Пережить распродажу на Ozon: хайлоад, сковородки и 38 инфарктов
Мы нечасто задумываемся о том, как работает тот или иной сервис и какой объём работ скрывается за тем, чтобы товар или услуга прибыли к нам вовремя. Взять, например, «чёрную пятницу» и День холостяка в e-com — дни самых больших распродаж. Казалось бы, что там такого? Со стороны может выглядеть, что главное — прогреть аудиторию предложениями разной степени заманчивости и запастись товарами на складах. Конечно, это не так. На деле нескольким дням распродаж предшествует год активной подготовки: от прогнозирования нагрузки и закупки железок до перестройки архитектуры. О том, на что мы обращали внимание и как готовились к высокому сезону, читайте под катом.

План — это список того, что может пойти не по плану
Немного контекста:
Высокий сезон для нас, как и для всего e-com, — это период c сентября по январь. В статье речь пойдёт о ноябрьских распродажах 2021 года — 11 и 26 ноября. Наша цель — пережить наплыв покупателей без ухудшения качества сервиса.
Хайлоад в Ozon не пустые слова: на пике мы получали 5к заказов в минуту и 38к RPS.
Подготовка к сезону
Подготовку с точки зрения оптимизаций, переписываний кода и распиливаний монолитов мы начали после новогодних каникул: собирались десятками команд, искали узкие места, каждую неделю проводили нагрузочное тестирование и анализировали результаты.
Стоит отметить, что мы немного отбитые и стреляем по продакшену. Почему так? Потому что только такой подход даёт максимальную репрезентативность результатов нагрузочного тестирования. Строить отдельный контур, полностью повторяющий продакшен, по которому можно пострелять, не боясь навредить продакшнену, слишком дорого, ведь у нас он состоит из тысяч серверов. Стрелять в какую-то уменьшенную копию продакшена и умножать результаты на некий коэффициент, надеясь, что если в продакшене в 20 раз больше серверов, то и его производительность в 20 раз выше, — самообман, потому что на больших масштабах проявляются самые разные спецэффекты. Если бы масштабирование работало именно так (увеличить в 20 раз количество серверов — и получить возможность выдерживать в 20 раз больше нагрузки), мы бы вообще не занимались подготовкой к сезону, а просто покупали серверы.
Чем ближе к сезону (сентябрю), тем подготовка шла активнее и тем больше накала страстей было в чатах.
В начале года казалось, что времени ещё много и мы всё успеваем: были чёткие планы, сроки и ощущение спокойствия. А потом, как обычно бывает в IT, всё начинает ехать, сроки сдвигаются, а ты понимаешь, что сезон неизбежен, как крах империализма.
Этапы подготовки
0. Capacity planning — планирование мощности
Планирование нагрузки в сезон мы начали за год — в конце 2020 года. Нам необходимо предсказать таргет по RPS и количество заказов в единицу времени. Происходит это примерно так:
Анализируем исторические данные. Мы понимаем, как нагружена наша система в разрезе каждого отдельного кластера, и знаем исторический тренд роста нагрузки: система мониторинга собирает огромное количество метрик с других систем и хранит историю за всё время своего существования.
Получаем от коллег из других отделов прогноз количества заказов. Обрабатываем эту информацию: например, мы получили количество заказов в виде суммарного значения по месяцам, а нам нужно построить график заказов по часам и минутам, чтобы найти моменты пиковой нагрузки.
Строим модель, в которой скрещиваем бизнесовый прогноз и исторические данные. На выходе мы получаем математическую модель зависимости ядер и памяти от заказов и других переменных. А дальше из этой модели мы строим прогноз для каждого кластера и вычисляем, сколько железа нам потребуется, чтобы пережить пиковые нагрузки.
В течение года мы несколько раз пересчитываем прогноз: сверяем таргет с трендом, как мы идём в течение года. Чем ближе к сезону, тем больше имеем данных для корректировки прогноза.
1. Бюджетирование
Благодаря планированию мы понимаем, сколько нам нужно железок и денег на них, — и начинаем закупку. Спойлер: не просчитались.
2. Стрельбы круглый год
Пока железо ехало к нам, мы готовились к сезону. В декабре 2020 года начали обстреливать сайт и мобильное приложение: запускали нагрузочное тестирование каждую ночь, чтобы узнать, какой RPS можем выдержать. В стресс-тестах отталкивались от предсказанного таргета в RPS.
После стрельб собирались с руководителями IT-команд и обсуждали обнаруженные узкие места и способы их устранения, чтобы улучшить перформанс:
Делали шардирование баз для ряда сервисов маркетплейса.
Со стороны платформы оптимизировали библиотеку для работы с PostgreSQL (это стреляло в некоторых сервисах, которые интенсивно читают базу данных или пишут в неё).
В K8s выделили изолированные ядра под сетевое взаимодействие — это уменьшило задержки при обмене сообщениями между сервисами.
Дорабатывали логику в отдельных сервисах: добавляли кеши, оптимизировали код и SQL-запросы, увеличивали количество ресурсов под сервисами и их базами данных и внедряли ещё миллиард разного рода ухищрений и ноу-хау.
Готовили graceful-деградацию, чтобы даже в случае невозможности выдержать весь объём нагрузки мы были готовы жертвовать функционалом постепенно и управляемо.
Помимо общего таргета для стрельб по сайту, есть прогнозы для отдельных сервисов: их владельцы независимо от большого теста делают свои стресс-тесты отдельно. Это нужно, чтобы они могли готовиться к высокому сезону независимо от общего теста: они заранее знают свой таргет в RPS и стреляют по сервису, даже если общий стресс-тест в него пока не упирается.
Этот процесс длился весь год. При первых попытках мы не выдерживали прогнозируемую нагрузку — и постоянно улучшали инфраструктуру, допиливали сервисы. В конце лета мы уже выдерживали таргет и чувствовали себя спокойнее. Но в этом деле главное не расслабляться, потому что всегда есть вероятность отката из-за изменений — параллельную деятельность с бизнесовой разработкой никто не отменял.
Мы посмотрели на это и подумали:
«Отличный план, надёжный, как швейцарские часы».
Что могло пойти не так?
Кейс #1. Мы ожидали нагрузку по RPS, а получили 5К заказов в минуту
Нагрузка выросла в пять раз — здесь бизнесовые показатели очень чётко коррелируют с нагрузкой на IT. Наш таргет по RPS на высокий сезон был 62,5К для композера — это сервис, который формирует ответ от сайта и мобильных приложений; он ходит в кучу других сервисов и отдаёт информацию пользователю. Для остальных сервисов прогноз вычислялся пропорционально.
Но во время распродаж мы видели максимум 38K RPS. При этом с точки зрения количества заказов мы попали в прогноз — 5К заказов в минуту.
Нельзя сказать, что мы перезаложились в таргете по RPS. На самом деле нам повезло: в период распродажи конверсия трафика в заказы была значительно выше предполагаемой. Мы ориентировались на показатель предыдущего года, а в 2021 году при меньшем количестве запросов мы уже получили так много заказов — и, если честно, были счастливы, что нагрузка при этом выросла не так сильно (хоть и были готовы к большему).
Конверсия в заказ была сильно выше обычной, потому что было проделано много подготовительной работы. Более 40 000 продавцов приняли участие в акции, а со стороны маркетинга два месяца крутили рекламу и баннеры, заранее показывая, какие товары будут доступны на распродаже: люди знали и даже положили в корзину, что хотели купить.
Из этого кейса мы сделали вывод: в capacity planning для следующего высокого сезона нужно улучшить алгоритмы подсчёта таргета — теперь учитываем ещё и конверсию.
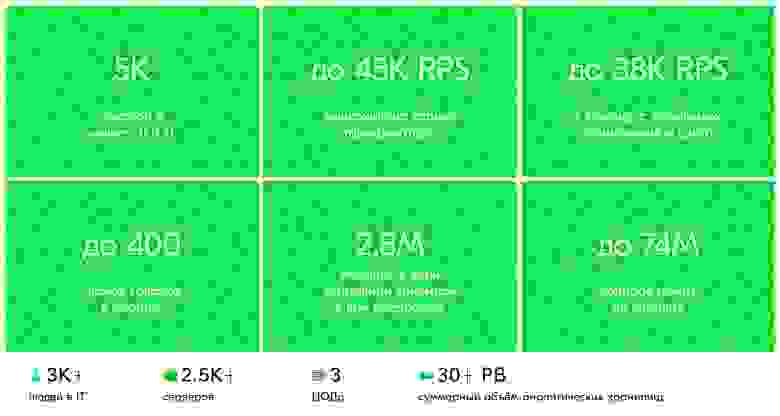 Высокий сезон Ozon Tech 2021 года в цифрах. Тарификатор — один из самых высоконагруженных сервисов.
Высокий сезон Ozon Tech 2021 года в цифрах. Тарификатор — один из самых высоконагруженных сервисов.
Кейс #2. Инцидент с падением до распродажи
Это было самое неожиданное — мы чуть не умерли до старта распродаж. 10 ноября (за день до Дня холостяка) открылась распродажа для владельцев Premium-подписки. Мы собрались в переговорке: смотрели на графики, готовились к пику заказов. Ещё ничего не росло — ни трафик, ни количество заказов — и вдруг в 23:50, за десять минут до начала, у нас умер один из сервисов — SLA-бэкенд (сервис, который отдаёт SLA комплектации заказов на складах). Из-за этого немного просела скорость принятия заказов. Было обидно: ещё ничего толком не началось, а нам уже плохо. Всё быстро починили (обнаружился специфичный баг в коде — сервис зациклился на аллокациях и начал потреблять все выделенные ему ядра), но осадок остался.
Кейс #3. Как мониторинг положили сами разработчики
Ещё один ироничный случай произошёл, когда наши же разработчики своими руками обеспечили нам хайлоад.
У нас устоявшаяся и хорошо развитая инфраструктура мониторинга, на которую многие рассчитывают. В момент начала распродажи 11 ноября сотрудники из разных направлений стали открывать различные дашборды — как базовые, которые оптимизированы и проверены, так и свои личные. При этом при создании кастомных графиков разработчики не всегда задумываются о том, тяжёлые там запросы или лёгкие.
Разработчики начали активно обновлять дашборды и брать данные за большой период времени: кто-то смотрел графики за 30 минут, а кто-то — за три года. Из-за этого поднималось огромное количество данных (метрик), мы быстро достигли потолка по in-flight-запросам, а так как их количество не уменьшалось, они просто выстроились в очередь и начали отваливаться по тайм-ауту.
Нагрузка на систему мониторинга в тот момент выросла в пять раз. Графики начали дико лагать и грузиться через раз, что спровоцировало панику и ещё большее количество обновлений и открытий новых вкладок. Сбор метрик работал, но посмотреть их удавалось только счастливчикам. Быстрым решением для нас стало докинуть ресурсов и отключить возможность запрашивать данные из long-term-хранилища.
В затишье между распродажами мы настроили стресс-тесты и понагружали систему мониторинга точно так же, как делали с сайтом. В результате мы ещё немного потюнили инфраструктуру, добавили шардов — и уже в «чёрную пятницу» всё прошло гладко.
Вывод сделали такой: впредь будем готовить не только микросервисы к нагрузке, но и инфраструктуру для наших разработчиков.
Кейс #4. Сон — для слабаков
Конечно, для мониторинга и решения возникающих инцидентов мы составляли графики дежурств на все дни (и ночи) распродаж: на три дня для распродажи 11 ноября и на три дня для распродажи 26 ноября. Дежурными побывали несколько сотен человек.
Помимо премий за ночные смены, ребятам дарили мерч и готовили ланч-боксы для каждой дежурной смены.






В основном дежурные работали в офисе. Это не только про доступность людей и скорость реакции, но и про ощущение, что мы все вместе делаем одно большое дело. Кстати, дежурили не только IT-специалисты, но и коллеги из маркетинга, операций, коммерции и других функций. Было что-то объединяющее в том, как люди вместе смотрели на графики и тушили инциденты плечо к плечу, превозмогая сон (лично я, кажется, вообще не спал на всём протяжении распродаж), дружно жаловались в чатах, что ночной уборки в офисе не хватает или что ланч-боксы недостаточно разнообразны.
Для многих дежурных такой опыт остаётся значимым событием в памяти — мы даже раздаём специальные ачивки в профиле на корпоративном портале.

Кейс #5. Кастрюли и 30 тонн муки
Мы заметили интересный паттерн поведения: некоторые пользователи вообще ничего не искали на сайте, а просто приходили и сразу оформляли заказ. Это происходило по двум причинам:
Мы заранее подогревали внимание к распродажам — и у пользователей уже были набиты корзины.
Мы вкидывали хаммеры — товары с крайне привлекательной ценой, но в ограниченном количестве.



В День холостяка хаммеры разошлись слишком быстро — и коллеги из команды коммерции договаривались с продавцами, что ещё можно докинуть.
В какой-то момент возникла проблема с хаммером, а пока её решали, его уже распродали. А ещё почему-то у нас стали тотемными сковородки в День холостяка и кастрюли в «чёрную пятницу».
Сам я ничего из хаммеров не успел купить: в момент каждого вброса я лихорадочно смотрел в миллион графиков и сидел на звонке с инженерами. В один из вбросов я очень хотел купить те самые тотемные кастрюли, но мне не удалось, потому что я открыл страницу, отвлёкся на графики — пик есть, вроде всё нормально и не тормозит —, а когда вернулся к кастрюлям, их уже не было.
К слову, среди самых популярных товаров были тушь, кофе и сироп, самый дорогой заказ стоил 444 000 рублей (царь-холодильник, не спрашивайте). И особенно нас удивило, что 30 тонн муки раскупили за один час (крупная сеть магазинов столько продаёт за день).
Кейс #6. Держать хайлоад и не попасть на HighLoad++
Иронично, что именно в «чёрную пятницу» должна была проходить конференция HighLoad++, на которой нам есть что посмотреть и рассказать. Мы не могли позволить себе отпустить на неё ни спикеров, ни слушателей — все сидели и работали. А в итоге мероприятие перенесли из-за того-что-нельзя-называть (или потому что мы не могли прийти? :)) Но мы не сильно расстраивались, потому что в эти дни самый настоящий хайлоад был у нас: никто в истории российского e-com’a не продавал столько за один день.
Так что наши инженеры всё же рассказали о пережитом: этом и этом.
Заключение
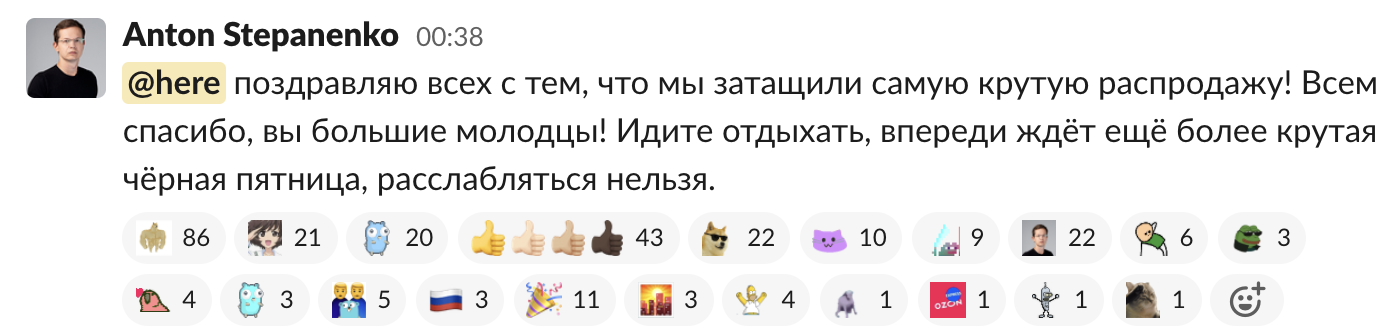
Мы затащили самую большую распродажу российского e-com«а — это было сложно и круто одновременно. Не всё было идеально, но это значит только то, что надо готовиться к высокому сезону ещё усерднее.
Мы сделали самые большие продажи на рынке, кратно (почти в четыре раза) выросли к предыдущему году, мне даже хочется написать «совершили невозможное».
Конечно, это не просто везение или случайность. Было проделано много работы — и мы получили заслуженный результат. Мы дежурили, смотрели в графики, чинили баги на лету, тушили инциденты, не спали, не ели, не пили, временами было нервно и напряжённо — за эти распродажи я получил 38 инфарктов, но мы это сделали! Считаю, что это уникальный опыт, которым можно гордиться. Огромная благодарность всей команде за то, что сделали это возможным!
А мы уже вовсю готовимся к сезону 2022. Встретимся на распродажах — летний фестиваль скидок уже близко ;)
