Платформа обработки данных Билайн
Весь телеком-бизнес основан на данных, и Билайн не исключение. Данные генерируются как внутри, так и снаружи: в OSS-системах (события на оборудовании, сетевой трафик), в BSS-системах (клиентские транзакции, маркетинговые кампании), на платформах Яндекс, Google и других. Общее количество систем, с которыми работает компания, исчисляется сотнями.
Чтобы извлекать пользу из всех этих данных, в Билайн с 2014 года существует и развивается платформа для их обработки. Считаю полезным для ИТ-сообщества делиться опытом, поэтому начинаю цикл статей о платформе обработки данных в Билайн.
Этот пост является первым. Поэтому для старта я кратко расскажу о роли платформы в реализации стратегии компании, предоставляемых возможностях (capabilities) и основных характеристиках. В последующих постах я буду более детально останавливаться на каждом элементе, иногда даже с погружением в отдельные компоненты.
Началом существования платформы обработки данных принято считать то время, когда в Билайн начали стартовать первые digital-проекты, основанные на аналитике данных. Платформа была создана как лаборатория: состав технологий мог меняться с каждой новой задачей, объем оборудования определялся глубиной данных, необходимых конкретным продуктовым командам. Тогда же начала формироваться команда девопс-инженеров, в руках которой и по сей день находится эксплуатация платформы.
Но сейчас это уже продукт с регламентами эксплуатации, контролем за доступом к данным, постоянными линиями поддержки и мониторинга. Естественно, все это развивается дальше и не стоит на месте — поэтому и появился этот материал.
Роль платформы в стратегии
Топ-менеджмент Билайн с 2020 года принял решение о внедрении компании доменного подхода к данным. Да, мы теперь тоже строим data mesh. На практике это означает переход к схеме работы, когда ответственность за данные распределена между подразделениями компании. Когда эта трансформация завершится, граница между ИТ и бизнесом будет стерта полностью — компетенции по работе с данными будут везде. В новом состоянии компании разработкой и аналитикой будут заниматься буквально в каждом подразделении. У каждого логического куска данных будет хозяин. И это будет не ИТ-подразделение.
Идеологической основной для нас были и остаются 2 статьи:
· https://martinfowler.com/articles/data-monolith-to-mesh.html
· https://martinfowler.com/articles/data-mesh-principles.html
Далеко не многие компании так делают, это сложный по реализации подход. На первый взгляд проще организовать одну центральную команду, которая принимает в разработку различные задачи по ТЗ, а потом сообщает о том, что все готово. Это приводит в итоге к непрозрачности отнесения расходов, конфликтам интересов и сложной процедуре передачи информации между «заказчиками» и «исполнителями». Мы считаем это анти-паттерном.
Мы решили поместить специалистов по работе с данными во все подразделения, чтобы приоритеты раздавались напрямую, непосредственно в продуктовых командах. Все необходимые роли, которые нужны для продукта, собираются в команду под управлением владельца продукта. Он напрямую ставит задачи архитектору, инженеру данных, data scientist-у, BI-разработчику, аналитику.
Иллюстрация подхода ниже
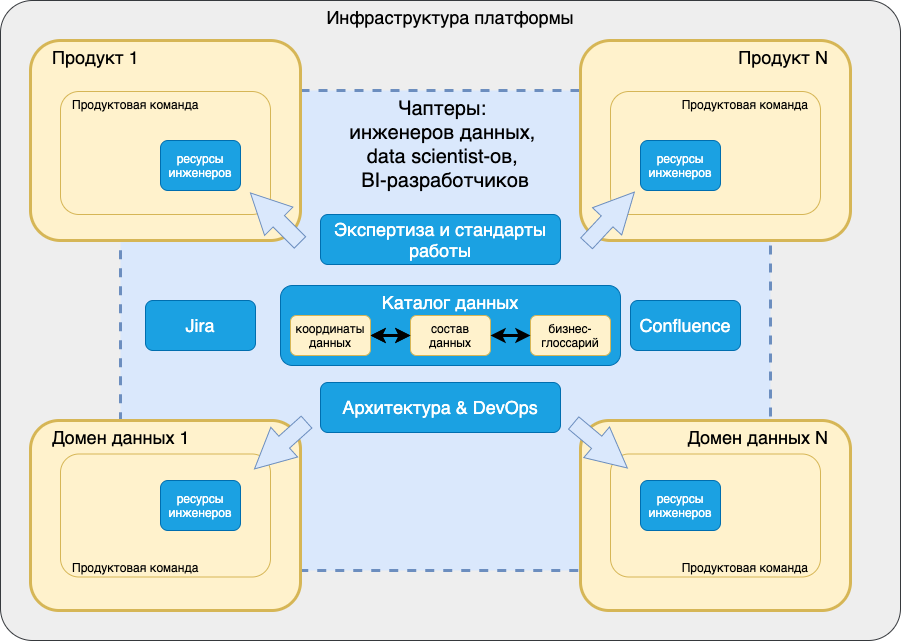
Сразу оговорюсь, что загрузку группы источников мы тоже рассматриваем как своего рода продукт особого типа — домен данных, приближенный к источнику.
Продуктовый подход повышает вовлеченность сотрудников и делает работу более прозрачной. Сразу видно: во что мы вкладываем и что получаем. Исключается конкуренция между продуктовыми командами, которые просят разработчиков помочь сделать что-то вперед других. Все происходит параллельно.
А платформа нужна для того, чтобы все продуктовые команды работали на конечном, детерминированном стеке, обеспеченном командой эксплуатации. Ведь подход data mesh не говорит сколько баз данных или физических платформ должно быть. Мы для себя решили, что экономически проще набирать и готовить людей нескольких определенных профилей, обеспеченных коммунальными возможностями платформы.
Самое время их перечислить.
Возможности платформы
1. Оркестрация обработки данных.
Построение зависимостей между задачами, запуски по расписанию. Тесно связан со следующим пунктом. Airlow запускаем на Kubernetes для каждой команды — свой экземпляр с соблюдением всех правил по безопасности.
Стек: Целевой — AirFlow, Legacy — Oozie
2. Обработка потоковых данных.
Наши самые большие потоки — это события на уровне сети, возникающие на низком уровне при передаче data-трафика, голоса, сообщений и т. д. Сюда же относится загрузка потоковых данных и их обогащение online. В основном это данные OSS-уровня.
Стек: NiFi, Flink.
3. Пакетная обработка данных aka ETL.
Все еще самый доступный и популярный способ ввиду его исторической массовости. Снова сюда же относится пакетная (batch) загрузка данных. Это преимущественный способ работы с данными из BSS-систем.
Стек: Целевой — Spark, Legacy — MapReduce.
4. Хранение данных.
Хранение в разных видах — блочное, файловое, объектное, табличное, колоночное. Зависит от типа решаемой задачи.
Стек: HDFS, Hive, Ceph, GreenPlum, MySQL, Postgres, ClickHouse.
5. Continuous integration & Continuous delivery.
Сборка кода и обновление версий в продуктиве
Стек: GitLab, Nexus, Terraform, Vault.
6. Транспорт данных.
Отказоустойчивая доставка любых событий, прием потоковых данных.
Стек: Kafka.
7. Развертывание приложений и виртуализация.
Помогает для быстрого вывода приложений в продуктив, спасибо контейнерам и CI/CD.
Стек: Kubernetes, OpenStack.
8. Сбор и управление логами.
Любые логи, сбор которых вы только сможете настроить.
Стек: Graylog, ElasticSearch.
9. Визуализация данных.
Позволяет рисовать наглядные дашборды, на которых будет выводиться информация, основанная на обработанных данных.
Стек: Qlik Sense.
10. Мониторинг и алертинг.
Собирает сигналы со всех уровней (железо, ОС, платформа, приложения), отправляет уведомления в Slack, Telegram, создает инциденты. Активно развивается в сторону генерации событий также и на основании лого из Graylog.
Стек: Целевой — Victoria Metrics, Grafana, Alerta.io. Legacy — Zabbix, Remedy.
Общая схема платформы
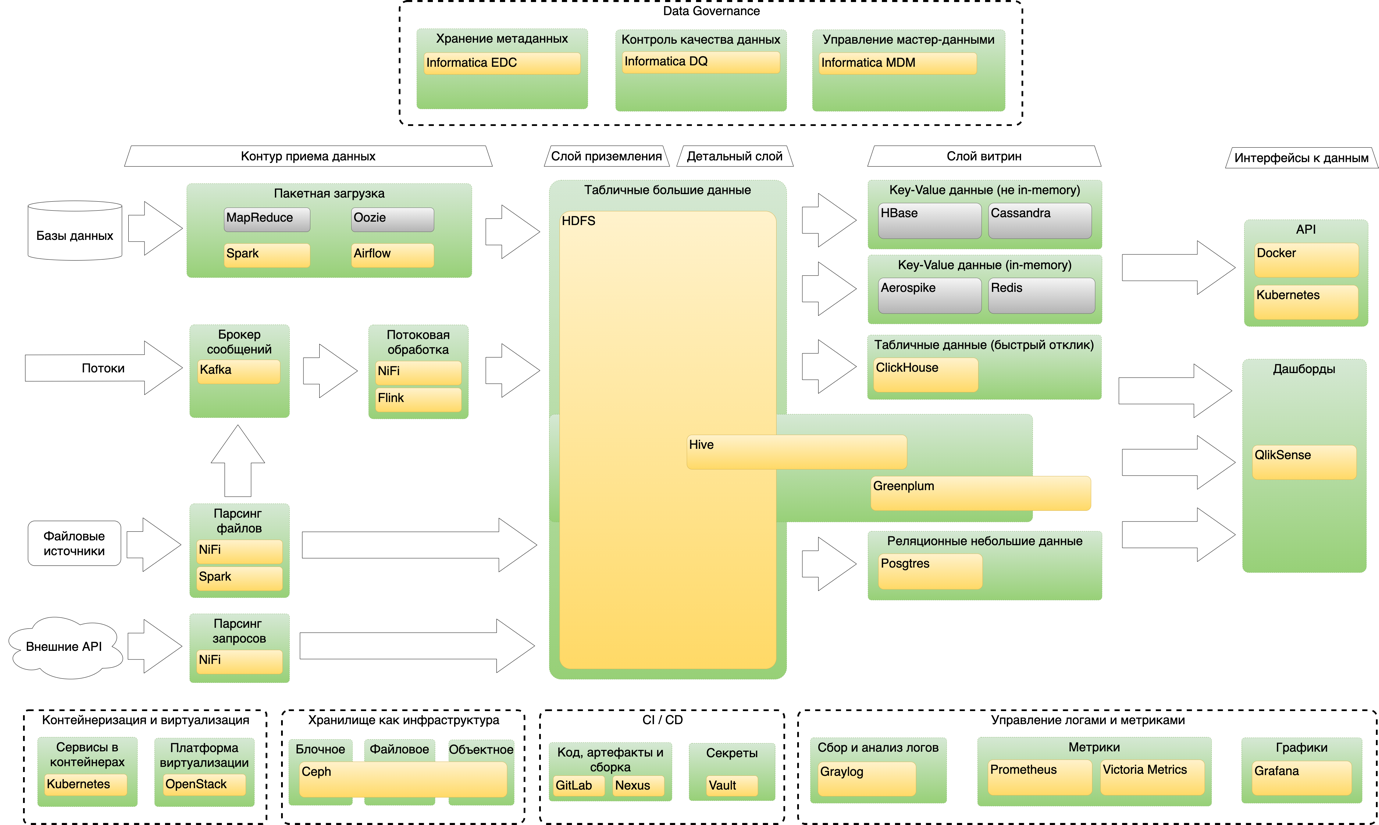
Характеристики платформы
Сегодня платформа — это чуть более 1 000 серверов, из них порядка 450 используется для Hadoop. Остальное используется под различные стенды, от Kafka, NiFi и Kubernetes до различных тестовых сред. В основном кластере Hadoop сейчас находится примерно 14 петабайт данных. Ежедневная аудитория пользователей — около 500. Количество активно работающих команд — около 20, количество продуктов — около 50.
Пользователи — все подразделения компании.
На этом завершается краткий обзор платформы, и далее пойдет описание первой из возможностей — оркестрация обработки данных на базе AirFlow.
Оркестрация обработки данных в AirFlow
В 2020 году параллельно с продолжением использования Oozie мы начали тестировать и внедрять для оркестрации задач Airflow. По сравнению с Oozie он более активно развивается, не привязан исключительно к Hadoop, имеет более наглядный интерфейс и имеет больше опций для разработчика. Не буду здесь углубляться в сравнение, так как эта тема раскрыта в открытых источниках. Достаточно даже просто посмотреть параметры проектов на GitHub. Хочется рассказать о том, как это сделано у нас.
1. Используем для запуска только Kubernetes.
Продуктовые команды разделены по namespaces, выполнение каждого оператора происходит в отдельно поднимаемом поде неймспейса продукта. Этим достигается изоляция команд друг от друга, а также разграничиваются права доступа к административным возможностям AirFlow. Тимлиды команд имеют полные права на инстансе своей команды и несут ответственность за его работоспособность.
2. Все секреты хранятся в Vault.
Команда не использует учетные записи и пароли напрямую, они запрашиваются только из Vault. А в самом Vault используется Kubernetes-аутентификация. Так мы исключаем hard-code паролей внутри приложений и DAG-ов AirFlow.
3. Все логи приложений в Kubernetes (и AirFlow не исключение) просматриваются через GrayLog.
Таким образом, каждый разработчик через redirect с front-end получает доступ к нужным логам для отладки DAG-ов.
4. Метрики scheduler-а из statsd забираются Prometheus, поверх них строится алертинг и визуализация в Grafana.
Таким образом, аналогично логам, каждая команда работает через web-интерфейс с метриками своего AirFlow по одному адресу.
5. DAG-и для каждой продуктовой команды хранятся в GitLab и оттуда через CI/CD доставляются на продуктивный контур.
Это один из основных принципов нашей работы — автоматизировать все что можно, в данном случае команде достаточно сделать merge в продуктивную ветку, после чего автоматизировано код DAG доезжает до прода.
6. Для работы каждого инстанса AirFlow используется Postgres с автоматическим failover, который также запускается на Kubernetes.
Это в какой-то степени вынужденная мера, так как администрировать из центра столько отдельных AirFlow с их базами данных было бы очень тяжело. Поэтому при создании каждого экземпляра — сразу предусматривается отказоустойчивость для базы данных, которая его обслуживает.
Cхема развертывания AirFlow для продуктовой команды

В заключение добавлю, что заказ своего экземпляра AirFlow для продуктовой команды осуществляется через одну общую заявку на создание ландшафта, в результате выполнения которой автоматизировано настраиваются все перечисленные выше возможности.
