Пишем чат-бот для работы с PDF
Популярность языковых моделей, в частности ChatGPT, растет в геометрической прогрессии, но многие из нас все еще сталкивается с определенными ограничениями, такими как устаревшая информация, которые OpenAI пока что не смогла преодолеть.
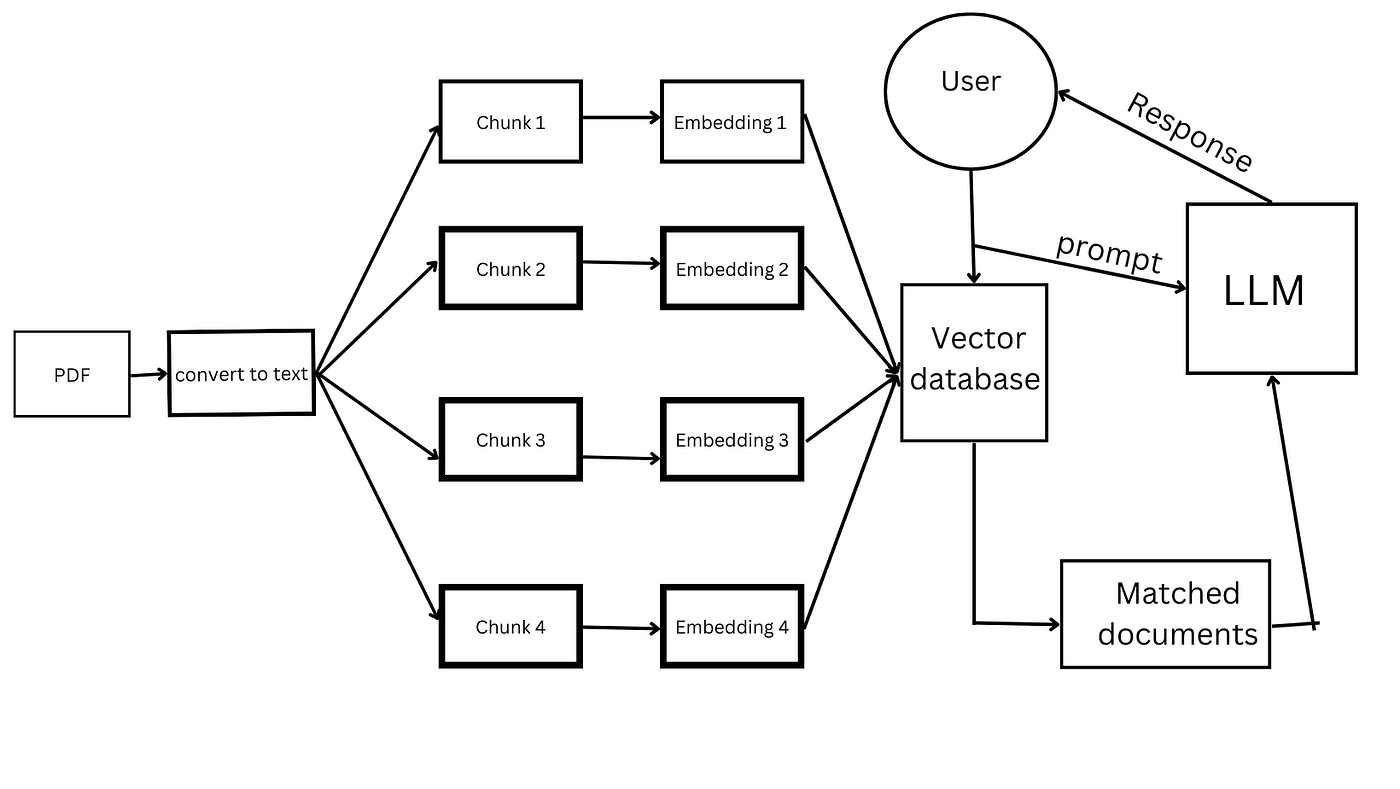
Но задумывались вы над тем, чтобы задавать вопросы непосредственно из своих документов, хранящихся в облаке? Сохраните своё время, которое уходило бы на поиски и ручной мониторинг сайтов, и задействуйте автоматизацию при работе с PDF-документами. Если вас занимает такая перспектива, эта статья окажется для вас ценным ресурсом.
Мы можем избежать риска недостоверных данных в ChatGPT, внедрив работу модели через RAG. В нашем материале мы подробно объясним, как создать чат-бота для взаимодействия с документами из вашего хранилища с помощью LangChain.
Приступим (:
Что такое RAG?
Мы все осведомлены о том, что ответы ChatGPT базируются на его тренировочных данных, над которыми у нас нет контроля, поэтому актуальной становится необходимость в методе, позволяющем обогащать модель данными пользователя.
RAG (Retrieval Augmented Generation) представляет собой подход в работе с крупными языковыми моделями, такими как ChatGPT, Llama или Cohere, цель которого — улучшение точности прогнозов за счёт интеграции внешнего хранилища данных в процесс генерации ответов. Суть заключается в том, что мы объединяем контекст запроса пользователя, соответствующие знания из хранилища RAG и предыдущий опыт взаимодействия, что дает языковой модели возможность предоставить более обстоятельный и точный ответ

RAG для LLMs
А Langchain?
Проще говоря, Langchain — это фреймворк, который упрощает работу с языковыми моделями, который предоставляет нам инструменты, необходимые для создания приложений, работающих на основе LLM.

Но почему именно он? Этот фреймворк дает нам возможность разрабатывать интеллектуальные приложения, учитывающие контекст запросов. Это особенно ценно для предоставления информации, актуальной для запросов пользователей, что является ключевым аспектом в нашей задаче. Не забывайте также, что у ChatGPT есть ряд ограничений (как пример, неактуальность фактов, недоступность пользовательских данных или ограниченный объем знаний), и фреймворк Langchain ориентирован на преодоление этих ограничений.
FAISS
Известно, что большинство крупных языковых моделей (LLM) имеют ограничения по количеству слов или токенов в запросе, поэтому, когда дело доходит до работы с PDF-файлами (даже если это один документ, не говоря уже о десятках или сотнях), мы просто не можем представить все данные как единый контекст сразу, что является не только неудобным, но и неэффективным.
Библиотека FAISS (Facebook AI Similarity Search), разработанная командой Facebook AI из компании Meta, представляет собой инструмент для быстрого поиска похожих элементов и кластеризации плотных векторов. Помимо этого, библиотека поддерживает использование графических процессоров (GPU) для ускоренной обработки данных.
Архитектура FAISS:


В рамках нашего приложения, применение FAISS обеспечивает возможность извлекать и возвращать текст, который является релевантным запросу пользователя, таким образом решая проблему с ограничением объема слов, о которой мы упоминали ранее.
Embeddings
В предыдущем разделе мы упомянули векторные представления, но в чем заключается их значение? Векторы представляют собой числовые массивы, что позволяет нам выполнять различные математические операции над текстом, такие как поиск текстовых фрагментов с заданным значением или контекстом. Именно на этих представлениях строится работа крупных языковых моделей (LLM) и ChatGPT в частности.

Вообще, поиск — это одно из самых частых применений векторных представлений. То есть, мы преобразуем данные в векторный формат, после чего храним их в базе данных для векторов. Для поиска используем метод на основе сходства с применением алгоритма KNN (K-Nearest Neighbors, или метод k ближайших соседей):

Для иллюстрации: в случае традиционного поиска по ключевым словам, если бы мы использовали запрос типа «Найди мне модели Mac с процессором Intel» в системе поиска SOLR, вероятно, мы бы не получили результатов высокого качества, поскольку платформа не интерпретирует смысл слов, а будет осуществлять поиск слов с аналогичным написанием и звучанием. В то же время, при использовании векторного поиска мы можем учитывать не только факт наличия слова, но и его контекст в предложении благодаря специфике хранения слов в виде векторов.
Кодим?
Установим необходимые пакеты и импортируем их:
# Устанавливаем необходимые пакеты
pip install openai
pip install langchain
pip install langchain-openai
pip install PyPDF2
pip install langchain-community
# Устанавливаем Faiss для GPU.
pip install faiss-gpu
#pip install faiss-cpu – если нет GPU
# Импорт для обработки ошибок и логирования
import logging
# Импорт для чтения PDF из PyPDF2
from PyPDF2 import PdfReader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.chat_models import ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferMemory
Далее нам необходимо поработать с входящим PDF-файлом:
# Инициализируем экземпляр класса OpenAIEmbeddings для работы с векторными вложениями текста
embeddings = OpenAIEmbeddings()
# Установка уровня логирования
logging.basicConfig(level=logging.INFO)
# Функция для разбиения текста на параграфы
def split_paragraphs(rawText):
# Инициализируем текстовый разделитель, который разбивает текст на параграфы
text_splitter = CharacterTextSplitter(
separator="\n", # Разделитель - символ новой строки
chunk_size=1000, # Максимальный размер фрагмента текста
chunk_overlap=200, # Перекрытие между фрагментами
length_function=len, # Функция для определения длины текста
is_separator_regex=False, # Указываем, что разделитель не является регулярным выражением
)
# Разбиваем текст на параграфы с помощью текстового разделителя и возвращаем результат
return text_splitter.split_text(rawText)
# Функция для загрузки текста из PDF-файлов
def load_pdfs(pdfs):
text_chunks = [] # Создаем пустой список для хранения текстовых фрагментов
# Проходим по всем PDF-файлам
for pdf in pdfs:
try:
with open(pdf, 'rb') as file:
reader = PdfReader(file)
for page in reader.pages:
raw = page.extract_text()
chunks = split_paragraphs(raw)
text_chunks += chunks
except Exception as e:
logging.error(f"Error loading PDF {pdf}: {e}")
# Возвращаем список текстовых фрагментов
return text_chunks
# Создаем экземпляр класса FAISS для хранения векторных вложений
store = None # Изначально устанавливаем значение None, оно будет изменено позже при необходимости
Далее, нам нужно обеспечить хранение обработанного текста:
# Основная функция программы
def main():
# Список PDF-файлов для обработки
list_of_pdfs = ["test.pdf"]
# Загрузка текста из PDF-файлов и разбиение на фрагменты
text_chunks = load_pdfs(list_of_pdfs)
# Инициализация экземпляра класса OpenAIEmbeddings для работы с векторными вложениями текста
embeddings = OpenAIEmbeddings()
store = FAISS.from_texts(text_chunks, embeddings)
# Запись индекса на диск
store.save_local("./vectorstore")
# Если код запускается непосредственно, а не импортируется в другой модуль, то вызываем функцию main().
if name == "main":
main()
Обеспечим взаимодействие:
# Загружаем сохраненное хранилище FAISS с диска. OpenAIEmbeddings() используется для преобразования текста в векторы.
store = FAISS.load_local("vectorstore", OpenAIEmbeddings(), allow_dangerous_deserialization=True)
# Создаем экземпляр модели ChatGPT turbo
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature=0)
# Создаем экземпляр цепочки RetrievalQA, используя экземпляры модели llm и хранилища store в качестве параметров
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=store.as_retriever()
)
# Импортируем список разговоров
conversations = [...] # [...] - ваш список разговоров
Сохраним контекст:
# Создаем экземпляр ConversationBufferMemory
memory = ConversationBufferMemory()
# Проходим по списку разговоров и сохраняем контекст каждого разговора в памяти
for msg in conversations:
memory.save_context(
{"input": msg['human_question']},
{"output": msg['chatbot_answer']}
)
# Создаем экземпляр цепочки RetrievalQA, используя экземпляры модели llm, хранилища store и памяти memory в качестве параметров
chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=store.as_retriever(),
memory=memory
)
Подведем итоги
В этой статье мы подробно изучили процесс создания простого чат-бота для работы с PDF-документами с использованием фреймворка LangChain. Разумеется, представленный здесь бот является только начальной стадией разработки функционального инструмента, но этот пример выступает важной отправной точкой для понимания подходов к созданию подобных приложений. Вы можете развернуть его локально и оценить функционал.
Я считаю, что это представляет существенный интерес, особенно потому, что, как мы уже отмечали, OpenAI в настоящее время не способен устранять все недостатки своих моделей, что приводит к выдаче устаревших или неверных ответов —, а набор данных, на котором обучены модели, может быть не актуален. Использование такого программного обеспечения позволит нам опираться на проверенные источники данных (или же самостоятельно брать ответственность за релевантность ответов, что зависит от выбранного источника информации). В любом случае, это может значительно экономить время, и это несомненный плюс.
Конечно, существуют уже готовые решения, такие как плагин AskYourPDF, но есть определенное удовлетворение в создании собственного продукта, настроенного лично под ваши потребности и предпочтения.
Спасибо за прочтение! Будем рады услышать ваше мнение (:
