Планировщик Go
Язык программирования Go был разработан для высокопроизводительных многопоточных приложений, и его система планирования горутин играет ключевую роль в эффективном использовании аппаратных ресурсов. В отличие от традиционных потоков ОС, горутины легче, создаются быстрее и управляются встроенным планировщиком Go, который распределяет задачи между доступными процессорами.
В этом тексте я рассмотрю, как Go-программа использует вычислительные мощности, как работает планировщик горутин и какие механизмы обеспечивают эффективное выполнение кода. Мы разберем принципы распределения задач, взаимодействие горутин с потоками ОС, а также механизмы синхронизации и асинхронного ввода-вывода. Это поможет лучше понять, как Go обеспечивает высокую производительность при работе с конкурентными процессами.
Запуск программы
Когда Go-приложение запускается, оно получает логические процессоры (P) в количестве, равном числу виртуальных ядер, доступных на машине. Если процессор поддерживает многопоточность (Hyper-Threading), каждое аппаратное ядро будет представляться в Go как виртуальное ядро.
Чтобы лучше понять это, я посмотрел системные характеристики своего MacBook Air.

Можно увидеть, что у меня MacBook Air с одним процессором и восемью физическими ядрами. Процессор Apple M1/M2 использует архитектуру с энергоэффективными и производительными ядрами, но для Go-программы он представляется как 8 виртуальных ядер, доступных для параллельного выполнения потоков ОС.
Чтобы проверить это, можно запустить следующий код:
package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU возвращает количество логических
//процессоров, используемых текущим процессом.
fmt.Println(runtime.NumCPU())
}Когда я запускаю этот код на своей системе, функция NumCPU () возвращает значение 8. Это означает, что любая Go-программа, запущенная на моем компьютере, будет иметь 8 логических процессоров (P). Каждый P управляет ОС-потоком (M, Machine), который контролируется операционной системой. ОС отвечает за размещение потока на физическом ядре.
Каждая Go-программа также получает первую Goroutine (G) — поток выполнения программы. Goroutine по сути является корутиной, но в Go используется именно этот термин. Goroutines можно сравнить с потоками ОС, но они легче и управляются Go-планировщиком. Так же, как ОС переключает потоки (M) между ядрами, Go-планировщик переключает Goroutines между потоками M.
Последним элементом пазла являются очереди выполнения (run queues). В планировщике Go есть два типа очередей: глобальная очередь выполнения (Global Run Queue, GRQ) и локальная очередь выполнения (Local Run Queue, LRQ).
Каждый P получает свою LRQ, которая управляет Goroutines, назначенными для выполнения в контексте данного P. Эти Goroutines по очереди переключаются на M, закрепленный за этим P.
GRQ используется для Goroutines, которые еще не были назначены какому-либо P. Существует процесс перемещения Goroutines из GRQ в LRQ, который мы рассмотрим позже.
На Рис. 1 представлено изображение всех этих компонентов вместе.

Кооперативный планировщик
Планировщик ОС является вытесняющим, поэтому в любой момент времени невозможно предсказать, какое решение он примет. Ядро управляет процессами, и всё происходит недетерминированно. Приложения, работающие поверх ОС, не могут контролировать процесс планирования внутри ядра, если только они не используют примитивы синхронизации, такие как атомарные инструкции и мьютексы.
Планировщик Go является частью Go runtime, который встроен в само приложение. Это означает, что он работает в пространстве пользователя, над ядром операционной системы. В текущей реализации планировщик Go не является вытесняющим, а работает по кооперативному принципу. Это значит, что для принятия решений о планировании ему нужны чётко определённые события в пространстве пользователя, которые происходят в безопасных точках кода.
Гениальность кооперативного планировщика Go в том, что он выглядит и ощущается как вытесняющий. Невозможно предсказать его поведение, так как решения о планировании не принимаются разработчиком, а переданы в Go runtime. Важно воспринимать планировщик Go как вытесняющий, поскольку он ведёт себя недетерминированно, и это не слишком далеко от истины.
Состояние горутин
Как и потоки, горутины имеют три основных состояния, которые определяют роль планировщика Go для каждой горутины. Горутина может находиться в одном из трёх состояний: waiting, runnable или executing.
Waiting: Горутина остановлена и ждёт какого-то события, чтобы продолжить выполнение. Это может быть связано с ожиданием работы с операционной системой (системные вызовы) или синхронизацией (атомарные операции и мьютексы). Такие задержки являются одной из основных причин плохой производительности.
Runnable: Горутина ожидает выделения OS-потока (M) для выполнения своих инструкций. Если в системе много горутин, им приходится дольше ждать своей очереди. С увеличением количества горутин время выполнения каждой из них сокращается, что также может негативно сказаться на производительности.
Executing: Горутина была назначена на OS-поток (M) и выполняет свои инструкции. В этот момент выполняется полезная работа приложения.
Переключение контекста
Планировщик Go требует чётко определённых событий в пользовательском пространстве, которые происходят в безопасных точках кода для выполнения переключений контекста. Эти события и безопасные точки проявляются в вызовах функций. Вызовы функций критически важны для работы планировщика Go. В Go 1.12 было принято изменение, позволяющее планировщику использовать некооперативные техники прерывания, что дало возможность прерывать tight loops.
В Go-программе существует четыре класса событий, которые позволяют планировщику принимать решения о планировании горутин:
Использование ключевого слова go
Сборка мусора
Системные вызовы
Синхронизация и оркестрация
Использование ключевого слова go
Ключевое слово go используется для создания горутин. Когда создаётся новая горутина, это даёт планировщику возможность принять решение о планировании.
Сборка мусора
Поскольку сборка мусора (GC) выполняется с использованием собственных горутин, эти горутины требуют времени на M для выполнения. Это создаёт определённый хаос в плане планирования. Однако планировщик очень умён в понимании того, что делает горутина, и использует это знание для принятия обоснованных решений. Одним из таких решений является переключение контекста горутины, которая работает с кучей, с теми, кто не работает с кучей во время работы GC. Когда происходит сборка мусора, планировщик принимает множество решений о планировании.
Системные вызовы
Если горутина выполняет системный вызов, который вызывает блокировку M, то планировщик может выполнить переключение контекста, переместив горутину с M и переключив на неё новую горутину. Однако, иногда для продолжения выполнения горутин, которые находятся в очереди P, требуется новый M. Как это работает, будет объяснено более подробно в следующем разделе.
Синхронизация и оркестрация
Если операция атомарного, мьютекса или канала вызывает блокировку горутины, планировщик может выполнить переключение контекста и запустить новую горутину. Когда горутина снова может продолжить выполнение, она может быть возвращена в очередь и в конечном итоге снова быть переключена на M.
Асинхронные Системные Вызовы
Когда операционная система, может обрабатывать системные вызовы асинхронно, используется так называемый network poller для более эффективной обработки системных вызовов. Это достигается с помощью таких механизмов, как kqueue (для macOS), epoll (для Linux) или iocp (для Windows), в зависимости от операционной системы.
Сетевые системные вызовы могут обрабатываться асинхронно во многих современных операционных системах. Именно отсюда и происходит название network poller — его основное назначение — обработка сетевых операций. Используя network poller для сетевых системных вызовов, планировщик Go может предотвратить блокировку M, когда эти системные вызовы выполняются. Это помогает сохранить доступность M для выполнения других горутин в LRQ P без необходимости создания новых M. Такой подход снижает нагрузку на планирование в ОС.
Лучший способ увидеть, как это работает, — это рассмотреть пример.

На Рис. 2 показана базовая схема планирования. Goroutine-1 выполняется на M, а еще 3 горутины ожидают своей очереди в LRQ, чтобы получить время на M. Network poller не активен и не выполняет никаких операций.

На Рис. 3 Goroutine-1 хочет выполнить системный вызов для сети, поэтому она перемещается в network poller, и асинхронный сетевой системный вызов обрабатывается. Как только Goroutine-1 перемещается в network poller, M становится доступной для выполнения другой горутины из LRQ. В данном случае Goroutine-2 выполняется с помощью контекстного переключения на M.

На Рис. 4 асинхронный сетевой системный вызов завершён Network Poller, и Goroutine-1 возвращается в локальную очередь выполнения (LRQ) на P. Как только Goroutine-1 может быть снова переведена на M с помощью контекстного переключения, код, связанный с Go, который она должна выполнить, снова выполняется. Главное преимущество здесь заключается в том, что для выполнения сетевых системных вызовов не требуется создавать дополнительные M. Network Poller использует OS-поток и обрабатывает эффективный цикл событий.
Синхронные системные вызовы
Что происходит, когда горутина хочет выполнить системный вызов, который нельзя выполнить асинхронно? В этом случае Network Poller не может быть использован, и горутина, выполняющая системный вызов, заблокирует M. Это неидеально, но избежать этого невозможно.
Примером такого системного вызова, который нельзя выполнить асинхронно, является файловый ввод-вывод. Если вы используете cgo, могут быть и другие случаи, когда вызовы C-функций также блокируют M. В операционной системе Windows есть возможность выполнения файловых системных вызовов асинхронно. Технически, при запуске на Windows, Network Poller может быть использован.
Рассмотрим, что происходит, когда синхронный системный вызов (например, файловый ввод-вывод) блокирует M.

На Риc. 5 показана основная схема планирования, но теперь Горутина-1 будет выполнять синхронный системный вызов, который заблокирует M1.

На рис. 6 планировщик может определить, что горутина G1 заблокировала M. На этом этапе планировщик отсоединяет M1 от P, поскольку G1 заблокирована. Затем планировщик создаёт новый M2, чтобы продолжить выполнение P. В этот момент горутина G2 может быть выбрана из LRQ и переключена на M2. Если свободный M уже существует после предыдущей замены, переключение происходит быстрее, чем создание нового M.
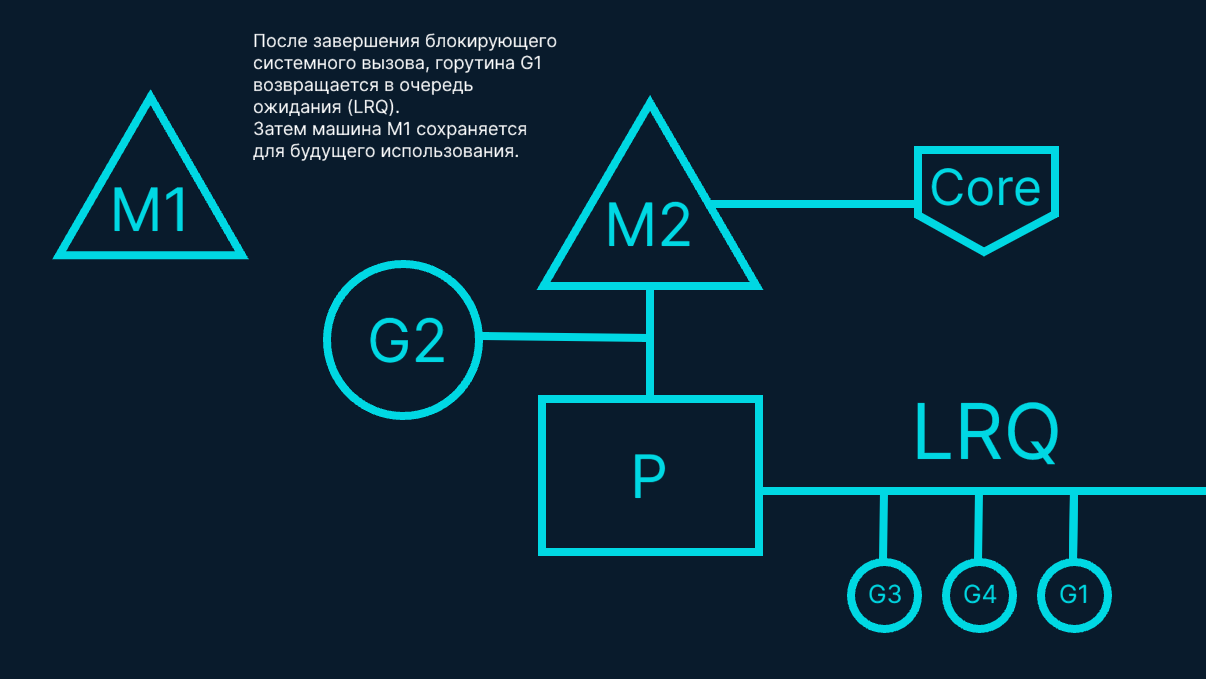
На рис. 7 блокирующий системный вызов, выполненный Goroutine-1, завершается. На этом этапе Goroutine-1 может вернуться в LRQ (локальную очередь готовых горутин) и быть снова обработанным процессором P. В случае повторения этой ситуации M1 откладывается на будущее.
Кража работы (Work Stealing)
Еще одной особенностью планировщика является механизм кражи работы. Это помогает в нескольких аспектах поддержания эффективности планирования. Во-первых, крайне нежелательно переводить M в состояние ожидания, поскольку в этом случае операционная система будет вынуждена переместить M с ядра. Это означает, что P не сможет выполнять работу, даже если в состоянии выполнения находится Goroutine, пока M снова не вернется на ядро. Кража работы также способствует балансировке Goroutines по всем P, что помогает более равномерно распределять нагрузку и повышает эффективность работы.
Давайте рассмотрим пример.

«На рис. 9 показана многопоточная Go-программа с двумя P, обслуживающими по четыре Goroutine каждый, и одной Goroutine в GRQ. Что произойдет, если один из P быстро выполнит все свои Goroutine?»

На рис. 10 у P1 больше нет Goroutines для выполнения. Однако есть готовые Goroutines как в LRQ для P2, так и в GRQ. В этот момент P1 необходимо украсть работу. Правила кражи работы следующие.
runtime.schedule() {
// Только 1/61 времени проверяй глобальную очередь готовых Goroutines (GRQ).
// Если не найдено, проверь локальную очередь (LRQ).
// Если не найдено,
// попробуй украсть работу у других P.
// Если не получилось, снова проверь глобальную очередь.
// Если не найдено, поллинг сети.
}
На основе правил, приведённых выше, P1 должно проверить LRQ P2 на наличие доступных Goroutines и забрать половину из найденных.

На рис. 10 показано, как половина Goroutines забирается у P2, и теперь P1 может их выполнить. Что произойдет, если P2 завершает выполнение всех своих Goroutines, а у P1 в LRQ больше нет задач?»

На рис. 11 показано, что P2 завершила всю свою работу, и теперь ей нужно забрать немного работы. Сначала она проверит LRQ у P1, но не найдет там Goroutines. Затем она проверит GRQ, где обнаружит Goroutine-9.

На рис. 12 показано, как P2 крадет Goroutine-9 из GRQ и начинает выполнять работу. Преимущество работы с использованием кражи работы (work-stealing) заключается в том, что это позволяет M оставаться занятыми и не переходить в неактивное состояние. Этот процесс работы с кражей работы рассматривается внутри как 'вращение' M. Вращение имеет дополнительные преимущества, которые Дж.Б.Д. хорошо объясняет в своем блоге о work-stealing.
Пример
С учетом механики и семантики рассмотрим, как всё это работает вместе, чтобы позволить планировщику Go выполнять больше работы со временем. Представим многопоточное приложение, написанное на C, где программа управляет двумя потоками ОС, которые обмениваются сообщениями.»

На рис. 13 показано, как два потока обмениваются сообщениями. Поток 1 переключается на ядро 1 и начинает выполнение, что позволяет ему отправить сообщение потоку 2. Как именно передается сообщение, не имеет значения. Важно лишь состояние потоков на протяжении этой оркестрации.

На рис. 14 показано, что как только Поток 1 завершает отправку сообщения, он должен ожидать ответа. Это приведет к тому, что Поток 1 будет переключен с Ядра 1 и переведен в состояние ожидания. Как только Поток 2 получит уведомление о сообщении, он переходит в состояние готовности. Операционная система может выполнить переключение контекста и запустить Поток 2 на Ядре 2. Далее Поток 2 обрабатывает сообщение и отправляет новое сообщение обратно Потоку 1.

«На рис. 15 показано, как Потоки снова переключаются при контексте, когда Поток 1 получает сообщение от Потока 2. Теперь Поток 2 переключается с состояния выполнения в состояние ожидания, а Поток 1 — с состояния ожидания в состояние готовности и, наконец, обратно в состояние выполнения, что позволяет ему обработать и отправить новое сообщение обратно.
Все эти переключения контекста и изменения состояний требуют времени, что ограничивает скорость выполнения работы. Каждое переключение контекста может приводить к задержке около 1000 наносекунд, и если оборудование выполняет 12 инструкций на наносекунду, это означает, что в среднем не выполняется около 12 000 инструкций в процессе переключений контекста. Поскольку эти Потоки также переключаются между различными Ядрами, вероятность возникновения дополнительной задержки из-за промахов в кэш-линии также велика.
Теперь давайте рассмотрим тот же пример, но с использованием Горутин и планировщика Go.»
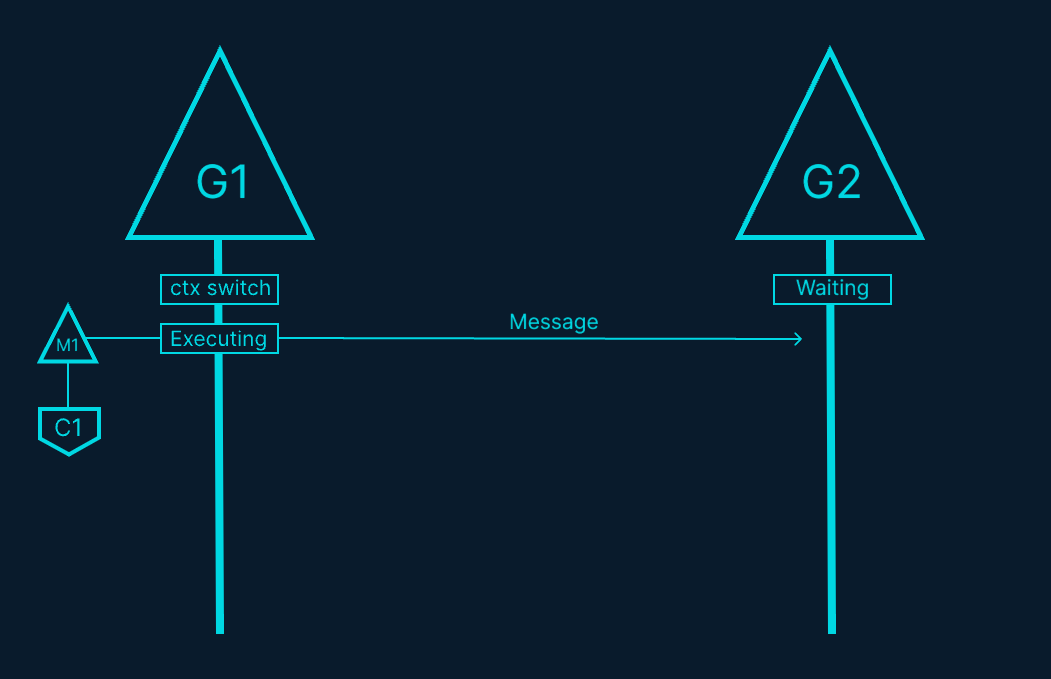
На рис. 16 показано, как две Горутины работают в оркестрации, передавая сообщение туда и обратно. G1 переключается на M1, который работает на Ядре 1, что позволяет G1 выполнять свою работу. Эта работа заключается в том, чтобы G1 отправить свое сообщение G2.

На рис. 17 показано, что как только G1 завершает отправку сообщения, ей нужно подождать ответ. Это приведет к переключению G1 с M1 и переводу ее в состояние ожидания. Как только G2 получает уведомление о сообщении, она переходит в состояние готовности. Теперь планировщик Go может выполнить переключение контекста и запустить G2 на M1, который все еще работает на Ядре 1. Затем G2 обрабатывает сообщение и отправляет новое сообщение обратно в G1.

На рис. 18 показано очередное переключение контекста, когда сообщение, отправленное G2, принимается G1. Теперь G2 переключается из состояния выполнения в состояние ожидания, а G1 — из состояния ожидания в состояние готовности, а затем обратно в состояние выполнения, что позволяет G1 обработать и отправить новое сообщение обратно.
На первый взгляд все выглядит не так уж и по-разному. Те же самые переключения контекста и изменения состояний происходят как при использовании потоков, так и при использовании горутин. Однако существует принципиальная разница между использованием потоков и горутин, которая может быть неочевидной на первый взгляд.
В случае с горутинами тот же самый ОС-поток и ядро используются для всей обработки. Это означает, что с точки зрения ОС поток никогда не переходит в состояние ожидания — ни разу. В результате все те инструкции, которые мы теряли из-за переключений контекста при использовании потоков, не теряются при использовании горутин.
По сути, Go превращает работу с IO и блокирующими вызовами в работу с процессором на уровне ОС. Поскольку все переключения контекста происходят на уровне приложения, мы не теряем те же ~12 тыс. инструкций (в среднем) на каждом переключении контекста, как это было с потоками. В Go те же самые переключения контекста стоят вам ~200 наносекунд или ~2,4 тыс. инструкций. Планировщик также помогает повысить эффективность работы с кэшами и NUMA. Именно поэтому нам не нужно больше потоков, чем виртуальных ядер. В Go можно выполнить больше работы со временем, потому что планировщик Go пытается использовать меньше потоков и выполнять больше работы на каждом потоке, что помогает снизить нагрузку на ОС и оборудование.
Заключение
Планировщик Go впечатляет своим продуманным дизайном, который учитывает особенности работы операционной системы и аппаратного обеспечения. Использование модели M: N позволяет эффективно управлять горутинами, перераспределяя их между потоками ОС в зависимости от нагрузки. Это дает значительное преимущество при работе с IO и блокирующими операциями, превращая их в управляемые вычислительные задачи на уровне планировщика.
Благодаря этой архитектуре в большинстве случаев нет необходимости создавать больше потоков ОС, чем виртуальных ядер. Это позволяет эффективно выполнять как процессоро-зависимые, так и IO-ориентированные задачи, минимизируя накладные расходы. Однако при наличии системных вызовов, которые блокируют потоки ОС, Go может динамически создавать дополнительные потоки, чтобы избежать блокировки выполнения других горутин.
