Хранение архива изображений для сайта в Azure BLOB storage
В статье рассказано про опыт организации бюджетного хранения архива изображений для сайта с миллионами объявлений.
Под изображениями в моем случае понимаются фотографии квартир, домов, участков и т.д. У меня есть собственный проект который представляет из себя сайт с объявлениями о продаже и аренде недвижимости. Сайту уже что-то около 6 лет и за это время скопилось достаточно большое количество объявлений. На каждой карточке объекта отображаются фотографии, в среднем 8 фотографий на объявление. Собственно эти фотографии я и собираюсь хранить в облаке чтобы потом показывать их посетителям на карточках объектов.
Вопрос хранения данных для меня давно маячил где-то на горизонте, но всегда был низкопроиритетным. Так сложились обстоятельства что никаких других интересных задач не осталось, и я решил наконец-то обзавестись облачным хранилищем.
Как я хранил их раньше? — никак. Я не хранил у себя изображения кроме тех которые были размещены вручную. В большинстве же случаев объявления попадают на сайт через партнеров посредством автоматической загрузки фида. В фиде для каждого объекта есть ссылки на фотографии — вот ссылки я и храню, и отдаю посетителю фотографию напрямую от партнера. Эта схема прекрасно работает и экономит кучу ресурсов.
Фотографии которые видят посетители в подборке объявлений или в карточке объекта на самом деле подгружаются со сторонних ресурсов.
Есть один нюанс связанный со спецификой сайта — я не удаляю архивные объекты. Т.е. после того как объявление снято с публикации, оно конечно пропадает из поисковой выдачи, но по прямой ссылке доступно всегда (без контактов продавца). Какое-то время ссылки на фотографии еще живут, бывает что годами, но рано или поздно они умирают. Архивные объекты имеют ценность потому что на них продолжают приходить посетители из поисковых систем. Также по архиву строится карта цен (я уже писал про нее), а еще я случайно открыл дополнительный источник дохода для проекта в виде продажи контактных данных архивных объектов. Зачем они их покупают — я точно не знаю, но предполагаю, что посетители хотят получить контакты потому что думают что объявление снято с публикации случайно или по ошибке. Также наверное бывает что хотят узнать что-то у предыдущих владельцев. Так или иначе, объявление с фотографиями в данном случае имеет больше шансов на то чтобы быть купленным. Ценность фотографий возрастает после осознания этого нюанса.
Объемы данных которые я собираюсь хранить в облаке составляют около 3–4 терабайт. Плюс ежедневный прирост в несколько гигабайт. Учитывая что напрямую данное нововведение денег не принесет, а лишь косвенно может повлиять на принятие решения посетителем, бюджет в который я хотел уложиться очень скромный — это 1000–2000 р. в месяц. Хорошо бы вообще бесплатно, но такой возможности я не нашел.
Azure
Я как-то сразу посмотрел в сторону Azure потому что работаю на .net, и часто вижу красивые рекламные статьи по этой теме. Плюс приходится пользоваться данной платформой по основной работе, но там мои возможности ограничены требованиями бизнеса и желаниями руководства.
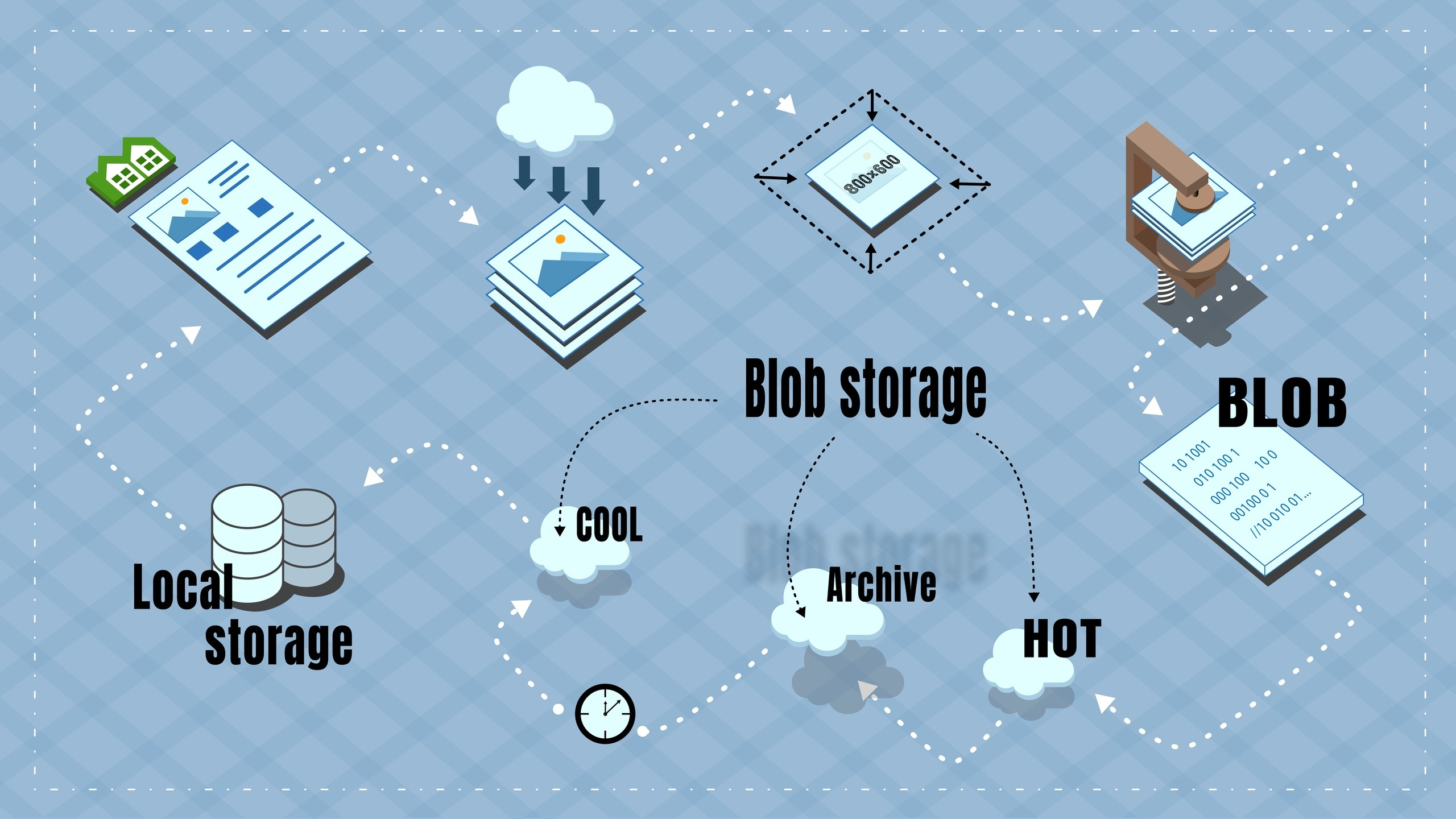
Azure предлагает BLOB-storage с тремя уровнями хранилища: Hot, Cool и Archive. Цены на всех уровнях разные. В общих словах, чем горячее — тем дешевле чтение\запись и дороже ежемесячная плата за хранение, и наоборот. На Hot — выгодно много писать\читать и удалять, но дорого долго хранить. А на Archive дешево хранить, но дорого читать\писать. Также на архивном и холодном уровнях есть плата за раннее удаление — это означает что если я удаляю (или перевожу на другой уровень) объект раньше чем определенный срок, то с меня все-равно возьмут плату как за весь этот срок. Для архивного уровня — это 180 дней, для холодного — 30.
Цены
Стоимость хранения составляет $0.0023 за Гб в месяц на архивном уровне, $0.01 на холодном и $0.0196 на горячем. По текущему курсу это примерно 0.15, 0.65 и 1.28 рубля соответственно.
Я сравнил со стоимостью в Amazon и Google, получается что в Azure дешевле.
Amazon (S3)
Hot: $0.024
Cool: $0.01
Archived: $0.0045
Google
Hot: $0.026
Cool: $0.01
Archived: $0.007
Я также искал среди малоизвестных компаний предоставляющих хранилища данных, но везде оказалось дороже чем в Azure, плюс мне очень нравится наличие трех уровней хранения, т.к. это дает дополнительные возможности для снижения общей стоимости хранения.
Помимо стоимости хранения необходимо учитывать стоимость операций — они тоже на всех уровнях разные. Цены приводятся за 10 000 операций.
Hot
Чтение: $0.0043, запись: $0.054
Cool
Чтение: $0.01, запись: $0.10
Archive
Чтение: $6, запись: $0.12
Логика работы
Стратегия для хранения данных была выбрана такая: в архиве хранится большая часть данных, а в Cool попадают только те фотографии ссылки на которые умерли, и у соответствующих объектов есть просмотры — т.е. это карточки объектов на которые заходят посетители сайта. При этом, если объект перестал быть популярным, то его фотографии надо опять заархивировать.
Как только объект (здесь и далее, объект — это объект недвижимости) пропадает из файла импорта партнера, т.е. партнер перестал его публиковать, формируется запись в приоритетную очередь, где приоритетом считается количество просмотров посетителями — чем больше просмотров, тем больше вероятность что будучи архивным, объект будет просматриваться и дальше.
Изначально это была обычная очередь, для первоначальной загрузки всех имеющихся фотографий в хранилище мне потребуется примерно месяц беспрерывной работы (а я не могу себе позволить делать это беспрерывно по материальным и техническим причинам), я добавил приоритет чтобы интересные с точки зрения посетителей объявления обрабатывались раньше.
При обработке записи из очереди формируется BLOB-объект содержащий в себе уменьшенные (до 800×600) фотографии для объекта и необходимую метадату, и в таком виде загружается сначала в Hot, а потом сразу же перемещается в архив. Возможности писать напрямую в архив нет, а поскольку в Cool есть плата за раннее удаление, то дешевле в качестве транзита использовать Hot.
Использование композитных объектов вместо непосредственно фотографий тоже обусловлено экономией — вместо 8 операций записи (в среднем 8 фоток на объект) производится одна, а каждая операция стоит денег.
В архиве BLOB лежит до тех пор пока ссылки на оригинальные фотографии активны, либо у него изменились фотографии.
Проверка на работоспособность ссылок производится при заходе посетителя на карточку объекта — если на нее ходят, значит объект популярен и восстанавливать фотографии из архива имеет смысл. Но тут есть нюанс: восстановление BLOB-объекта из архива (у Microsoft это называется rehydration) — может занимать до 15 часов (!). Не получится восстановить объект из архива и сразу же отдать на клиент. Опять использую очередь — отправил запрос на rehydration, жду когда объект переместится в Cool, далее копирую разархивированный BLOB в локальное хранилище и уже потом отдаю на клиент. Под локальным хранилищем подразумевается жесткий диск на сервере — это нужно чтобы не читать напрямую из Azure при каждой загрузке карточки объекта — каждая операция стоит денег. В локальном хранилище BLOB разделяется на нормальные фотографии и в таком виде хранится несколько дней. Если за эти несколько дней были просмотры объекта — срок локального хранения продлевается. Если просмотров не было, фотографии удаляются из локального хранилища, но остаются на Cool-уровне в Azure. Из Cool в Archive они копируются если просмотров не было в течении двух месяцев — объект явно не популярен и соответственно нет смысла переплачивать за хранение в Cool.
Первый запуск
Когда процесс был написан и протестирован, настало время опытной эксплуатации, и тут ожидаемо возникли неприятности. В очереди на тот момент было около 10 миллионов объектов, я решил начать миграцию с 30 000 объектов в день. Настроил красивые графики на дашборде и стал наблюдать. Большая часть запросов должна была составлять PutBlob — изначальная загрузка объекта на Hot-уровень и SetBlobTier — перемещение в архив. Но помимо этих транзакций я увидел в статистике странные «выпады» с запросами GetBlobProperties. Они происходят с примерно равным интервалом в один час, начинаются всегда спустя примерно полтора часа после запуска миграции, и длятся еще какое-то время после ее завершения.
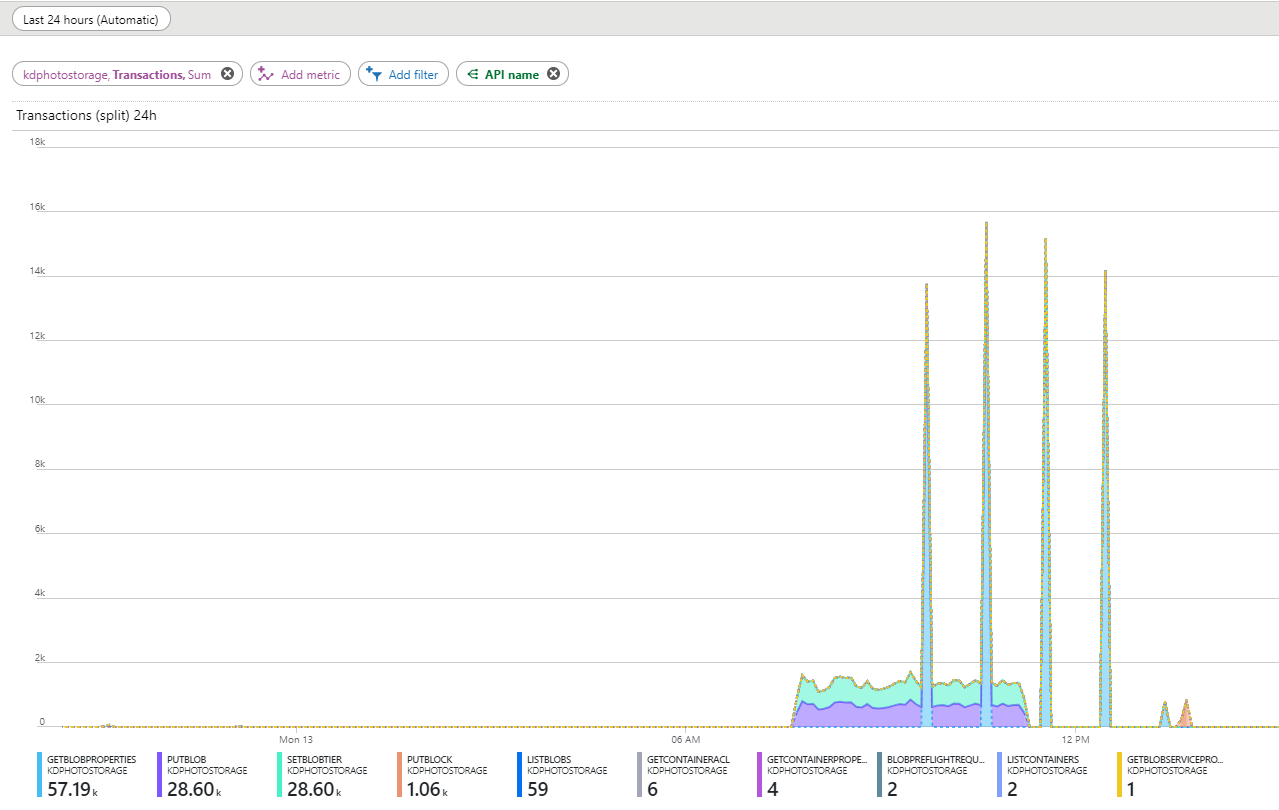
Количество таких запросов было слишком большим чтобы не обращать на них внимание. Я смотрел логи и видел что эти запросы идут не от моего сервера, а с иностранных IP-адресов. Платить за них мне совсем не хотелось.
Я искал на стэке и в документации, но безрезультатно. Написал вопрос на Stackoverflow и в техподдержку. В итоге после длительной переписки с техподдержкой, и предоставления им логов, они мне сообщили что могут воспроизвести ситуацию и это баг на их стороне.
Интересный нюанс, что на мой вопрос на Stackoverflow был дан ответ не объясняющий причин, а только подтверждающий что я буду платить за эти запросы, но человек давший ответ настойчиво просил чтобы я пометил его как правильный. Он также вскользь намекнул мне что у них (в поддержке) не приветствуется распространяться об ошибках в собственных продуктах. Я дал ему понять что не сделаю этого пока он не напишет правду. Я мог бы написать это сам, но подумал что у сотрудников техподдержки наверняка результативность измеряется в том числе и количеством подтвержденных ответов, так что я предложил ему написать истинную причину и в этом случае отмечу его ответ как правильный. После недолгих колебаний, он согласился и дополнил свой комментарий сообщением о баге. В целом мне понравилось как работает техподдержка — меня даже перевели на русскую девушку которая до сих пор держит меня в курсе изменений по этой проблеме.
Факт признания бага меня удовлетворил только морально, но мне хотелось запустить механизм в работу, и при этом не платить деньги за левые запросы. Особенно учитывая что я нормально так заморочился чтобы максимально снизить количество запросов и тем самым стоимость.
В техподдержке мне посоветовали подождать с запуском, а спустя пару недель написали что баг исправлен, но когда будет релиз с исправлением — неизвестно. Предложили включить логирование и работать так, а после релиза запросить компенсацию в Microsoft. Собственно, в таком режиме это пока и работает. Я ежедневно запускаю миграцию небольшого количества объектов и жду релиза.
Заключение
Стоимость ежедневных 30000 объектов обходится пока в 900 р. в месяц — и это вполне приемлемо. Большая часть расходов — это операции записи. Так что когда вся очередь будет обработана и наступит этап плановой работы, будет понятно какова реальная стоимость такого хранилища. Но по моим подсчетам это произойдет примерно через год.
Когда будет релиз в Azure Blob-storage я допишу здесь удалось ли получить компенсацию. Относительно ежемесячных трат — это около 10% стоимости.
