Перцептрон на numpy
Я придерживаюсь мнения, что если хочешь в чем-то разобраться, то реализуй этой сам. Когда я только начинал заниматься датасаенсом, я разобрался, как считать градиенты на бумажке, перескочил этап реализации сеток на numpy и сразу стал их обучать. Однако, когда спустя долгое я всё-таки решил это сделать, то столкнулся с тем, что не могу это сделать, потому что у меня не сходятся размерности.
Перебрав множество материалов, я остановился на книге Deep Learning from Scratch. Теперь я разобрался, и хочу сделать свой туториал.
На вопрос «Зачем очередной туториал с сеткой на numpy» я отвечу:
В туториале сделаны акценты в неочевидных местах, где могут не сходиться размерности;
В коде нет абстракций (классы слоёв), чтобы не отвлекать от сути.
Код доступен тут. Также можно посмотреть это видео с курса deep learning на пальцах, чтобы посчитать градиенты на бумажке.
Для того, чтобы обучить нейросеть, нам нужно понимать chain rule (дифференцирование сложной функции). Данное правило описывает, как брать производную композиций функций. Если у нас есть выражение y = f (g (x)), то производная y по x.

Так как нейронная сеть является большой композицией функций (слоёв), то для того, чтобы посчитать производную (градиент) ошибки мы перемножим производные всех слоёв.
Обучать будем двухслойный персептрон (два полносвязных слоя) с сигмоидальной функции активацией между слоями для задачи регрессии (предсказания цены дома) на датасете цен на дома в калифорнии.
w1 = np.random.randn(in_dim, hidden_dim)
b1 = np.zeros((1, hidden_dim))
w2 = np.random.randn(hidden_dim, out_dim)
b2 = np.zeros((1, out_dim))Нейронную сеть можно представить в виде следующего вычислительного графа:
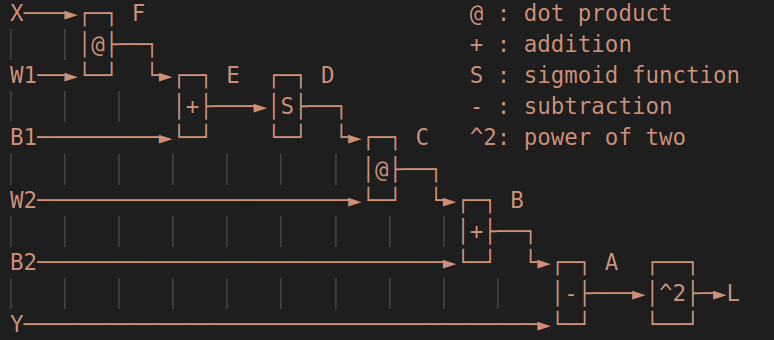 Вычислительный граф сети
Вычислительный граф сети
Это как раз композиция, и нам нужно знать производную функции ошибки для всех весов. Они будут такие:




Посчитаем все промежуточные производные:


В следующей производной могут возникнуть проблемы с размерностями. Единица здесь — это единичный вектор с размерностью как у С np.ones_like(C).

Аналогично np.ones_like(b2).

Тут тоже надо быть аккуратным. Так как производная по D, которая стоит слева, то нам нужно транспонировать w2 и ставить его справа при перемножении с другой матрицей np.dot(prev_grad, w2.T).

Аналогично нам нужно транспонировать D и ставить его слева при перемножении с другой матрицей np.dot(D.T, prev_grad)

У сигмоиды классная производная.

Тут np.ones_like(b1).

Тут np.ones_like(b1).

Тут нужно транспонировать D и ставить его справа при перемножении с другой матрицей np.dot(prev_grad, X.T)

В коде это выглядит так:
dLdA = 2 * A # (bs, out_dim)
dAdB = -1 # (bs, out_dim)
dBdC = np.ones_like(C) # (bs, out_dim)
dBdb2 = np.ones_like(self.B2) # (bs, out_dim)
dCdD = self.W2.T # (out_dim, hidden_dim)
dCdw2 = D.T # (hidden_dim, bs)
dDdE = D * (1 - D) # (bs, hidden_dim)
dEdF = np.ones_like(F) # (bs, hidden_dim)
dEdb1 = np.ones_like(self.B1) # (bs, hidden_dim)
dFdw1 = X.T # (in_dim, bs)
dLdb2 = np.mean(dLdA * dAdB * dBdb2, axis=0, keepdims=True) # (1, out_dim)
dLdw2 = np.dot(dCdw2, dLdA * dAdB * dBdC) # (bs, out_dim)
dLdb1 = np.mean(
np.dot(dLdA * dAdB * dBdC, dCdD) * dDdE * dEdb1, axis=0, keepdims=True
) # (1, hidden_dim)
dLdw1 = np.dot(
dFdw1, np.dot(dLdA * dAdB * dBdC, dCdD) * dDdE * dEdF
) # (bs, in_dim)Осталось только обновить веса в соответствии с посчитанными градиентами. Так как градиент показывает, какой вклад веса дают, чтобы функция ошибки росла, то мы его вычитаем. То есть, делаем шаг в сторону, чтобы ошибка уменьшалась.
b2 -= self.lr * dLdb2
w2 -= self.lr * dLdw2
b1 -= self.lr * dLdb1
w1 -= self.lr * dLdw1Как говорится «Охапку дров и перцептрон готов». Надеюсь, этот туториал поможет тем, кто столкнулся с той же проблемой, что и я.
А еще у меня есть телеграм канал, где я рассказываю про сетки с упором в инференс.
