Переводчик из машины, или как научить МФУ переводить документы
Привет, %username%!
Недавно мы, ABBYY LS, совместно с Xerox запустили Xerox Easy Translator Service — сервис, который позволяет получить машинный перевод документа — для этого его нужно отсканировать при помощи МФУ на базе технологии Xerox ConnectKey или же сфотографировать камерой телефона. Через эту же платформу можно заказать и профессиональный перевод.
Как это работает? Давай разбираться!

Пользователь сканирует, фотографирует или загружает готовый файл через Web. Файл сохраняется в базе, после чего начинается его разбор на сегменты — объекты, хранящие фрагменты текста (как правило, это предложения), и информацию о верстке этих фрагментов. Файлы в графических форматах предварительно распознаются при помощи ABBYY Recognition Server. Перед отправкой документа на распознавание мы спрашиваем пользователя, на каком языке написан документ. Изображение может быть распознано и без этого, однако указание языка исходного документа позволит распознать его быстрее и качественнее.
В процессе интеграции с Recognition Server нам нужно было выбрать параметры обработки для нашего потока документов: формат экспорта результатов, подходящее для нас соотношение скорость\качество распознавания, тип сборки документа.
В качестве формата экспорта сейчас мы используем «старичка» .doc, так как на данный момент он наиболее полно описывает Rich-текст и при этом решает ряд проблем, связанных с компоновкой элементов на странице при сегментации (привет, .docx!). Тем не менее, переход на .docx в планах есть. Соотношение между скоростью и качеством вызывало больше всего споров. С одной стороны, качество распознавания — наивысший приоритет для машинного перевода документа, так как весь процесс автоматизирован, и нет возможности привлекать специалистов по верстке. С другой стороны, основное преимущество MT (machine translation) — скорость (особенно в сценарии, когда пользователь ждет распечатанный перевод возле МФУ), а за скорость приходится платить качеством. Тем не менее, выбор был сделан в пользу качества.
Тип сборки документа определяет то, какие элементы исходного документа попадут в файл с результатом. Можно ограничить результат распознавания plain-текстом (этот вариант нам не подходит, так как важная для понимания контекста нетекстовая информация будет утеряна), можно сохранить форматирование этого текста (уже лучше, но как быть с важной не текстовой информацией?). Тип Editable Copy сохраняет текст с форматированием и нетекстовый контент, но без привязки к страницам. Казалось бы, нарушается компоновка страниц — и это минус. Но так как при переводе длина слов может значительно меняться (например, немецкий перевод слова «дружба» — «Freundschaftsbezeigungen»), отсутствие привязки к страницам исходного файла позволяет избегать ситуаций, когда блоки с текстом «наезжают» на другие элементы страницы, а также когда текст перевода нельзя вписать в размеры блока исходного текста. Последний вариант Exact Copy сохраняет и текст с форматированием, и нетекстовый контент. На выходе мы имеем документ, максимально приближенный к оригиналу с точки зрения постраничной компоновки. Такой вариант выглядит более цельным с точки зрения форматов, поддерживающих постраничный вывод (pdf, djvu), но перевод может оказаться «за бортом». В итоге мы сделали выбор в пользу Editable Copy.
Исходный текст

Пример Exact Copy

Пример EditableCopy

Далее распознанный файл проходит уже упомянутую сегментацию, а для сегментов, составляющих первую 1000 символов документа, выполняется автоматическое определение языка текста. Несмотря на то, что мы уже попросили пользователя указать язык документа при загрузке файла, мы всё равно проводим авто-определение, так как при работе через API задание языка необязательно для графических форматов, и необязательно совсем при загрузке документов текстовых форматов. Зная язык, мы можем подсчитать статистику по документу: количество страниц, слов, символов. После этого сервис направляет блоки сегментов документа через API машинного перевода (MT-API) в один из нескольких движков МТ. По завершению перевода документ собирается, а пользователю направляется уведомление.
Пример машинного перевода:
Исходное изображение

Результат

Хочу отметить, что, несмотря на то, что технология машинного перевода еще сильно уступает по качеству профессиональному, она отлично справляется с задачей быстрого перевода больших объемов информации, когда требуется понимание общих положений документа. Другой частотный сценарий — понимание релевантных кусков исходного текста, которые потом можно перевести более тщательно. Тем не менее, мы предпринимаем шаги для улучшения качества машинного перевода за счет использования баз памяти перевода, о которых мы поговорим чуть ниже.
Если пользователю необходим более качественный перевод, он может сделать заказ профессиональным переводчикам. В этом случае путь файла будет немного другой:
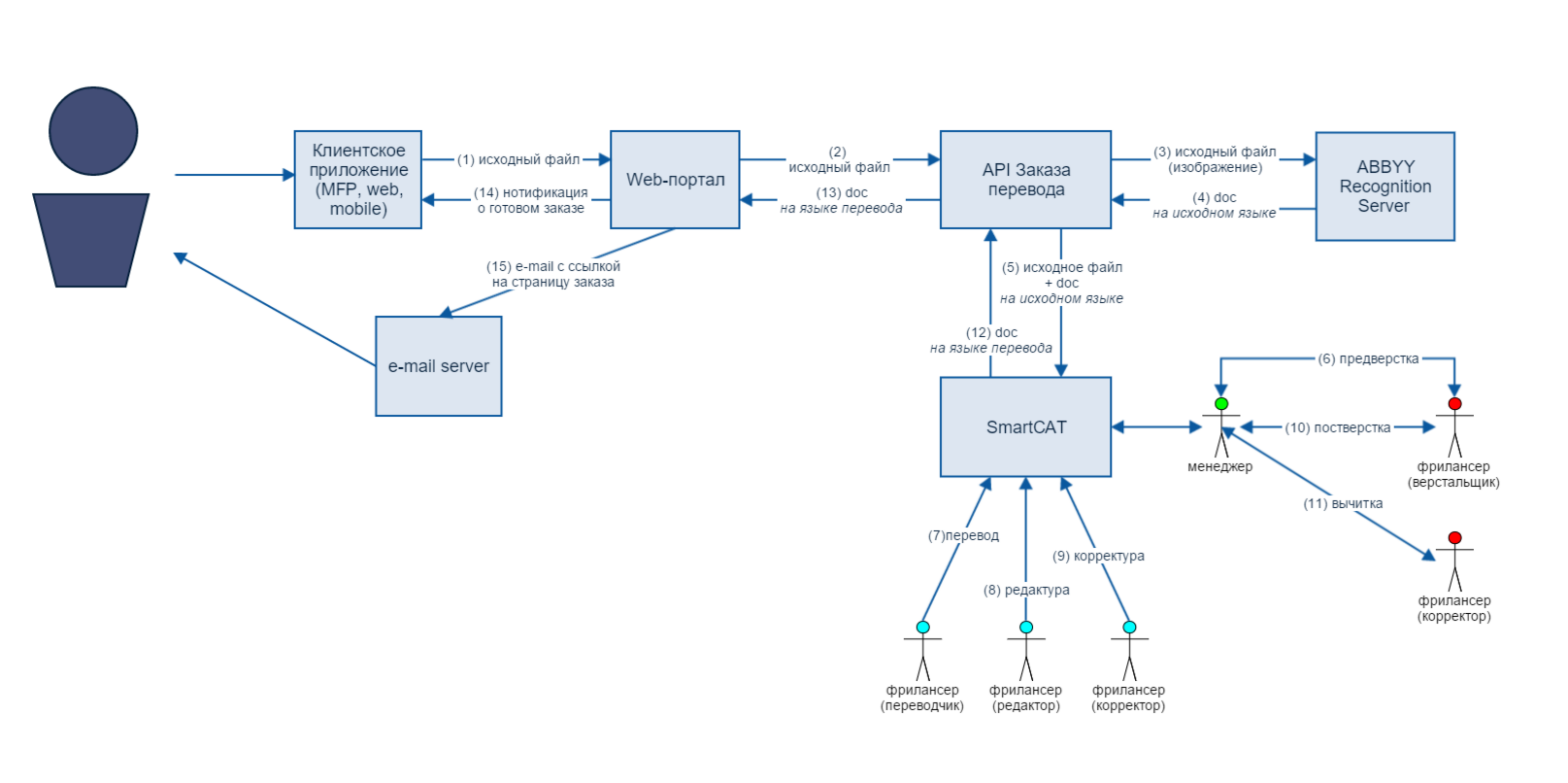
Текст, который получился в результате распознавания на Recognition Server, вместе с исходным документом направляется в SmartCAT — платформу для автоматизации процесса перевода. Исходный файл нужен для того, чтобы при переводе был доступен нетекстовый контент, который может содержать информацию, важную для сохранения контекста перевода. Но прежде чем документ попадает к самому переводчику, менеджер проверяет, нужна ли ему предварительная верстка, и в случае необходимости привлекает специалистов по верстке. Только потом назначаются исполнители. Непосредственно в редакторе переводчик имеет доступ как к движкам машинного перевода, так и к базам Translation Memory (памяти перевода), что позволяет сокращать время работы над документом. Когда перевод завершен, он редактируется, вычитывается и еще раз проверяется менеджером. И вот перевод завершен, а пользователь получает оповещение по почте и файл с высококлассным результатом.
Пример перевода:
Исходное изображение

Результат

Как всё это устроено внутри? Хороший вопрос!

Вы любите слоеные торты? Мы любим, и инфраструктуру нашего приложения можно представить в виде такого тортика:

Каждый кусок составляют dll-сборки, реализующие конкретную фичу (feature), например, FileManagement — управление файлами. Также библиотеки разделяются по слоям: Контракты, Web API, Data Storage, Task Processing. При разделении был реализован принцип CQRS — command-query responsibility segregation, согласно которому метод должен быть либо командой, выполняющей какое-то действие, либо запросом, возвращающим данные, но не одновременно. Другими словами, задавание вопроса не должно менять ответ (wiki).
Контракты
В контрактной сборке хранятся интерфейсы, по которым взаимодействуют модули приложения, а также команды и запросы, которыми оперирует описываемая фича. Эти сборки используются другими слоями того же набора функциональности (на примере управления файлами это FileManagement.Api и FileManagement.Processing) и другими фичами (управление заказами использует управление файлами).
Web API
Тут всё просто — метод API, вызываемый потребителем, инициирует выполнение команд, запросов, либо их комбинаций, и отдает результат выполнения пользователю.
Data Storage
Хранение данных. Сборка подписывается на выполнение команд и запросов определенных типов и осуществляет изменение или чтение данных. Мы используем для этих целей MongoDB, но так как работа с данными осуществляется через команды и запросы, остальные (не Data Storage) сборки могут только догадываться о документальной сущности базы.
Task Processing
Выполнение длительных операций. Как и сборка хранения данных, эта сборка подписывается на вызов определенных команд, однако реальное время начала обработки такой команды регулируется планировщиком. Такие команды называются задачами. Разбор файла на сегменты — одна из таких задач.
Дерево всего проекта при этом выглядит так:

Подобное разделение на слои и фичи позволяет достаточно гибко наращивать функциональность нашего тортика приложения, добавляя всё новые и новые вкусные полезные возможности.
А на сегодня всё, до новых встреч.
