Поиск недействительных паспортов или учимся готовить бинарные файлы
 В комментариях к публикации Почему Go превосходит посредственность, один из хабраюзеров предложил в качестве примера написать алгоритм поиска по списку недействительных паспортов.
В комментариях к публикации Почему Go превосходит посредственность, один из хабраюзеров предложил в качестве примера написать алгоритм поиска по списку недействительных паспортов.Одним из условий задачи было — не использовать для этой цели СУБД. Также решение должно по минимуму использовать память, место на диске и ЦП.
К своему удивлению обнаружил, что большинство комментаторов предлагали всё же использовать СУБД, несмотря на то, что решение, использующее стандартные базы данных будет весьма громоздким (кроме того, что для самих данных нужно использовать минимум 5 байт на запись, так ещё и почти столько же места на индексы).
Имея опыт работы над бинарными базами для Sypex Geo, я решил попробовать набросать формат бинарного файла и алгоритм поиска по нему.
Анализ данных
Первым делом, для того, чтобы создать специальный формат файла нужно проанализировать сами данные.
Исходные данные представляют собой CSV файл, в котором находится список недействительных паспортов (серия и номер, разделены запятой), по заданию нас интересуют только российские паспорта (4 цифры серия и 6 цифр номер).
В bz2 архиве этот список занимает 359 МБ, в распакованном виде 1,13 ГБ. Около 102 млн записей.
Я загрузил данные в MySQL (там есть удобная загрузка CSV файла с помощью LOAD DATA), и уже в нём провел анализ данных.
Без индексов таблица со следующей структурой завесила на 680 МБ.
CREATE TABLE `pass` (
`seria` SMALLINT(5) UNSIGNED NOT NULL,
`num` MEDIUMINT(8) UNSIGNED NOT NULL
) ENGINE=MyISAM ROW_FORMAT=FIXED
Если добавить индекс по столбцу num, занято будет 1,5 ГБ, а если сделать индекс по двум столбцам, то уже будет 1,7 ГБ.
Выяснилось, что:
- Для одной серии может быть до 600 000 номеров.
- В то время, как для одного номера максимум 200 серий.
Отсюда делаем вывод, что искать сразу по номеру более выгодно, так как это сильно сократит дальнейший поиск. Значит, делаем индекс по номеру паспорта.
Создаем свой формат
Наш бинарный файл будет состоять из двух частей, первая часть будет представлять собой индекс, в котором будет постоянное количество элементов, а именно миллион значений от 000 000 до 999 999. Каждый элемент индекса занимает 4 байта и содержит смещение во второй части файла, где расположены списки серий для соответствующего номера. Сами серии хранятся во второй части файла в виде двухбайтовых значений. Количество элементов в списке серий для определенного номера — это разница смещений (Искомый номер) и (Искомый номер + 1).
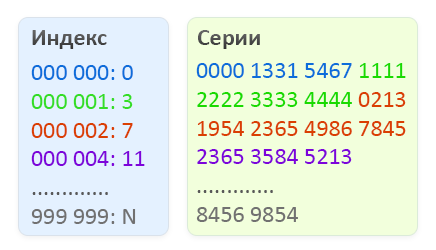
Схематическое отображение структуры бинарного файла для поиска недействительных паспортов.
Чтобы узнать, есть ли паспорт в списке недействительных, нужно произвести следующие простейшие действия.
Для примера возьмем номер 2365 000002.
- По номеру паспорта определяем смещение в индексе, для этого номер умножаем на 4 (размер элемента индекса). 4×000002 = 8 байт (красный блок на рисунке)
- Выполняем смещение и читаем 2 элемента индекса (2×4 байт), чтобы знать начало списка серий и конец. Преобразуем их в 2 десятеричных 32-битных числа. В нашем случае получается 7 и 11 (для наглядности отображения, показаны не смещения в байтах, а 1 единица смещения = 1 серия)
- Читаем данные по смещению начала списка серий до конца списка серий искомого номера, помним, что серии записываются 2 байтами.
- Теперь ищем среди двухбайтовых последовательностей нужную нам серию.
- Если нашли — паспорт недействителен, иначе — в базе недействительных не значится.
Поскольку серий для каждого номера не больше 200, можно искать серию простым перебором. Для ускорения процесса можно использовать бинарный поиск, предварительно отсортировав серии. Но о всяких дополнительных оптимизациях, наверное, в другой публикации напишу, если будет интересно.
А теперь тестирование
Для примера набросал пару тестовых скриптиков на PHP. Один для конвертации CSV файла в наш бинарный формат. Второй для поиска нужного паспорта. Архив со скриптами можно скачать здесь.
Также сравним полученное решение с вариантом, в котором данные в MySQL. Данные хранятся на SSD (в случае с хранением на HDD показатели будут хуже), кроме того на сервере достаточно памяти чтобы кэшировать все таблицы в памяти, т.е. самый оптимальный для MySQL вариант.
Тестирование проводилось на любимой тестовой площадке — Vultr. Любимая потому, что можно быстро поднять мощную VPS-ку с почасовой оплатой и хранение снапшотов бесплатное (т.е. можно удалять, а потом, когда нужно быстро восстанавливать тестовое окружение).
Для VPS выбран план 6 CPU, 8 ГБ, 150 ГБ SSD, MariaDB 10.1.16, PHP 7.0.9.Итак, к цифрам.
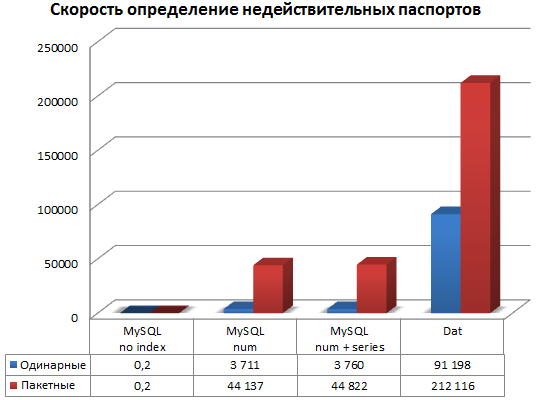
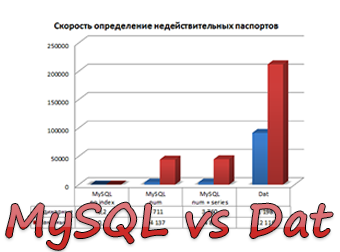
Для каждого типа хранения данных проверили два режима: одинарный режим (когда открытие файла и коннект к БД делается для каждого номера) и пакетный режим (открытие файла и коннект к БД однократные).
| DAT-файл | MySQL без индексов |
MySQL индекс по номерам |
MySQL индекс по номерам и сериям |
|
| Размер БД (включая индекс) | 198 МБ | 680 МБ | 1,5 ГБ | 1,7 ГБ |
| Размер индекса | 4 МБ | 0 МБ | 893 МБ | 1,07 ГБ |
| Загрузка CSV в БД (мм: сс) | 3:54* | 0:31 | 3:38 | 3:42 |
| Скорость поиска одинарная (п/сек) | 91 198 | 0,2** | 3 711 | 3 760 |
| Скорость поиска пакетная (п/сек) | 212 116 | 0,2 | 44 137 | 44 822 |
** Для всех методов осуществлялся прогон по 300 тысячам паспортов, кроме MySQL без индекса, так как, там на поиск одного паспорта уходит до 10 секунд.
Выводы
Как видим по результатам тестирования, кастомное решение заточенное под нужную задачу, может работать значительно быстрее, чем СУБД общего назначения, кроме того формат в 7–8 раз компактнее, чем таблица в MySQL.
А сам скрипт для поиска по файлу занимает меньше 10 строк (без комментов).
$pass = '0307,000000'; // Искомый паспорт
$fn = fopen('passports.dat', 'rb');
// Осуществляем поиск
// Конвертируем серию в 2-байтовый формат, лучше это сделать один раз, чем конвертировать списки серий
$seria = pack('n', substr($pass, 0, 4));
$num = substr($pass, 5);
// Смещаемся к искомому номеру в индексе
fseek($fn, $num * 4);
// Читаем по 2 смещения по 4 байта
$seek = unpack('Nbegin/Nend', fread($fn, 8));
// Читаем серии по найденным смещениям
fseek($fn, $seek['begin']);
$series = fread($fn, $seek['end'] - $seek['begin']);
// Поиск в списке серий
echo ($pos = strpos($series, $seria)) !== false && $pos % 2 == 0 ? 'INVALID' : 'VALID';
P.S. скрипт естественно максимально упрощен, и предназначен для учебных целей, а не для продакшена (но это касается не столько алгоритма, сколько обработки ошибок).
Приветствуется переводы на другие языки программирования, можно будет померяться :)
Комментарии (6)
11 августа 2016 в 09:39
+2↑
↓
А зачем вся эта свистопляска с номерами и сериями? Просто собрать из них 10-значный номер, по ним индексировать и искать. yusman
yusman
11 августа 2016 в 10:53
0↑
↓
И не забыть сделать реверсивный индекс — будет работать быстрее.
11 августа 2016 в 09:56
0↑
↓
Я не понял, с базой вы по сети работали, а файл лежит не в расшаренной папке, а локально на компе, да? youlose
youlose
11 августа 2016 в 10:10
0↑
↓
Предлагаю файлик bench.php из архива посмотреть, там автор на каждый запрос делает соединение к базе данных =)
Даже не знаю как это можно прокомментировать… 30+ лет вроде бы автору…-
youlose
11 августа 2016 в 10:18 (комментарий был изменён)
0↑
↓
Хмммм, невнимательно прочитал статью, но «пакетного» поиска в том файле нет.Там в статье на которую вы ссылаетесь (надо было дать статью на ветку обсуждений) файлик в 1Gb, говорят. Если БД сможет его прожевать, то даже с переподключением будет быстрее работать, чем перечитывание этого файла для каждого запроса поиска. Что именно вы хотели доказать?
11 августа 2016 в 10:42
0↑
↓
Осталось подождать пока тот же кодес перепишут на С и посмотреть на производительность…
