Перехват функций в ядре Linux с помощью ftrace
 В одном проекте, связанном с безопасностью Linux-систем, нам потребовалось перехватывать вызовы важных функций внутри ядра (вроде открытия файлов и запуска процессов) для обеспечения возможности мониторинга активности в системе и превентивного блокирования деятельности подозрительных процессов.
В одном проекте, связанном с безопасностью Linux-систем, нам потребовалось перехватывать вызовы важных функций внутри ядра (вроде открытия файлов и запуска процессов) для обеспечения возможности мониторинга активности в системе и превентивного блокирования деятельности подозрительных процессов.
В процессе разработки нам удалось изобрести довольно неплохой подход, позволяющий удобно перехватить любую функцию в ядре по имени и выполнить свой код вокруг её вызовов. Перехватчик можно устанавливать из загружаемого GPL-модуля, без пересборки ядра. Подход поддерживает ядра версий 3.19+ для архитектуры x86_64.
(Изображение пингвина чуть выше: © En3l с DeviantArt.)
Известные подходы
Linux Security API
Наиболее правильным было бы использование Linux Security API — специального интерфейса, созданного именно для этих целей. В критических местах ядерного кода расположены вызовы security-функций, которые в свою очередь вызывают коллбеки, установленные security-модулем. Security-модуль может изучать контекст операции и принимать решение о её разрешении или запрете.
К сожалению, у Linux Security API есть пара важных ограничений:
- security-модули не могут быть загружены динамически, являются частью ядра и требуют его пересборки
- в системе может быть только один security-модуль (с небольшими исключениями)
Если по поводу множественности модулей позиция разработчиков ядра неоднозначная, то запрет на динамическую загрузку принципиальный: security-модуль должен быть частью ядра, чтобы обеспечивать безопасность постоянно, с момента загрузки.
Таким образом, для использования Security API необходимо поставлять собственную сборку ядра, а также интегрировать дополнительный модуль с SELinux или AppArmor, которые используются популярными дистрибутивами. Заказчик на подобные обязательства подписываться не хотел, поэтому этот путь оказался закрыт.
По этим причинам Security API нам не подошёл, иначе он был бы идеальным вариантом.
Модификация таблицы системных вызовов
Мониторинг требовался в основном для действий, выполняемых пользовательскими приложениями, так что в принципе мог бы быть реализован на уровне системных вызовов. Как известно, Linux хранит все обработчики системных вызовов в таблице sys_call_table. Подмена значений в этой таблице приводит к смене поведения всей системы. Таким образом, сохранив старое значения обработчика и подставив в таблицу собственный обработчик, мы можем перехватить любой системный вызов.
У этого подхода есть определённые преимущества:
- Полный контроль над любыми системными вызовами — единственным интерфейсом к ядру у пользовательских приложений. Используя его мы можем быть уверены, что не пропустим какое-нибудь важное действие, выполняемое пользовательским процессом.
- Минимальные накладные расходы. Есть единоразовые капитальные вложения при обновлении таблицы системных вызовов. Помимо неизбежной полезной нагрузки мониторинга, единственным расходом является лишний вызов функции (для вызова оригинального обработчика системного вызова).
- Минимальные требования к ядру. При желании этот подход не требует каких-либо дополнительных конфигурационных опций в ядре, так что в теории поддерживает максимально широкий спектр систем.
Однако, он также страдает от некоторых недостатков:
- Техническая сложность реализации. Сама по себе замена указателей в таблице не представляет трудностей. Но сопутствующие задачи требуют неочевидных решений и определённой квалификации:
- поиск таблицы системных вызовов
- обход защиты от модификации таблицы
- атомарное и безопасное выполнение замены
Это всё интересные вещи, но они требуют драгоценного времени разработчиков сначала на реализацию, а затем на поддержку и понимание. - Невозможность перехвата некоторых обработчиков. В ядрах до версии 4.16 обработка системных вызовов для архитектуры x86_64 содержала целый ряд оптимизаций. Некоторые из них требовали того, что обработчик системного вызова являлся специальным переходничком, реализованным на ассемблере. Соответственно, подобные обработчики порой сложно, а иногда и вовсе невозможно заменить на свои, написанные на Си. Более того, в разных версиях ядра используются разные оптимизации, что добавляет в копилку технических сложностей.
- Перехватываются только системные вызовы. Этот подход позволяет заменять обработчики системных вызовов, что ограничивает точки входа только ими. Все дополнительные проверки выполняются либо в начале, либо в конце, и у нас есть лишь аргументы системного вызова и его возвращаемое значение. Иногда это приводит к необходимости дублировать проверки на адекватность аргументов и проверки доступа. Иногда вызывает лишние накладные расходы, когда требуется дважды копировать память пользовательского процесса: если аргумент передаётся через указатель, то его сначала придётся скопировать нам самим, затем оригинальный обработчик скопирует аргумент ещё раз для себя. Кроме того, в некоторых случаях системные вызовы предоставляют слишком низкую гранулярность событий, которые приходится дополнительно фильтровать от шума.
Изначально мы выбрали и успешно реализовали именно этот подход, преследуя выгоды от поддержки наибольшего количества систем. Однако, в то время мы ещё не знали об особенностях x86_64 и ограничениях на перехватываемые вызовы. Позже для нас оказалась критичной поддержка системных вызовов, связанных с запуском новых процессов — clone () и execve (), — которые как раз являются особенными. Именно это и привело нас к поиску новых вариантов.
Использование kprobes
Одним из вариантов, которые рассматривались, было использование kprobes: специализированного API, в первую очередь предназначенного для отладки и трассирования ядра. Этот интерфейс позволяет устанавливать пред- и постобработчики для любой инструкции в ядре, а также обработчики на вход и возврат из функции. Обработчики получают доступ к регистрам и могут их изменять. Таким образом, мы бы могли получить как мониторинг, так и возможность влиять на дальнейший ход работы.
Преимущества, которые даёт использование kprobes для перехвата:
- Зрелый API. Kprobes существуют и улучшаются с незапамятных времён (2002 год). Они обладают хорошо задокументированным интерфейсом, большинство подводных камней уже найдено, их работа по возможности оптимизирована, и так далее. В общем, целая гора преимуществ над экспериментальными самописными велосипедами.
- Перехват любого места в ядре. Kprobes реализуются с помощью точек останова (инструкции int3), внедряемых в исполнимый код ядра. Это позволяет устанавливать kprobes в буквально любом месте любой функции, если оно известно. Аналогично, kretprobes реализуются через подмену адреса возврата на стеке и позволяют перехватить возврат из любой функции (за исключением тех, которые управление в принципе не возвращают).
Недостатки kprobes:
- Техническая сложность. Kprobes — это только способ установить точку останова в любом места ядра. Для получения аргументов функции или значений локальных переменных надо знать, в каких регистрах или где на стеке они лежат, и самостоятельно их оттуда извлекать. Для блокировки вызова функции необходимо вручную модифицировать состояние процесса так, чтобы процессор подумал, что он уже вернул управление из функции.
- Jprobes объявлены устаревшими. Jprobes — это надстройка над kprobes, позволяющая удобно перехватывать вызовы функций. Она самостоятельно извлечёт аргументы функции из регистров или стека и вызовет ваш обработчик, который должен иметь ту же сигнатуру, что и перехватываемая функция. Подвох в том, что jprobes объявлены устаревшими и вырезаны из современных ядер.
- Нетривиальные накладные расходы. Расстановка точек останова дорогая, но она выполняется единоразово. Точки останова не влияют на остальные функции, однако их обработка относительно недешёвая. К счастью, для архитектуры x86_64 реализована jump-оптимизация, существенно уменьшающая стоимость kprobes, но она всё ещё остаётся больше, чем, например, при модификации таблицы системных вызовов.
- Ограничения kretprobes. Kretprobes реализуются через подмену адреса возврата на стеке. Соответственно, им необходимо где-то хранить оригинальный адрес, чтобы вернуться туда после обработки kretprobe. Адреса хранятся в буфере фиксированного размера. В случае его переполнения, когда в системе выполняется слишком много одновременных вызовов перехваченной функции, kretprobes будет пропускать срабатывания.
- Отключенное вытеснение. Так как kprobes основывается на прерываниях и жонглирует регистрами процессора, то для синхронизации все обработчики выполняются с отключенным вытеснением (preemption). Это накладывает определённые ограничения на обработчики: в них нельзя ждать — выделять много памяти, заниматься вводом-выводом, спать в таймерах и семафорах, и прочие известные вещи.
В процессе исследования темы наш взгляд упал на фреймворк ftrace, способный заменить jprobes. Как оказалось, для наших нужд перехвата вызовов функций он подходит лучше. Однако, если вам необходимо трассирование конкретных инструкций внутри функций, то kprobes не стоит списывать со счетов.
Сплайсинг
Для полноты картины стоит также описать классический способ перехвата функций, заключающийся в замене инструкций в начале функции на безусловный переход, ведущий в наш обработчик. Оригинальные инструкции переносятся в другое место и исполняются перед переходом обратно в перехваченную функцию. С помощью двух переходов мы вшиваем (splice in) свой дополнительный код в функцию, поэтому такой подход называется сплайсингом.
Именно таким образом и реализуется jump-оптимизация для kprobes. Используя сплайсинг можно добиться тех же результатов, но без дополнительных расходов на kprobes и с полным контролем ситуации.
Преимущества сплайсинга очевидны:
- Минимальные требования к ядру. Сплайсинг не требует каких-либо особенных опций в ядре и работает в начале любой функции. Нужно только знать её адрес.
- Минимальные накладные расходы. Два безусловных перехода — вот и все действия, которые надо выполнить перехваченному коду, чтобы передать управление обработчику и обратно. Подобные переходы отлично предсказываются процессором и являются очень дешёвыми.
Однако, главный недостаток этого подхода серьёзно омрачает картину:
- Техническая сложность. Она зашкаливает. Нельзя просто так взять и переписать машинный код. Вот краткий и неполный список задач, которые придётся решить:
- синхронизация установки и снятия перехвата (что если функцию вызовут прямо в процессе замены её инструкций?)
- обход защиты на модификацию регионов памяти с кодом
- инвалидация кешей процессора после замены инструкций
- дизассемблирование заменяемых инструкций, чтобы скопировать их целыми
- проверка на отсутствие переходов внутрь заменяемого куска
- проверка на возможность переместить заменяемый кусок в другое место
Да, можно подсматривать в kprobes и использовать внутриядерный фреймворк livepatch, но итоговое решение всё равно остаётся довольно сложным. Страшно представить, какое количество спящих проблем будет в каждой новой его реализации.
В общем, если вы способны призвать этого демона, подчиняющего только посвящённым, и готовы терпеть его в своём коде, то сплайсинг — это вполне рабочий подход для перехвата вызовов функций. Я негативно относился к написанию велосипедов, поэтому этот вариант оставался для нас резервным на случай, если совсем не будет никакого прогресса с готовыми решениями попроще.
Новый подход с ftrace
Ftrace — это фреймворк для трассирования ядра на уровне функций. Он разрабатывается с 2008 года и обладает просто фантастическим интерфейсом для пользовательских программ. Ftrace позволяет отслеживать частоту и длительность вызовов функций, отображать графы вызовов, фильтровать интересующие функции по шаблонам, и так далее. О возможностях ftrace можно начать читать отсюда, и дальше по приведённым ссылкам и официальной документации.
Реализуется ftrace на основе ключей компилятора -pg и -mfentry, которые вставляют в начало каждой функции вызов специальной трассировочной функции mcount () или __fentry__(). Обычно, в пользовательских программах эта возможность компилятора используется профилировщиками, чтобы отслеживать вызовы всех функций. Ядро же использует эти функции для реализации фреймворка ftrace.
Вызывать ftrace из каждой функции — это, разумеется, не дёшево, поэтому для популярных архитектур доступна оптимизация: динамический ftrace. Суть в том, что ядро знает расположение всех вызовов mcount () или __fentry__() и на ранних этапах загрузки заменяет их машинный код на nop — специальную ничего не делающую инструкцию. При включении трассирования в нужные функции вызовы ftrace добавляются обратно. Таким образом, если ftrace не используется, то его влияние на систему минимально.
Описание нужных функций
Каждую перехватываемую функцию можно описать следующей структурой:
/**
* struct ftrace_hook - описывает перехватываемую функцию
*
* @name: имя перехватываемой функции
*
* @function: адрес функции-обёртки, которая будет вызываться вместо
* перехваченной функции
*
* @original: указатель на место, куда следует записать адрес
* перехватываемой функции, заполняется при установке
*
* @address: адрес перехватываемой функции, выясняется при установке
*
* @ops: служебная информация ftrace, инициализируется нулями,
* при установке перехвата будет доинициализирована
*/
struct ftrace_hook {
const char *name;
void *function;
void *original;
unsigned long address;
struct ftrace_ops ops;
};
Пользователю необходимо заполнить только первые три поля: name, function, original. Остальные поля считаются деталью реализации. Описание всех перехватываемых функций можно собрать в массив и использовать макросы, чтобы повысить компактность кода:
#define HOOK(_name, _function, _original) \
{ \
.name = (_name), \
.function = (_function), \
.original = (_original), \
}
static struct ftrace_hook hooked_functions[] = {
HOOK("sys_clone", fh_sys_clone, &real_sys_clone),
HOOK("sys_execve", fh_sys_execve, &real_sys_execve),
};
Обёртки над перехватываемыми функциями выглядят следующим образом:
/*
* Это указатель на оригинальный обработчик системного вызова execve().
* Его можно вызывать из обёртки. Очень важно в точности соблюдать
* сигнатуру функции: порядок и типы аргументов и возвращаемого значения,
* а также спецификаторы ABI (внимание на "asmlinkage").
*/
static asmlinkage long (*real_sys_execve)(const char __user *filename,
const char __user *const __user *argv,
const char __user *const __user *envp);
/*
* Эта функция будет вызываться вместо перехваченной. Её аргументы — это
* аргументы оригинальной функции. Её возвращаемое значение будет передано
* вызывающей функции. Она может выполнять произвольный код до, после
* или вместо оригинальной функции.
*/
static asmlinkage long fh_sys_execve(const char __user *filename,
const char __user *const __user *argv,
const char __user *const __user *envp)
{
long ret;
pr_debug("execve() called: filename=%p argv=%p envp=%p\n",
filename, argv, envp);
ret = real_sys_execve(filename, argv, envp);
pr_debug("execve() returns: %ld\n", ret);
return ret;
}
Как видим, перехватываемые функции с минимумом лишнего кода. Единственный момент, требующий тщательного внимания — это сигнатуры функций. Они должны совпадать один к одному. Без этого, очевидно, аргументы будут переданы неправильно и всё пойдёт под откос. Для перехвата системных вызовов это важно в меньшей степени, так как их обработчики очень стабильные и для эффективности аргументы принимают в том же порядке, что и сами системные вызовы. Однако, если вы планируете перехватывать другие функции, то следует помнить о том, что внутри ядра стабильных интерфейсов нет.
Инициализация ftrace
Для начала нам потребуется найти и сохранить адрес функции, которую мы будем перехватывать. Ftrace позволяет трассировать функции по имени, но нам всё равно надо знать адрес оригинальной функции, чтобы вызывать её.
Добыть адрес можно с помощью kallsyms — списка всех символов в ядре. В этот список входят все символы, не только экспортируемые для модулей. Получение адреса перехватываемой функции выглядит примерно так:
static int resolve_hook_address(struct ftrace_hook *hook)
{
hook->address = kallsyms_lookup_name(hook->name);
if (!hook->address) {
pr_debug("unresolved symbol: %s\n", hook->name);
return -ENOENT;
}
*((unsigned long*) hook->original) = hook->address;
return 0;
}
Дальше необходимо инициализировать структуру ftrace_ops. В ней обязательным
полем является лишь func, указывающая на коллбек, но нам также необходимо
установить некоторые важные флаги:
int fh_install_hook(struct ftrace_hook *hook)
{
int err;
err = resolve_hook_address(hook);
if (err)
return err;
hook->ops.func = fh_ftrace_thunk;
hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS
| FTRACE_OPS_FL_IPMODIFY;
/* ... */
}
fh_ftrace_thunk() — это наш коллбек, который ftrace будет вызывать при трассировании функции. О нём позже. Флаги, которые мы устанавливаем, будут необходимы для выполнения перехвата. Они предписывают ftrace сохранить и восстановить регистры процессора, содержимое которых мы сможем изменить в коллбеке.
Теперь мы готовы к включению перехвата. Для этого необходимо сначала включить ftrace для интересующей нас функции с помощью ftrace_set_filter_ip (), а затем разрешить ftrace вызывать наш коллбек с помощью register_ftrace_function ():
int fh_install_hook(struct ftrace_hook *hook)
{
/* ... */
err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0);
if (err) {
pr_debug("ftrace_set_filter_ip() failed: %d\n", err);
return err;
}
err = register_ftrace_function(&hook->ops);
if (err) {
pr_debug("register_ftrace_function() failed: %d\n", err);
/* Не забываем выключить ftrace в случае ошибки. */
ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0);
return err;
}
return 0;
}
Выключается перехват аналогично, только в обратном порядке:
void fh_remove_hook(struct ftrace_hook *hook)
{
int err;
err = unregister_ftrace_function(&hook->ops);
if (err) {
pr_debug("unregister_ftrace_function() failed: %d\n", err);
}
err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0);
if (err) {
pr_debug("ftrace_set_filter_ip() failed: %d\n", err);
}
}
После завершения вызова unregister_ftrace_function () гарантируется отсутствие активаций установленного коллбека в системе (а вместе с ним — и наших обёрток). Поэтому мы можем, например, спокойно выгрузить модуль-перехватчик, не опасаясь, что где-то в системе ещё выполняются наши функции (ведь если они пропадут, то процессор расстроится).
Выполнение перехвата функций
Как же выполняется собственно перехват? Очень просто. Ftrace позволяет изменять состояние регистров после выхода из коллбека. Изменяя регистр %rip — указатель на следующую исполняемую инструкцию, — мы изменяем инструкции, которые исполняет процессор — то есть можем заставить его выполнить безусловный переход из текущей функции в нашу. Таким образом мы перехватываем управление на себя.
Коллбек для ftrace выглядит следующим образом:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip,
struct ftrace_ops *ops, struct pt_regs *regs)
{
struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops);
regs->ip = (unsigned long) hook->function;
}
С помощью макроса container_of () мы получаем адрес нашей struct ftrace_hook по адресу внедрённой в неё struct ftrace_ops, после чего заменяем значение регистра %rip в структуре struct pt_regs на адрес нашего обработчика. Всё. Для архитектур, отличных от x86_64, этот регистр может называться по-другому (вроде IP или PC), но идея в принципе применима и для них.
Обратите внимание на спецификатор notrace, добавленный для коллбека. Им можно помечать функции, запрещённые для трассировки с помощью ftrace. Например, так помечены функции самого ftrace, задействованные в процессе трассировки. Это помогает предотвратить зависание системы в бесконечном цикле при трассировании всех функций в ядре (ftrace так умеет).
Коллбек ftrace обычно вызывает с отключенным вытеснением (как и kprobes). Возможны исключения, но на них не стоит рассчитывать. В нашем случае, правда, это ограничение не важно, так мы всего лишь заменяем восемь байтов в структуре.
Функция-обёртка, которая вызывается позже, будет выполняться в том же контексте, что и оригинальная функция. Поэтому там можно делать то же, что позволено делать в перехватываемой функции. Например, если вы перехватываете обработчик прерывания, то спать в обёртке всё ещё нельзя.
Защита от рекурсивных вызовов
В коде выше есть подвох: когда наша обёртка вызовет оригинальную функцию, та опять попадёт в ftrace, который опять вызовет наш коллбек, который опять передаст управление обёртке. Эту бесконечную рекурсию необходимо как-то оборвать.
Наиболее элегантный способ, который пришёл нам в голову — это использовать parent_ip — один из аргументов ftrace-коллбека, который содержит адрес возврата в функцию, которая вызвала трассируемую функцию. Обычно этот аргумент используют для построения графа вызовов функций. Мы же можем воспользоваться им для того, чтобы отличить первый вызов перехваченной функции от повторного.
Действительно, при повторном вызове parent_ip должен указывать внутрь нашей обёртки, тогда как при первом — куда-то в другое место ядра. Передавать управление следует только при первом вызове функции, все другие должны дать выполниться оригинальной функции.
Проверку на вхождение можно очень эффективно выполнить, сравнивая адрес с границами текущего модуля (который содержит все наши функции). Это отлично работает в случае, если в модуле лишь обёртка вызывает перехваченную функцию. В противном случае необходимо быть более избирательным.
Итого, правильный ftrace-коллбек выглядит следующим образом:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip,
struct ftrace_ops *ops, struct pt_regs *regs)
{
struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops);
/* Пропускаем вызовы функции из текущего модуля. */
if (!within_module(parent_ip, THIS_MODULE))
regs->ip = (unsigned long) hook->function;
}
Отличительные особенности/преимущества данного подхода:
- Низкие накладные расходы. Всего лишь несколько вычитаний и сравнений. Никаких спинлоков, проходов по спискам, и так далее.
- Не требует глобального состояния. Отсутствие синхронизации делает подобный подход автоматически совместимым с вытеснением. Он не привязан к глобальному списку процессов, так что позволяет перехватывать в том числе обработчики прерываний.
- Нет ограничений на функции. Этот подход лишён недостатка kretprobes и из коробки поддерживает любое количество активаций перехватываемой функции, в том числе рекурсивных (когда ядро само вызывает функцию несколько раз). При рекурсивных вызовах адрес возврата всё ещё находится вне нашего модуля, так что проверка в коллбеке работает корректно.
Схема работы перехвата
Рассмотрим пример: вы набрали в терминале команду ls, чтобы увидеть список файлов в текущей директории. Командный интерпретатор (скажем, Bash) для запуска нового процесса использует традиционную пару функций fork() + execve() из стандартной библиотеки языка Си. Внутри эти функции реализуются через системные вызовы clone () и execve () соответственно. Допустим, мы перехватываем системный вызов execve (), чтобы контролировать запуск новых процессов.
В графическом виде перехват функции-обработчика выглядит так:
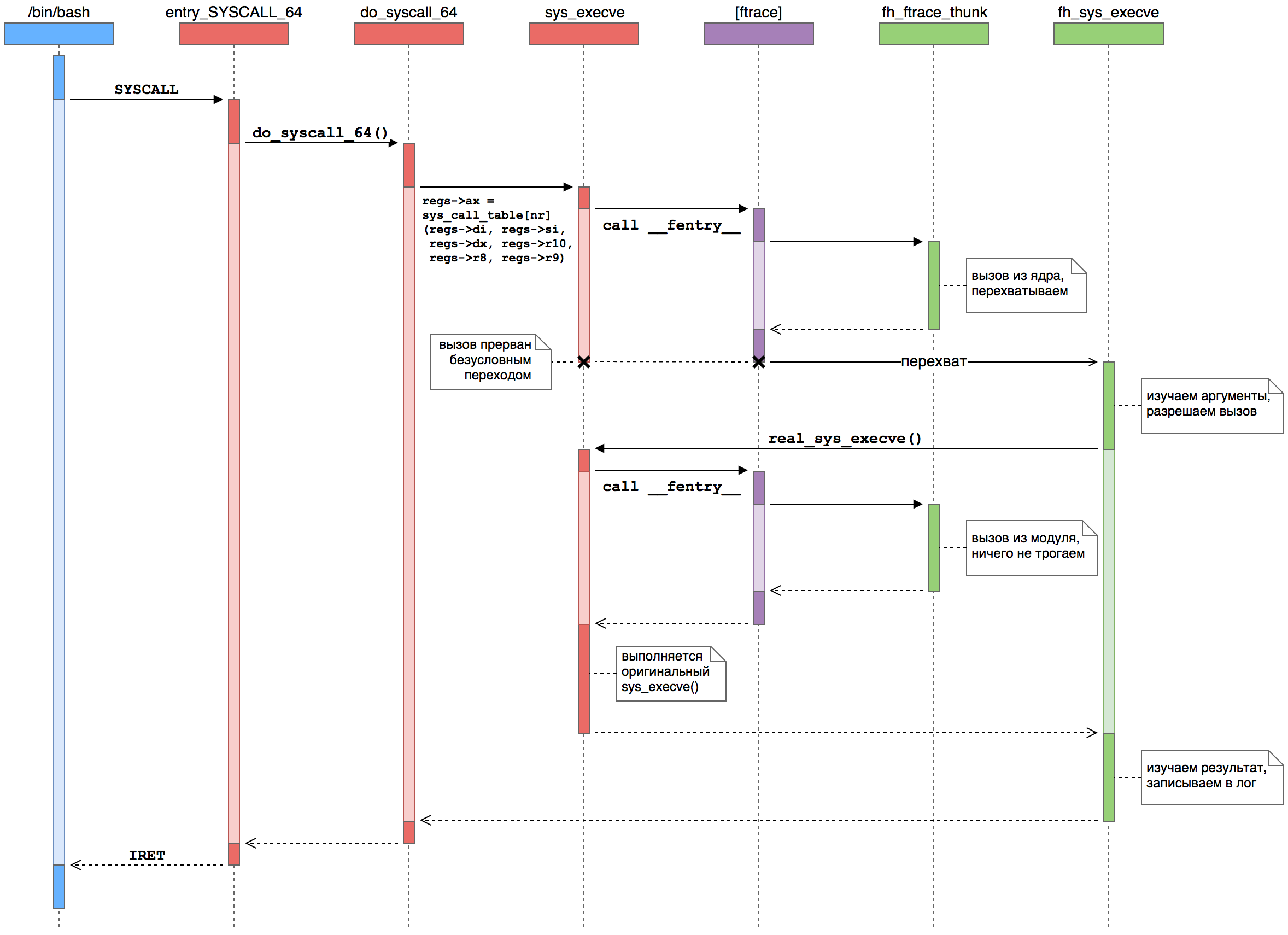
Здесь мы видим, как пользовательский процесс (голубой) выполняет системный вызов в ядро (красное), где фреймворк ftrace (фиолетовый) вызывает функции из нашего модуля (зелёного).
- Пользовательский процесс выполняет SYSCALL. С помощью этой инструкции выполняется переход в режим ядра и управление передаётся низкоуровневому обработчику системных вызовов — entry_SYSCALL_64(). Он отвечает за все системные вызовы 64-битных программ на 64-битных ядрах.
- Управление переходит к конкретному обработчику. Ядро быстро делает низкоуровневые дела, реализованные на ассемблере, и передаёт управление высокоуровневой функции do_syscall_64(), написанной на Си. Эта функция в свою очередь обращается к таблице обработчиков системных вызовов
sys_call_tableи вызывает оттуда конкретный обработчик по номеру системного вызова — в нашем случае это будет функция sys_execve(). - Вызывается ftrace. В начале каждой функции ядра находится вызов функции __fentry__(), которая реализуется фреймворком ftrace. В функциях, которые трассировать не надо, этот вызов обычно заменён на инструкции nop, но в интересной нам функции sys_execve () этот вызов присутствует.
- Ftrace вызывает наш коллбек. В процессе работы ftrace вызывает все зарегистрированные трассировочные коллбеки, включая и наш. В одном месте может быть установлен только один коллбек, изменяющий значение регистра %rip, так что другие коллбеки нам не помешают.
- Коллбек выполняет перехват. Коллбек смотрит на значение
parent_ip, указывающее внутрь do_syscall_64() — так как именно эта функция вызвала обработчик sys_execve () — и принимает решение выполнит перехват, обновляя значение регистра %rip в структуреpt_regs. - Ftrace восстанавливает регистры. Следуя флагу FTRACE_SAVE_REGS, ftrace сохраняет состояние регистров в структуре
pt_regsперед вызовом обработчиков. При завершении обработки ftrace восстанавливает регистры из этой структуры. Наш обработчик изменяет регистр %rip — указатель на следующую исполняемую инструкцию — что в итоге приводит к передаче управления по новому адресу. - Управление получает функция-обёртка. Из-за безусловного перехода активация функции sys_execve () как бы прерывается. Вместо неё управление получает наша функция fh_sys_execve(). При этом всё остальное состояние процессора и памяти остаётся без изменений, поэтому наша функция получает все аргументы оригинального обработчика и при завершении вернёт управление в функцию do_syscall_64().
- Обёртка вызывает оригинальную функцию. С этого момента судьба системного вызова находится в наших руках. Функция fh_sys_execve () может проанализировать аргументы и контекст системного вызова (кто что запускает) и запретить или разрешить процессу его выполнение. В случае запрета функция просто возвращает код ошибки. Иначе же ей следует вызвать оригинальный обработчик — sys_execve () вызывается повторно, через указатель real_sys_execve, который был сохранён при настройке перехвата.
- Управление получает коллбек. Как и при первом вызове sys_execve (), управление опять проходит через ftrace и передаётся в наш коллбек. Однако, в этот раз ситуация развивается немного по-другому…
- Коллбек ничего не делает. Потому что в этот раз функция sys_execve () вызывается нашей функцией fh_sys_execve (), а не ядром из do_syscall_64(). Поэтому коллбек не модифицирует регистры и выполнение функции sys_execve () продолжается как обычно. Единственный побочный эффект такого дела: ftrace видит вход в sys_execve () дважды.
- Управление возвращается обёртке. Во второй раз обработчик системного вызова sys_execve () вернёт управление в нашу функцию fh_sys_execve (). К этому моменту новый процесс уже почти запущен. Мы можем посмотреть, завершился ли вызов execve () с ошибкой, изучить свежезапущенный процесс, сделать соответствующие записи в лог, и т. д.
- Управление возвращается ядру. Наконец fh_sys_execve () завершается и управление переходит в do_syscall_64(), которая считает, что системный вызов был завершён как обычно. Ядро продолжает свои ядерные дела.
- Управление возвращается в пользовательский процесс. Наконец ядро выполняет инструкцию IRET (или SYSRET, но для execve () — всегда IRET), устанавливая регистры для нового пользовательского процесса и переводя центральный процессор в режим исполнения пользовательского кода. Системный вызов (и запуск нового процесса) завершён.
Преимущества и недостатки
В итоге мы получаем очень удобный способ перехвата любых функций в ядре, обладающий следующими преимуществами:
- Зрелый API и простой код. Использование готовых интерфейсов в ядре существенно упрощает код. Вся установка перехвата требует пары вызовов функций, заполнение двух полей в структуре, и мааааленького кусочка магии в коллбеке. Остальной код — это исключительно бизнес-логика, выполняемая вокруг перехваченной функции.
- Перехват любой функции по имени. Для указания интересующей нас функции достаточно написать её имя в обычной строке. Не требуются какие-то особые реверансы с редактором связей, разбор внутренних структур данных ядра, сканирование памяти, или что-то подобное. Мы можем перехватить любую функцию (даже не экспортируемую для модулей), зная лишь её имя.
- Перехват совместим с трассировкой. Очевидно, что этот способ не конфликтует с ftrace, так что с ядра всё ещё можно снимать очень полезные показатели производительности. Использование kprobes или сплайсинга может помешать механизмам ftrace.
Какие же недостатки у этого решения?
- Требования к конфигурации ядра. Для успешного выполнения перехвата функций с помощью ftrace ядро должно предоставлять целый ряд возможностей:
- список символов kallsyms для поиска функций по имени
- фреймворк ftrace в целом для выполнения трассировки
- опции ftrace, критически важные для перехвата
Все эти возможности не являются критичными для функционирования системы и могут быть отключены в конфигурации ядра. Правда, обычно ядра, используемые популярными дистрибутивами, все эти опции в себе всё равно содержат, так как они не влияют на производительность и полезны при отладке. Однако, если вам необходимо поддерживать какие-то особенные ядра, то следует иметь в виду эти требования. - Накладные расходы на ftrace меньше, чем у kprobes (так как ftrace не использует точки останова), но они выше, чем у сплайсинга, сделанного вручную. Действительно, динамический ftrace — это и есть по сути сплайсинг, только вдобавок выполняющий «ненужный» код ftrace и другие коллбеки.
- Оборачиваются функции целиком. Как и традиционный сплайсинг, данный подход полностью оборачивает вызовы функций. Однако, если сплайсинг технически возможно выполнить в любом месте функции, то ftrace срабатывает исключительно при входе. Естественно, обычно это не вызывает сложностей и даже наоборот удобно, но подобное ограничение иногда может быть недостатком.
- Двойной вызов ftrace. Описанный выше подход с анализом указателя
parent_ipприводит к повторному вызову ftrace для перехваченных функций. Это добавляет немного накладных расходов и может сбивать показания других трассировок, которые будут видеть в два раза больше вызовов. Этого недостатка можно избежать, применив немного чёрной магии: вызов ftrace расположен в начале функции, так что если адрес оригинальной функции сдвинуть вперёд на 5 байтов (длина инструкции call), то через ftrace можно перескочить.
Рассмотрим некоторые недостатки подробнее.
Требования к конфигурации ядра
Для начала, ядра должно поддерживать ftrace и kallsyms. Для этого должны быть включены следующие опции:
- CONFIG_FTRACE
- CONFIG_KALLSYMS
Затем, ftrace должна поддерживать динамическую модификацию регистров. За эту возможность отвечает опция
- CONFIG_DYNAMIC_FTRACE_WITH_REGS
Далее, используемое ядро должно быть основано на версии 3.19 или выше, чтобы иметь доступ к флагу FTRACE_OPS_FL_IPMODIFY. Более ранние версии ядра тоже умеют заменять регистр %rip, но начиная с 3.19 это следует делать только после установки данного флага. Наличие флага для старых ядер приведёт к ошибке компиляции, а его отсутствие для новых — к неработающему перехвату.
Наконец, для выполнения перехвата критическим является расположение вызова ftrace внутри функции: вызов должен располагаться в самом начале, до пролога функции (где выделяется место под локальные переменные и формируется стековый фрейм). Эта особенность архитектуры учитывается опцией
- CONFIG_HAVE_FENTRY
Архитектура x86_64 поддерживает эту опцию, а вот i386 — нет. Из-за ограничений архитектуры i386 компилятор не может вставить вызов ftrace до пролога функции, поэтому к моменту вызова ftrace стек функции уже оказывается модифицированным. В таком случае для перехвата недостаточно лишь изменить значение регистра %eip — нужно ещё обратить все действия, выполненные в прологе, которые отличаются от функции к функции.
По этой причине перехват с помощью ftrace не поддерживает 32-битную архитектуру x86. В принципе, его можно было бы реализовать с помощью определённой чёрной магии (генерируя и выполняя «антипролог»), но тогда пострадает техническая простота решения, являющаяся одним из преимуществ использования ftrace.
Неочевидные сюрпризы
Во время тестирования мы столкнулись с одной интересной особенностью: на некоторых дистрибутивах перехват функций приводил к зависанию системы намертво. Естественно, это происходило только на системах, отличных от используемых разработчиками. Проблема также не воспроизводилась на исходном прототипе перехвата, с любыми дистрибутивами и версиями ядер.
Отладка показывала, что зависание происходит внутри перехваченной функции. По какой-то мистической причине при вызове оригинальной функции внутри ftrace-коллбека адрес parent_ip продолжал указывать в код ядра вместо кода функции обёртки. Из-за этого возникал бесконечный цикл, так как ftrace раз за разом вызывал нашу обёртку, не выполняя каких-либо полезных действий.
К счастью, у нас был в распоряжении как рабочий, так и поломанный код, поэтому нахождение различий было лишь вопросом времени. После проведённой унификации кода и выбрасывания всего ненужного, различия между версиями удалось локализовать до функции-обёртки.
Вот этот вариант работал:
static asmlinkage long fh_sys_execve(const char __user *filename,
const char __user *const __user *argv,
const char __user *const __user *envp)
{
long ret;
pr_debug("execve() called: filename=%p argv=%p envp=%p\n",
filename, argv, envp);
ret = real_sys_execve(f
