Performance in .NET Core

Всем привет! Данная статья является сборником Best Practices, которые я и мои коллеги применяем на протяжении долгого времени при работе на разных проектах.
Intel Core i5–8250U CPU 1.60GHz (Kaby Lake R), 1 CPU, 8 logical and 4 physical cores
.NET Core SDK=3.0.100
[Host]: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), 64bit RyuJIT
Core: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), 64bit RyuJIT
[Host]: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64bit RyuJIT
Core: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64bit RyuJIT
Job=Core Runtime=Core
ToList vs ToArray and Cycles
Данную информацию я планировал готовить с выходом .NET Core 3.0, но меня опередили, мне не хочется красть чужую славу и копировать чужую информацию, поэтому просто укажу ссылку на хорошую статью, где подробно расписанно сравнение.
От себя лишь хочу представить вам свои замеры и результаты, я добавил в них обратные циклы для любителей «C++ стиля» написания циклов.
public class Bench
{
private List _list;
private int[] _array;
[Params(100000, 10000000)] public int N;
[GlobalSetup]
public void Setup()
{
const int MIN = 1;
const int MAX = 10;
Random random = new Random();
_list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList();
_array = _list.ToArray();
}
[Benchmark]
public int ForList()
{
int total = 0;
for (int i = 0; i < _list.Count; i++)
{
total += _list[i];
}
return total;
}
[Benchmark]
public int ForListFromEnd()
{
int total = 0;t
for (int i = _list.Count-1; i > 0; i--)
{
total += _list[i];
}
return total;
}
[Benchmark]
public int ForeachList()
{
int total = 0;
foreach (int i in _list)
{
total += i;
}
return total;
}
[Benchmark]
public int ForeachArray()
{
int total = 0;
foreach (int i in _array)
{
total += i;
}
return total;
}
[Benchmark]
public int ForArray()
{
int total = 0;
for (int i = 0; i < _array.Length; i++)
{
total += _array[i];
}
return total;
}
[Benchmark]
public int ForArrayFromEnd()
{
int total = 0;
for (int i = _array.Length-1; i > 0; i--)
{
total += _array[i];
}
return total;
}
}
Скорость работы в .NET Core 2.2 и 3.0 являются почти идентичными. Вот что мне удалось получить в .NET Core 3.0:
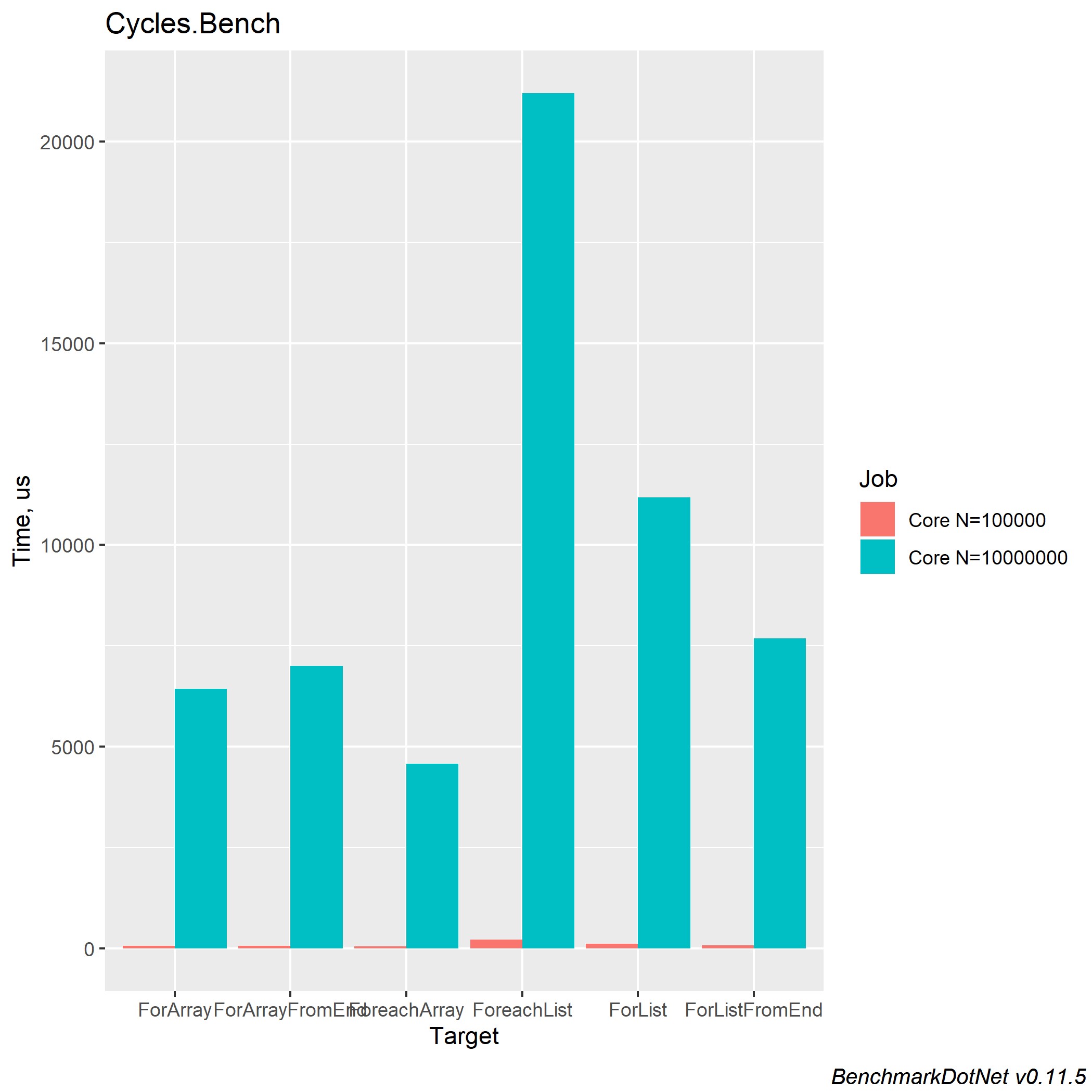
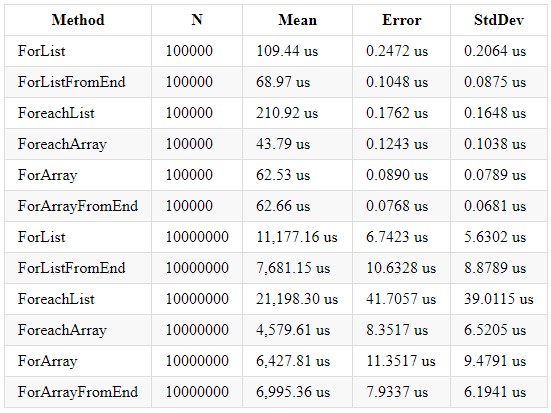
Мы можем прийти к выводу о том, что циклическая обработка коллекции типа Array является более быстрой, за счет своих внутренних оптимизаций и явного выделения размера коллекции. Также стоит помнить, что у коллекции типа List есть свои преимущества и вам стоит использовать нужную коллекцию в зависимости от необходимых вычислений. Даже если вы пишете логику работы с циклами не стоит забывать, что это обычный loop и он тоже подвержен возможной оптимизации циклов. На habr довольно давно вышла статья: https://habr.com/ru/post/124910/. Она всё ещё актуальна и рекомендуется к прочтению.
Throw
Год назад я работал в компании над legacy проектом, в том проекте было в рамках нормального обрабатывать валидацию полей через try-catch-throw конструкцию. Я уже тогда понимал, что это нездоровая бизнес-логика работы проекта, поэтому по возможности старался не использовать такую конструкцию. Но давайте разберёмся, чем же плох подход обрабатывать ошибки такой конструкцией. Я написал небольшой код для того, чтобы сравнить два подхода и снял «бенчи» на каждый вариант.
public bool ContainsHash()
{
bool result = false;
foreach (var file in _files)
{
var extension = Path.GetExtension(file);
if (_hash.Contains(extension))
result = true;
}
return result;
}
public bool ContainsHashTryCatch()
{
bool result = false;
try
{
foreach (var file in _files)
{
var extension = Path.GetExtension(file);
if (_hash.Contains(extension))
result = true;
}
if(!result)
throw new Exception("false");
}
catch (Exception e)
{
result = false;
}
return result;
}
Результаты в .NET Core 3.0 и Core 2.2 имеют аналогичный результат (.NET Core 3.0):
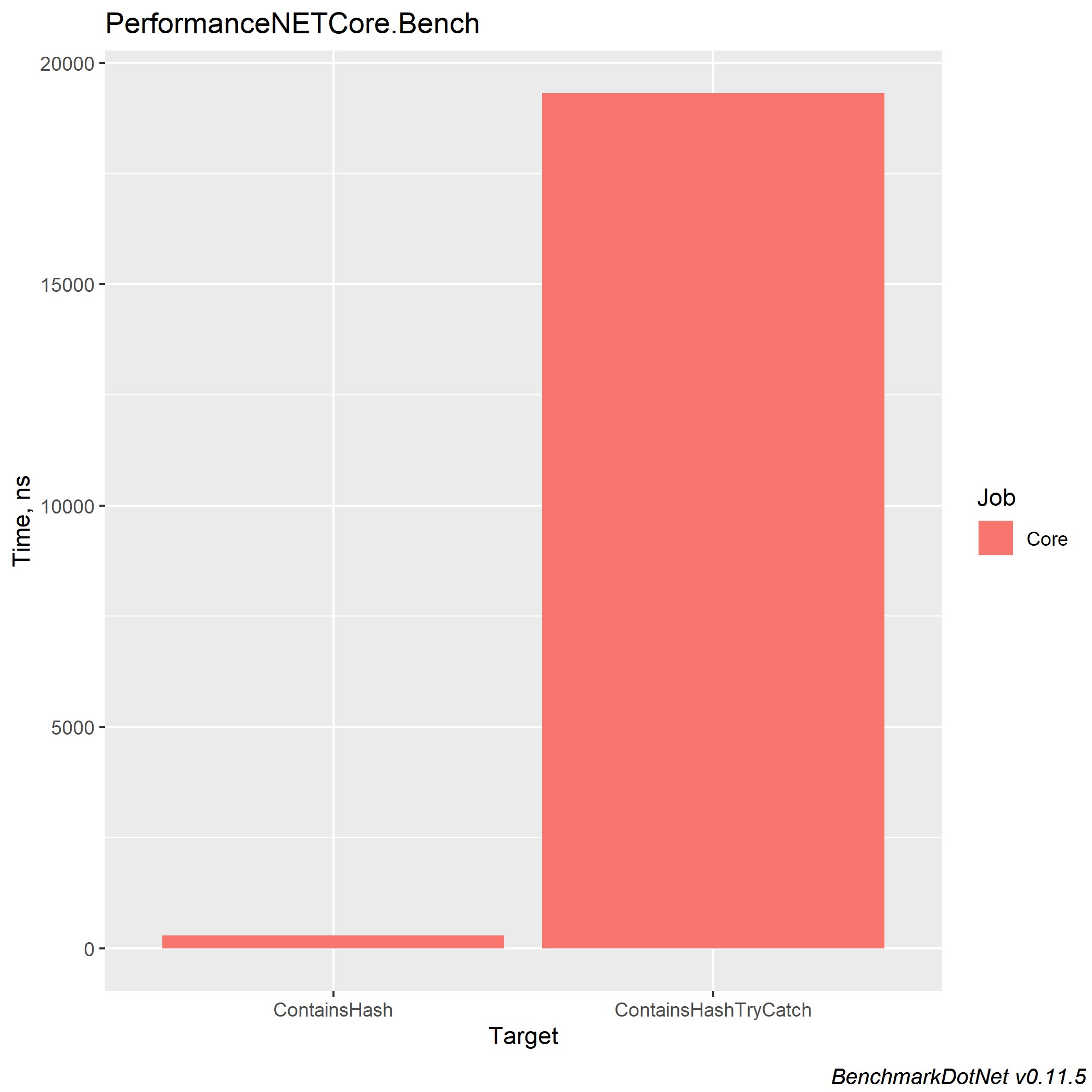
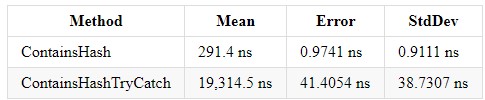
Try catch усложняет понимание кода и увеличивает время выполнения вашей программы. Но если вам необходима данная конструкция, не стоит вставлять те строки кода, от которых не ожидается обработка ошибок — это облегчит понимание кода. На самом деле, нагружает систему не столько обработка исключений, сколько выкидывание самих ошибок через конструкцию throw new Exception.
Выкидывание исключений работает медленнее какого-нибудь класса, который соберёт ошибку в нужном формате. Если вы обрабатываете форму или какие-нибудь данные и явно знаете какая ошибка должна быть, так почему бы не обработать их?
Не стоит писать конструкцию throw new Exception () если эта ситуация не является исключительной. Обработка и выкидывание исключения стоит очень дорого!!!
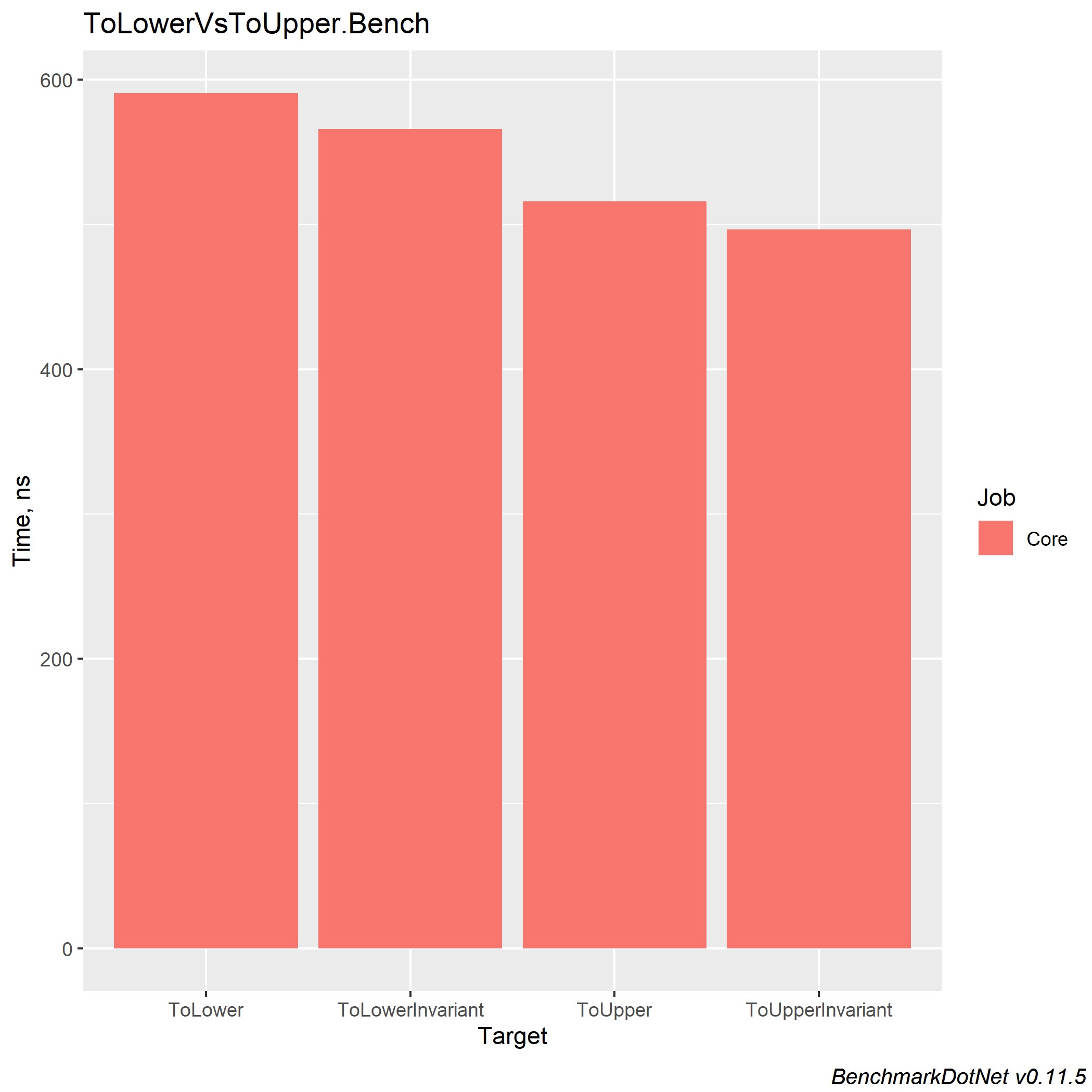
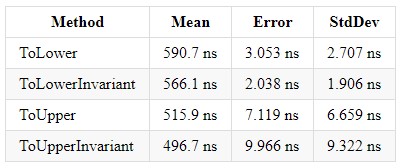
ToLower, ToLowerInvariant, ToUpper, ToUpperInvariant
За свой 5 летний опыт работы на платформе .NET встречал немало проектов, которые использовали сопоставление строк. Также видел следующую картину: было одно Enterprise решение с множеством проектов, каждый из которых выполнял сравнение строк по разному. Но что стоит использовать и как это унифицировать? В книге CLR via C# Рихтера я вычитал информацию о том, что метод ToUpperInvariant () работает быстрее ToLowerInvariant ().
Вырезка из книги:

Конечно же я не поверил и решил провести некоторые тесты тогда ещё на .NET Framework и результат меня шокировал — более 15% прироста производительности. Далее по приходу на работу следующим утром я показал данные замеры своему начальству и предоставил им доступ к исходникам. После этого 2 из 14 проектов были изменены под новые замеры, а при учёте того что эти два проекта существовали чтобы обрабатывать огромные excel таблицы, результат был более чем значимым для продукта.
Также представляю вам замеры для разных версий .NET Core, чтобы каждый из вас мог сделать выбор в сторону наиболее оптимального решения. А я лишь хочу дополнить, что в компании, где я работаю, мы используем ToUpper () для сравнения строк.
public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3";
[Benchmark]
public bool ToLower()
{
return defaultString.ToLower() == defaultString.ToLower();
}
[Benchmark]
public bool ToLowerInvariant()
{
return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant();
}
[Benchmark]
public bool ToUpper()
{
return defaultString.ToUpper() == defaultString.ToUpper();
}
[Benchmark]
public bool ToUpperInvariant()
{
return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant();
}
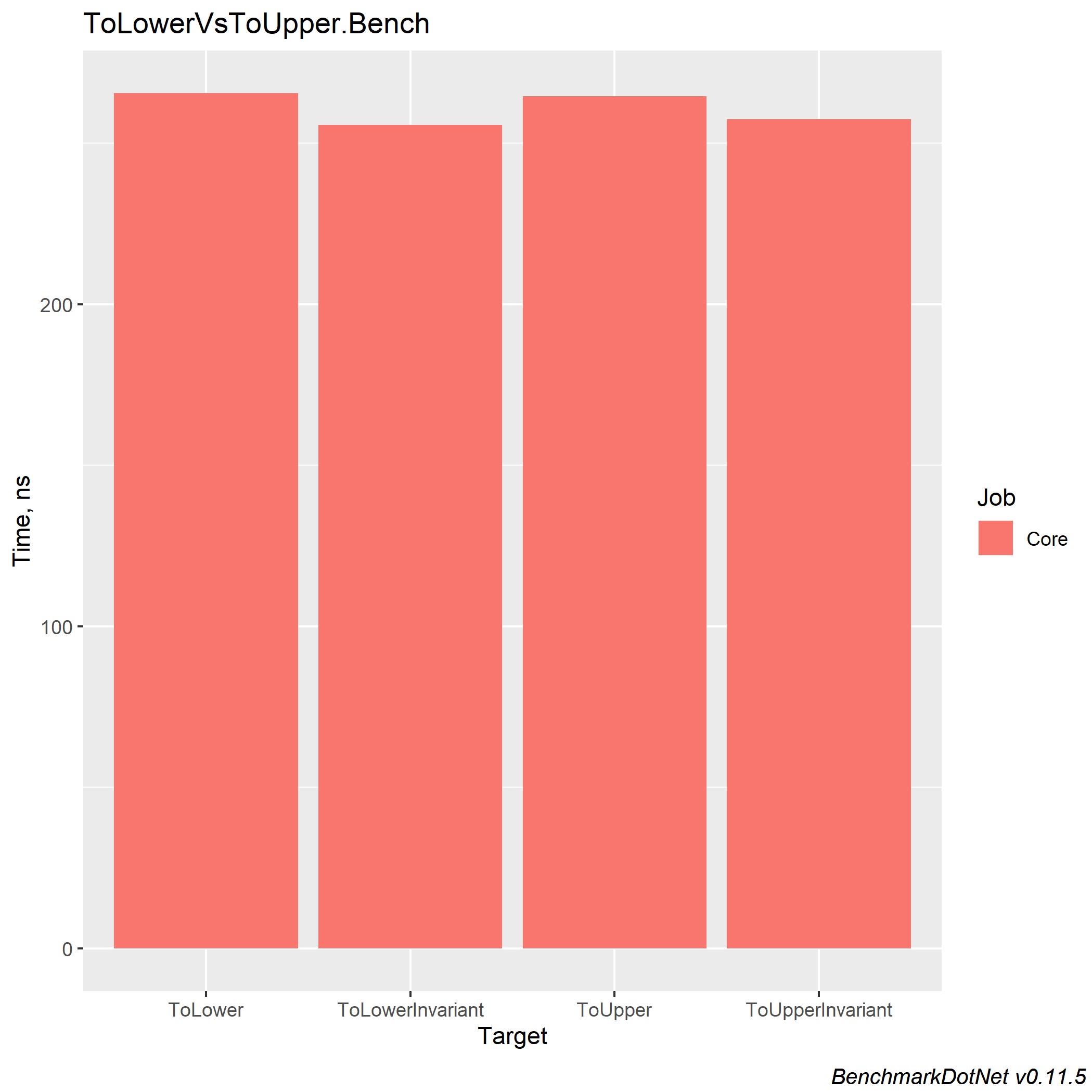
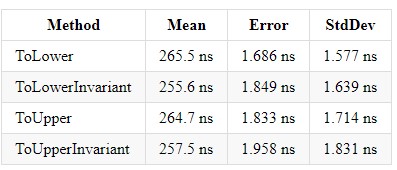
В .NET Core 3.0 прирост для каждого из этих методов ~x2 и балансирует реализации между собой.
Tier Compilation
В своей прошлой статье я описал этот функционал вкратце, хотелось бы исправить и дополнить свои слова. Многоуровневая компиляция ускоряет время запуска вашего решения, но вы жертвуете тем, что части вашего кода будут компилироваться в более оптимизированную версию в фоне, что может привести к небольшим накладным расходам. С приходом NET Core 3.0 уменьшилось время сборки проектов с включенным tier compilation и пофиксили баги связанные с этой технологий. Раньше эта технология приводила к ошибкам первых запросов в ASP.NET Core и к подвисанию при первой сборке в режиме многоуровневой компиляции. На данный момент в .NET Core 3.0 она включена по умолчанию, но вы можете её отключить по желанию. Если вы находитесь на должности team-lead, senior, middle или вы руководитель отдела то, должны понимать что быстрая разработка проекта увеличивает ценность команды и данная технология позволит вам экономить время как разработчиков, так и само время работки проекта.
.NET level up
Повышайте версию вашего .NET Framework / .NET Core. Зачастую, каждая новая версия дает дополнительный прирост к производительности и добавляет новые фичи.
Но какие именно преимущества? Давайте рассмотрим некоторые из них:
- В .NET Core 3.0 появилось R2R образы, которые позволят снизить время запуска .NET Core приложений.
- С версии 2.2 появилась Tier Compilation, благодаря которой программисты будут тратить меньше времени запуск проекта.
- Поддержка новых стандартов .NET Standard.
- Поддержка новой версии языка программирования.
- Оптимизация, с каждой новой версией улучшается оптимизация базовыми библиотеками Collection/Struct/Stream/String/Regex и много чего ещё. Если вы переходите с .NET Framework на .NET Core, вы получите большой прирост к производительности из коробки. Для примера прикрепляю ссылку на часть оптимизаций которые были добавлены в .NET Core 3.0: https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-core-3–0/

Заключение
При написание кода стоит уделять внимание разным аспектам вашего проекта и использовать функции вашего языка программирования и платформы для достижения наилучшего результата. Буду рад если вы поделелитесь своими знаниями связанными с оптимизацией в .NET.
Ссылка на github
