Phoenix: разбираемся со сбоями ML системы прямо в вашем ноутбуке

Добрый день! Меня зовут Роман, на момент написания статьи я являюсь студентом 4-курса НГУ. Я изучаю машинное обучение уже почти три года, а сейчас в своих исследованиях я занимаюсь большими языковыми моделями. В этой статье хочу рассказать вам об одной полезной библиотеке.
Что это за птица?
Phoenix — это библиотека с открытым исходным кодом, направленная на ML Observability, которую выпустили разработчики из Arize AI — компании, известной большим опытом в вопросах наблюдаемости ML систем.
Нам до сих пор не до конца понятны некоторые возможности больших языковых моделей.
Основная цель Phoenix — помочь специалистам по данным понять и оценить сложные LLM-приложения, чтобы они могли узнать больше о внутренней работе системы.
Чтобы иметь возможность понимать что-то о системе, приложения с большими языковыми моделями должны быть оснащены необходимыми инструментами и оставлять данные о событиях, произошедших в процессе работы. Более того, когда данные собраны, их необходимо оценить на предмет критических ошибок, таких как галлюцинации и токсичность.
ML Observability или наблюдаемость — термин, который стоит в основе библиотеки.
По утверждению авторов библиотеки, ML система наблюдаема, если вы можете:
обнаруживать проблемы в продакшене, например, отсутствие признака в пайплайне, дрейф данных или резкое ухудшение производительности;
быстро идентифицировать корень проблемы.
Говоря терминами — ML Observability = Monitoring + Root-Cause Analysis
Наблюдаемость — это инструментирование вашей системы так, чтобы гарантировать сбор и анализ достаточного объема данных о ее работе.
В ML наблюдаемость включает интерпретируемость, помогающую нам понять, как работает ML-модель, кроме того, наблюдаемость также помогает разобраться с тем, как работает вся система, включающая ML-модель. Например, когда в течение последнего часа производительность модели ухудшается, способность выявить и интерпретировать признак, который вносит наибольший вклад в неправильные прогнозы за последний час, поможет выяснить, что пошло не так и как это исправитьЧип Хьюен, «Проектирование систем машинного обучения»
Доступный функционал
После простой установки —pip install arize-phoenix,
Phoenix предоставляет MLOps и LLMOps инсайты с молниеносной скоростью и возможностью наблюдения без трудной настройки.
Phoenix UI доступен по ссылке, которую выдает методlaunch_app
Или прямо в вашем ноутбуке с помощью вызова метода active_session().view()
Пользователю предоставляются определенные сценарии для внедрения мониторинга и наблюдаемости в системы моделей и LLM-приложений:
LLM Traces. Phoenix предоставляет фреймворк, который позволяет иерархически отслеживать процесс выполнения вашего приложения с LLM на основе LangChain и LlamaIndex, позволяя понять больше о внутренней структуре и устранить проблемы, которые тяжело обнаружить в связи с широкой областью применения: поиск и припоминание через векторные хранилища, генерация эмбеддингов, использование внешних инструментов и т.д.
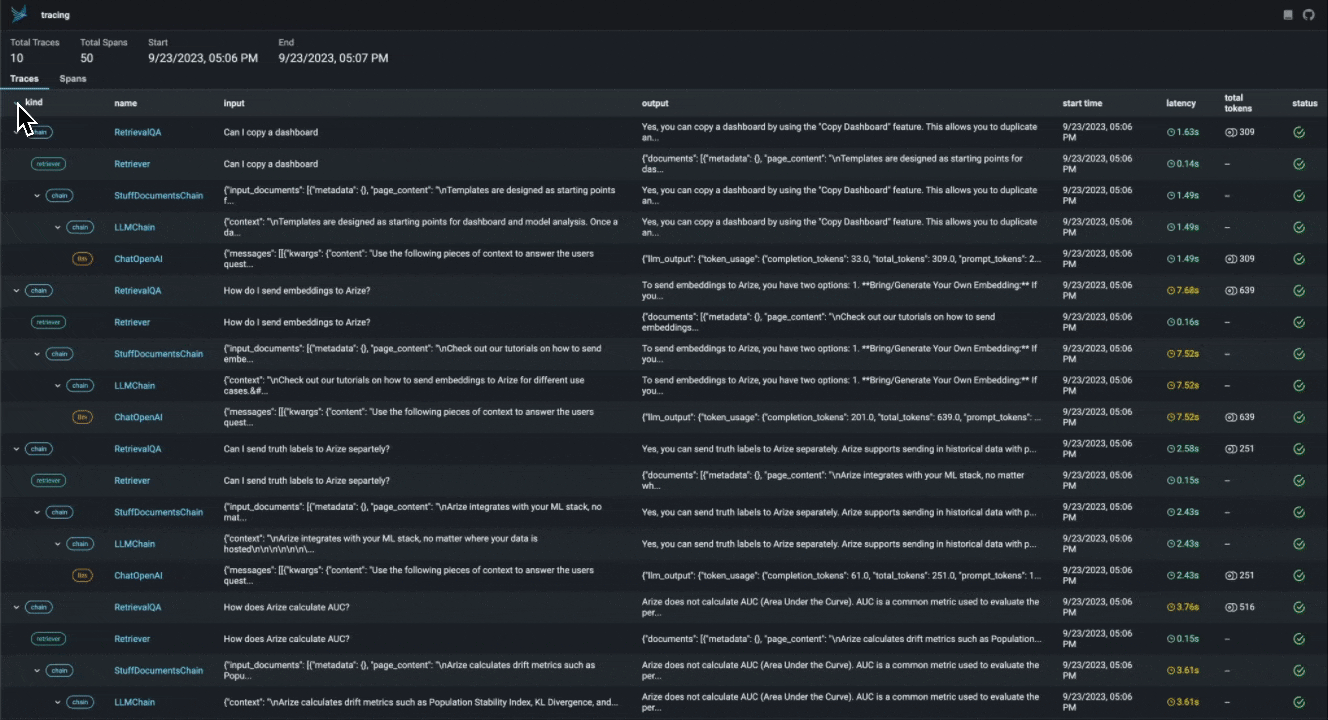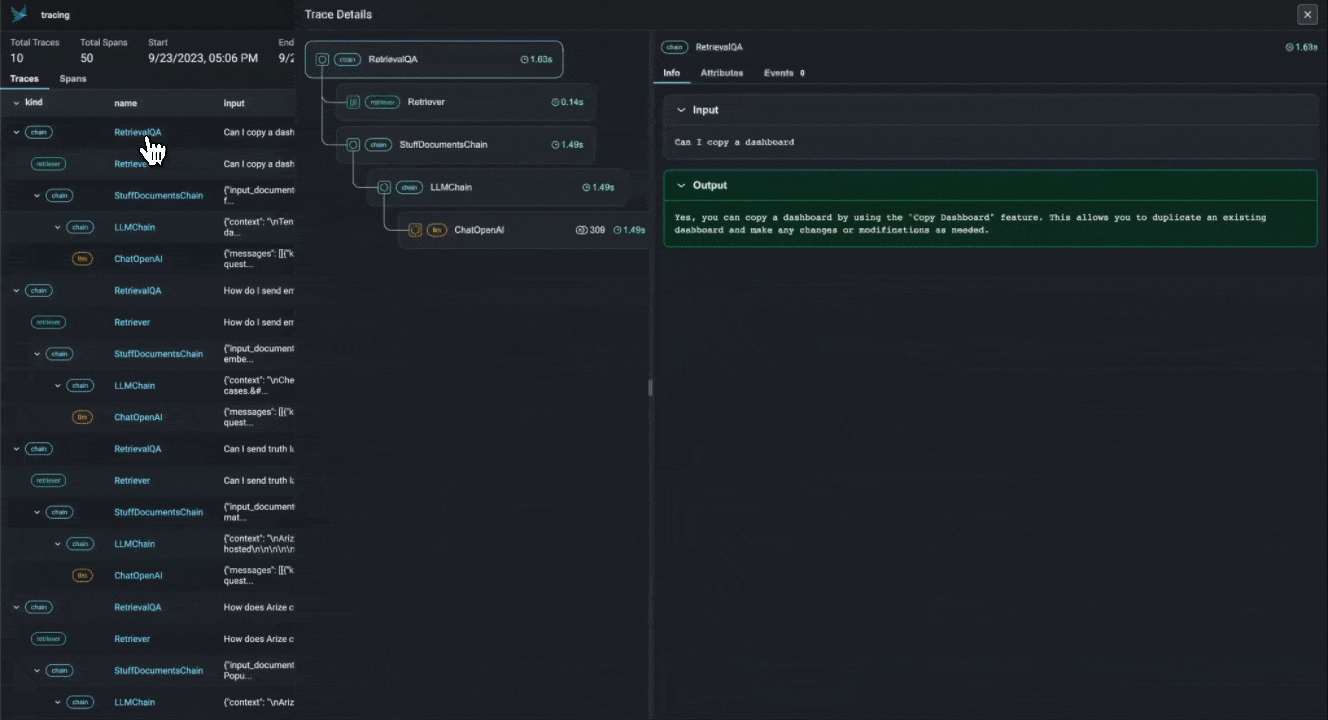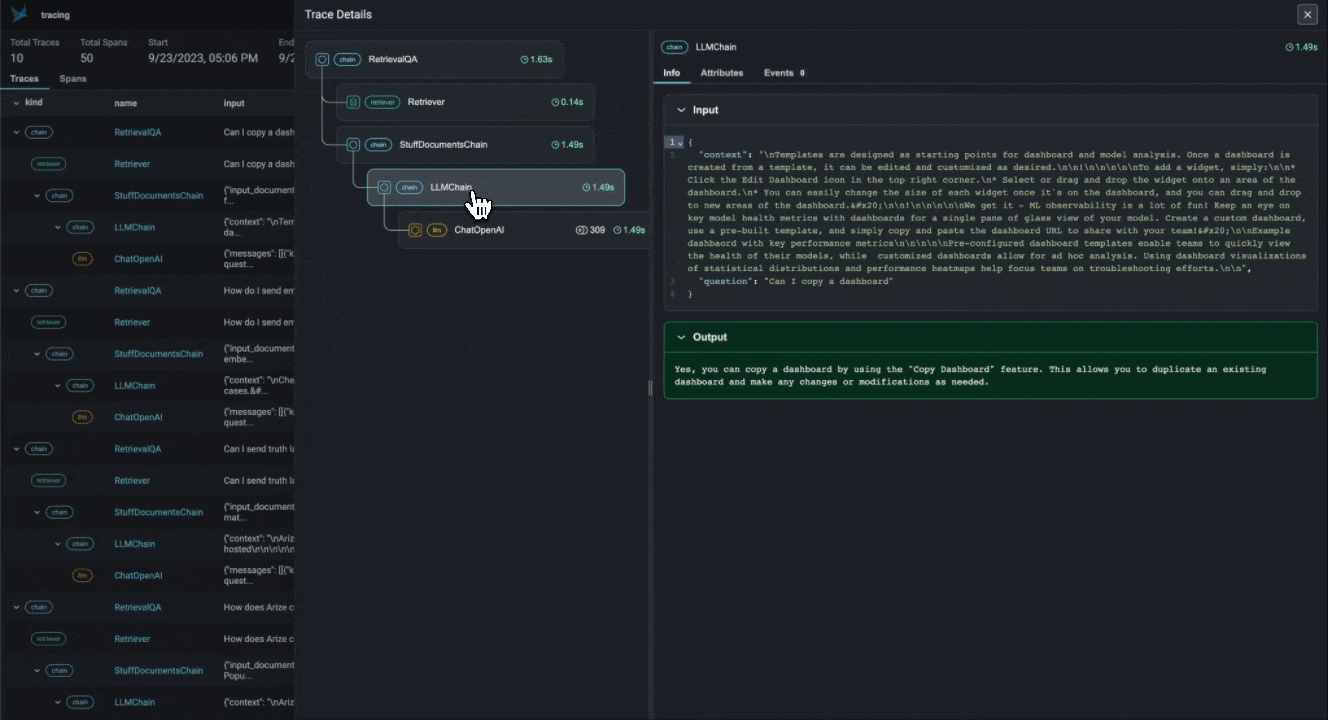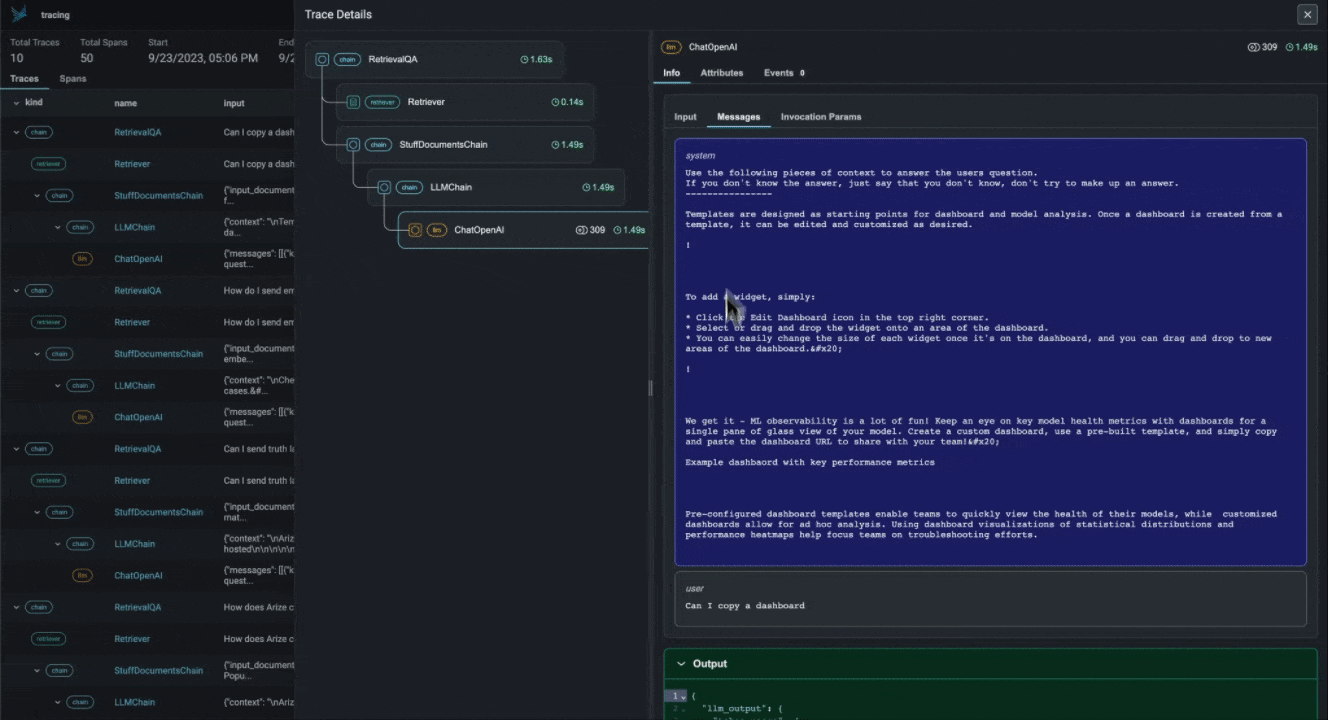
Цепочка Retrieval-Augmented Generation по документам в LangChain приложении
Phoenix использует стандарт OpenInference для того, чтобы отслеживать, экспортировать и собирать информацию о приложении. О данном формате можете почитать здесь — OpenInference Specification.
Туториалы от авторов библиотеки для ознакомления в Colab: Tracing with LlamaIndex, Tracing with LangChain.
LLM Evals. Используйте бенчмарки на основе LLM для трудно выявляемых проблем, вроде галлюцинаций и релевантности RAG.
Подход Phoenix к оценкам c помощью LLM примечателен по следующим причинам:
— cодержит заранее проверенные шаблоны и удобные функции для типичных задач;
— выдерживает строгость в тестировании комбинаций моделей и шаблонов;
— разработан для максимально быстрой работы с батчами;
— включает в себя набор эталонных датасетов и тесты для каждого метода оценки.На данный момент требует установки
arize-phoenix[experimental]Туториал для ознакомления в Colab — Оценка релевантности классификации на основе RAG.Анализ эмбеддингов. Исследуйте облака точек эмбеддингов, размерность которых уменьшается с помощью UMAP и выявляйте кластеры с высоким дрейфом и снижением качества.

В верхней части можно увидеть измерение дрейфа в продакшене со временем
Анализ эмбеддингов критически важен для понимания поведения приложения.
Phoenix предоставляет фреймворк для A/B тестов, чтобы понять, как ваши эмбеддинги меняются со временем и в различных версиях вашей модели, например,prodvstrain, и помочь в активном обучении.
Раскрашивайте облака точек по размерам, дрейфу и производительности вашей модели, чтобы выявить проблемные выборки
Данные разбиваются на кластеры с помощью встроенного HDBSCAN.
 Кластеры можно экспортировать в parquet для дальнейшего анализа и файн-тюнинга
Кластеры можно экспортировать в parquet для дальнейшего анализа и файн-тюнингаТуториал для ознакомления в Colab — Aктивное обучение в задаче классификации изображений при дрейфе данных.
Structured Data Analysis. Phoenix предоставляет набор инструментов для структурированных данных: A/B-анализ, анализ временного дрейфа и многое другое.
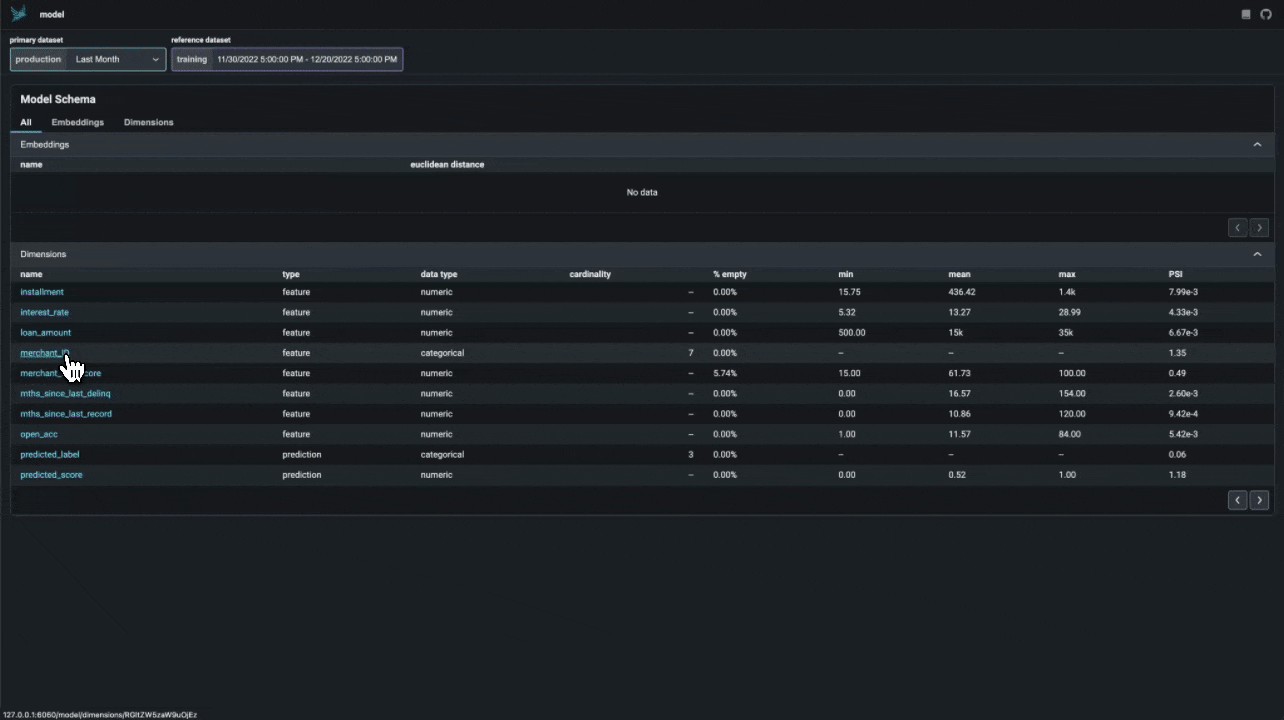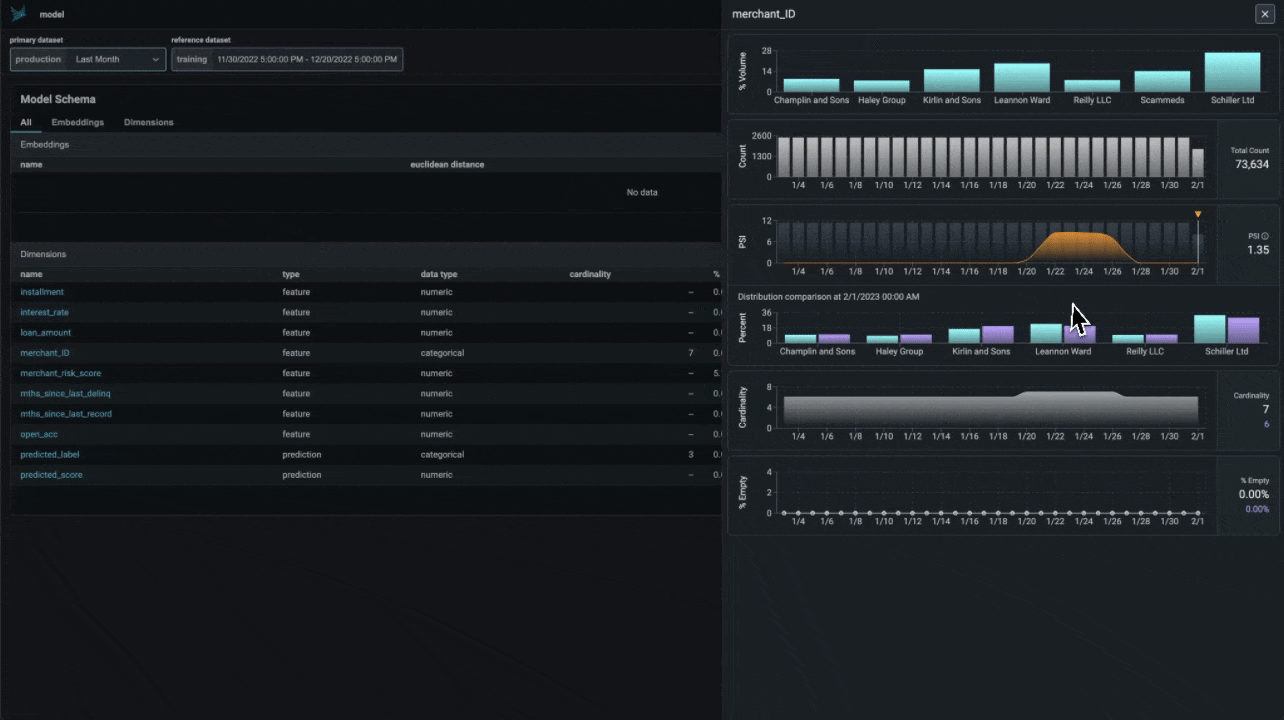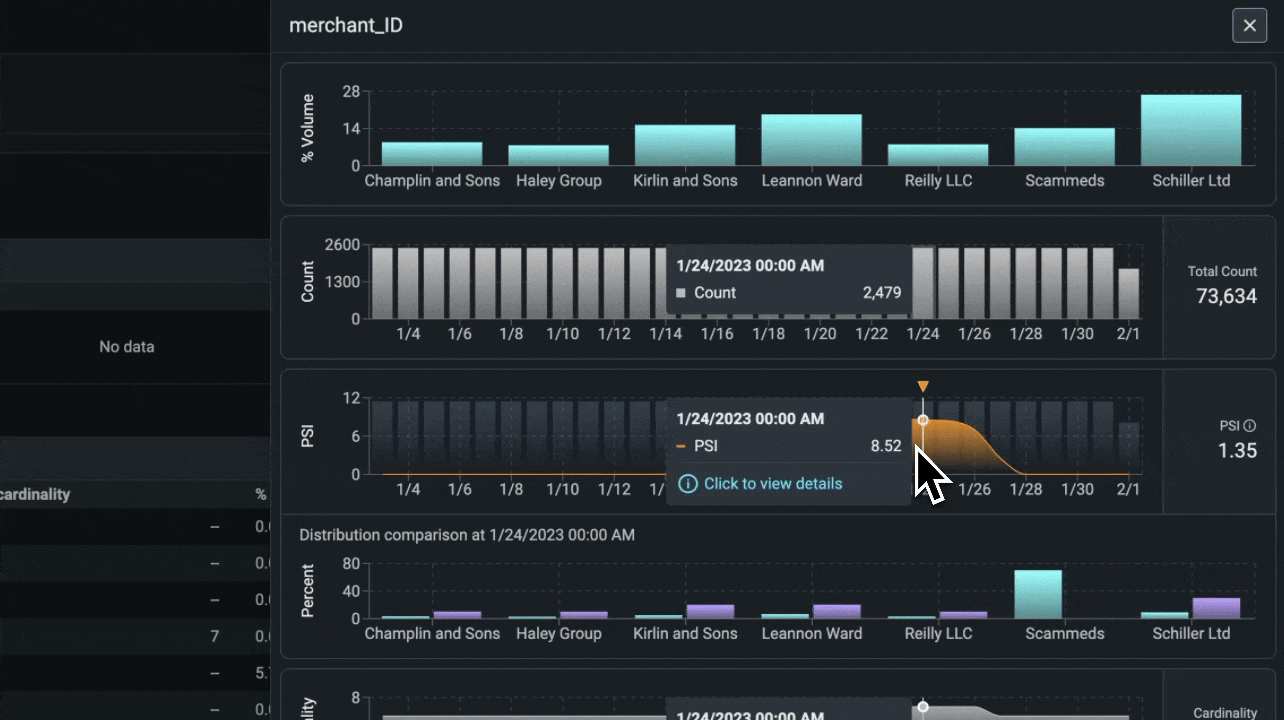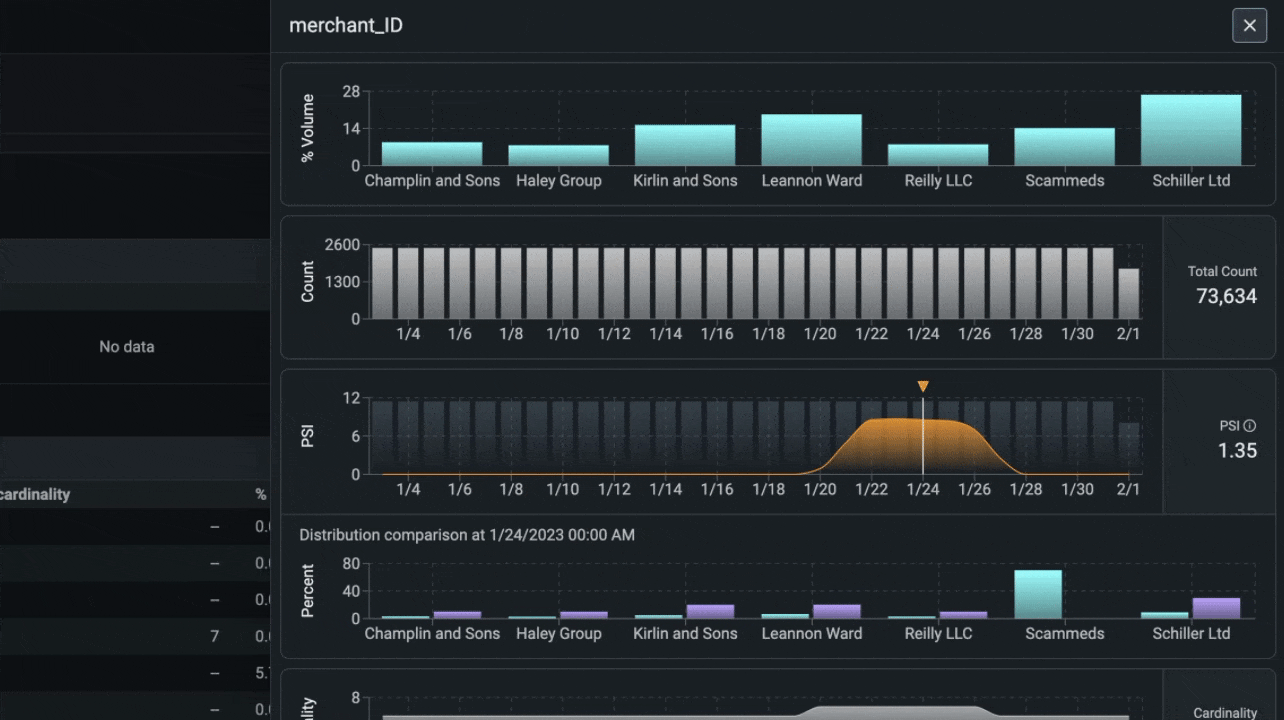
Анализ дрейфа признаков
Туториал для ознакомления в Colab — Обнаружение мошенничества на табличных эмбеддингах.
RAG-анализ. Визуализируйте процесс поиска и припоминания вашего приложения, чтобы улучшить качество генерации с расширенным поиском.

Как говорил Платон, «знание подобно припоминанию»
Поисковая расширенная генерация является важнейшим компонентом многих приложений LLM, поскольку она позволяет расширить возможности модели, включив в неё знания о дополнительных данных. Обычно для хранения фрагментов документов используется векторное хранилище эмбеддингов, которые «припоминаются» на инференсе, добавляясь к контексту
Phoenix позволяет загружать корпус вашей базы знаний вместе с выводами вашего LLM-приложения, чтобы помочь устранить неполадки, которые трудно обнаружить при использовании этого алгоритма.

Туториал для ознакомления в Colab — Оценка и улучшение RAG в LlamaIndex приложении.
Аналоги
Можно обратить внимание на платформу Arize, которую разработчики рекомендуют использовать в продакшене вместо Phoenix. Она обладает расширенным функционалом для промышленных решений.

Arize доступен в облаке или on-prem — на ваших серверах, поддерживает работу сразу с несколькими моделями, предлагает возможность делиться сведениями и дэшбордами в команде, но имеет серьезные ограничения в бесплатной версии. Если у вас большая команда или крупные проекты, то вам не хватит и pro версии с ограничением на 2 модели по 200 признаков. Кроме того, могут быть проблемы с подпиской, если вы из России.

arize — больше интеграций, больше возможностей от тех же разработчиков, но уже не open source

Также можно обратить взгляд на Aporia. У этой платформы есть отслеживание токенов и запросов с расчётом затрат для удобного планирования бюджета, инструменты, направленные на борьбу с галлюцинациями LLM и встраивание модерации в чат. Для получения демо необходимо оставлять заявку от компании. Также могут быть проблемы у российских компаний.

Широкий функционал под разные модели и их количество
Если вам не сильно важны предположения о взаимосвязи между внутренним состоянием системы и выходными данными, то самое подходящее для вас решение с качественным мониторингом — это open-source платформа Evidentely AI
Evidentely AI фокусируется на трёх аспектах:
Тесты по батчам

Отчеты с интерактивной визуализацией

Дэшборд с мониторингом

Evidentely AI — российский стартап, основанный в 2020 году Еленой Самуйловой и Эмели Драль, которые ранее работали в Yandex Data Factory

Evidentely стремится к развитию в области наблюдаемости и активно работает над функционалом, связанным с LLM.
Заключение

Phoenix предназначен для быстрой итеративной разработки моделей и их подготовки к эксплуатации
Основные преймущества Phoenix:
Библиотека имеет полностью открытый исходный код, построена на открытых стандартах и работает на условиях конфиденциальности вашего ноутбука
Приложение запускается прямо в вашем локальном Jupyter сервере или в Colab
Богатый инструментарий для оценки и обнаружения аномалий приложений с большими языковыми моделями
Нахождение проблемных кластеров и их последующий экспорт для удобного файн-тюна
Указание на данные, которые необходимо изучить для идентификации корня проблемы
Дополнительные материалы
Статья была подготовлена в рамках курса «ML System Design» от Дмитрия Колодезева на платформе Open Data Science.
Чтобы понимать больше про сбои ML-систем, я рекомендую вам занятие — «Диагностика ошибок и отказов ML-систем»

Автор отличной книги по проектированию ML систем — Чип Хьюен — рекомендует в своем MLOps гайде доклад от Джона Уиллса — Instrumentation, Observability & Monitoring of Machine Learning Models

У Arize есть качественный бесплатный курс по Machine Learning Observability
Также, можете посмотреть курс на ту же тему от Evidentely AI
А для работы с Phoenix советую обратить внимание на:
документацию;
плейлист по библиотеке на канале Arize;
туториалы из официального репозитория;
сообщество в Slack.
Спасибо, что прочитали! Делитесь своими впечатлениями и опытом использования ML Observability платформ и инструментов в комментариях.
