Переходим от MongoDB Full Text к ElasticSearch
В своем прошлом посте, с анонсом Google Chrome расширения для Likeastore, я упомянул тот факт, что в качестве поискового индекса мы начали использовать ElasticSeach. Именно ElasticSeach дал достаточно хорошую производительность и качество поиска, после которого было принято решение, выпустить расширение к хрому.В этом посте, я расскажу о том, что использование связки MongoDB + ElasticSeach, есть крайне эффективное NoSQL решение, и о том, как перейти на ElasticSearch, если у вас уже есть MongoDB.
Немного истории Функциональность поиска, суть нашего приложения. Возможность найти что-то быстро среди тысячи своих лайков, было то, ради чего мы начали этот проект.Глубоких знаний теории полнотекстового поиска у нас небыло, и в качестве первого подхода мы решили попробовать MongoDB Full Text Search. Не смотря на то, что в версии 2.4 full text является экспериментальной фичей, он заработал довольно хорошо. Поэтому, на некоторое время мы его оставили, переключившись на более актуальные задачи.
Время шло и база данных росла. Коллекция, по которой мы проводим индексацию начала набирать определенный размер. Начиная от размера в 2 миллионов документов, я стал замечать общее снижение производительности приложения. Проявлялось это в виде долгого открытия первой страницы, и крайне медленного поиска.
Все это время я присматривался к специализированным поисковым хранилищам, как ElasticSearch, Solr или Shpinx. Но как это часто былает в стартапе, пока «гром не грянет, мужик не перепишет».
Гром «грянул» 2 недели назад, после публикации на одном из ресурсов, мы испытали резкое увеличение траффика и большую пользовательскую активность. New Relic слал страшные письма, о том что приложение не отвечает, а собсвенные попытки открытия приложения, показывали — пациент скорее жив, чем мертв, но все работало крайне медленно.
Быстрый анализ показал, что большая часть HTTP реквестов отваливается с 504, после обращений к MongoDB. Мы хостимся на MongoHQ, но при попытке открыть консоль мониторинга, ровным счетом ничего не выходило. База была нагружена до самого предела. После того, как консоль таки удалось открыть я видел, что Locked % уходить в заоблачные 110 — 140% и держится там, не собираясь уходить вниз.
Сервис, который собирает пользовательские лайки, делает довольно много insert’ов, и каждый такой insert влечет за собой ре-калькуляцию полнотекстового индекса, это дорогая операция, и достигая определенных ограничений (в том числе и по ресурсам сервера), мы просто уперлись в ее предел.
Сбор данных пришлось отключить, полнотекстовый индекс удалить. После перезапуска, сервиса Locked index не превышал 0.7%, но если пользователь пытался что-то поискать, нам пришлось отвечать неудобным «sorry, search is on maintenance»…
Пробуем ElasticSeach локально Я решил посмотреть, что представляет из себя Elastic, попробовав его на своей машине. Для того рода экспериментов, всегда был (есть, и надеюсь будет) vagrant.ElasticSeach написан на Java, и требует соответвующего рантайма.
> sudo apt-get update > sudo apt-get install openjdk-6-jre > sudo add-apt-repository ppa: webupd8team/java > sudo apt-get install oracle-java7-installer После чего можно проверить, все ли нормально, запустив > java --version Сам Elastic устанавливается крайне просто. Я рекомендую установку из Debian пакета, так как в таком виде его проще сконфигурировать для запуска как сервис, а не как процесс. > wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.1.1.deb > dpkg -i elasticsearch-1.1.1.deb После этого, он готов к запуску, > sudo update-rc.d elasticsearch defaults 95 10 > sudo /etc/init.d/elasticsearch start Открыв свой браузер и перейдя по ссылке, получаем примерно такой ответ. { «ok» : true, «status» : 200, «name» : «Xavin», «version» : { «number» :»1.1.1», «build_hash» :»36897d07dadcb70886db7f149e645ed3d44eb5f2», «build_timestamp» :»2014–05–05T12:06:54Z», «build_snapshot» : false, «lucene_version» :»4.5.1» }, «tagline» : «You Know, for Search» } Полное развертывание занимает около 10 минут.Теперь что-то надо сохранить и поискать ElasticSearch это интерфейс, построенный поверх технологии Lucene. Это без преувеличений сложнейшая технология, отточенная годами, в которую было вложено тысячи трудо-часов высококлассных инженеров. Elastic, делает эту технологию доступной простым смертным, и делает это очень хорошо.Я нахожу некоторые параллели, между Elastic’ом и CounchDB — тоже HTTP API, тоже schemaless, таже ориентация на документы.
После быстрой установки, я потратил много времени читая мануал, смотря релевантные видосы, пока не понял, как можно сохранить документ в индекс и как запустить самый простой поисковой запрос.
На этом этапе я использовал голый curl, точно также, как это показанно в документации.
Но долго тренироваться «на кошках», не интересно. Я сделал дамп продакшн MongoDB базы, и теперь мне нужно было перегнать всю свою коллекцию из MongoDB в ElasticSearch индекс.
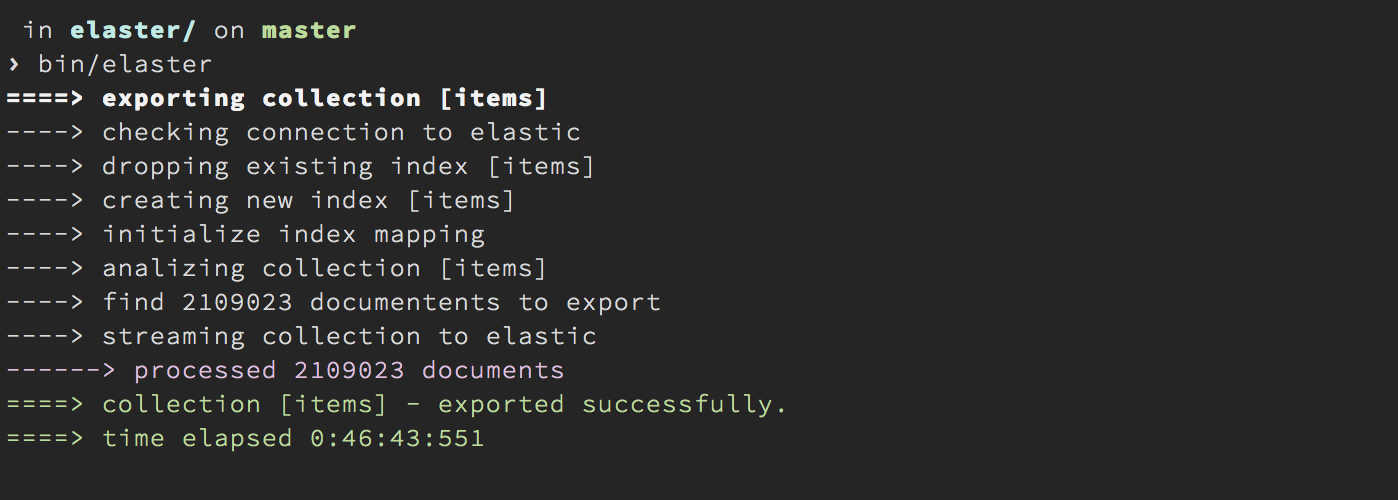
Для данной миграции, я сделал небольшой тул — elaster. Elaster, это node.js приложение, которое стриммит заданную коллекцию MongoDB, в ElasticSearch, предватительно создав нужный индекс и инициализировав его маппингом.
Процесс этот не очень быстрый (есть пару идей, для улучшения elaster), но примерно через 40 минут, все записи из MongoDB были в ElasticSearch, можно пробовать искать.
Создание поискового запроса Query DSL, язык построения запросов к Elastic. По синтаксису это обычный JSON, но вот делать эффективный запрос, это опыт, практика и знания. Я признаюсь чесно их еще не достиг, поэтому моя первая попытка выглядела вот так: function fullTextItemSearch (user, query, paging, callback) { if (! query) { return callback (null, { data: [], nextPage: false }); }
var page = paging.page || 1;
elastic.search ({ index: 'items', from: (page — 1) * paging.pageSize, size: paging.pageSize, body: { query: { filtered: { query: { 'query_string': { query: query }, }, filter: { term: { user: user.email } } } } } }, function (err, resp) { if (err) { return callback (err); }
var items = resp.hits.hits.map (function (hit) { return hit._source; });
callback (null, {data: items, nextPage: items.length === paging.pageSize}); }); } Это фильтрованный запрос, с пейджингом, для выдачи результатов для одного пользователя. Когда я попробовал его запустить, я был поражен как крут Elastic. Время выполнения запроса 30–40 мс, и даже без каких-то тонких настроек, я был доволен результатами выдачи! Помимо этого, в состав ElasticSeach входит Hightligh API, для подсветки результатов. Расширив запрос, до такого вида
elastic.search ({
index: 'items',
from: (page — 1) * paging.pageSize,
size: paging.pageSize,
body: {
query: {
filtered: {
query: {
'query_string': {
query: query
},
},
filter: {
term: {
user: user.email
}
}
},
},
highlight: {
fields: {
description: { },
title: { },
source: { }
}
}
}
В респонсе на него (объект hit) будет содержатся вложенный объект highlight, c HTML-ом, готовым для использовании на фронт-енде, что дает возможность делать примерно такое, 
Модификация кода приложения После того как базовый поиск заработал, необходимо сделать так, чтобы все новые данные, которые приходят в MongoDB (как основное хранилище) «перетекали» в ElasticSearch.Для этого, существуют специальные плагины, т.н. rivers. Их довольно много, под разные базы данных. Для MongoDB, самый широко использованный находится тут.
River для MongoDB работает по принципу мониторинга oplog из локальной базы, и трансформации oplog событий в ElasticSeach команды. В теории все просто. На практике, мне не удалось завести этот плагин с MongoHQ (скорее всего проблема кризны моих рук, ибо в интернете полно описаний успешных использований).
Но в моем случае, оказалось гораздо проще пойти по другому пути. Так как у меня только одна коллекция, в которую есть только insert и find, мне проще было модифицировать код приложения, таким образом, что сразу после insert`а в MongoDB, я делаю bulk комманду в ElasticSeach.
async.waterfall ([ readUser, executeConnector, findNew, saveToMongo, saveToEleastic, saveState ], function (err, results) { }); Функция, saveToElastic var commands = []; items.forEach (function (item) { commands.push ({'index': {'_index': 'items', '_type': 'item', '_id': item._id.toString ()}}); commands.push (item); });
elastic.bulk ({body: commands}, callback); Не исключаю, что в более сложных сценариях использование river будет более оправдано.Разворачиваем в продакшине После того, как локальные эксперимент был завершен, нужно было все это развернуть в продакшине.Для этого я создал новый дроплет на Digital Ocean (2 CPU, 2 GB, 40 GB SDD) и по сути провел с ним все манипуляции описанные выше — установить ElasticSeach, установить node.js и git, установить elaster и запустить миграцию данных.
Как только новый инстанс был поднят и инициализирован данными, я перезапустил сервисы сбора данных и Likeastore API, уже с кодом модифицированным под Elastic. Все сработало очень гладко и в продакшине уже никаких сюрпризов небыло.
Результаты Сказать то, что я доволен переходом на ElasticSearch это ничего не сказать. Это действительно одна из не многих технологий, которая работает «из коробки».Elastic открыл возможность создания расширения к браузеру, для быстрого поиска, а также возможности создания расширенного поиска (по датам, типа контента и т.д.)
Тем не менее, я еще полный нуб, в этой технологии. Тот фидбек, который мы получили с момента перехода на Elastic и выпуска расширения, явно указывает на то, что необходимы улучшения. Если кто-то готов поделится опытом, буду очень рад.
MongoDB наконец-то задышала свободно, Locked % держится на уровне 0.1% и не стремится вверх, что делает приложение действительно отзывчивым.
Если вы все еще используете MongoDB Full Text, то надеюсь этот пост вдохновит вас на переход к ElasticSeach.
