Понимаем и работаем с gulp
Всем привет. Если вы связаны хоть как-то с JS, вы наверняка слышали о таком приложении как gulp. А возможно даже и использовали. По своему опыту могу сказать, что «въехать» в то, как с ним работать бывает сложно, хотя ключ к пониманию лежит на поверхности. Поэтому и публикую этот материал, надеясь, что он станет полезным.
Так же, на основе данного материала был снят видеоролик, так что можете выбирать, в каком виде потреблять.
Если сравнить gulp с другими популярными системами сборки, то это как сравнивать готовый квадрокоптер по типу «купил и полетел», и набор для самостоятельной сборки дрона. Да, взлетите вы только на следующий день, но зато у ваших руках больше гибкости и контроля, особенно если у вас нестандартная задача.
На самом деле, после преодоления порога входа, gulp выглядит не так уж и сложно, и моментами даже понятно и логично. Но, без должной подготовки придти к такому состоянию может быть непросто. Давайте же нырнем в самое оно и рассмотрим, на каких принципах построен gulp.
Зайдем издалека. В экосистеме nodejs, существует такое понятие, как потоки, или stream. Из-за сложности перевода, потоками так же называются нити или threads многопоточной программы. В нашем же случае, поток — это объект, представляющий потоковые данные, и является совершенно иным понятием.
Так вот эти потоки предлагают удобный интерфейс для асинхронной работы с данными. Всем процессом чтения/записи занимается движок ноды, а мы имеет только соответствующие колбеки, когда появилась новая порция данных, когда произошла ошибка, когда поток закончился и т.п. Таким образом достигается эффективность ввода/вывода при минимальных затратах со стороны программиста.
const fs = require('fs');
const input = fs.createReadStream('myfile');
input.on('data', (chunk) => {
console.log(chunk);
});
input.on('end', () => {
console.log('file is read');
});
Потоками в nodejs может быть практически все, начиная от файлов или строк заканчивая сокетами. Например, в известном фреймворке Express, HTTP запрос и ответ являются ни чем иным, как потоками. Потоки могут быть только на чтение, только на запись или и то и другое.
Есть у потоков одна полезная функция: их можно складывать между собой у цепочку, которая называется pipe. Таким образом, мы можем объединить несколько потоков между собой, и управлять им как одним целым. Выход одного потока идет на вход следующему и так до конца. Как можно догадаться из перевода слова pipe, это очень похоже на трубопровод.
Это позволяет определить нужный поток данных (опять сложность перевода. Здесь имеется в виду flow, или течение) прямо здесь и сейчас не дожидаясь, когда данные станут доступны.
Например, вот так вот мы можем определить, что мы хотим отдать как результат, а «как» отдавать уже занимается сам движок.
const fs = require('fs');
const express = require('express');
var app = express();
app.get('/', function (req, res) {
fs.createReadStream('myfile')
.pipe(res);
});
app.listen(3000);
Обратите внимание, что обработчик запроса завершается до того, как файл даже откроется — остальное берет на себя движок ноды.
Gulp построен на аналогичном подходе. Это его преимущество, но это и его недостаток. Недостатком, как минимум, можно назвать из-за возникающей путаницы, поскольку gulp использует другие, похожие, но несовместимые потоки. Gulp плотно работает с файловой системой, поэтому он и использует потоки, которые представляют не столько поток данных, сколько отдельные виртуальные файлы, каждый со своим содержимым.
Если вы когда-нибудь слышали о vinyl — это как раз и есть реализация потоков, которые используют в gulp. Если мы возьмем стандартную задачу для галпа, и посмотрим что там внутри, то обнаружим, что на каждый вызов события data к нам приходит объект file, который и содержит всю необходимую информацию: имя файла, путь к файлу, рабочая директория и конечно же, его содержимое.
const gulp = require('gulp');
gulp.task('default', function() {
gulp.src('./*.js')
.on('data', function(file) {
console.log('data callback');
console.log(file.inspect());
/* It outputs:
* data callback
* >
* data callback
* >
*/
})
.pipe(gulp.dest('dist/'));
});
Содержимое может быть представлено в двух форматах: в виде уже прочитанного буфера, или же в виде родного нодовского потока. Каждая ступень галповского пайпа берет на вход такие вот файлы, делает некую трансформацию и передает на выход следующей цепочке. Последняя цепочка обычно просто сохраняет их на диск.
.pipe(gulp.dest('dist/'));
Осознание факта того, что потоки в gulp другие ведет к просветлению и пониманию, поскольку это объясняет большинство проблем и ошибок.
Рассмотрим реальный пример. Вы хотите использовать browserify для склейки ваших JS файлов. Вы идете, и находите плагин gulp-browserify. Но видите приписку, которая говорит, что плагин deprecated, т.е. Устарел.
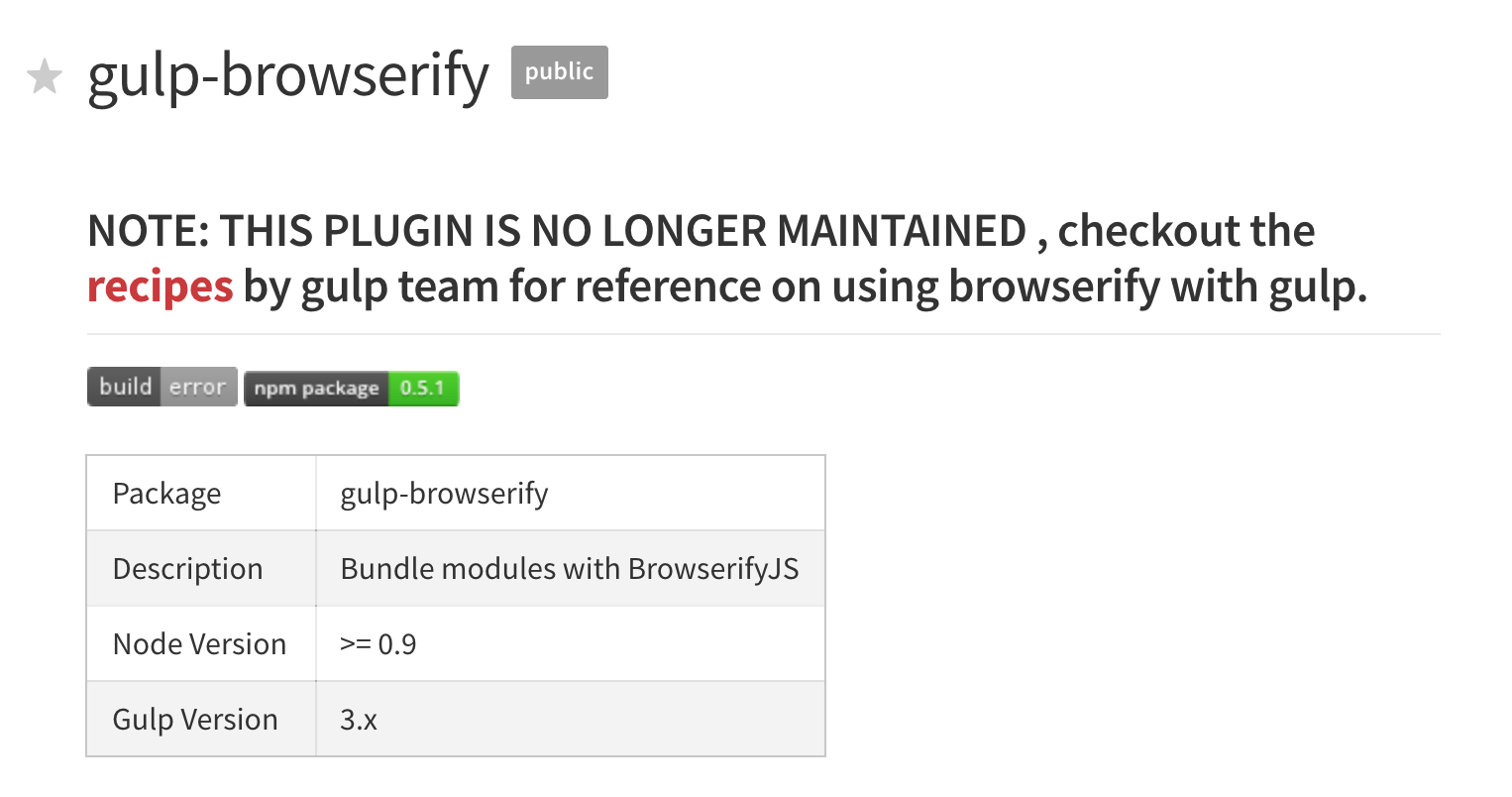
Как хорошо воспитанный программист вы отметаете этот вариант, и идете искать, а какое же решение не устарело. Находите официальные рецепты от gulp, и видите, что browserify работает с галпом напрямую. Ну как напрямую, через прослойку vinyl-source-stream, которая как раз и переводит родной нодовский поток в виниловский поток, который понимает gulp. Без него ничего бы не заработало, поскольку это разные потоки.
Если вы хотите написать свою трансформацию, то можете использовать данный шаблон.
Как видим, здесь все просто: на каждый файл будет вызываться наш обработчик, который и выполнит модификации. Мы можем делать все что захотим: изменить содержимое файла, переименовать файл, удалить файл или добавить еще пару новых файлов в поток.
Как мы помним, содержимое файла в виниловском потоке может быть представлено в виде буфера или в виде потока данных. Однако не обязательно поддерживать и то другое. Всегда можно использовать пакет vinyl-buffer, который вычитает поток данных и сохранит его в буфер для последующих трансформаций.
Пока что все. Надеюсь, что вам стало немного понятнее, как работать с gulp. Спасибо.
