Перевод с программистского: как убедить бизнес инвестировать в технику
При разработке приложений, в частности — продуктовой, каждый программист, архитектор или тестировщик понимает важность технических инвестиций и наличия стратегии гашения технического долга. Бизнес, особенно тот, который хочет считать себя передовым, модным и молодежным, тоже знаком с этими понятиями и даже иногда использует.
В нашей компании ресурсы на разработку распределяются в пропорции 80% на продуктовые задачи и 20% — на технические (на самом деле чуть сложнее, т.к. зависит от «зрелости» продукта, но опустим детали)

К сожалению, реальность же намного суровее, и очевидно такое распределение практически всегда нарушается в сами знаете какую сторону :) Не успели к дедлайну, недооценили объем работ, неожиданные «срочные» задачи, которых не было на планировании — и вот технина, грустно взмахнув ручкой архитектору, отъезжает на следующий спринт, а потом на следующий, а потом и в следующий квартал.
Продуктовый офис можно понять — они ответственны за бизнес метрики, а технические, вроде нагрузки, покрытия тестами, чистоты кода и т.д. — совершенно для них непонятны и/или неинтересны. Как донести их значимость?
Неприятная правда в том, что бизнес понимает только бизнесовые и продуктовые метрики. Это задача технической команды (техлидов или архитекторов, зависит от компании) конвертировать непонятные технические метрики в понятные деньги. Расскажу о нашем опыте на примере двух ситуаций: как мы столкнулись с проблемами отказоустойчивости нашего приложения и как мы осознали, что инфраструктура не готова удовлетворить ожидания бизнеса.
Для контекста: наша компания предоставляет SaaS электронной коммерции для других компаний.
Слабое звено или хрупкая инфраструктура
По мере развития приложения в ходе компромиссов и из-за ограниченного контекста мы пришли к ситуации, когда Redis из кэша превратился в единую точку отказа (не спрашивайте как). Хоть у него и был аптайм 6 лет, по закону Мёрфи в какой-то момент виртуалка ушла в себя и приложение было недоступно 20 минут.
Что говорит бизнесу даунтайм в 20 минут? Ну полежали чуть чуть, пара пользователей не смогли совершить транзакцию, а через 20 минут смогли. Че бухтеть то? Лучше продолжать пилить фичи.
В таком случае нужно понять, сколько денег стоит подобный инцидент и вернуться с цифрами. В нашем случае 2 составляющих:
Количество активных пользователей, которые получили ошибку. Зная воронку конверсии можно оценить, сколько денег недополучили
Посмотреть SLA, которые указаны в договорах. В нашем случае у одного из крупных наших партнерах в договоре указаны следующие SLA
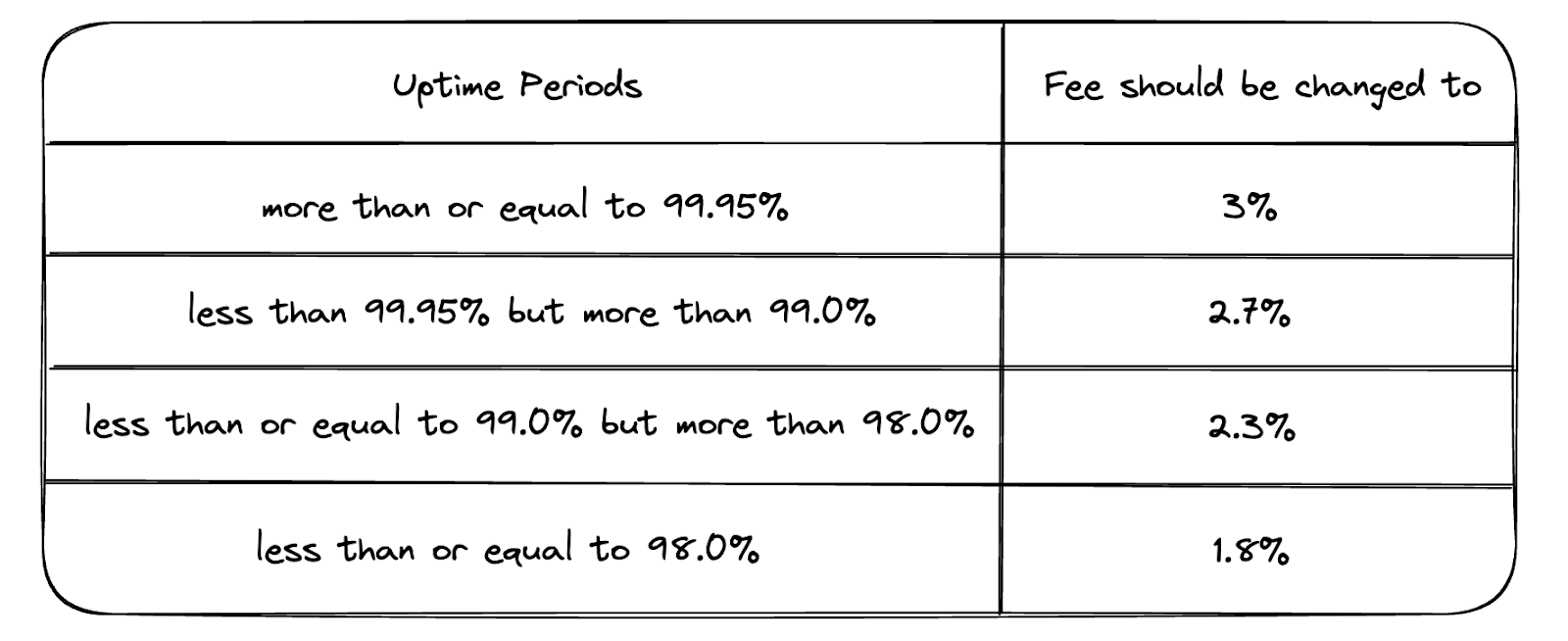
Один из примеров SLA, которые указываются в договоре с партнером
20 минут даунтайма в месяц — это уже 0.046% недоступности, т.е. бюджет на ошибки будет практически полностью исчерпан одним таким инцидентом, после чего комиссия, получаемая за период с партнера будет уменьшена на 0.3%. Зная исторический оборот этого партнера, нетрудно посчитать сколько денег будет упущено
Можно сюда же добавить репутационные потери, но, их очень тяжело посчитать
Остается проблема в том, как оценить риск повторного инцидента. Повторюсь, за 6 лет это был первый отказ Redis. Честно говоря, для нас самих эта задача оказалась нетривиальной, но описание катастрофичности последствий уже было достаточно, чтобы удалось запланировать развертывание нового кластера на следующий квартал.
В ожидании прекрасного будущего
В какой-то момент мы поняли, что текущая нагрузка на нашем приложении подозрительно близка к максимальной. По метрикам вышло, что за первые 2 месяца года нагрузка на API выросла в 2 раза.
Далее возникает вопрос: «И что с этим делать? Пора паниковать? Или это нормально?». На этот случай у нас была тактика, и мы ее придерживались
Сбор текущих показателей
Мы предоставляем бекенд для интеграции партнерами, поэтому в простейшем случае можно посмотреть метрики по использованию различных методов API разными партнерами + дополнительно сгруппировать по типу интеграции (например, партнеры которые продают физический мерч генерят намного меньше трафика) и размеру партнера (мидтир, энтерпрайз и т.д.).
Поэтому важна хорошая система мониторинга, которая позволяет собирать не только метрики реального времени, но и хранить их для исторического анализа.
В нашем приложении мы используем New Relic для метрик приложений и Prometheus + Grafana для инфраструктурных метрик.
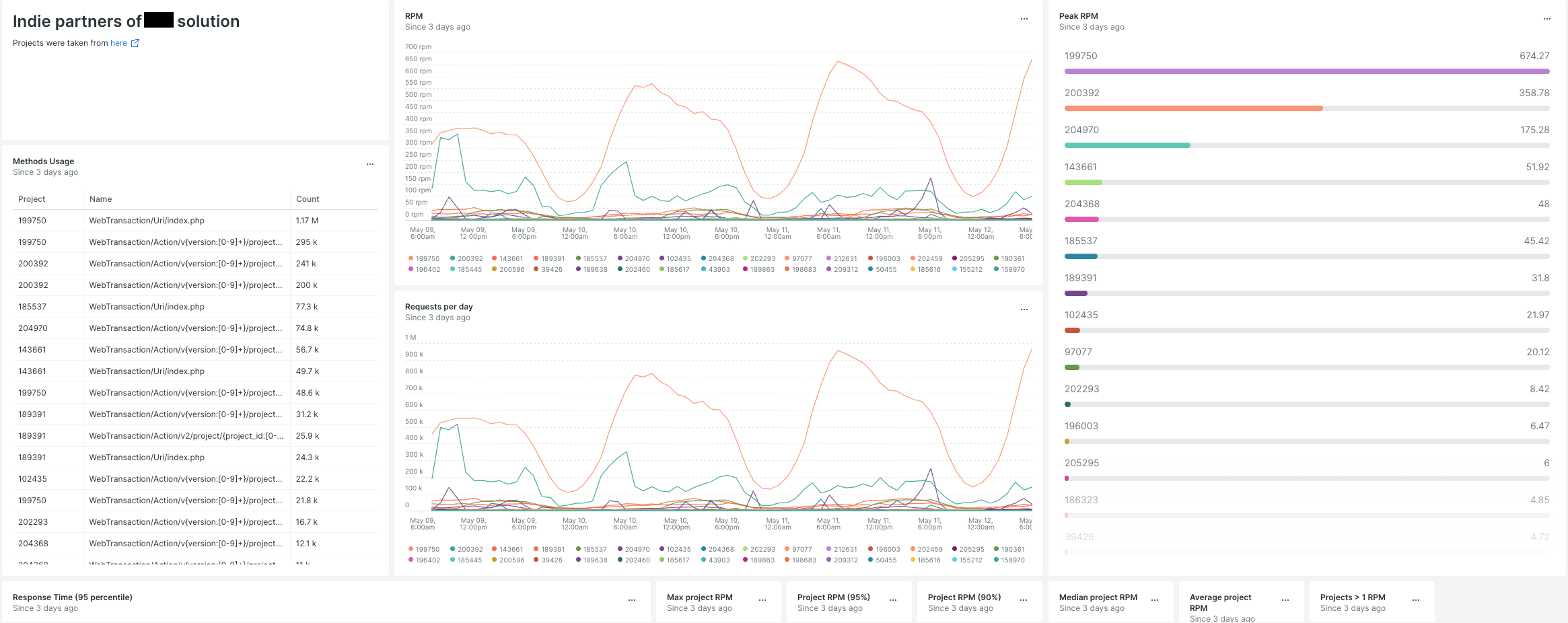
Примеры дашбордов с трафиком от партнеров. Есть возможность строить дашборды по разным сегментам и продуктам
После анализа нам стало понятно сколько примерно каждый партнер генерирует нагрузки на нашу API, а по инфраструктурным метрикам можно было сказать, станет ли какая-то часть системы (базы, брокеры сообщений и т.п.) узким горлышком при горизонтальном масштабировании приложения
Следующий шаг — актуализировать текущие значения максимальной пропускной способности. Проще говоря, провести нагрузочное тестирование, которое можно сделать, например, с помощью k6.
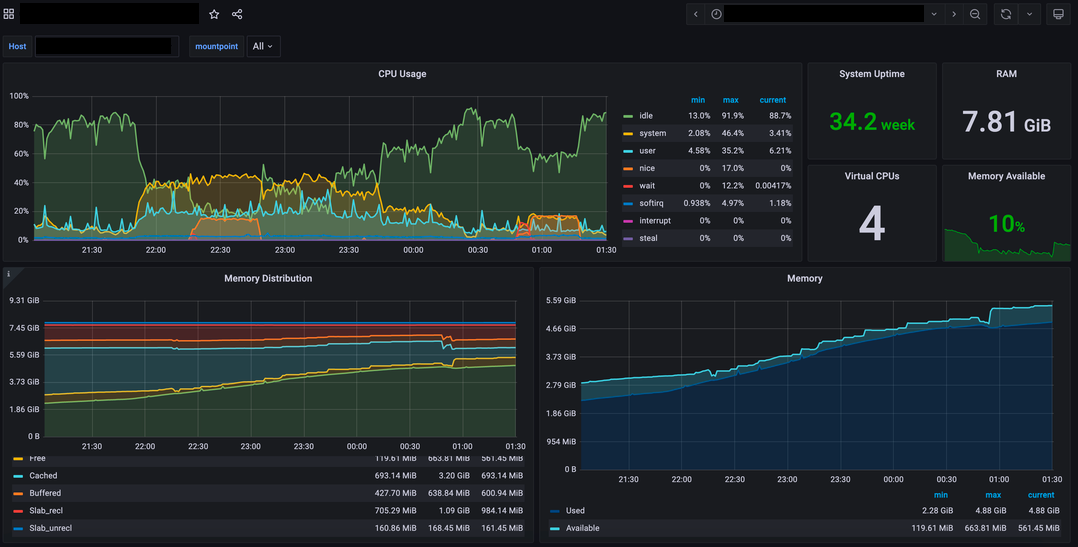
Одна из виртуалок стала узким местом во время очередной распродажи
Самое главное — фиксировать все инциденты, связанные с этой проблемой. В нашем случае разбирать и писать постмортемы для случаев, когда была запущена какая-то маркетинговая активность/распродажа и т.п., которые привели к росту трафика, который мы зарезали рейт лимитами (или у приложения начали деградировать SLO, такие как время ответа или время на процессинг транзакции). Если приложение не выдержало, то можно посчитать потери в течение этого даунтайма, в текущей ситуации — посчитать по трафику, который был отброшен. Хорошая идея добавлять в отчеты цифры в деньгах или хотя бы в пользователях вместо сухих цифр отброшенных запросов к API.
Эти инциденты будут дополнительным аргументом, когда будете убеждать бизнес, что проблема реальная.
Планируемые бизнес показатели
После этого мы выяснили планы бизнеса на развитие на ближайший год. Пришлось долго трясти людей, потому что как обычно ничего не формализовано, у разных людей разное понимание. Но суть в том, что когда кто-либо, даже если разработчики, приходят с такими вопросами — приходится что-то делать, собирать и актуализировать. В результате смогли собрать примерные планы по подключению новых партнеров на год, а также планы соседних департаментов, которые используют наши продукты и тоже могут генерировать нагрузку.
Полученную информацию мы сконвертировали в нагрузку, используя исторические данные каждого партнера с разными типами интеграциями.
Построили календарь, где указали конкретный месяц, когда мы перестанем справляться с новыми интеграциями (без учета пиковых нагрузок во время активностей). Учитывая прогнозируемые ревенью по каждой интеграции, нетрудно будет посчитать упущенную прибыль.
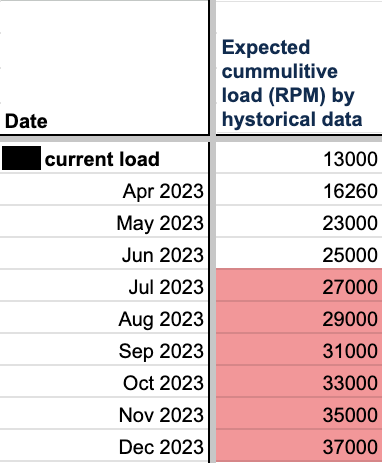
Наглядное представление, когда настанет судный день для приложения
Решения
На последнем этапе мы занялись генерацией и анализом возможных решений. Нет смысла идти с тем, что есть сейчас, потому что бизнесу непонятно сколько ресурсов нужно выделить и какой профит в итоге мы получим.
Поэтому стоит расписать все варианты, дать оценку, подсветить риски и профит.
На этом этапе появляется искушение схитрить и не показывать вариант, который не выгоден для самих разработчиков (например, дешевый, но который приведет к обилию костылей и кода с запашком). Это рабочая тактика в некоторых случаях, но, как мне кажется, негативно влияет на доверие между продуктовым офисом и отделом разработки.
Доверительные отношения ценны, т.к. приводит к осознанию важности технических задач второй стороной, поэтому капасити будет выделяться с большей готовностью.

Табличка с кратким обзором возможных решений, которую мы презентовали
Что в итоге?
Мы представили продуктовому менеджменту актуальные проблемы и предложили возможные решения, прошлись по цепочке вверх вплоть до бизнес хедов. После некоторых дискуссий, нам удалось добиться того, чтобы на целый квартал нам были выделены два опытных разработчика, которые будут заниматься только этой проблемой и никак не участвовать в разработке фичей или поддержке текущих партнеров
Резюме
Вот краткий пересказ основных моментов, которые я вынес из этих ситуаций:
Хорошая система мониторинга, сбора и хранения технических метрик (не только продуктовых) жизненно необходима. Без метрик что-то доказать будет сложно. Например, будет намного понятнее, если сопоставить время на разработку задачи в конкретном компоненте/время на онбординг в конкретный продукт с метриками качества кода.
Нужно конвертировать профит технических задач в понятные бизнесовые метрики и наглядно их презентовать. Например, «Обновить версии фреймворка/языка» — для бизнеса непонятно, но если сказать, что мы не пройдем сертификацию в следующем году из-за устаревшего ПО или что в этой версии обнаружены следующие эксплойты, которые могут привести к утечке данных — это уже прозрачнее
Фиксировать все инциденты с причинами, последствиями и работами, которые могли бы предотвратить их, но не были сделаны. Это будет дополнительным аргументом.
Нужно быть готовым, что придется вытягивать самостоятельно информацию из бизнеса: примеры SLA в договорах, которые подписываются с партнерами, планы по привлечению трафика к разным продуктам и т.п.
Иногда, следуя этим практикам, мы осознаем, что задача, которую мы хотели сделать, на самом деле не так важна, и даже непонятно, зачем мы пытались ее впихнуть в техническую дорожку :)
Издавна разработчики и менеджеры противопоставляются друг другу, выступают героями постоянных мемов. Я поделился своим опытом общения с продуктовым офисом. А как обстоят дела у вас? Как вы приходите к взаимному пониманию?
