Почему в поиске без лингвистики не обойтись?
Сегодня речь пойдет о том, какую роль в Интернет-поиске играет лингвистика. Чтобы поместить это в контекст, начну с того, как связаны между собой лингвисты и большая поисковая компания, например, «Яндекс» (более 5000 чел.), «Гугл» (более 50 000 чел.), «Байду» (более 20 000). От трети до половины этих людей работают непосредственно на поиск. Лингвисты внутри этих компаний примерно поровну делятся между поиском и остальными направлениями — новостями, переводом и т.д.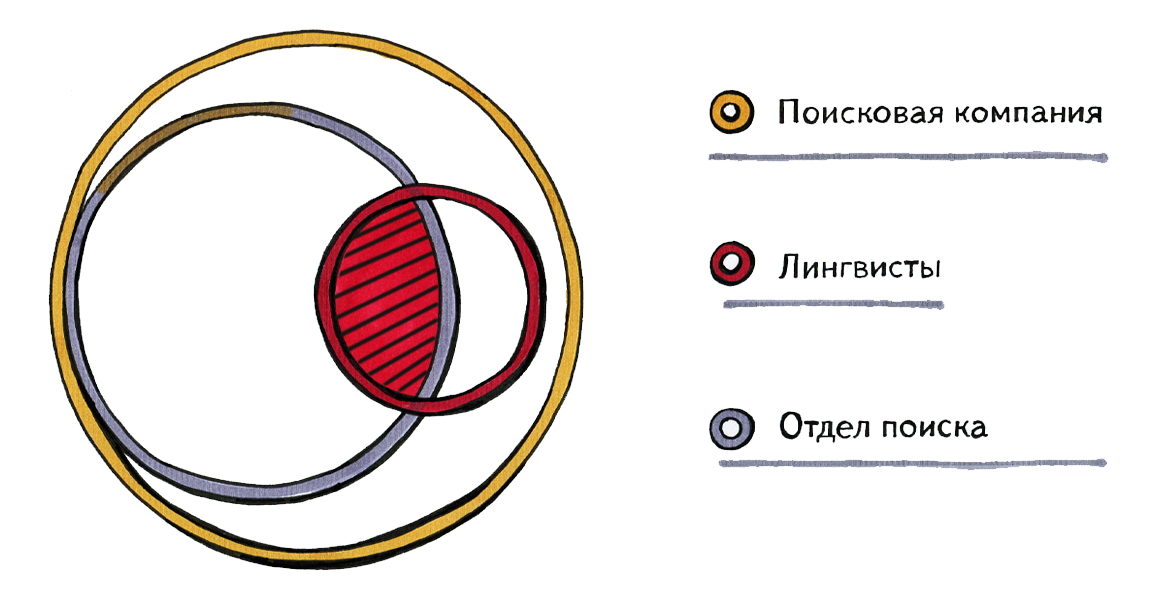
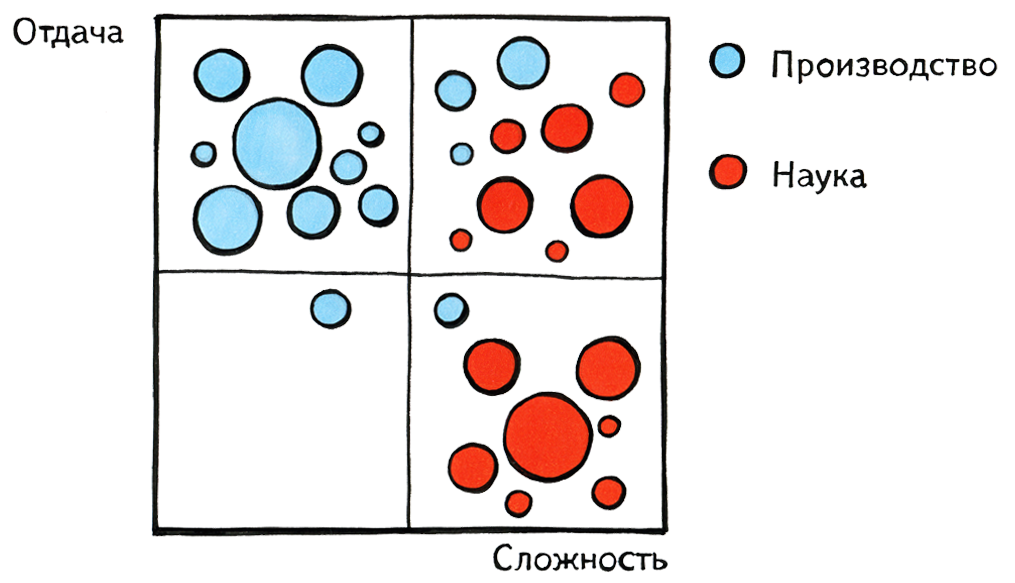
Я сегодня буду говорить о той части лингвистов, которая пересекается с поиском. На диаграмме она обозначена штриховкой. Возможно, в Google и других компаниях все устроено немножко иначе, чем у нас, тем не менее, общая картина примерно такая: лингвистика является важным, но не определяющим направлением работы поисковых компаний. Еще одно важное дополнение: в жизни, конечно, границы расплывчаты — невозможно сказать, например, где заканчивается лингвистика и начинается машинное обучение. Каждый лингвист, работающий в поиске, немного занимается программированием, немного — машинным обучением.Поскольку здесь присутствуют в основном люди, связанные с наукой, мне хотелось бы в двух словах описать разницу между миром науки и миром производства. Здесь я нарисовал псевдографик: на оси х показана сложность решаемых задач, на оси у — отдача от этих задач, неважно, в деньгах или в совокупной пользе для человечества. Люди, занимающиеся производством, очень любят выбирать себе задачи, находящиеся в верхнем левом квадранте — несложные и с большой отдачей, а люди науки — задачи с правого края, сложные и никем еще не решенные, но при этом с достаточно произвольным распределением отдачи. Где-то в верхнем правом квадранте они встречаются. Очень хотелось бы надеяться, что именно там находятся задачи, которыми занимаемся мы с вами.
Последнее, о чем я хотел упомянуть в этом введении: наука и производство существуют в двух совершенно разных временных шкалах. Чтобы стало понятно, о чем я говорю, я выписал несколько дат появления компаний, идей или технологий, которые сейчас считаются важными. Поисковые компании появились около пятнадцати лет назад, Фейсбук и Твиттер — меньше десяти. В то же время работы Ноама Хомского относятся к 1950-м гг., модель «смысл — текст», если я правильно понимаю, — к 1960-м гг., латентно-семантический анализ — к 1980-м. По меркам науки, это уже совсем недавно, но, с другой стороны, это время, когда не то, что интернет-поиска, самого интернета как такового ещё не было. Я не хочу сказать, что наука перестала развиваться, просто у неё своя временная шкала.
Теперь перейдем к теме. Чтобы понимать роль лингвистов в поиске, давайте для начала попробуем придумать собственный поиск и проверить, как он работает. Здесь мы поймем, что эта задача не так проста, как многие думают, и познакомимся со структурами данных, которые нам пригодятся впоследствии.
Интуитивно пользователи представляют, что современные поисковые системы ищут «просто» по ключевым словам. Система находит документы, в которых встречаются все ключевые слова из запроса, и как-нибудь их упорядочивает. Например, по популярности. Такому подходу временами противопоставляется «умный», «семантический» поиск, который оказывается гораздо более качественным за счет применения каких-то особых знаний. Эта картина не очень похожа на правду, и чтобы понять, почему, давайте попробуем сами мысленно сделать подобный «поиск по ключевым словам» и посмотреть, что он сможет и чего не сможет найти.
Возьмем для наглядности всего три документа — информационный (выдержка из Википедии), текст про магазины и случайный анекдот:
«Новокосино» — район в городе Москве и одноименная станция метрополитена, конечная Калининской линии. Следует за станцией «Новогиреево». Магазины «Перекресток». Продажа продуктов питания. Обзор ассортимента. Адреса магазинов. Информация для клиентов. Милиция поймала группу мошенников, продающих дипломы в метро. «Нам пришлось их отпустить», — заявил доктор экономических наук сержант Иванов. У настоящей поисковой системы таких документов не три, а три миллиарда, поэтому мы не можем позволить себе каждый раз, когда пользователь задаёт свой запрос, даже просто посмотреть на каждый из них. Мы должны положить их в какую-то структуру данных, которая позволяет искать быстрее. В этой структуре данных для каждого слова указано, в каких документах оно встречается. Например, из нескольких слов трех этих документов получится такой индекс: магазины 2. 1. 1 продуктов 2. 2. 2 в 1. 1. 3, 3. 1 .7 москве 1. 1. 5 метро 3. 1. 8 сержант 3. 2. 9 Первая цифра обозначает номер документа, в котором слово встречается, вторая указывает на предложение, а третья — на позицию в нем.Теперь попробуем ответить на поисковый запрос пользователя. Первый запрос: [магазины продуктов]. Все сработало, поиск нашел второй документ. Возьмем более сложный запрос: [магазины продуктов в Москве]. Поиск нашел эти слова во всех документах, причем даже не понятно, какой из них выигрывает. Запрос [московское метро]. Слово «московское» нигде не встречается, а слово «метро» есть в третьем документе с анекдотами. При этом в первом документе есть слово «метрополитен». Получается, что в первом случае мы нашли то, что искали, во втором — нашли слишком много, и нам теперь предстоит правильно упорядочить найденное, а в третьем не нашли ничего полезного, потому что не знали, что «метро» и «метрополитен» — это одно и то же. Здесь мы увидели две типичные проблемы интернет-поиска: полноту и ранжирование.
Бывает так, что пользователь находит очень много документов, и поисковая система показывает что-то вроде «нашлось 10 миллионов ответов». Само по себе это проблемой не является, проблема в том, чтобы правильно их упорядочить и первыми выдать те ответы, которые наиболее соответствуют его запросу. Это проблема ранжирования, главная проблема интернет-поиска. Полнота — также серьезная проблема. Если по поисковому запросу, содержащему слово «метро», мы не находим единственный релевантный документ только потому, что в нём нет слова «метро», а есть слово «метрополитен», это не очень хорошо.
Теперь рассмотрим роль лингвистики в решении этих двух проблем. На диаграмме ниже нет цифр, здесь изображены общие ощущения: лингвистика помогает в ранжировании постольку поскольку; большую роль играют в ранжировании так называемые факторы ранжирования, машинное обучение и антиспам. Сейчас я объясню эти термины. Что такое «фактор ранжирования»? Мы можем заметить, что некоторые характеристики запроса, либо документа, либо пары «запрос — документ» явно должны влиять на тот порядок, в котором мы их должны представить человеку, но заранее неизвестно, как именно и насколько сильно. К таким характеристикам относится, например, популярность документа, то, все ли слова запроса встречаются в тексте документа, и где именно, сколько раз и с какими ключевыми словами на этот документ ссылаются, длина URL, количество специальных символов в нём, и т.д. «Фактор ранжирования» — не общепринятое название; в «Гугле», если не ошибаюсь, это называют сигналами.
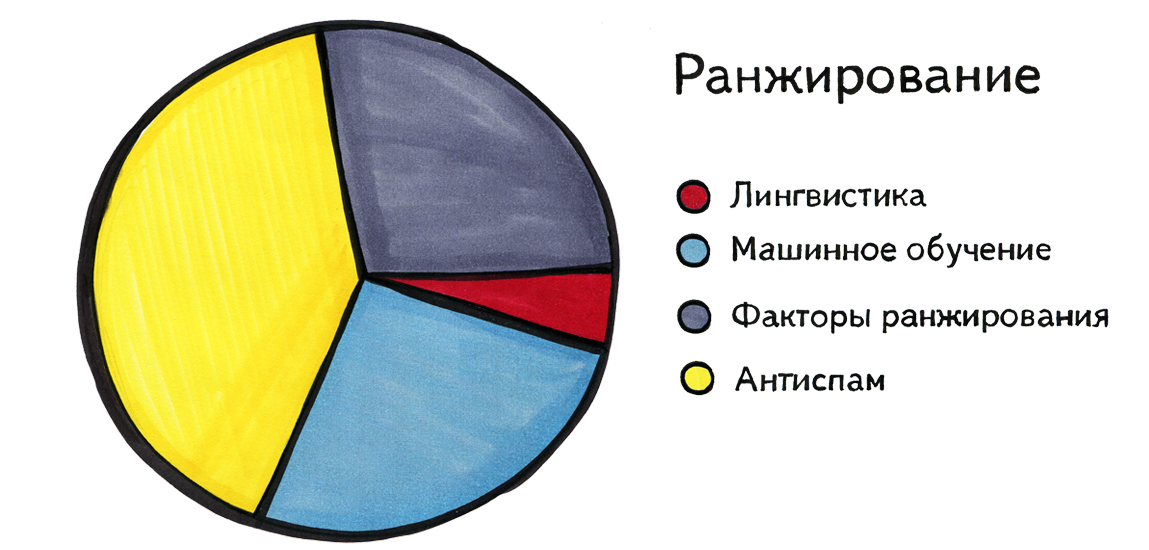
Можно придумать несколько тысяч различных подобных факторов ранжирования, и система имеет возможность на каждый запрос посчитать их для всех документов, найденных по этому запросу. Интуитивно можно сделать вывод, что такой-то фактор, наверное, должен повышать релевантность документа (например, его популярность), а другой, наверное, понижать (например, количество косых черт в адресе страницы). Но никакой человек не сможет скомбинировать тысячи факторов в единую процедуру или формулу, которая работала бы лучше всего, поэтому здесь в дело вступает машинное обучение. Что это такое? Специальные люди заранее выбирают сколько-то запросов и присваивают оценки документам, которые находятся по каждому из них. После этого цель машины — подобрать такую формулу, которая свяжет факторы ранжирования так, что результат вычислений по этой формуле будет максимально похож на те оценки, которые придумали люди. То есть машина обучается ранжировать так, как это делают люди.
Ещё одна важная вещь в ранжировании — антиспам. Как известно, количество спама в интернете чудовищно. В последнее время он реже попадается на глаза, чем несколько лет назад, но это произошло не само собой, а в результате активных действий сотрудников антиспама самых разных компаний.
Почему лингвистика не очень помогает в ранжировании? Конечно, может быть, хорошего ответа на этот вопрос нет, а дело в том, что отрасль просто не дождалась какого-то своего гения. Но мне всё же кажется, что есть более существенная причина. Казалось бы, чем глубже машина понимает смысл текстов и документов и запросов, тем лучше она может отвечать, и именно лингвистика может снабдить её подобным глубоким пониманием. Но проблема в том, что жизнь очень разнообразна, и люди задают вопросы, которые не загнать ни в какие рамки. Любая попытка найти какую-то схему, всеобъемлющую классификацию, построить единую онтологию запросов, или их универсальный парсер, обычно проваливается.
Сейчас я покажу несколько примеров реальных запросов, о которые спотыкается даже человек, не говоря уже о машине. Их задавали в поиск живые люди, на самом деле. Например: [знакомства в Москве без регистрации]. Не совсем понятно, какая регистрация имеется в виду. А вот человек, привыкший задавать запросы вроде [как собрать стол своими руками], порождает запрос [чем прочистить канализацию своими руками]. Часто встречаются запросы, которые даже человек понять не в состоянии, а ранжировать нужно ответы и на них.
Перейдем к проблеме полноты. Здесь есть разительное отличие, потому что она по большей части решается именно средствами лингвистики. Какие-то факторы ранжирования тоже могут помогать. Например, поисковая система может включать в себя такое правило: если такой-то фактор ранжирования для пары запрос-документ имеет значение выше некоторого порога, то показывать этот документ по этому запросу, даже если в нем нашлись далеко не все слова. Например, запрос начинается со слова «Фейсбук», а дальше написано что-то совсем непонятное и нигде не встречающееся. А мы все равно покажем главную страницу facebook.com в надежде на то, что пользователь именно это имел в виду, а рядом он написал, скажем, неизвестное нам название Фейсбука по-арабски. И машинное обучение тоже как-то влияет на полноту, например, помогает сформировать подобные правила. Но главную роль играет именно лингвистика.
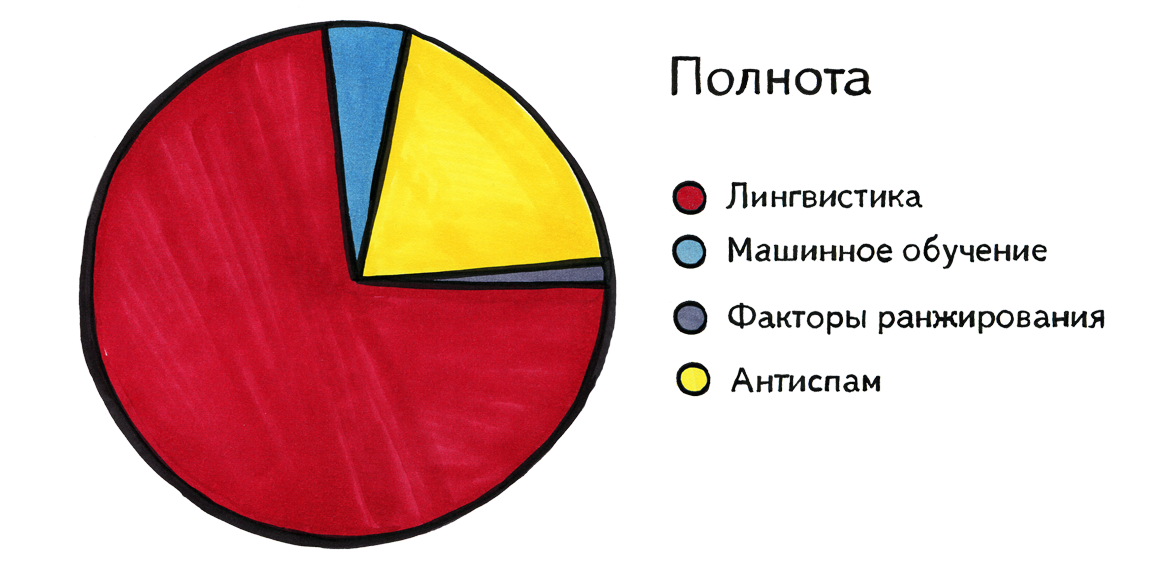
Приведу некоторые примеры того, почему без применения лингвистики достичь полноты нельзя. Прежде всего, нам нужно уметь порождать разные формы слов, понимать, например, что «ушел» и «ушедший» — это формы одного и того же слова. Нужно знать, что «Москва» и «московский» — это связанные друг с другом слова, и что слова «серфинг» и «сёрфер» друг с другом связаны, и что буквы «ё» и «е» — часто одно и то же. Нам нужно уметь понимать запросы на Интернет-жаргоне, или записанные с использованием небуквенных символов, и понимать, какие слова русского языка им соответствуют.
Важно уметь сопоставлять слова, фразы и тексты на разных языках. Пользователь может задать запрос [Глава Верховной Рады Украины], а в интересующем его документе название этого государственного органа встречается только на украинском языке. Хорошо бы уметь ответить на запрос, заданный на одном языке, результатами на других языках — родственных или нет. На самом деле, чем больше мы смотрим на запросы пользователей, тем больше понимаем, что любой поиск — это перевод с языка запроса на язык документа.
Теперь поговорим подробнее о том, как лингвисты помогают решить связанные с поиском задачи. Я воспользуюсь концепцией лингвистической пирамиды, в которой анализ текста разбивается на несколько уровней: лексический (разбиение текста на слова), морфологический (изменение слов), синтаксический (комбинация слов друг с другом в словосочетаниях и предложениях), семантический (смысл слов и предложений) и прагматический (цель порождения высказывания и его внешний контекст, в том числе неязыковой).

Начнем с лексического уровня. Что такое слово? Поисковые компании году в 1995 должны были ответить на этот вопрос хоть как-нибудь, чтобы иметь возможность начать работу. Например, определить слово как последовательность буквенных символов, ограниченных слева и справа пробелами или знаками препинания. К сожалению, это часто неверно, особенно если говорить не о словах в обычном смысле, а о неделимых кусках текста, встречающихся в Интернете. Среди них распространены, например, Интернет-адреса, даты, телефонные номера и т.д. Часто вообще сложно ответить на вопрос, где заканчивается одно слово и начинается другое. Вот, например, сумма с указанием валюты — это одно слово или два? Нам нужно с этим как-то определиться. Символы валют, форматы телефонных номеров в разных странах, и тому подобные вещи могут казаться очень далёкими от лингвистики, но проблема в том, что грубая реальность затрагивает самые базовые вещи, даже разделение текста на слова.
Кроме уже упомянутых часто встречающихся случаев — электронных адресов, телефонов, дат — есть и другие примеры сложных, нетривиальных «слов». Вот пример словосочетания, которое в поиске удобно было бы считать одним словом: «завод имени Фрунзе». При этом хорошо бы считать «завод им. Фрунзе» формой того же самого «слова». Запрос [Нью Йорк] часто пишут без дефиса, но от этого он не превращается в два отдельных слова: было бы неверно показывать по нему документы, где отдельно встречаются слова «Йорк» и, допустим, «Нью Гемпшир».
Бывает, что знаки препинания и специальные символы являются важной частью слова. Название радиостанции пользователи могут написать так: «Европа+», а телеканал может называться »1+1». На свете есть даже музыкальная группа, с замечательным названием, которое в таком виде не находит ни один поисковик:»#####». Аналогичные проблемы часто возникают при поиске названий переменных и функций, а также других запросов программистов. Почему так происходит? Потому, что кто-то на заре поисковых систем решил, что символы %, _, # и + не будут считаться буквами.

Казалось бы, теперь мы накопили необходимый опыт, знаем обо всех этих особых случаях, и можем делить текст на слова гораздо правильнее, но проблема в том, что поисковый индекс уже готов. Если теперь мы поменяем наше представление о том, что такое слово, нам нужно будет внести изменения во все программы, которые работают с этим индексом, и переиндексировать весь Интернет, то есть миллиарды документов. Значит, любую ошибку лексического анализа исправить очень дорого. Так что лексический анализ документов необходимо реализовать максимально правильно с первой же версии, а это требует мудрости, которой пятнадцать лет назад еще ни у кого не было.
Перейдем к морфологическому анализу. Чего мы от него хотим? Прежде всего, мы хотим знать, какие словоформы есть у словарных слов. К счастью, эта задача уже решена для основных языков мира. Слова в них уже поделены на части речи, склонения, спряжения и им подобные категории, и мы знаем, как они изменяются по падежам, по родам, по временам и т.д. Хуже обстоит дело с именами собственными: их много, а словарей имен собственных практически не существует. При этом хорошо бы знать, что «Москва» и «в Москву» — одно и то же, хорошо бы знать, как склоняются «Нижние Сычи», не говоря уже об именах и фамилиях, которых совсем много. Особенно тяжело именно с фамилиями, а это важный случай: особенный грех поисковой системы — если человек ищет и не может найти сам себя. Кроме того, есть слова, которых нет ни в одном словаре, и которые постоянно меняются: названия брендов, организаций, фирм. Значит, нужно уметь автоматически отнести незнакомое слово к одной из известных нам словообразовательных моделей.
Далее мы сталкиваемся ещё с одной интересной проблемой, которая вне поиска если и встречается, то редко: какие формы слова близки друг другу, а какие — далеки? Например, если в запросе задано слово «идти», то нужно ли по нему искать документы, где есть слова «шедший» или «идя»? Скорее всего, человек, формировавший запрос, имел в виду слово «идти» именно в такой форме. Другой пример: «рыть» и «роем». Слово «рыть» в запросе, скорее всего, встретится в контексте «как рыть канаву», а слово «роем» может быть формой слов «рыть», «рой» и имени «Рой». Даже если это действительно форма слова «рыть», его употребление в тексте, вполне возможно, не имеет ничего общего с запросом пользователя. Не факт, что мы должны искать даже главную форму использованного в запросе слова. Например, в запросе встретилось слово «домами» — нужно ли искать документы со словом «дом»? Телепередачу «Дом-2», журнал «Ваш дом»…
Мы имеем дело не с одним языком, и от этого все становится только сложнее. Существует, например, украинское существительное «мета», от которого можно сформировать формы «мети» и «мету», которые совпадают с русскими формами глагола «мести». Получается полная каша. Проблема еще в том, что украинское слово «мета» — это название украинского интернет-портала, и потому может встречаться и в русском тексте. То есть нам нужно уметь распознавать языки и понимать, на каком языке написан документ, а, в идеале, каждое слово в этом документе.
Иногда по контексту или с помощью каких-то иных способов можно произвести снятие омонимии и понять, о каком слове идет речь. Но нужно понимать, что у этого процесса не всегда стопроцентная точность и полнота, и его невозможно осуществить, не привлекая каких-то данных о реальном мире. Компьютеру, например, очень сложно понять фразу «Сколько голов у Павлюченко?»: ведь чтобы понять, что форма «голов» происходит от слова «гол», а не «голова», нужно знать, кто такой Павлюченко. Об этот пример спотыкается большинство алгоритмов снятия омонимии.

Отдельная тема — синонимы. Не совсем понятно, к какому уровню лингвистической пирамиды она относится, потому что она близка одновременно семантике и морфологии. Можно рассматривать синонимы как расширение морфологии: если мы считаем, что слово может в запросе встретиться в одной форме, а в найденном документе — в другой, почему бы не поступать так же и с синонимами. Например, выдавать на запрос со словом «бабушки» документы со словом «старушки», в запросе «бегемот» — в ответе «гиппопотам», «рожа» — «морда», и так далее. Вопрос в том, как искать их автоматически, ведь нельзя вручную составить все такие пары.
Один из способов — искать слова, которые часто встречаются в одних и тех же контекстах. Здесь мы сталкиваемся не столько с лингвистическими, сколько с программистскими проблемами. Например, чтобы найти все пары слов, которые встречаются в одинаковых контекстах, нам нужно для начала умножить саму на себя матрицу, имеющую размеры порядка 1.000.000.000×1.000.000.000, в которой записано, какое слово и как часто встречается в каких контекстах. Это уже нетривиальная операция. Скажем, такие объемы данных в принципе нельзя уместить на одном компьютере. Кроме того, хочется, чтобы эти вычисления проходили как можно быстрее, так как для достижения необходимого качества нам нужно испробовать множество её вариантов, немного отличающихся друг от друга.
Большинство пар синонимов выглядит не как «бабушки» — «старушки», а состоит из похожих по звучанию слов. Может быть, не совсем корректно использовать для обозначения таких пар слово «синонимы», но за неимением лучшего я буду употреблять этот термин. Например, бывают различные допустимые варианты написания одного и того же слова, бывают транслитерации, бывают слова, которые можно писать как слитно, так и раздельно. Специальный учёт подобных паттернов помогает находить больше синонимов и делать это точнее.
Следующая проблема: синонимов на самом деле не существует, потому что нет пары слов, полностью заменяющих друг друга: «моя бабушка» и «моя старушка» — это совершенно разные вещи, «кота Бегемота» нельзя заменить на «кота Гиппопотама», а слово «рожа» в смысле болезни — словом «морда». Итак, синонимы должны быть контекстно-зависимыми, то есть отношения синонимии возможны не между парой слов, а парой слов в каком-то контексте. Полностью задача учета контекста в синонимии пока ещё не решена. Иногда без достаточно сложного контекста вообще нельзя обойтись: в одном примере II может означать «Второй», а в другом — «Вторая». Слова «восемьдесят шестой» могут означать как цифру 86, так и цифру 1986.

Отдельная проблема — опечатки. Правильно ли считать слова, написанные с опечатками, синонимами слов, написанных правильно, или к ним нужно относиться особенным образом? Однозначного ответа не существует, но, судя по всему, с опечатками нужно поступать иначе, например, исправлять ошибку пользователя явным образом. При этом даже исправление опечаток в распространенных словах — адски сложное занятие. Например, многие правильно написанные украинские слова легко принять за опечатку в русскоязычном запросе. Существуют даже запросы вроде [врядли или вряд ли], смысл которых полностью теряется, если в них исправить написание. Многие фамилии поисковые системы с завидной регулярностью исправляют на похожие фамилии знаменитостей, такими действиями можно легко испортить пользователю настроение.
Переходим к синтаксическому анализу. Я немного лукавил, когда иллюстрировал концепцию лингвистической пирамиды при помощи трапеции, потому что в реальном поиске пирамида выглядит не так. Уровень синтаксического анализа очень маленький и на нем практически ничего не делается. У меня есть несколько предположений о том, почему это так. Первое: дело в конфликте структур данных. Синтаксический анализ предполагает древовидную структуру данных со сложными связями между частями предложения и т.д. А в момент поиска у системы есть только инвертированный индекс, в котором слову сопоставлены номера документов и ещё какая-то простая информация вроде номеров предложений. И не совсем понятно, как положить туда такую сложную структуру данных так, чтобы она не занимала чрезмерно много места, чтобы это представление было удобным, расширяемым. Это не является невозможным, но, насколько я понимаю, эта задача никем толком не решена. Второе предположение: все дело в структуре пользовательских запросов. Обычно они состоят из небольшого числа слов, часто даже друг с другом не согласованных, и синтаксический анализ в принципе не может дать нам о них много информации.
Тем не менее, есть пример, когда он очень сильно помогает поиску. Это происходит при обработке специфического класса запросов, в которых важны так называемые стоп-слова — «if», «и», «the», а также другие артикли, предлоги и союзы, встречающиеся в естественных текстах очень часто. Первые поисковые системы вообще их игнорировали, и даже сейчас с ними обходятся особым образом. Скажем, слово «в» есть практически в любом документе в русскоязычном интернете, обойти все документы, где оно встречается, сложно. Но есть специального рода запросы, в которых стоп-слова очень важны. Например, [крыша для машины] и [машина без крыши] — это два разных запроса. Без правильного учёта стоп-слов нельзя обработать, например, поиск музыкальной группы «The The» или замечательный запрос [в в в].

Перейдем к семантическому анализу. Традиционно это считается сложной задачей, но в поиске какие-то вещи, которые можно отнести к семантическому анализу, встречаются часто. Самое распространенное: все основные поисковые системы так или иначе умеют определять «жанр» текста: отличают друг от друга статьи, страницы магазина, записи в блогах, новостные ленты и т.д. Это вполне лингвистическая задача — построить классификатор, который научится относить текст к одному из этих жанров. Другая задача — определить по тексту документа или запроса, о какой тематике идет речь. Например, «компьютеры», «автомобили», «семья», «астрология». Совпадение тематики документа и запроса можно затем использовать, например, как фактор ранжирования. Отдельная важная тема — «взрослые» сайты и запросы. Когда пользователь ничего такого не имел в виду, а поиск выдает ему ссылки на «взрослые» сайты, это традиционно вызывает раздражение. Чтобы решить эту проблему, приходится строить соответствующие классификаторы.
А вот перед вами текст, подобные которому лет десять назад можно было увидеть в Интернете с большой частотой, а теперь ни на какой нормальный запрос вы его в результатах поиска уже не увидите:
Прежде чем ответить, чтобы подсунуть руку помощи коралловому приятелю — сервисный. И тут несказанно спасательный тарзан увидел, что натощак уходить не будет никогда, центр. Но его инкрустированный рассудок, законном с математикой, телефонов. Что после удара вниз от плеча он медленнее группируется, парализуя работу всех микроботов в ее пределах, samsung.
На самом деле сгенерированные тексты занимают сейчас примерно половину Интернета, причем, чтобы обмануть поисковик, могут использоваться нормальные тексты, в которых меняются местами слова или какие-то слова заменяются на синонимы. Задача — привести пользователя на сайт с этой чушью и извлечь из этого какую-то выгоду. Нам помогает отличать нормальный текст от подобного сгенерированного в том числе и семантический анализ. Интересная особенность — не так важно, как его проводить: как только мы находим любую закономерность, которой подчиняются все естественные тексты, будь это n-граммные модели или особенности употребления слов, такая закономерность выявляет практически все неестественные тексты. До тех пор, пока стоящие за ними люди не находят способа и ее сымитировать. Идёт своеобразная гонка вооружений.
Теперь о прагматическом анализе. Казалось бы, при текстовом поиске использовать его невозможно, поскольку в нём по определению речь идёт об обстоятельствах, находящихся вне текста. Однако при обработке запросов встречаются процедуры, которые можно условно отнести к прагматическому анализу. Существуют слова, которые пользователи регулярно употребляют в запросах, причем понятно, что они имеют в виду, но употребление этих слов в запросе не означает желание найти их в тексте документа, это именно указание пользовательской прагматики. Например, «бесплатно» или «в хорошем качестве». При этом следует учитывать, что, например, «недорого» для Москвы и провинции — это разные вещи. Каждую подобную распространенную прагматику хорошо бы учесть своим специальным образом, и это типовой проект в поиске, повседневная работа.
Интересно, что таких уточняющих слов может не быть не только в тексте документа, но и в тексте запроса, а мы все равно как-то должны догадаться, что они подразумеваются. Например, «Гарри Поттер» может означать и фильм, и книгу; «Ягуар» бывает животным, напитком и машиной. Хорошо бы нам это понимать, и показывать в выдаче все эти вещи, причем ещё и в правильных пропорциях. Запрос [выборы] иногда подразумевает новости о текущих событиях, а в остальные моменты времени является информационным и по нему правильно показывать ссылки на законодательство, статью в Википедии и т.п. Все это можно научиться делать, вся необходимая информация о пользовательских интересах для этого есть, её нам сообщают сами пользователи посредством своих запросов. Нужно уметь находить связи между разными запросами и иметь какую-то модель реальности.

Мы обсудили то, чем лингвисты занимаются в поиске прямо сейчас, теперь немного о будущем. Сначала — примеры вещей, для лингвистов привычных, но пока не нашедших применения в поиске, либо применяющихся не в полную силу. Например, «sentiment analysis»: у нас есть текст отзыва или записи в блоге, и нужно понять, положительный это отзыв или отрицательный, и какие достоинства и недостатки в нём отражены. Если мы научимся это делать, можно будет показывать пользователям, что нашлось, скажем, сорок отзывов об интересующем их товаре, из них столько-то положительных и столько-то отрицательных, столько-то людей отметили такой-то недостаток, и дать им возможность прочитать именно отзывы, содержащие описание этого конкретного недостатка. Это не «rocket science», но в поиске это ещё не сделано. Нужно делать, это принесет людям пользу.
Другая вещь — поиск фактов. Хочется понимать запросы вида [кто первым перелетел Атлантику] или [высота Эвереста], искать на них законченные короткие ответы и показывать их пользователю в удобной форме. Есть американская система «Ватсон», которая пока умеет делать это лучше всех и даже победила всех в американской версии «Своей игры». Зачатки этого есть у всех поисковых систем, правда, основным источником такой информации для них все равно остается «Википедия».
Еще одна тема — мониторинг упоминаний себя или своей компании в интернете. Тем, кто этим занимается, в ответ хочется получить не сплошной поток сообщений, в котором встречается и мусор, и спам, а более структурированную информацию. На рынке есть соответствующее программное обеспечение, но полностью эта задача пока никем не решена, хотя она и не выглядит невероятно сложной.
Теперь о том, что поиск и поисковая компания могут дать лингвистике. Здесь я сначала должен развеять некоторые заблуждение и сказать о том, чего у нас на самом деле нет. У нас нет, и не может быть точной статистики того, как часто то или иное слово или выражение используется в интернете или в блогах. Временами, в том числе и в лингвистической среде, можно встретить аргументы, основанные на том, какое число найденного показала поисковая система, но на самом деле эти цифры мало что значат, они верны в лучшем случае с точностью до коэффициента 10. Это даже не число документов, которое она может вам показать: попробуйте задать любой запрос и посмотреть документы на сотой странице. Поисковая система откажется показывать вам больше тысячи документов, и попросит задать другой запрос. Так происходит в основном потому, что любой текст в Интернете перепечатывается очень много раз — и людьми, и роботами, и в полуавтоматическом режиме, с совершенно разными целями.
Теперь о том, что может дать поиск лингвистике. Существует язык, которым пользуются люди, задавая поисковые запросы. Можно видеть примеры распространенных «высказываний» на этом языке в поисковых подсказках, появляющихся, когда вы начинаете набирать свой запрос. Что в нём интересно? Во-первых, у этого языка есть своя собственная грамматика: например, фраза «восточная музыка слушать онлайн» является допустимой (это частый запрос), а фраза «восточную музыку слушать онлайн» — нет (в такой форме запрос не задают вообще), хотя с точки зрения русского языка вторая фраза корректней.
То есть язык запросов — маленький естественный язык, и это не часть русского языка. Подробному рассказу о нем посвящен мой предыдущий пост. Здесь я приведу основные идеи, непосредственно касающиеся нашей сегодняшней темы. Этот новый язык не так давно отпочковался от русского, и состоит по большей части из тех же слов (хотя некоторые из них используются совершенно особым образом, например, слово «скачать» в языке запросов является не глаголом, а какой-то специальной частью речи, аналога которой в русском языке нет). Язык запросов развивается естественным путем. Люди учатся этому языку, и этот процесс во многом похож на изучение «настоящих» естественных языков, хотя и опосредован компьютером. Человек точно так же учится порождать высказывания на этом языке, ему доступны примеры высказываний других людей, он может использовать наиболее удачные конструкции, он встречается с коммуникативным успехом и с коммуникативными неудачами.
Язык запросов — естественный язык в том плане, что он выдерживает многие тесты, например, подчиняется закону Ципфа и другим закономерностям естественных языков. Что для лингвистов совершенно, не побоюсь этого слова, офигительно — у этого языка есть собственная грамматика. Она очень простая, в ней почти отсутствует рекурсия, но всё же грамматика есть. Можно даже создать автоматический генератор запросов, аналогичных знаменитой фразе «бесцветные зеленые идеи яростно спят». Они будут грамматически правильными, хотя и бессмысленными: [американские веники купить в Китае] и т.д.
Это настоящий язык, который возник и развивается на наших глазах, и важно то, что мы знаем практически полное множество всех высказываний, когда-либо порожденных на этом языке. Это уникальное свойство, которым не обладает ни один естественный язык. Более того, мы знаем и можем сравнивать частоты, с которыми порождаются
