Пишем и тестируем миграции БД с Alembic. Доклад Яндекса
Приложения на бэкенде могут работать с самыми разными базами данных: PostgreSQL, SQLite, MariaDB и другими. Перед разработчиками встает задача реализовать возможность легко и безопасно изменять состояние БД. Менять нужно как структуру базы, так и сами данные от одной версии приложения к другой.
В докладе я поделился опытом использования Alembic — хорошо себя зарекомендовавшего инструмента для управления миграциями. Почему стоит выбрать именно Alembic, как с его помощью подготовить миграции, как их запускать (автоматически или вручную), как решить проблемы необратимых изменений, зачем тестировать миграции, какие проблемы могут выявить тесты и как их реализовать — на все эти вопросы я постарался ответить. Заодно поделился несколькими лайфхаками, которые сделают работу с миграциями в Alembic легкой и приятной.
Со дня доклада код на GitHub немного обновился, примеров стало больше. Если вы хотите посмотреть код именно в том виде, в котором он представлен на слайдах, вот ссылка на коммит того времени.
— Всем привет! Меня зовут Александр, я работаю в Едадиле. Сегодня я хочу рассказать, как мы живем с миграциями и как вы могли бы с ними жить. Возможно, это поможет вам жить легче.
Прежде чем мы начнем, стоит поговорить о том, что такое миграции в принципе. Например, у вас есть приложение и вы создаете пару табличек, чтобы оно работало, ходило в них. Потом выкатываете новую версию, в которой что-то поменялось, — первая табличка поменялась, вторая нет, а третьей раньше не было, но она появилась.

Потом появляется новая версия приложения, в которой какая-то табличка удаляется, с остальными ничего не происходит. Что это такое? Можно сказать, что это и есть состояние, которое можно описать миграцией. Когда мы переходим от одного состояния к другому, это upgrade, когда хотим вернуться назад — downgrade.
Что же такое миграции?

С одной стороны, это код, который меняет состояние базы данных. С другой, это процесс, который мы запускаем.

Какими свойствами должны обладать миграции? Важно, чтобы состояния, между которыми мы переключались в версиях приложения, были атомарными. Если, например, мы хотим, чтобы у нас появилось две таблицы, а появится только одна, это может привести к не очень хорошим последствиям на продакшене.
Важно, чтобы мы могли откатить наши изменения, потому что если вы выкатываете новую версию, она не взлетает и вы не можете откатиться, все обычно заканчивается плохо.
Также важно, чтобы версии были упорядочены, чтобы вы могли построить цепочку по тому, как они накатывались.
Как мы можем эти миграции реализовать?

Первая идея, которая приходит в голову: окей, миграция — это SQL, почему бы не взять и не сделать SQL-файлы с запросами. Есть еще несколько модулей, которые способны облегчить нам жизнь.

Если мы рассмотрим, что происходит внутри, то действительно, есть пара запросов. Это может быть CREATE TABLE, ALTER, что-нибудь еще. В файле downgrade_v1.sql мы это все отменяем.

Почему так делать не стоит? В первую очередь потому, что вам нужно это делать руками. Не забыть написать begin, потом закоммитить свои изменения. Когда вы будете писать код, вам нужно будет помнить все зависимости и что в каком порядке нужно делать. Это достаточно рутинная, сложная и долгая работа.
У вас нет никакой защиты от того, чтобы случайно не запустить какой-нибудь не тот файл. Нужно запускать все файлы руками. Если у вас 15 миграций, это непросто. Нужно будет 15 раз позвать какой-нибудь psql, это будет не очень круто.
Самое важное: вы никогда не знаете, в каком состоянии находится ваша БД. Вам нужно где-то записывать — на листочке, где-нибудь еще, — какие файлы вы накатили, а какие нет. Это тоже звучит как-то не очень.

Есть модуль yoyo-migrations. Он поддерживает самые распространенные базы данных и использует сырые запросы.

Если мы посмотрим, что он нам предлагает, это выглядит так. Мы видим тот же самый SQL. Справа уже появился Python-код, который импортирует библиотеку yoyo.

Таким образом мы уже можем запускать миграции, именно автоматически. Другими словами, есть команда, которая создает и добавляет в цепочку новую миграцию, куда мы можем написать наш SQL-код. С помощью команд можно применить одну или несколько миграций, можно откатить, это уже шаг вперед.

Плюс в том, что вам уже не нужно писать на листочке, какие у вас запросы были выполнены на базе, какие файлы вы запускали и куда нужно откатываться в случае чего. У вас есть какая-то защита от дурака: вы уже не сможете запустить миграцию, которая рассчитана на другое, на переход между двумя другими состояниями базы данных. Очень большой плюс: эта штука делает каждую миграцию в отдельной транзакции. Это тоже дает такие гарантии.

Недостатки налицо. У вас опять же остался сырой SQL. Если, например, у вас есть большой дата-продакшен с развесистой логикой на Python, вы не сможете ее использовать, потому что у вас есть только SQL.
Также вас ждет очень много рутинной работы, которую невозможно автоматизировать. Надо отслеживать все связи между таблицами — что можно писать куда-то, а что пока еще нельзя. В общем, есть вполне очевидные недостатки.
Еще один модуль, на который стоит обратить внимание и ради которого сегодня весь доклад, — это Alembic.

В нем есть то же самое, что и в yoyo, а также еще очень много всего. Он не только следит за вашими миграциями и умеет их создавать, но и позволяет писать очень сложную бизнес-логику, подключать весь ваш дата-продакшен, любые функции на Python. Вытаскивать данные и обрабатывать их внутри, если вы хотите. Если не хотите — можете этого не делать.
Он умеет писать за вас код автоматически в большинстве случаев. Не всегда, конечно, но звучит как хороший плюс после того, как вам нужно было многое писать руками.
У него есть очень много крутых штук. Например, SQLite не полностью поддерживает ALTER TABLE. А у Alembic есть функциональность, которая позволяет это в пару строчек спокойно обойти, и вы даже об этом не будете задумываться.
На предыдущих слайдах был модуль Django-migrations. Это тоже очень хороший модуль для миграций. Его принцип сопоставим с Alembic по функциональности. Единственная разница: он привязан к фреймворку, а Alembic не привязан.
Так как Alembic базируется на SQLAlchemy, я предлагаю немножко пробежаться по SQLAlchemy, чтобы вспомнить или узнать, что это такое.

До сих пор мы смотрели на сырые запросы. Сырые запросы — это неплохо. Это бывает очень даже хорошо. Когда у вас высоконагруженное приложение, может быть, это именно то, что вам нужно. Не нужно тратить время на превращение каких-то объектов в какие-то запросы.
Никаких дополнительных библиотек не требуется. Просто берете драйвер, и все, оно работает. Но например, если вы пишете сложные запросы, это будет уже не так просто: хорошо, вы можете взять константу, вынести вверх, написать большой многострочный код. Но если у вас будет 10–20 таких запросов, это уже будет очень сложно читаться. Потом вы не сможете никак их переиспользовать. У вас есть большой кусок текста и, конечно, функции для работы со строками, f-string и всякое такое, но это уже звучит не очень хорошо. Их сложно читать.
Если, например, у вас есть класс, внутри которого вы тоже хотите иметь запросы и сложные структуры, отступы будут дикой болью. Если вы захотите сделать миграцию с сырыми запросами, то единственный способ найти, где у вас что-то используется, — это grep. И динамического инструмента для динамических запросов у вас тоже нет.
Например, суперпростая задача. У вас есть сущность, у нее 15 полей в одной табличке. Вы хотите сделать PATCH-запрос. Это, казалось бы, суперпросто. Попробуйте это написать на сырых запросах. Это будет выглядеть не очень красиво, и пул-реквест вам вряд ли заапрувят.

Этому есть альтернатива — Query builder. Безусловно, у него есть недостатки, потому что он позволяет представить ваши запросы в виде объектов на Python.
За удобство придется заплатить и временем на генерацию запросов, и памятью. Но есть плюсы. Когда вы пишете большие сложные приложения, вам требуются абстракции. Как раз Query builder может эти абстракции вам дать. Эти запросы можно декомпозировать, мы чуть позже увидим, как это делается. Их можно переиспользовать, расширять, оборачивать в функции, которые будут уже называться понятными именами, связанными с бизнес-логикой.
Очень легко строить динамические запросы. Если вам нужно что-то поменять, написать миграцию, достаточно статистического анализа кода. Это очень удобно.
Почему же все-таки SQLAlchemy? Почему на ней стоит остановиться?

Это вопрос даже не только про миграции, а в целом. Потому что когда у нас появляется Alembic, разумно использовать весь cтек сразу, потому что SQLAlchemy работает не только с синхронными драйверами. То есть Django — очень крутой инструмент, но Alchemy можно использовать, например, с asyncpg и aiopg. Asyncpg позволяет вычитывать, как Селиванов рассказывал, миллион строк в секунду — читать из базы и передавать в Python. Конечно, с SQLAlchemy будет чуть меньше, будут какие-то накладные расходы. Но все-таки.
В SQLAlchemy просто невероятное количество драйверов, с которыми она умеет работать. Есть и Oracle, и PostgreSQL, и просто всё на любой вкус и цвет. Причем они есть уже из коробки, а если вам нужно что-то отдельное, то там, я недавно смотрел, есть даже Elasticsearch. Правда, только на чтение, но — понимаете? — Elasticsearch в SQLAlchemy.
Там очень хорошая документация, большое сообщество. Очень много библиотек. И что важно, все-таки он не диктует вам фреймворки и библиотеки. Когда вы делаете узкую задачу, которую нужно решить хорошо, это может быть инструментом.
Итак, из чего она состоит?
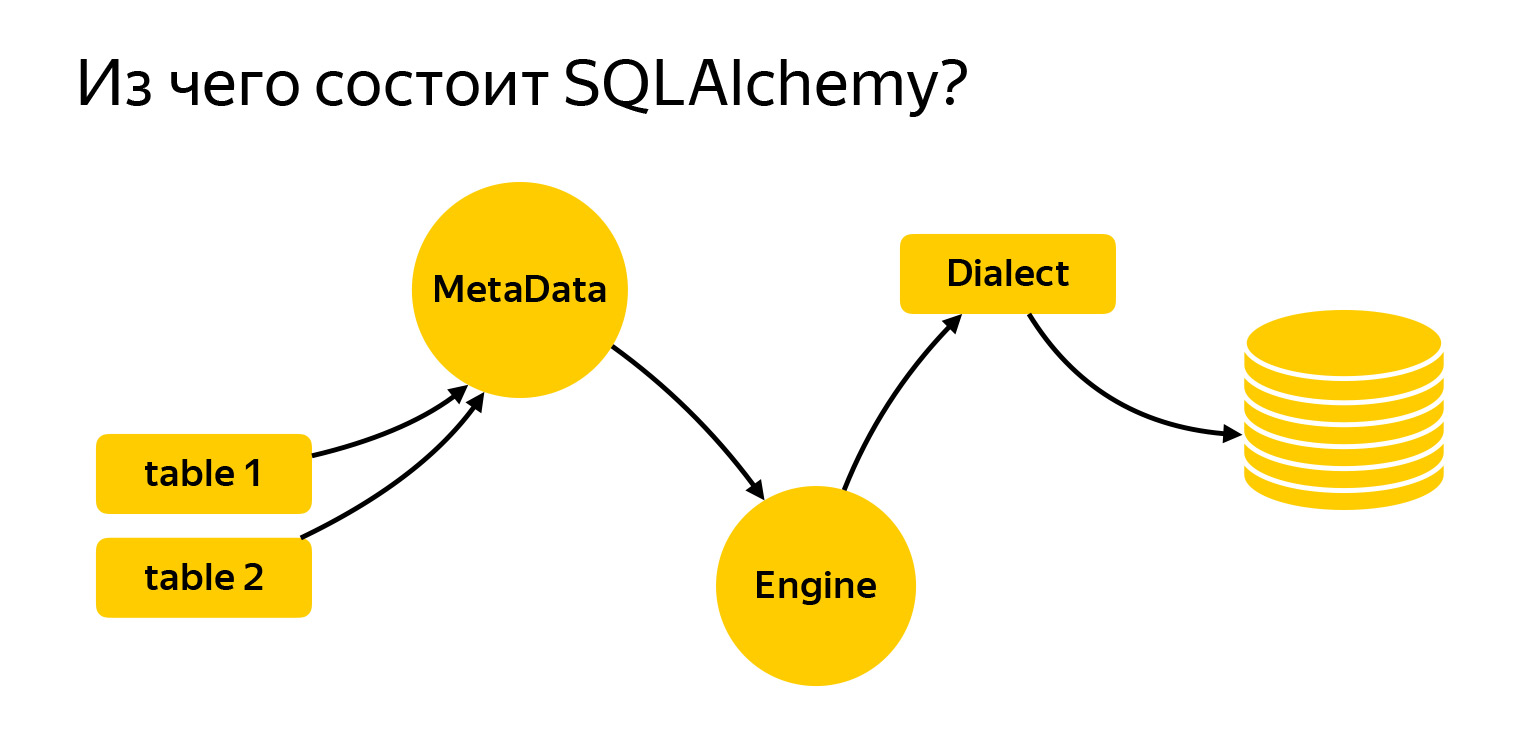
Я сюда вынес основные сущности, с которыми мы будем сегодня работать. Это таблицы. Чтобы писать запросы, в Alchemy нужно рассказать, что это такое, с чем мы работаем. Дальше есть реестр MetaData. Engine — такая штука, которая подключается уже к базе и с ней общается посредством Dialect.
Рассмотрим подробнее, что же это такое.

MetaData — некий объект, контейнер, в который вы будете добавлять ваши таблицы, индексы и вообще все сущности, которые у вас есть. Это такой объект, который отражает, с одной стороны, то, как вы хотите видеть базу данных, исходя из вашего написанного кода. С другой стороны, MetaData может пойти в базу, получить snapshot того, что там реально есть, и сам построить эту объектную модель.
Также у объекта MetaData есть одна очень интересная особенность. Он позволяет вам задать шаблон наименования индексов и constraint«ов по умолчанию. Это очень важно, когда вы пишите миграции, потому что у каждой БД — будь то PostgreSQL, MySQL, MariaDB — есть какое-то свое видение того, как должны называться индексы.
У некоторых разработчиков тоже есть свое видение. И SQLAlchemy позволяет вам раз и навсегда задать стандарт, как это будет работать. Мне приходилось разрабатывать проект, который должен был работать и с SQLite, и с PostgreSQL. Это было очень удобно.

Выглядит это следующим образом: вы импортируете объект MetaData из SQLAlchemy и при его создании указываете шаблоны с помощью параметра naming_convention, ключами которого указываете типы индексов и constraint’ов: ix — обычный индекс, uq — уникальный индекс, fk — foreign-ключ, pk — primary-ключ.
В значениях параметра naming_convention можно указать шаблон, который состоит из типа индекса/constraint (ix/uq/fk и др.) и названия таблицы, разделенных подчеркиваниями. В каких-то шаблонах можно перечислить еще и все столбцы. Например, для primary-ключа этого делать не обязательно, можно указать просто название таблицы.
Когда вы начинаете делать новый проект, то один раз добавляете в него шаблоны наименований и забываете. С тех пор все миграции у вас генерируются с одинаковыми названиями индексов и constraint’ов.
Это важно и по другой причине: когда вы решите, что в вашей объектной модели этот индекс больше не нужен и удалите его, то Alembic будет знать, как он называется, и правильно сгенерирует миграцию. Это уже некий залог надежности, что все будет работать, как должно.
Другая очень важная сущность, с которой вы обязательно столкнетесь, — это таблица, объект, который описывает, что таблица содержит.

У таблицы есть название, столбцы с типами данных, и она обязательно ссылается на реестр MetaData, так как MetaData — это реестр всего, что вы описываете. И есть столбцы с типами данных.
Благодаря тому, что мы описали, SQLAlchemy теперь очень многое может и знает. Если бы мы здесь указали foreign-ключ, она бы еще знала, как у нас таблицы друг с другом соединяются. И знала бы порядок, в котором что-то нужно делать.

Еще у SQLAlchemy стоит отметить Engine. Важно: то, что мы говорили про запросы, можно использовать отдельно, и Engine можно использовать отдельно. А можно использовать всё вместе, никто не запрещает. То есть Engine умеет подключиться уже непосредственно к серверу, и дает вам абсолютно одинаковый интерфейс. Нет, конечно, разные драйверы стараются соблюдать DBAPI, есть такой PEP в Python, который дает рекомендации. Но Engine дает вам абсолютно одинаковый интерфейс для всех БД, и это очень удобно.

Последняя важная веха — Dialect. Это то, как Engine общается уже с разными БД. Здесь как разные языки, разные люди, так и разные Dialect.
Давайте посмотрим, ради чего все это.

Так будет выглядеть обычный Insert. Если мы захотим добавить новую строчку, табличку, которую мы раньше описывали, в которой было поле ID и email, здесь мы указываем email, делаем Insert, и сразу получаем обратно все, что у нас заинсертилось.
Что если мы хотим добавить много строчек? Никаких проблем.

Можно просто передать сюда список диктов. Выглядит как идеальный код для какой-нибудь суперпростой ручки. Данные пришли, прошли какую-нибудь валидацию, какие-нибудь JSON-схемы, и все, попали в базу. Суперлегко.
Некоторые запросы достаточно сложные. Иногда запрос можно посмотреть даже принтом, иногда приходится его компилировать. Это несложно. Alchemy все это позволяет делать. В данном случае мы скомпилировали запрос, и можно посмотреть, что реально улетит в базу.

Запрос на получение данных выглядит совсем просто. Буквально две строчки, можно даже в одну написать.

Вернемся к нашему вопросу о том, как, например, написать PATCH-запрос на 15 полей. Здесь вам стоит написать только название поля, его ключик и значение. Это все, что необходимо. Никаких файлов, построения строк, вообще ничего. Звучит удобно.
Пожалуй, самая важная особенность Alchemy, которую я в своей работе использую каждый день, — это декомпозиция и расширение запросов.

Предположим, вы пишете интерфейс в PostgreSQL, ваше приложение должно как-то авторизовать человека и дать ему возможность выполнять CRUD. Окей, декомпозировать там особо нечего.
Когда вы пишете очень сложное приложение, которое использует версионирование данных, кучу разных абстракций, то запросы, которые у вас будут генерироваться, могут состоять из огромного количества подзапросов. Подзапросы джойнятся с подзапросами. Бывают разные задачи. И иногда декомпозиция запросов очень сильно помогает, позволяет здорово разделить логику и оформить код.
Почему это работает так? Когда вы, например, вызываете метод users_table.select (), он возвращает объект. Когда вы вызываете у полученного объекта еще какой-нибудь метод, например where (), он возвращает абсолютно новый объект. Все объекты запросов иммутабельные. Поэтому вы можете сверху надстраивать все что угодно.
Итак, мы разобрались с SQLAlchemy и теперь наконец можем написать Alembic-миграции.

Начать использовать Alembic совсем не сложно, особенно если вы уже описали свои таблички, как мы говорили раньше, и указали объект MetaData. Вы просто делаете pip install alembic, вызываете alembic init alembic. alembic — название модуля, это command-line, у вас поставится. init — команда. Последний аргумент — папка, в которую он поставится.
Когда вы вызовите эту команду, у вас появится несколько файлов, которые мы сейчас рассмотрим подробнее.

В alembic.ini будет общая конфигурация. script_location — как раз тот аргумент, куда вы хотели бы, чтобы он поставился. Дальше будет шаблон названий ваших миграций, которые вы будете генерировать, и информация для подключения к базе.

Есть также шаблон для новых миграций. Вы скажете: «Хочу новую миграцию», — и Alembic создаст ее по определенному шаблону. Вы можете все это настраивать, это очень просто. Вы заходите в этот файл и редактируете все что вам нужно. Все переменные, которые здесь можно указать, есть в документации. Это его первая часть. Сверху здесь есть какой-то комментарий, чтобы было удобно посмотреть, что там происходит. Дальше есть набор переменных, которые должны быть в каждой миграции, — revision, down_revision. Мы еще сегодня с ними поработаем. Дальше — дополнительная мета-информация.

Самые важные методы — это upgrade и downgrade. Alembic сюда подставит ту разницу, которую объект MetaData найдет между вашим описанием схемы и тем, что есть в базе данных.

env.py — самый интересный файл в Alembic. Он контролирует ход выполнения команд и позволяет кастомизировать его под себя. Именно в этот файл вы подключаете ваш объект MetaData. Как я уже рассказывал, объект MetaData является реестром для всех сущностей вашей базы.
Вы подключаете этот объект MetaData сюда. И именно с этих пор Alembic понимает, что вот они, мои модельки, вот они, мои таблички. Он понимает, с чем он работает. Дальше у Alembic есть код, который вызывает Alembic либо в офлайн-, либо в онлайн-режиме. Мы сейчас тоже все это рассмотрим.
Это именно та строчка, куда необходимо подключать MetaData в вашем проекте. Вы не переживайте, если что-то будет не очень понятно, я собрал все в проект и выложил на GitHub. Его можно склонировать и посмотреть, пощупать все это.

Что такое онлайн-режим? В онлайн-режиме Alembic подключается к базе данных, указанной в параметре sqlalchemy.url в файле alembic.ini, и начинает прогонять миграции.
Зачем мы вообще смотрим на этот кусок кода? Alembic можно настроить под себя очень гибко.
Представьте, что у вас есть приложение, которое должно жить в разных схемах базы данных. Например, вы хотите, чтобы сразу работало очень много инстансов приложения, и каждый жил в своей схеме. Это бывает удобно и необходимо.
Вам это вообще ничего не стоит сделать. После вызова метода context.begin_transaction () вы можете написать команду «SET search_path = SCHEMA», которая укажет PostgreSQL использовать другую схему по умолчанию. И все. С этих пор ваше приложение живет в абсолютно другой схеме, миграции накатываются в другую схему. Это вопрос одной строчки.

Также есть офлайн-режим. Стоит обратить внимание, что Alembic здесь не использует Engine. Ему сюда можно просто передать ссылку. Можно, конечно, передать и Engine, но он никуда не подключается. Он просто генерирует сырые запросы, которые вы потом уже можете где-то выполнить.

Итак, у вас стоит Alembic и какая-то MetaData с табличками. И вы наконец хотите сгенерировать себе миграции. Вы выполняете эту команду, и в принципе на этом все. Alembic сходит в базу данных, посмотрит, что там есть. Есть ли там его специальная табличка «alembic_versions», которая скажет, что в этой базе уже накатывались миграции? Посмотрит, какие таблицы там существуют. Посмотрит, какие данные вам нужны в базе. Все это проанализирует, сгенерирует новый файл, как раз на основе этого шаблона, и у вас появится миграция. Конечно, стоит обязательно смотреть, что в миграции нагенерировалось, потому что Alembic не всегда генерирует то, что вы хотите. Но в большинстве случаев это работает.

Что у нас сгенерировалось? Была табличка users. Когда мы генерировали миграцию, я указал сообщение Initial. Миграция будет называться initial.py с каким-то еще шаблоном, который был указан до этого в alembic.ini.
Также здесь есть информация о том, какой ID у этой миграции. down_revision = None — это первая миграция.
На следующем слайде будет самая важная часть: upgrade и downgrade.

В upgrade мы видим, что у нас создается табличка. В downgrade эта табличка удаляется. Alembic по умолчанию специально добавляет такие комментарии, чтобы вы зашли туда, отредактировали его, хотя бы удалили эти комментарии. И на всякий случай просмотрели миграцию, убедились, что вас все устраивает. Это вопрос одной команды. У вас уже есть миграция.

После это вы, скорее всего, захотите эту миграцию применить. Нет ничего проще. Вам нужно просто сказать: alembic upgrade head. Он применит абсолютно всё.
Если мы скажем head, он попытается обновиться до самой свежей миграции. Если назовем конкретную миграцию, он обновится до нее.
Также есть команда downgrade — на случай, если вы, например, передумали. Все это выполняется в транзакциях и работает достаточно просто.

Итак, у вас есть миграции, вы умеете их запускать. У вас есть приложение, и вы задаетесь, например, таким вопросом: у меня есть CI, тесты бегают, и я даже не знаю, хочу ли я, например, запускать миграции автоматически? Может лучше это сделать руками?
Тут есть разные точки зрения. Наверное, стоит придерживаться правила: если у вас нет легкого доступа, возможности попасть на машину с БД, то лучше, конечно, делать это автоматически.
Если у вас есть доступ, вы делаете сервис, который работает в облаке, и можете туда зайти с ноутбука, который у вас всегда с собой, то можно делать это самостоятельно и тем самым дать себе больше контроля.
В целом есть много инструментов, позволяющих делать это автоматически. Например, в том же самом Kubernetes. Там есть init-контейнеры, которые это умеют и в которых можно выполнять эти команды. Можно и прямо в Docker добавить команду на запуск, которая это сделает.
Просто нужно учитывать: если вы применяете миграции автоматически, то вам нужно задуматься, что произойдет, если вы, например, захотите откатиться, но не сможете. Например, у вас была какая-нибудь табличка на 500 гигабайт с данными. Вы подумали: окей, больше эти данные по бизнес-логике не нужны, наверное, можно дропать. Взяли и дропнули. Или поменяли тип столбца, который поменялся с потерей данных. Например, была длинная строка, а стала короткая. Или что-нибудь удалилось. Или вы удалили столбец. Вы не сможете откатиться, даже если захотите.
Я в свое время делал продукты для on-premises, которые exe-файлом людям ставятся прямо на машину. Однажды ты понимаешь: да, ты написал миграцию, она ушла в продакшен, люди ее уже поставили. В ближайшие пять лет оно у них может работать по SLA, и ты хочешь что-то поменять, что-то могло быть лучше. В этот момент ты задумываешься, как быть с необратимыми изменениями.

Здесь тоже никакого rocket science. Идея в том, что вы можете не использовать эти столбцы или не использовать таблицы, насколько это возможно. Перестать к ним обращаться. Можно, например, в ORM пометить поля специальным декоратором. Он будет говорить в логах, что вы вроде хотели не трогать это поле, но до сих пор к нему обращаетесь. Просто завести задачу в бэклоге и когда-нибудь это дело удалить.
У вас, если что, будет время на то, чтобы откатиться обратно. И если все будет хорошо, вы потом спокойно потом в бэклоге эту задачу сделаете. Сделаете еще одну миграцию, которая уже реально все удалит.
Теперь самый важный вопрос: зачем и как тестировать миграции?

Это делают немногие из тех, у кого я спрашивал. Но лучше это делать. Это правило, которое написано болью, кровью и потом. Применение миграции в продакшене всегда сопряжено с риском. Вы никогда не знаете, чем это может закончиться. Даже очень хорошая миграция на вполне нормальном работающем продакшене, когда у вас настроен CI, может рвануть.
Дело в том, что когда вы тестируете миграции, вы можете даже скачивать, например, stage или какую-то часть продакшена. Прдакшен бывает большой, скачать его полностью для тестов или других задач не получается. Девелоперские базы — это, как правило, не совсем продакшен-базы. В них нет очень многого из того, что могло накопиться за годы.

Это могут быть поврежденные данные, когда мы что-то мигрировали, или старый софт, который привел данные в неконсистентное состояние. Еще это могут быть подразумеваемые зависимости — вдруг кто-то забыл добавить foreign-ключ. Он думает, что оно связано, но его коллеги, например, об этом не знают. Еще поля называют совершенно случайно, вообще не понятно, что они связаны.
Потом кто-то решил зайти и добавить какой-нибудь индекс прямо на продакшен, потому что «оно сейчас тормозит, а вдруг заработает быстрее?» Может, я утрирую, но люди правда иногда что-то меняют прямо в базах.
Бывают, конечно, ошибки в инструментах, в миграции схем. Если честно, я с таким не сталкивался. Обычно бывали первые три проблемы. И пожалуй, еще ошибки в предположениях о том, как следует переносить данные.
Когда у вас очень большая объектная модель, сложно держать все в голове. Сложно постоянно писать актуальную документацию. Самая актуальная документация — это ваш код, и в нем не всегда есть полностью расписанная бизнес-логика: что и как должно работать, кто что имел в виду.

Что мы можем проверить? Хотя бы то, что миграция запускается. Это уже здорово. И что в коде нет каких-то глупых опечаток. Можем проверить, что есть корректный метод downgrade (), что в методе downgrade () удаляются все типы данных, созданные SQLAlchemy.
SQLAlchemy делает очень много удобных вещей. Например, когда вы описываете таблицу и указываете тип столбца Enum, SQLAlchemy автоматически создаст тип данных для этого перечисления в PostgreSQL. Но код для удаления этого типа данных в методе downgrade () автоматически сгенерирован не будет.
Нужно это помнить и проверять: когда захотите откатиться и заново применить миграцию, попытка создания уже существующего типа данных в методе upgrade () вызовет исключение. И самое важное: если миграция меняет какие-либо данные, нужно проверять, что данные корректно изменяются в upgrade. И очень важно проверить, что они правильно откатываются в downgrade без побочных эффектов.

Прежде чем перейти к самим тестам, посмотрим, как лучше подготовиться к их написанию. Я видел много подходов к этому. Некоторые создают базу, таблички, потом пишут фикстуру, которая все это очищает, используют какие-нибудь фикстуры с автоприменением. Но идеальный способ, который защитит вас на 100% и будет гонять тесты в абсолютно изолированном пространстве, — это создание отдельной базы.
Есть шикарный модуль sqlalchemy_utils, который умеет создавать базы данных и удалять их. В PostgreSQL он еще проверяет: если кто-нибудь из клиентов заснул и не отключился, он не упадет с ошибкой, что «кто-то использует базу, я ничего не могу с ней сделать, не могу ее удалить». Вместо этого он спокойненько посмотрит, кто к ним подключился, отключит этих клиентов и спокойно удалит базу.
Создание базы и применение миграции на каждый тест — не всегда быстрый процесс. Это можно решить следующим образом: PostgreSQL поддерживает создание новых баз данных по шаблону, поэтому можно разделить подготовку базы на две фикстуры.
Первая фикстура запускается один раз на запуск всех тестов (scope=session), создает базу данных и применяет к ней миграции. Вторая фикстура (scope=function) создает базы непосредственно для каждого теста на основе базы из первой фикстуры.
Создание базы на основе шаблона работает очень быстро и позволяет сэкономить время на применение миграций для каждого теста.

Если мы говорим просто о том, как нам временно создать базу данных, то можем написать такую фикстуру. Что здесь происходит? Мы генерим случайное имя. Добавляем на всякий случай в конец pytest, чтобы, когда мы зайдем на localhost к себе через какой-нибудь Postico, можно было понять, что создано тестами, а что нет.
Потом генерируем из ссылки c информацией о подключении к БД, которую показал человек, новую, уже с новой базой. Создаем ее и просто отдаем ее в тесты. После того, как человек с этой базой данных поработал, мы ее удаляем.

Также мы можем подготовить Engine, чтобы к этой базе подключаться. То есть в этой фикстуре мы обращаемся к предыдущей фикстуре, используемой как зависимость. Создаем Engine и отдаем его в тесты.

Итак, какие тесты мы можем написать? Первый тест — это просто гениальное изобретение моего коллеги. С тех пор, как он появился, мне кажется, я забыл о том, что проблемы с миграциями бывают.
Это очень простой тест. Вы один раз добавляете его в свой проект. Он есть в проекте на GitHub. Вы можете просто утащить его к себе, добавить и забыть, наверно, о процентах 80 проблем.
Он делает очень простую вещь: получает список всех миграций и начинает по ним итерироваться. Вызывает upgrade, downgrade, upgrade.

Например, у нас есть пять миграций. Давайте посмотрим, как это будет работать. Вот первая миграция. Мы выполнили ее. Откатили первую миграцию, еще раз ее выполнили. Что здесь произошло? На самом деле мы здесь увидели, что человек корректно реализовал метод downgrade (), потому что два раза, например, создать таблицы уже не получилось бы.
Мы видим, что если человек создавал какие-то типы данных, он тоже их удалил, потому что там нет опечаток и в в целом это хотя бы как-то работает.
Затем тест двигается дальше. Он берет вторую миграцию, сразу пробегает до нее, откатывается на один шаг назад, снова пробегает вперед. И так происходит столько раз, сколько у вас есть миграций.
Задача этого теста — найти базовые ошибки, проблемы при изменении структуры данных.
Stairway запускается на пустой базе и обычно выполняется очень быстро. То есть этот тест — он больше про структуру данных. Это не про то, что вы меняете данные в миграциях. Но в целом он может очень здорово спасти вам жизнь.
Если вам нужно быстрое решение, вот оно. Это правило. Как правило Парето: вставляете в свой проект, и вам становится легче.

Выглядит этот тест примерно так. Мы получаем все ревизии, генерируем config Alembic. Вот то, что мы видели до этого, файл alembic.ini, здесь функция get_alembic_config, она считывает этот файл, добавляет в него нашу временную базу, потому что там мы указывали путь до базы. И после этого мы можем пользоваться командами Alembic.
Ранее выполненную команду — alembic upgrade head — тоже можно спокойно заимпортировать. К сожалению, на этом слайде не поместились все импорты, но поверьте мне на слово. Это просто from alembic.com, импорт upgrade. Вы туда переводите config, говорите, до куда заходить через upgrade. Потом говорите: downgrade.
При downgrade миграция откатывается до down_revision, то есть до предыдущей ревизии, или до »-1».
»-1» — альтернативный способ указать Alembic, что необходимо откатить текущую миграцию. Он очень актуален, когда запускается первая миграция, у нее down_revision равен None, в то время как API Alembic не позволяет передавать None в
