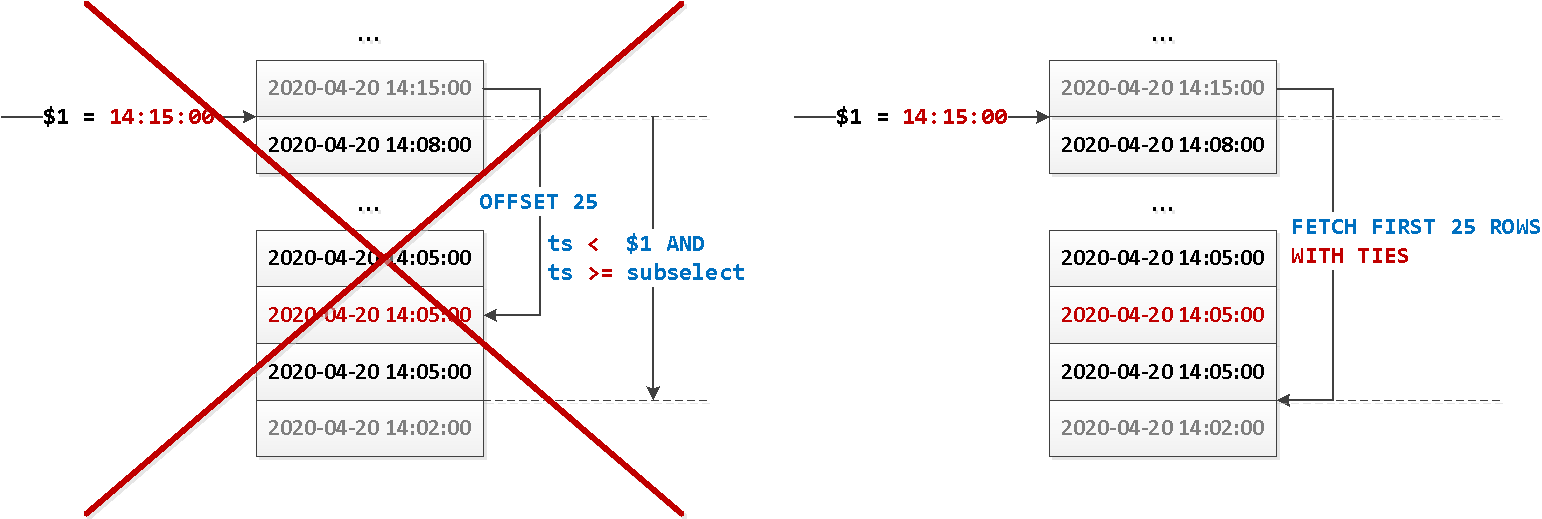
Напомню, что в той статье мы остановились на моменте, что если у нас есть табличка такого вида:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
INSERT INTO events(ts)
SELECT
now() - ((random() * 1e8) || ' sec')::interval
FROM
generate_series(1, 1e6);
… то для организации хронологического пейджинга по ней (по ts DESC) эффективнее всего использовать вот такой индекс:
CREATE INDEX ON events(ts DESC);
… и вот такую модель запроса:
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;Старый-добрый подзапрос
Давайте посмотрим на план такого запроса, если мы хотим получить очередной сегмент от начала этого года:
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
events
WHERE
ts < '2020-01-01'::timestamp AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < '2020-01-01'::timestamp
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;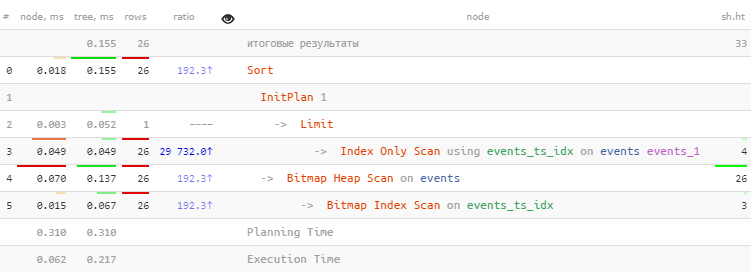
[посмотреть на explain.tensor.ru]
Зачем тут вложенный запрос? Ровно за тем, чтобы не иметь описанных в той статье проблем с «перепрыгиванием» одинаковых значений ключа сортировки между запрашиваемыми сегментами:

Пробуем WITH TIES «на зуб»
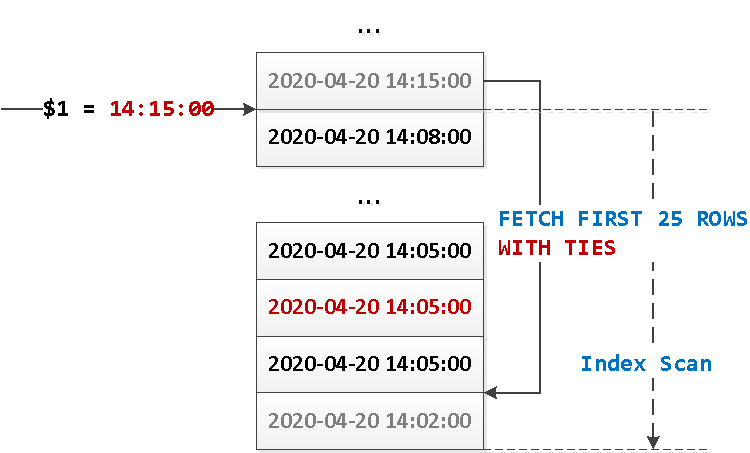
Но ведь ровно для этого и нужен функционал WITH TIES — чтобы отобрать сразу все записи с одинаковым значением граничного ключа!
EXPLAIN (ANALYZE, BUFFERS)
SELECT
*
FROM
events
WHERE
ts < '2020-01-01'::timestamp
ORDER BY
ts DESC
FETCH FIRST 26 ROWS WITH TIES;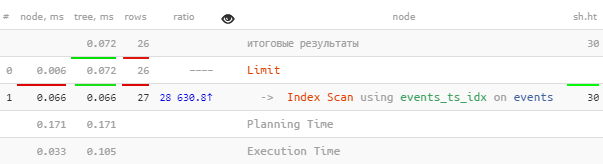
[посмотреть на explain.tensor.ru]
Запрос выглядит гораздо проще, почти в 2 раза быстрее, и всего лишь за один Index Scan — отличный результат!
Обратите внимание, что хоть мы и «заказывали» всего 26 записей, Index Scan извлек на одну больше — ровно для того, чтобы убедиться, что «следующая» нам уже не подходит.
Ну что же, ждем официального релиза PostgreSQL 13, который запланирован на завтра.
