Покупка оптимальной квартиры с R
Многие люди сталкиваются с вопросом покупки или продажи недвижимости, и важный критерий здесь, как бы не купить дороже или не продать дешевле относительно других, сопоставимых вариантов. Простейший способ — сравнительный, ориентироваться на среднюю цену метра в конкретном месте и экспертно добавляя или снижая проценты от стоимости за достоинства и недостатки конкретной квартиры.  Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение созданное с помощью R.
Сбор данных
С постановкой задачи понятно, возникает вопрос, откуда же брать данные, в РФ есть несколько основных сайтов по поиску недвижимости, и есть база WinNER, которая в достаточно удобном интерфейсе содержит максимальное количество объявлений и позволяет осуществлять выгрузку в csv формате. Но если раньше данная база позволяла повременной доступ (минуты, часы, дни), то теперь минимальный только 3 месячный доступ, что является несколько избыточным для обычного покупателя или продавца (хотя если серьезно подходить, то можно понести эти расходы). С этим бы вариантом было бы совсем просто, поэтому пойдем другим путем, парсингом с какого-нибудь сайта недвижимости. Из нескольких вариантов, я выбрал наиболее удобный небезызвестный cian.ru. На тот момент, отображение данных представлялось в простой табличной форме, но когда я попытался распарсить все данные на R, тут меня постигла неудача. В некоторых ячейках, данные могли быть недозаполнены, а стандартными средствами функций R я не мог зацепиться за якорные слова или символы, и надо было или использовать циклы (что в R для такой задачи некорректно) или использовать регулярные выражения, с которыми я совсем не знаком, поэтому пришлось использовать альтернативу. Этой альтернативой оказался замечательный сервис import.io, который позволяет извлекать информацию со страниц (или сайтов), имеет свое REST API и отдает результат JSON. А R может и запрос к API осуществить и JSON разобрать.
Быстро освоившись с данным сервисом, создал на нем экстрактор, который извлекает всю требуемую информацию (все параметры каждой квартиры) с одной страницы. А R уже перебирает все страницы, вызывая данный API для каждой и склеивая получаемые JSON данные в единую таблицу. Хотя import.io позволяет сделать и полностью автономный API, который проходил бы по всем страницам, я посчитал, что логично, чего я не могу сделать (парсинг одной страницы) правильно возложить на стороннее API, а все остальное продолжать делать в R. Итак, источник данных выбран, теперь об ограничениях будущей модели:
- Город Москва
- Один тип квартир в модель (то есть однушки или двушки или трешки)
- В пределах одной станции метро (так как используется геокодирование, и расстояние до ближайшего метро)
- Вторичка (так как новостройки все принципиально разные, и качественно друг от друга отличаются, а в объявлениях это либо не сказано, или написано что-то в комментариях, но ни то, ни другое, не позволяет создать адекватную модель)
Обзор данных
Как это часто бывает, в данных могут оказаться и выбросы, и пропуски, и просто обман, когда новостройки выдают за вторичку, или вообще продают землю.
Поэтому первоначально надо привести все данные к «опрятному» виду.Проверка на обман
Здесь основной упор на описание объявления, если встречаются слова явно не относящиеся к требуемой мне выборке, эти наблюдения исключаются, это проверяется функцией R grep. А так как в R вычисления векторные, данная функция сразу возвращает вектор значений верных наблюдений, применив его, отфильтруем выборку.Проверка на пропущенные значения
Пропущенные значения встречаются достаточно редко (и в основном именно в «левых» объявлениях, с новостройками и землей, которые к этому моменту уже исключены), но с теми, что остаются надо что-то делать. Вариантов, в общем-то, два, исключать такие наблюдения или заменять эти пропущенные значения. Так как жертвовать наблюдениями не хотелось, а исходя из предположения, что данные не заполнены исходя из принципа «что его заполнять, и так понятно, что это как все окружающее», решил заменять качественные переменные на моду их значений, а количественные (метраж) на медианные значения. Конечно, это не совсем корректно, и совсем правильно было бы проводить корреляционное отношение между наблюдениями, и заполнять пропуски согласно полученным результатам, но для данной задачи посчитал это избыточным, притом таких наблюдений достаточно мало.Проверка на выбросы
Выбросы встречаются еще реже, и могут быть только количественными, а именно по цене и по метражам. Здесь исходил из предположения, что покупатель (я) конкретно знает по какой цене и примерно какого метража должна быть его квартира, поэтому задавая начальные значения верхней и нижней цены, ограничивая метраж, мы автоматически избавляемся от выбросов. Но даже если это не так (не делать ограничения), то при получении результата или взглянув на диаграмму рассеяния и увидев, что есть выброс, можно осуществить запрос с уточненными данными, тем самым убрав эти наблюдения, что улучшит модель.Основные предпосылки теоремы Гаусса-Маркова
Забегая вперед, скажу, что от модели мы не хотим получения трактовки коэффициентов, или корректной оценки их доверительных интервалов, она необходима нам для прогнозирования «теоретической» цены, поэтому некоторые предпосылки нам не критичны.
- Модель данных правильно специфицирована. В общем да, путем исключения выбросов, некорректных объявлений, замены пропущенных значений, модель вполне адекватна. Какая-то нестрогая мультиколлинеарность может присутствовать (например пятиэтажка и нет лифта или площади — общая/жилая), но как писал выше, для прогнозирования это не критично, более того она не нарушает и основные предпосылки. Для целей построения тестовых моделей, все значений переводились в дамми-переменные корректно, строгая мультиколлинеарность исключена.
- Все регрессоры детерминированы и не равны. Да, тоже верно.
- Ошибки не носят систематического характера. Верно, так как в МНК используется свободный член, которые уравнивает ошибки.
- Дисперсия ошибок одинакова (гомоскедастичность). Так как используется ограничения по размеру регрессоров и зависимой переменной (масштаб сопоставимый), то гетероскедастичность минимальна, да и для прогнозирования она снова не критична (стандартные ошибки несостоятельны, а они нам не интересны)
- Ошибки некоррелированы (эндогенность). Вот тут нет, эндогенность, скорее всего, есть (например, квартиры -«соседи» с одной площадки или подъезда), есть какой-то внешний неучтенный фактор, но снова для прогнозирования, запись с эндогенностью не принципиальна, более того, мы не знаем этот неучтенный фактор.
Данные в целом соответствуют предпосылкам, поэтому можно строить модели.
Набор регрессоров
Помимо переменных (получаемых непосредственно с сайта), решил добавить дополнительные регрессоры, а именно пятиэтажный дом или нет (так как обычно это весьма качественное отличие), и расстояние до ближайшего метро (аналогично). Для определения расстояния используется API сервиса геокодирования Google (выбрал его как наиболее точный, лояльный к ограничениям, да и готовая функция в R есть), сначала геокодируются адреса квартир и метро, функцией geocode из пакета ggmap. А расстояние определяется по формуле гаверсинуса, готовой функцией distHaversine из пакета geosphere.
Итоговое количество регрессоров составило 14 штук:
- Расстояние до метро
- Общая площадь
- Жилая площадь
- Площадь кухни
- Тип дома
- Наличие и типы лифтов
- Наличие и типы балконов
- Кол-во и типы санузлов
- Куда выходят окна
- Наличие телефона
- Тип продажи
- Первый этаж
- Последний этаж
- Пятиэтажка
Протестированные модели предиктивного анализа
1. МНК на все регрессоры
2. МНК с логарифмированием (разные варианты: логарифмированием цены и/или площадей и/или расстоянием до метро)
3. МНК с включением и исключением регрессоров
а) последовательным пошаговым исключениям регрессоров
б) алгоритмом прямого поиска
4. Модели со штрафами (для уменьшения влияния гетероскедастичности)
а) Лассо-регрессия (с 2 способами определения параметра фракционирования)
б) Ридж-регрессия (с 3 способами нахождения параметра штрафа)
5. Метод главных компонент
а) со всеми регрессорами
б) с пошаговым исключением регрессоров
6. Квантильная (медианная) регрессия (для уменьшения влияния гетероскедастичности)
7. Алгоритм случайного леса
Общее число протестированных моделей составило 18 штук.
Критерии эффективности моделей
Все модели по своей сути принципиально разные, и для многих из них нет функции правдоподобия, поэтому нельзя определить внутренние критерии качества, да и не вполне корректно опираться на них для выбора эффективной модели, так как они служат в первую очередь для оценки адекватности модели. Поэтому будем ориентироваться на оценку качества моделей на средней разности эмпирических и прогнозируемых значений. А чтобы было интереснее, да и для определения выгоды (эффективности по цене) не всегда будет показательна среднеквадратичная ошибка (так как некоторые наблюдения могут исказить ее), использовал для оценки критериев не только обычный RMSE — среднеквадратичную ошибку, но и MAE — среднеабсолютную ошибку, и MPE — среднепроцентную ошибку.
Результаты тестирования моделей
Так как модели оцениваются разными функциями и синтаксис предсказанных значений у них тоже разный, простым указанием, что часть регрессоров является факторными не подходит для всех моделей, поэтому было создан дополнительный фрейм данных, в котором все качественные переменные трансформировались в дамми-переменные и в таком виде строились модели. Это позволяет однообразно оценивать все модели, предсказывать новые цены, и определять ошибки.
На различных случайных тестовых выборках (разные станции метро, разный тип квартир, прочие параметры), оценивались все вышеперечисленные модели по 3 критериям эффективности. И практически абсолютным (92%) победителем по всем 3 критериям, оказался алгоритм случайного леса. Также на разных выборках по некоторым критериям неплохие результаты показывала медианная регрессия, МНК с логарифмированием цены, полный МНК и иногда Ридж с Лассо. Результаты несколько удивительны, так как я полагал, что модели со штрафами могут оказаться лучше, чем полный МНК, но так было не всегда. Так что простая модель (МНК) может является лучшей альтернативой, чем более сложные. По причине того, что на разных выборках, по разным критериям места начиная со второго, занимали разные модели, а победителем оставался случайный лес, для дальнейшей работы решил использовать его.
Так как используется уже одна модель, то нет необходимости в явном указании дамми-переменных, поэтому возвращаемся к оригинальному фрейму, указав, что качественные переменные являются факторными, это упростит последующую трактовку на диаграмме, да и алгоритму будет проще (хотя ему по сути все равно). Для тестового моделирования использовалась функция randomForest (из одноименного пакета) со значениями по умолчанию, попробовав изменить основные параметры сложности деревьев nodesize, maxnodes, nPerm, определил, что чуть лучшую минимизацию ошибок прогноза при разных выборках достигается при изменении параметра nodesize (минимальное число узлов) в 1. Итак, модель выбрана.
Отображение на карте
Победитель определен (случайный лес), данная модель предсказывает «теоретические» цены для всех наблюдений с минимальными ошибками. Теперь можно посчитать абсолютную, относительную недооценку и результат вывести в виде отсортированной таблицы, но помимо табличного вида, хочется сразу информативности, поэтому выведем несколько лучших результатов сразу на карту. И для этого в R есть пакет googleVis предназначенный для интеграции с картографической системой Google (впрочем, есть пакет и для Leaflet). Я продолжил использовать также Google, так как полученные координаты от их геокодирования запрещено отображать на прочих картах.
Графический веб-интерфейс
Передавать все требуемые параметры через консоль медленно и неудобно, поэтому захотелось все сделать автоматизировано. И традиционно, для этого опять можно использовать R с фреймворками shiny, и shinydashboard, которые обладают достаточными элементами управления ввода-вывода.
Результатом всего этого становится удобное приложение с графическим интерфейсом, с фактически двумя (остальные пункты для контроля) главными пунктами бокового меню — первым и последним. В первом (Source data) пункте бокового меню (рис. 1), задаются все требуемые параметры (аналогично cian) по поиску и оценки квартир.
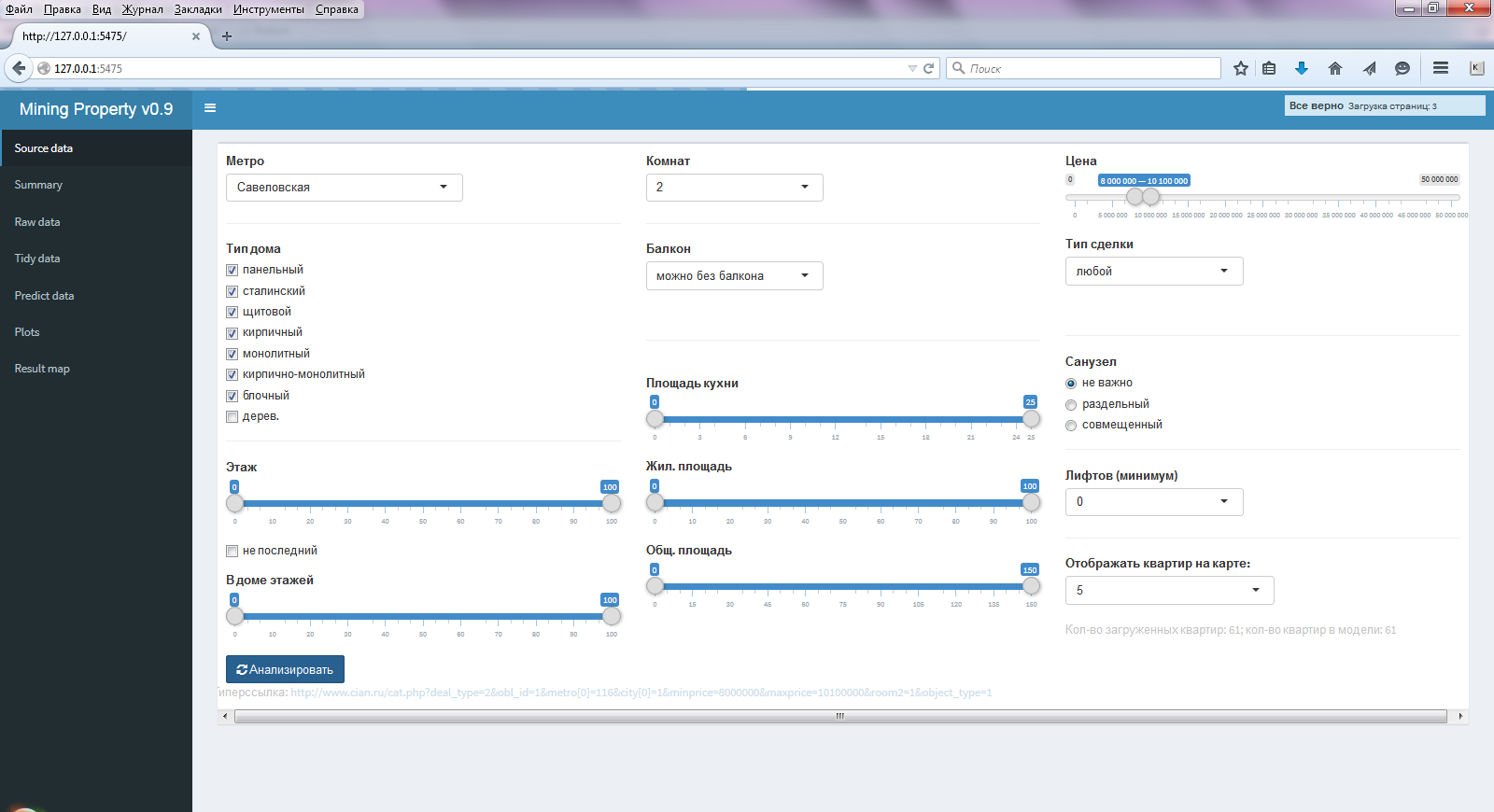
Рис. 1 Окно выбранного меню Source data
В остальных пунктах бокового меню выводится:
- сводный отчет (Summary) по регрессорам
- таблицы данных (сырая (Raw data) — исходная после парсинга, опрятная (Tidy data) — после приведения параметров в опрятный вид и корректировки параметров и добавлением геолокации, и итоговая (Predict data) таблица с предсказанными значениями цен)
- три диаграммы (Plots) (рис. 2)– точности модели и важности регрессоров в алгоритме случайного леса (почти всегда все регрессоры являются важными) и диаграмма рассеяния исходных и предсказанных цен.
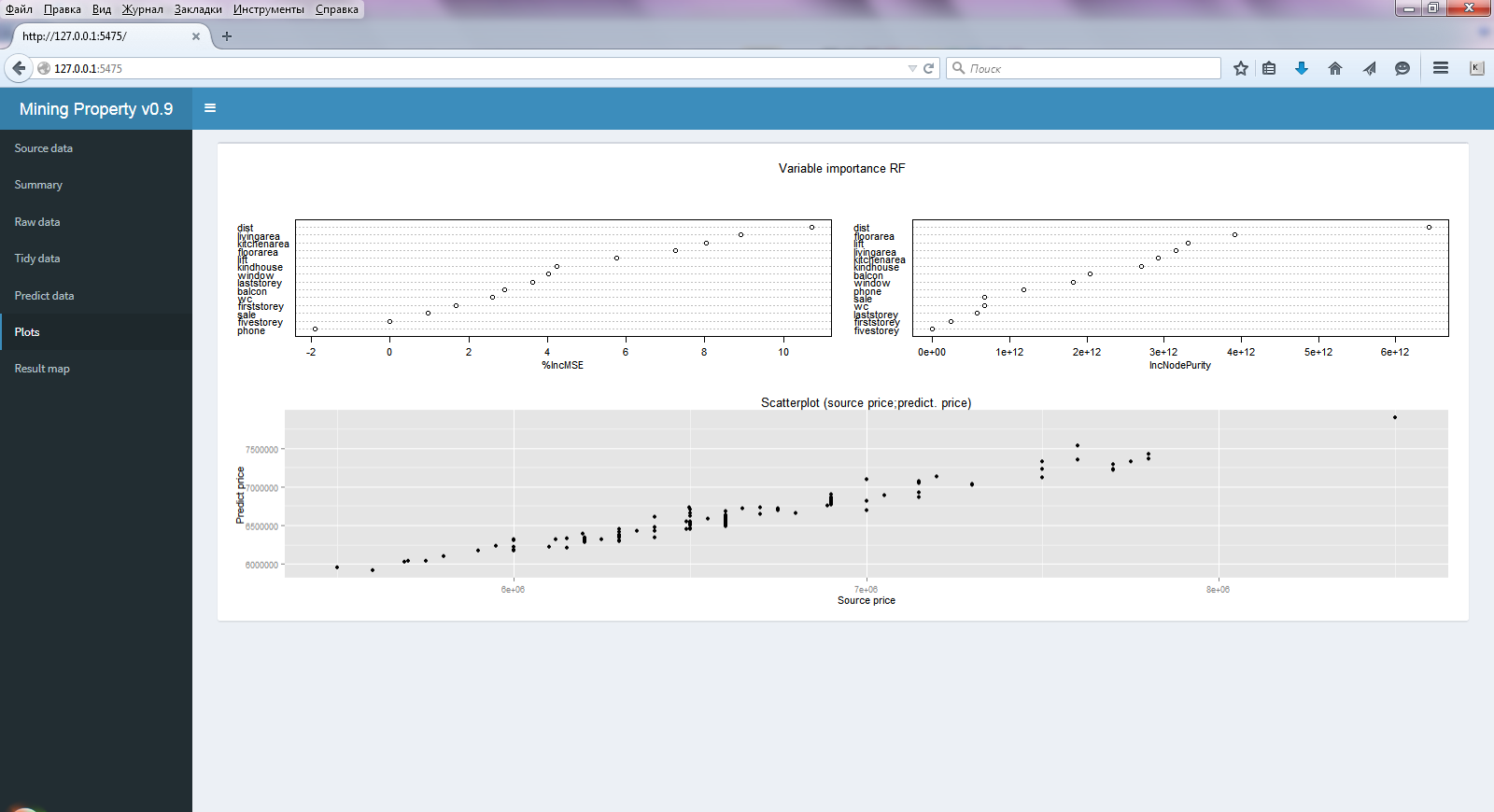
Рис. 2 Окно выбранного меню Plots
Ну, а в последнем пункте (Result map) (рис. 3) отображается то, ради чего все и затевалось, карта с выбранными лучшими результатами и приводится таблица с рассчитанной предсказанной ценой и основными характеристиками квартир.
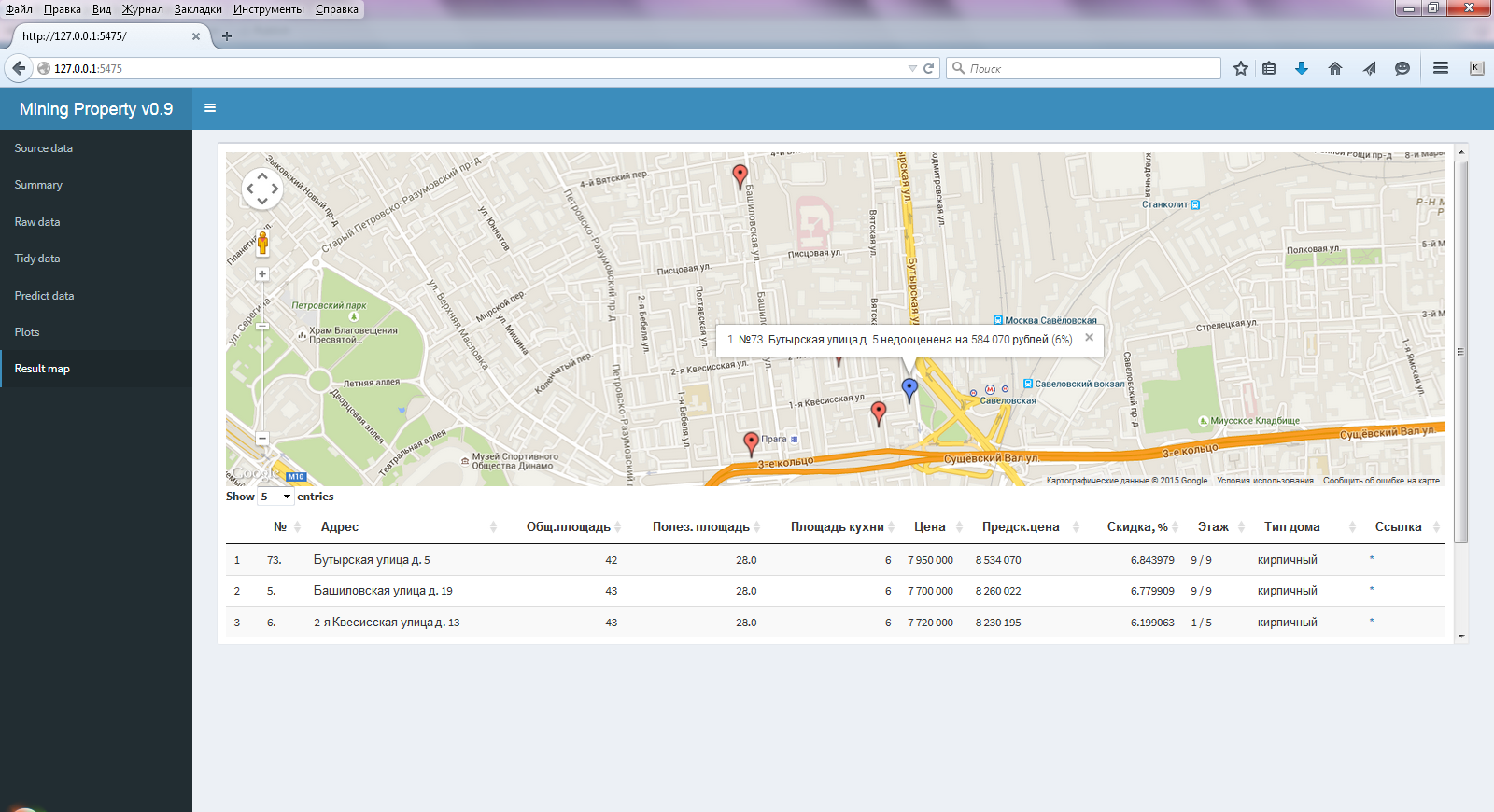
Рис. 3 Окно выбранного меню Result map
Также в этой таблице сразу имеется ссылка (*) для перехода на данное объявление. Данную интеграцию (включение элементов JS в таблицу) позволяет сделать пакет DT.
Заключение
Резюмируя все вышеизложенное, как же все это работает:
- На первой страницы с помощью элементов управления задается исходный запрос
- На основе выбора данных элементов ввода, формируется строка запроса (также она указывается как гиперссылка для проверки)
- Данная строка с указанием страницы передается в API import.io (в процессе создания всего этого, cian начал менять интерфейс вывода, благодаря import.io переобучил я экстрактор буквально в течение 5 минут)
- Обрабатывается получаемый JSON от API
- Перебираются все страницы (в процессе работы отображается строка состояния по процессам)
- Таблицы склеиваются, проверяются (исключаются некорректные значения, заменяются пропущенные значения), приводятся в единообразный вид, пригодный для анализа
- Проводится геокодирование адресов и определение расстояния
- Строится модель по алгоритму случайного леса
- Определяются предсказанные цены, абсолютные, относительные отклонения
- На карте и в таблице под ней отображаются лучшие результаты (кол-во этих результатов указывается на 1 странице)
Вся работа приложения (от начала запроса до отображения на карте) выполняется менее чем за минуту (большая часть времени уходит на геолокацию, ограничение Google для бытового использования).
Данной публикацией хотелось показать, как для простых бытовых нужд, в рамках одного приложения удалось решить много небольших, но принципиально разных интересных подзадач:
- краулинг
- парсинг
- интеграция со сторонним API
- обработка JSON
- геокодирование
- работа с различными моделями регрессий
- оценка их эффективности разными способами
- геолокация
- отображение на карте
Ко всему прочему все это реализовано в удобном графическом приложении, которое может быть как локальным, так и размещенном в сети, и все это сделано на одном R (не считая import.io), с минимумом строк кода с простым и изящным синтаксисом. Конечно, что-то не учитывается, например, дом рядом с шоссе или состояние квартиры (так как этого в объявлениях нет), но итоговый, отранжированный список вариантов, сразу отображаемых на карте и со ссылкой на само исходное объявление, значительно облегчают выбор квартир, ну и плюс ко всему узнал много нового в R.
