Полномасштабный DevOps: греческая трагедия в трёх актах
Траге́дия (от нем.Tragödie из лат. tragoedia от др.-греч. τραγωδία) — жанр художественного произведения, предназначенный для постановки на сцене, в котором сюжет приводит персонажей к катастрофическому исходу.
Большинство трагедий написано стихами. Эта трагедия написана Барухом Садогурским (@jbaruch) и Леонидом Игольником (@ligolnik). Если уж мы говорим о DevOps в большом масштабе, что это, как не трагедия?
Эта статья отмечена суровостью реализма, изображает действительность большой разработки наиболее заостренно, как сгусток внутренних противоречий. Вскрывает глубочайшие конфликты реальности в предельно напряженной и насыщенной форме, обретающей значение художественного символа.
А теперь заканчиваем играть в Белинского и добро пожаловать под кат! Там и текст, и видео. Заложников не брать!

Как известно, греки обожали диаграммы Венна. И мы вам покажем целых три — и все про DevOps.

Есть традиционное описание DevOps — это пересечение областей Operations, Development и QA. Исторически интересно, что QA добавили туда позже.
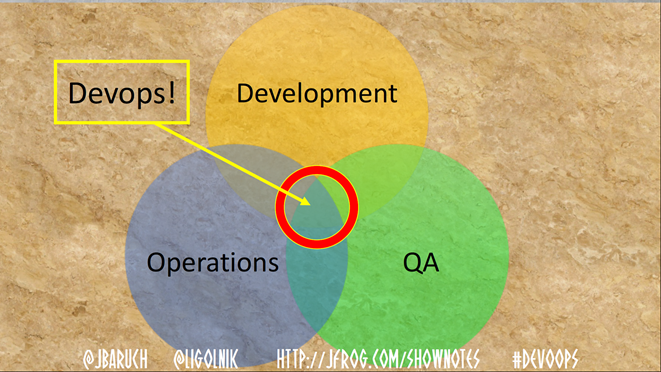
Но сегодня мы поговорим о другом — о пересечении технологий, процесса и людей. О том, что нужно сделать со всеми этими тремя компонентами, чтобы получился DevOps.
Теперь сравните еще две диаграммы:
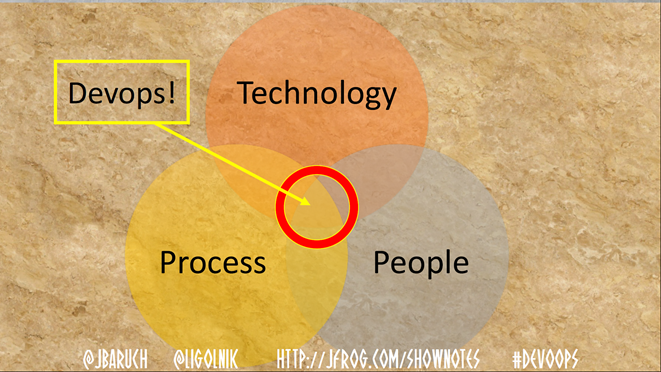
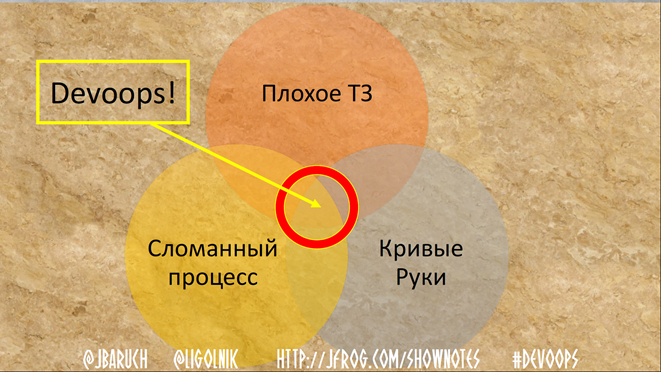
Иногда так случается.
Pentagon Inc.
Начнем рассказ с мифической компании под названием Pentagon, которая занимается транзакциями по кредитным картам.

Акт I — Пожарные
Люди. Компания только начинает свою работу, у нее три инженера. Все трое пришли из одной компании из оборонки. Ребята достаточно толковые, поэтому у них есть все: JavaScript, Node, React, Docker, микросервисы.

Процесс. Как может выглядеть процесс, когда в команде три человека? Kanban: или на доске с бумажками, или в Trello. Ребята толковые и понимают, что QA нужен с самого начала, поэтому TDD, unit & integration tests. Никакого ops, у всех root.

Инструменты. Соответственно, для трех человек, которые только-только поднимают что-то: JIRA, GitHub, Travis CI и тд.
Поговорим о том, как этим людям живется на этом прекрасном стеке. Во-первых, как в хороших стартапах — мы пилим-пилим продукт и ждем первого клиента.

Неожиданно произошло чудо — одна организация, которая организовывает самые лучшие конференции на постсоветском пространстве, решила довериться этим ребятам и делать свои транзакции через них.

Что делает настоящий стартап, получив своего первого клиента? Отмечает! И где-то часа в три ночи, когда все в особом состоянии, звонит клиент и говорит, что ничего не работает.

Конечно, в первую очередь, паника!

Следующий шаг — в бой! Смотрим логи, например.

Смотрели, смотрели, оказалось, что один из наших трех героев — Вася, придя домой после празднества, закоммитил свою небольшую идею. Мы помним, что после коммита и пройденных тестов все улетает в продакшн.
Ну кто из нас не заваливал продакшн? Мы не будем винить Васю. Откатываем на предыдущий коммит. Оно не собирается! Почему-то не хватает библиотеки, называется left-pad.
Для тех, кто не знает, что произошло с left-pad, — рассказываем. Итак, 23 марта 2016 года сломалось пол-интернета. Вообще модуль left-pad в JavaScript просто вставляет пробелы в левой части строк. И пол-интернета напрямую или транзитивно от этого модуля зависели. Автор left-pad каким-то образом умудрился поссориться с хозяевами центрального репозитория npm, поэтому он просто ушел от них, прихватив все свои разработки. npm — вообще загадочная система: мало того, что они проверяют, когда вы добавляете новый модуль для скачивания, — они еще и проверяют все старые модули.
Таким образом, раз за разом борьба с огнем продолжается. И проблемы все время одни и те же.

Акт II — Установщики пожарной сигнализации
Новости компании: подняли бабла, нашли инвестора, наняли 27 человек, причем один из них — с ops-бэкграундом. Появилось 100 клиентов и даже техподдержка.

Процесс, соответственно, тоже должен получить апргейд. Появился нормальный Scrum, exploratory testing. Поняли, что NoOps не бывает вообще, потому что есть Ops (если архитектура serverless, то сервер все равно есть, он просто не ваш). Так как по ночам будить всю команду неправильно, появился дежурный (developer on call).

Соответственно, расширился набор инструментов. Как минимум появилась Knowledge Base, так как теперь есть дежурный, и ему надо где-то искать информацию. Еще новинка — JFrog Artifactory: система, позволяющая хранить то, что было задеплоено вчера, чтобы можно было легко откатиться назад (урок с left-pad прошёл не зря), а не перестраивать всё заново. Поставили систему сбора логов и поиска по ним. Добавилась Pingdom — феерическая мониторинг-система: вы даете ей url, и она рассказывает вам, работает он или упал.

Итак, на этом этапе снова подняли денег. Значит, отмечаем. Пятница, три часа ночи, звонит клиент. Кое-что не работает: Visa и MasterCard проходят, а American Express — нет.

И как в первую очередь реагирует саппорт, когда в три часа ночи звонит клиент? Паника!
Затем звоним дежурному. Угадайте, кто дежурит? Конечно, Вася! Угадайте, в каком состоянии Вася? М-да. Но Вася берет себя в руки, смотрит на то, что ему прислал саппорт, и говорит, что ему все это подозрительно знакомо и он уже такое делал. Поэтому Вася просто берет и чинит. Все идут отсыпаться. В понедельник начинается разбор полетов.

Вот пример конкретного документа, который мы производим для knowledge base, чтобы если что-либо снова повторилось, это можно было быстро найти. Кроме того, иногда его показывают клиентам:
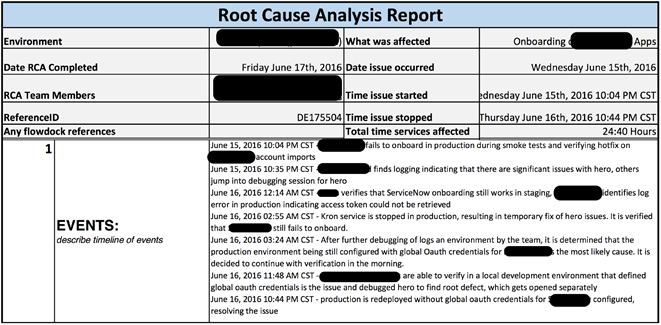


В документе отображаются основные заголовки, причины, характеристики, список событий. Обязательно указываются симптомы, дается техническое описание того, что именно сломалось и как это починить. Самая важная часть документа — ключевая причина, по которой что-то упало.
В случае с Васей у нас по логам переполнение очереди. Нужно ее очистить от транзакций кредитных карт, а кроме того, увеличить ее размер. Например, на 42!
Такой процесс очень хорош для внутреннего continuous improvement и он гарантирует установку тех самых «детекторов дыма». Вторая причина, по которой этот документ важен — это отчет перед клиентом. Некоторые сервисы после того, как они «лежали» какое-то время, публикуют причины этого.

Иногда проблема оказывается настолько катастрофической, что распространяться об этом не стоит.
В GitLab«е в феврале 2017 года какой-то человек удалил базу данных на продакшне. Вот анализ, который выложил GitLab:

Итак, где-то есть бекап, только никто не знает, где. Затем бекапы нашлись, но они оказались пустыми. Да, есть дамп базы. Но он делался в другой версии postgres, поэтому не подходит. У нас есть диск-снепшоты, но на них нет базы данных. Репликация с S3 тоже не сработала из-за отсутствия данных.
Таким образом, пять различных техник для резервного копирования данных не отработали. Мы думаем, что такое публиковать нельзя, так как больше им никто ничего не доверит. Но, в зависимости от того, как про это рассказать, клиент может и простить. Правда, только один раз.

Кстати говоря, тот парень, который это сделал, получил повышение. Кроме того, он поменял себе статус в twitter на Database (removal) Specialist at GitLab.
Акт III — Кульминация
Итак, что происходит в нашей фирме? Снова подняли денег, наняли кучу народа — теперь у нас пять ops-инженеров и один человек, который занимается performance. Есть главный архитектор. Появилась команда customer success team, покрывающая все отрасли, которым может понадобиться саппорт. Их тормозят, чтобы оставшаяся часть команды могла продолжать работать. Часто в такой команде есть группа, которая может построить отношения с ops или саппортом, а также периодически туда надо закидывать инженеров на scrum, либо на sprint, либо на месяц. Компания выросла, появился юрист, финансовый директор. База клиентов выросла до 1000.

Так как команда растет, процесс разработки должен поменяться.
Появился SAFE — фреймворк, который объясняет, что делать scrum-ам, когда команд становится много или центров разработки — больше, чем один. Количество процессов, которые присутствуют в Safe, может убить лошадь, но если только все их взять сразу. Если забирать себе только те кусочки, которые требуются на данной стадии развития компании, то все должно быть нормально.
System testing появляется, когда у больших команд возникают определенные нужды или если у вас громадная система, из которой нужно что-то собрать. Индивидуальные scrum-команды могут хорошо оттестировать свои системы, но кто-то должен отвечать за то, что вся система должна собраться в продакшн.
Что можно сказать про Ops Team? Как мы говорили, есть два варианта делать DevOps. Первый — по книжке и по инструкциям Netflix, Google и Twitter. Второй — в реальной жизни, где не всем инженерам можно доверить root в продакшн.
Escalation path — важный концепт, который позволяет решать любую проблему в заданное время, потому что в конце escalation path есть мобильный телефон генерального директора, после звонка которому все проблемы исчезают за 5 часов 58 минут.
SOC II — набор стандартов, которые вендор предоставляет клиенту. Эти стандарты подтверждают, что у фирмы есть определенные решения в безопасности, подходы к разделению работы.
Backlog — список проблем, которые нужно решать для улучшения системы. Обычно backlog manager«ом становится chief architect, который должен посмотреть на нужды системы и нужды продукта и расставить приоритеты по этим задачам.

Инструменты, естественно, тоже совершенствуются.

Есть еще новости. Васю повысили. Он теперь VP of Engineering.
Проходит пятница, суббота, воскресенье — ничего не приходит. Все работает. Все сами в шоке. Наступает понедельник, приходит к Васе юрист и говорит, что был на конференции юристов и услышал там про LGPL 2.2. Вася понятия не имеет есть ли у них LGPL 2.2.

Люди работали долго, а потом нашли LGPL 2.2. Нужно выпиливать. Но это выпиливается здоровым куском системы, а релиз завтра никто не отменял. Ну ничего, справились с этим.

Приходит финдиректор к Васе:
- Сколько нужно денег для серверов и продакшн? Делаем бюджет на следующий год…
- 42 — говорит Вася.
Решили и эту проблему.

К Васе приходят и говорят, что есть потенциальный клиент, но он боится, что такого масштабного заказчика у нас никогда не было, и хочет, чтобы его убедили в том, что будет хорошо. Из истории мы знаем, что на этом этапе все умерли.

Но так как у нас в обязательном порядке должен быть happy end, к греческой трагедии мы приделали и его.
Эпилог — Proactive Improvement
Теперь расскажем про последнюю стадию масштабирования DevOps — Proactive Improvement. Это о предотвращении пожаров.
С людьми никаких изменений не происходит. А вот с процессом — очень даже.

Так как у нас есть Performance Engineer, то он должен как-то следить за системой. Появился License and security management. Proactive Performance — теперь мы внимательно смотрим за тем, куда движутся ключевые индикаторы, и чиним вещи до того, как начнется громадный пожар. Желательно при масштабировании продукта иметь что-то, что говорит: если вы хотите иметь микросервис, то у него как минимум должен быть стандартный мониторинг, логи и прочее.
Соответственно, есть инструменты, которые все это поддерживают. Например, инструмент для license and security мониторинга — JFrog Xray. Blazemeter — так как теперь есть proactive performance, то надо как-то генерировать load. Появляются такие вещи, как Service Virtualization, который позволяет применять mock-объекты для удаленных API, потому что не каждый вендор, с которым вы работаете, может предоставлять тестовый API.

Разбор
Разберем некоторые события из предыдущих актов.
Помните тот случай, когда Василий планировал бюджет пальцем в небо? В работе над одним из наших продуктов нам захотелось разобраться, на что тратятся ресурсы. Сгруппировав все, что было в бэклоге, получили вот такую диаграмму:

Мы ошибочно думали, что тратим 80% на Big Feature A — на самом деле на нее уходит только 13%. При этом целых 34% уходит на Keep the lights on — вещи, которые надо делать в продуктах: чинить баги, обновлять библиотеки и тд.
На самом деле существует только одна объективная метрика качества продукта: удовлетворенность клиента, которая выражается в обращениях к саппорту.
Второй пример. Разбили все дефекты по критичности:
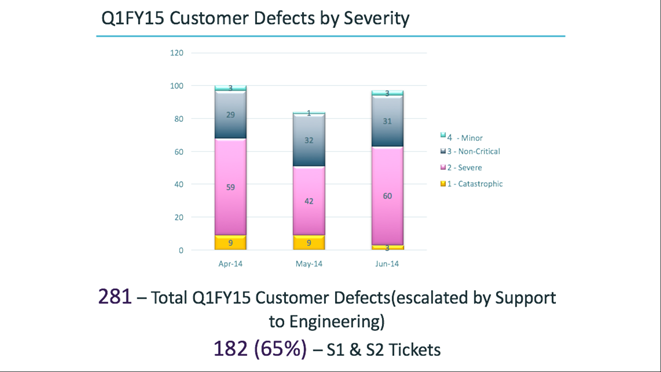
65% тикетов относятся к первым уровням критичности. Это же кошмар?
Теперь возьмем те же самые данные и посмотрим на них под другим углом.
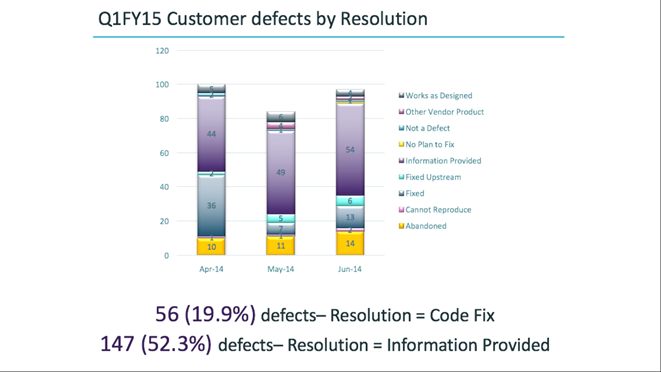
Теперь диаграмма отражает ситуацию после разбора полетов. Оказалось, что 52% тикетов были закрыты инженером при помощи information provided, то есть он отписал в саппорт то, чего они не знали. Только около 20% тикетов были закрыты при помощи какого-то изменения кода. Таким образом получается, что виноват совсем не R&D. Виноват даже не саппорт. На самом деле нам не хватало обучения — и Вася, как VP of engineering, посмотрев, сколько он тратит время на всякие глупости, отправил кучу инженеров обучать саппорт.
Ребята поправили документацию в узких местах, поправили логи. Как результат, кусок, на который уходила куча времени разработчиков, исчез.
Выводы
На всех стадиях, от пожаротушения до установки сигнализации и проактивного решения проблем, есть много процессов, людей, специалистов, подходов, инструментов, которые надо установить. Все это сделать за один день нельзя. Кроме того, некоторые вещи на каких-то этапах развития не нужны.
Важно понимать, что и в людях, и в процессах, и в тулах постоянно нужны какие-то улучшения.

Что именно нужно улучшать, нам помогут узнать те самые цифры, о которых мы говорили. Только на основе этих данных можно принимать правильные решения о том, куда вкладывать время и что двигать вперед.
И не забывайте два основополагающих принципа DevOps:
- You build it — you own it.
- Pain is instructional.
Уже в следующее воскресенье Барух и Леонид выступят с докладом »#DataDrivenDevOps» на DevOops 2018 в Петербурге. Приходите, будет много интересного: вот доклады, вот Джон Уиллис, а вот вечеринка с BoF-ами и караоке. Ждем вас!
