Perf и flamegraphs

Огромную популярность набирает тема повышения производительности операционных систем и поиска узких мест. В этой статье мы расскажем об одном инструменте для поиска этих самых мест на примере работы блочного стека в Linux и одного случая траблшутинга работы хоста.
Пример 1. Тестовый
Ничего не работает
Тестирование в нашем отделе ― это синтетика на продуктовом железе, а позже ― тесты прикладного ПО. К нам на тестирование поступил диск Intel Optane. Ранее о тестировании дисков Optane мы уже писали в нашем блоге.
Диск был установлен в сервер стандартной комплектации, собранный относительно давно под один из облачных проектов.
Во время тестирования диск показал себя не лучшим образом: при тесте с глубиной очереди в 1 запрос в 1 поток, блоками в 4Кбайта около ~70Kiops. А это значит, что время ожидания ответа огромно: примерно 13 микросекунд на запрос!
Странно, ведь спецификация обещает «Latency ― Read 10 µs», а у нас получилось на 30% больше, разница довольно существенная. Диск переставили в другую платформу, более «свежей» сборки, используемую в другом проекте.
Почему оно работает?
Забавно, но диск на новой платформе заработал как надо. Производительность увеличилась, время ожидания уменьшилось, CPU в полку, в 1 поток в 1 запрос, 4Кбайта блоками, ~106Kiops при ~9 микросекунд на запрос.
И тут самое время сравнить настройки достать из широких штанин perf. Ведь нам интересно, почему так? При помощи perf можно:
- Снимать показатели аппаратных счетчиков: количество вызовов инструкций, кэш-промахов, неверно предсказанных ветвлений и т.п. (PMU events)
- Снимать информацию со статических трейспоинтов, количество вхождений
- Проводить динамическую трассировку
Для проверки мы воспользовались CPU sampling.
Суть в том, что perf может собрать весь стэк трейс запущенной программы. Естественно, запущенный perf будет вносить задержку в работу всей системы. Но у нас есть флаг -F #, где # ― частота сэмплирования, измеряемая в Гц.
Тут важно понимать, что чем выше частота сэмплирования, тем больше шансов поймать вызов какой-то конкретной функции, но тем больше тормозов работа профайлера вносит в систему. Чем меньше частота, тем больше шансов, что часть стека мы не увидим.
При выборе частоты нужно руководствоваться здравым смыслом и одной хитростью — стараться не выставлять четную частоту, чтобы не попасть в ситуацию, когда в сэмплы попадет какая-то работа, выполняющаяся по таймеру с этой частотой.
Ещё один момент, который поначалу вводит в заблуждение ― ПО должно быть собрано с флагом -fno-omit-frame-pointer, если это, конечно, возможно. Иначе в трейсе вместо названий функций мы увидим сплошные значения unknown. Для некоторого ПО отладочные символы идут отдельным пакетом, например, someutil-dbg. Рекомендуется установить их перед запуском perf.
Нами были выполнены следующие действия:
- Взят fio из git://git.kernel.dk/fio.git, тэг fio-3.9
- В Makefile к CPPFLAGS добавлена опция -fno-omit-frame-pointer
- Запущен make -j8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
Опция -g нужна для захвата стек трейсов.
Посмотреть полученный результат можно командой:
perf report -g fractal
Опция -g fractal нужна для того, чтобы проценты, отражающие количество сэмплов с этой функцией и показываемые perf, были относительны вызывающей функции, количество вызовов которой берется за 100%.
Ближе к концу длинного стека вызовов fio на платформе «свежей сборки» мы увидим:
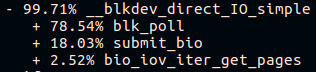
А на платформе «старой сборки»:

Отлично! Но хочется красивых флеймграфов.
Построение флеймграфов
Чтобы было красиво, есть два инструмента:
- Относительно более статический flamegraph
- Flamescope, который дает возможность из собранных сэмплов выбрать конкретный отрезок времени. Это очень полезно, когда искомый код нагружает CPU короткими всплесками
Эти утилиты принимают на вход вывод perf script > result.
Скачиваем result и отправляем его через пайпы в svg:
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
Открываем в браузере и наслаждаемся кликабельной картинкой.
Можно использовать другой способ:
- Добавляем result в flamescope/example/
- Запускаем python ./run.py
- Заходим через браузер на 5000 порт локального хоста
Что мы видим в итоге?
Хороший fio проводит много времени в поллинге:

А плохой fio проводит время где угодно, но только не в поллинге:
С первого взгляда кажется, что на старом хосте не работает поллинг, но везде стоит ядро 4.15 одной сборки и поллинг по умолчанию включен на NVMe-дисках. Проверить, включен ли поллинг, можно в sysfs:
# cat /sys/class/block/nvme0n1/queue/io_poll
1
Во время тестов используются вызовы preadv2 с флагом RWF_HIPRI ― необходимое условие для работы поллинга. И, если внимательно изучить флеймграф (или предыдущий скриншот из вывода perf report), то его можно найти, но он занимает совсем незначительный промежуток времени.
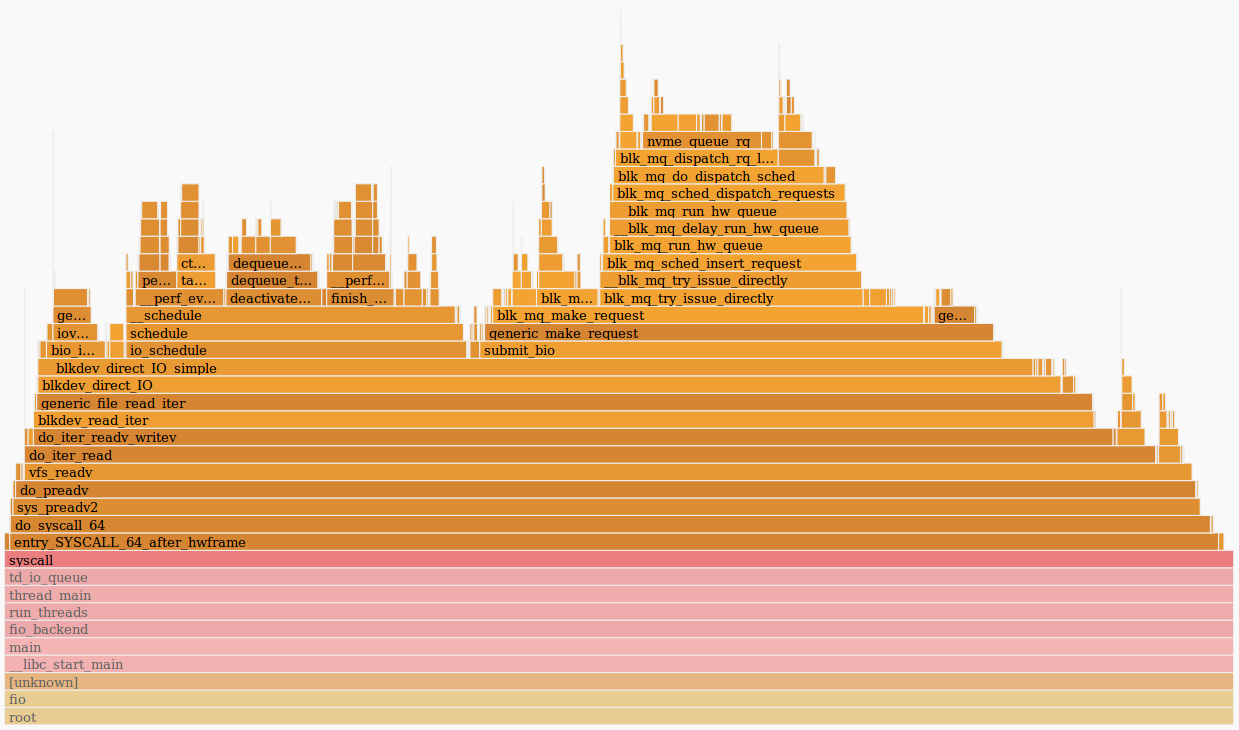
Второе, что видно ― это отличающийся стек вызовов у функции submit_bio () и отсутствие вызовов io_schedule (). Посмотрим поближе на разницу внутри submit_bio ().
Медленная платформа «старой сборки»:

Быстрая платформа «свежей»:

Похоже, что на медленной платформе запрос проходит долгий путь до устройства, заодно попадая в планировщик kyber. О планировщиках ввода/вывода подробнее можно прочитать в нашей статье.
Как только kyber был выключен, тот же тест fio показал среднее время ожидания около 10 микросекунд, прямо как заявлено в спецификации. Отлично!
Но откуда разница еще в одну микросекунду?
А если чуть глубже?
Как уже было сказано, perf позволяет собирать статистику с аппаратных счетчиков. Попробуем посмотреть количество кэш-промахов и инструкций на цикл:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


Из результатов видно, что быстрая платформа выполняет больше инструкций на цикл CPU и имеет больший процент кэш-промахов при выполнении. Вдаваться в детали работы разных аппаратных платформ в рамках этой статьи мы, конечно, не будем.
Пример 2. Продуктовый
Что-то идет не так
В работе распределенной системы хранения данных был замечен рост нагрузки на CPU на одном из хостов при росте входящего трафика. Хосты равноправные, равнозначные и имеют идентичные аппаратное и программное обеспечение.
Рассмотрим как выглядит нагрузка на CPU:
~# pidstat -p 1441734 1
Linux 3.13.0-96-generic (lol) 10/10/2018 _x86_64_ (24 CPU)
09:23:30 PM UID PID %usr %system %guest %CPU CPU Command
09:23:44 PM 0 1441734 23.00 1.00 0.00 24.00 4 ceph-osd
09:23:45 PM 0 1441734 85.00 34.00 0.00 119.00 4 ceph-osd
09:23:46 PM 0 1441734 0.00 130.00 0.00 130.00 4 ceph-osd
09:23:47 PM 0 1441734 121.00 0.00 0.00 121.00 4 ceph-osd
09:23:48 PM 0 1441734 28.00 82.00 0.00 110.00 4 ceph-osd
09:23:49 PM 0 1441734 4.00 13.00 0.00 17.00 4 ceph-osd
09:23:50 PM 0 1441734 1.00 6.00 0.00 7.00 4 ceph-osd
Проблема возникла в 09:23:46 и мы видим, что процесс работал в пространстве ядра исключительно в течении всей секунды. Посмотрим на то, что происходило внутри.
Почему так медленно?
В данном случае мы сняли сэмплы со всей системы:
perf record -a -g -- sleep 22
perf script > perf.results
Опция -a нужно здесь для того, чтобы perf снимал трейсы со всех CPU.
Откроем perf.results при помощи flamescope, чтобы отследить момент повышенной нагрузки на CPU.

Перед нами «тепловая карта», обе оси (X и Y) которой представляют собой время.
По оси X пространство разбито на секунды, а по оси Y ― на отрезки по 20 миллисекунд в пределах секунд X. Время идет снизу вверх и слева направо. Наиболее яркие квадраты имеют наибольшее количество сэмплов. То есть, CPU в это время работал активнее всего.
Собственно, нас интересует красное пятно посередине. Выделяем его мышкой, кликаем и смотрим, что оно скрывает:
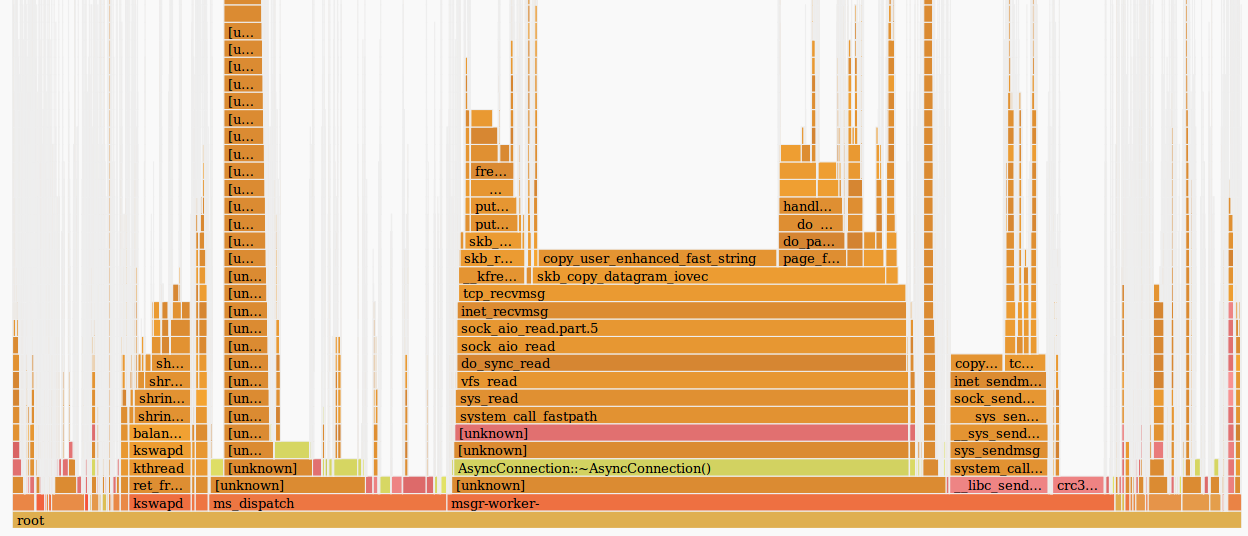
В целом, уже видно, что проблема заключается в медленной работе tcp_recvmsg и skb_copy_datagram_iovec в ней.
Для наглядности сравним с сэмплами другого хоста, на котором тот же объем входящего трафика не вызывает проблем:
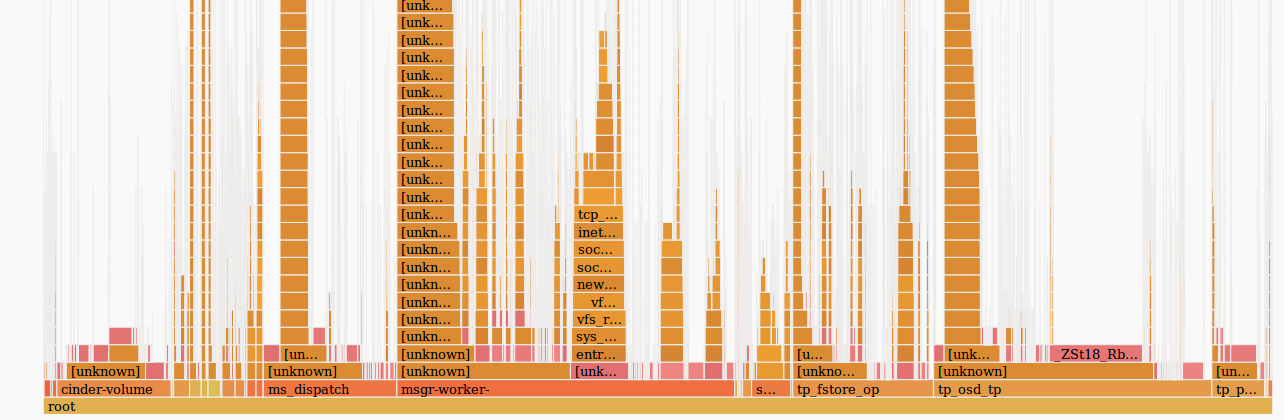
Исходя из того, что мы имеем одинаковое количество входящего трафика, идентичные платформы, которые работают уже длительное время без остановки, можно предположить, что проблемы возникли на стороне железа. Функция skb_copy_datagram_iovec копирует данные из структуры ядра в структуру в пространстве пользователя, чтобы передать дальше приложению. Вероятно, имеются проблемы с памятью хоста. При этом, в логах ошибок нет.
Перезапускаем платформу. При загрузке BIOS видим сообщение о битой планке памяти. Замена, хост стартует и проблема с перегруженным CPU больше не воспроизводится.
Постскриптум
Производительность системы с perf
Вообще говоря, на загруженной системе запуск perf может внести задержку в обработку запросов. Размер этих задержек зависит в том числе и от нагрузки на сервер.
Попробуем найти эту задержку:
~# /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
fio-3.9-dirty
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=413MiB/s][r=106k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=109786: Wed Dec 12 17:25:56 2018
read: IOPS=106k, BW=414MiB/s (434MB/s)(4096MiB/9903msec)
clat (nsec): min=8161, max=84768, avg=9092.68, stdev=1866.73
lat (nsec): min=8195, max=92651, avg=9127.03, stdev=1867.13
…
~# perf record /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
fio-3.9-dirty
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=413MiB/s][r=106k IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=109839: Wed Dec 12 17:27:50 2018
read: IOPS=106k, BW=413MiB/s (433MB/s)(4096MiB/9916msec)
clat (nsec): min=8259, max=55066, avg=9102.88, stdev=1903.37
lat (nsec): min=8293, max=55096, avg=9135.43, stdev=1904.01
Разница не сильно заметна, всего около ~8 наносекунд.
Посмотрим, что будет, если увеличить нагрузку:
~# /root/fio/fio --clocksource=cpu --name=test --numjobs=4 --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
...
fio-3.9-dirty
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=1608MiB/s][r=412k IOPS][eta 00m:00s]
~# perf record /root/fio/fio --clocksource=cpu --name=test --numjobs=4 --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=pvsync2, iodepth=1
...
fio-3.9-dirty
Starting 4 processes
Jobs: 4 (f=4): [r(4)][100.0%][r=1584MiB/s][r=405k IOPS][eta 00m:00s]
Здесь разница уже становится заметна. Можно сказать, что система замедлилась менее чем на 1%, но по существу потеря около 7Kiops на высоконагруженной системе может привести к проблемам.
Понятно, что данный пример синтетический, тем не менее он весьма показательный.
Попробуем запустить еще один синтетический тест, который вычисляет простые числа ― sysbench:
~# sysbench --max-time=10 --test=cpu run --num-threads=10 --cpu-max-prime=100000
...
Test execution summary:
total time: 10.0140s
total number of events: 3540
total time taken by event execution: 100.1248
per-request statistics:
min: 28.26ms
avg: 28.28ms
max: 28.53ms
approx. 95 percentile: 28.31ms
Threads fairness:
events (avg/stddev): 354.0000/0.00
execution time (avg/stddev): 10.0125/0.00
~# perf record sysbench --max-time=10 --test=cpu run --num-threads=10 --cpu-max-prime=100000
…
Test execution summary:
total time: 10.0284s
total number of events: 3498
total time taken by event execution: 100.2164
per-request statistics:
min: 28.53ms
avg: 28.65ms
max: 28.89ms
approx. 95 percentile: 28.67ms
Threads fairness:
events (avg/stddev): 349.8000/0.40
execution time (avg/stddev): 10.0216/0.01
Здесь видно, что даже минимальное время обработки увеличилось на 270 микросекунд.
Вместо заключения
Perf ― очень мощный инструмент для анализа производительности и отладки работы системы. Однако, как и с любым другим инструментом, нужно держать себя в руках и помнить, что любая нагруженная система под пристальным наблюдением работает хуже.
Ссылки по теме:
