Парсинг сайтов судов общей юрисдикции в России
История о том, как выявлять новые иски к клиенту
Содержание
Введение
Парсить сайты судов общей юрисдикции — законно?
Разведка боем
Что нужно от сайта
Выбор стратегии поиска
Собираем
Записываем
Формируем датасеты для сравнения, отчет
Отправляем отчет себе или коллегам на почту
Заключение
I. Введение
1. Статья не претендует на статус полноценного исследования и написана начинающим. Программирование — мое хобби, работаю юристом и специализируюсь на судебных спорах.
2. Доверитель захотел регулярно получать информацию обо всех исках, которые к нему предъявляют.
3. Споры бывают «бытовые» и коммерческие. Бытовые (потребительские, трудовые, «дачно-гаражно-дворовые» споры и др.) рассматриваются судами общей юрисдикции, коммерческие — арбитражными судами. Особняком стоят споры с гос.органами, которые при разных условиях рассматриваются и там, и там.
4. С мониторингом не завершенных коммерческих споров (когда дело еще рассматривается судом) все хорошо. Все арбитражные суды (чуть меньше 120) == один сайт с информацией о спорах. С ним можно подписаться на конкретную компанию или судебный спор, быстро найти информацию и получать апдейты о них.
Вводишь ИНН организации — и в поисковой выдаче все споры (как продолжающиеся, так и завершенные) с этой организацией во всех арбитражных судах России за все время существования сайта. Определение о принятии иска, об отложении / приостановлении разбирательства, о назначении экспертизы и др. Красота.
5. Совсем другое дерево — это общая юрисдикция. Запасись терпением всяк сюда входящий.
Если нужна информация о незавершенном споре в суде общей юрисдикции — добро пожаловать на 2500+ сайтов судов (не считая мировых судей, которых в 10 раз больше), унифицированного каталога либо нет, либо он недоступен простым смертным. Информацию о споре в конкретном суде получаем только на сайте этого суда через поиск.
Если нужен судебный акт по завершенному спору (для нашей задачи не интересен) — идем в ГАС «Правосудие». Все-таки случайно здесь появляются судебные акты по не завершенным спорам. Но подвох в том, что суды в 99% случаев не публикуют такие акты, и акты не попадают в видимый для пользователя сегмент ГАС «Правосудие». Для нашей задачи ГАС «Правосудие» — источник крайне не надежный.
6. Мега-приложение на 2500+ сайтов судов писать нет ресурсов, выбрали 19 наиболее вероятных для подачи иска судов. Сайты мировых судей отсекли из-за низкой цены потенциального иска (50 000 руб.).
7. Тайна юридической помощи — такая же важная, как медицинская или банковская. Поэтому в коде не будет ссылок, которые помогают раскрыть моего доверителя. Все герои вымышлены, а совпадения — случайны.
8. Использовать буду не «скраппинг», а старинное русское «парсинг» как более понятное широкому кругу читателей слово.
Ну что, погнали?

II. Парсить сайты судов общей юрисдикции — законно?
В повседневной работе я не занимаюсь глубоко вопросами интеллектуальной собственности.
Парсинг сайтов в мире и в России — вопрос актуальный и однозначного решения не имеет. Выражаясь грубо, правопорядки ищут компромисс между позициями «А чо, парсер же как человек смотрит, человеку же можно!» и «Это моя база данных, я ее танцую, и вообще у меня сервер от ваших ботов стонет».
Моими коллегами написано множество интересных материалов на эту тему. Есть уйма интересных судебных дел в других правопорядках (American Airlines v. FareChase, Facebook v. Power Ventures, Craigslist, Inc. v. Instamotor, Inc. и др.). Россия — не исключение, один только спор Double Data v. VK чего стоит.
Ситуация с некоммерческими сайтами судов яснее. Открытость и гласность — ключевые принципы судопроизводства. В отношении информации на сайте судов в России принят отдельный закон: Федеральный закон от 22.12.2008 № 262-ФЗ «Об обеспечении доступа к информации о деятельности судов в Российской Федерации». Помимо этого еще есть масса других документов, к примеру:
«Положение по созданию и сопровождению официальных Интернет-сайтов судов общей юрисдикции Российской Федерации» (утв. Постановлением Президиума Верховного Суда РФ от 24.11.2004);
«Регламент размещения информации о деятельности федеральных судов общей юрисдикции …» (утв. Приказом Судебного департамента при Верховном Суде РФ от 02.11.2015 № 335);
Постановление Пленума Верховного Суда РФ от 13.12.2012 № 35 «Об открытости и гласности судопроизводства и о доступе к информации о деятельности судов»;
«Концепция информационной политики судебной системы на 2020 — 2030 годы» (одобрена Советом судей РФ 05.12.2019);
Может быть, на каком-то из 2500+ сайтов судов есть правила конкретного сайта, но я с таким не сталкивался.
Во всех этих документах про парсинг, скраппинг, автоматизированный сбор данных нет ни слова. На то мы и юристы, чтобы говорить «да» или «нет» в отсутствие конкретного правила.
Есть ряд норм, которые позволяют утверждать, что собирать оттуда данные вполне себе законно (читать нужно возвышенно, с трепетом):
Часть 1, 3 статьи 4 Закона № 262-ФЗ: основными принципами обеспечения доступа к информации о деятельности судов являются 1) открытость и доступность информации о деятельности судов, за исключением случаев, предусмотренных законодательством Российской Федерации; 3) свобода поиска, получения, передачи и распространения информации о деятельности судов любым законным способом;
Часть 1, 2 ст. 8 Закона № 262-ФЗ: пользователь информацией имеет право 1) получать достоверную информацию о деятельности судов; 2) не обосновывать необходимость получения запрашиваемой информации о деятельности судов, доступ к которой не ограничен.
В Концепции (п. 4 выше) есть «угроза» парсингу, но она направлена на борьбу с охотниками за персональными данными:»особую важность приобретает проведение мероприятий по противодействию незаконной обработке и сбору сведений о гражданах, в том числе персональных данных граждан на территории Российской Федерации неуполномоченными и неустановленными лицами, а также используемыми ими техническими средствами». К слову, аппарат суда обязан сделать так, чтобы информация на сайте была анонимной. В судебных актах даже даты и суммы компенсаций морального вреда затирают, не говоря уже о персональных данных. Поэтому этот пункт концепции вряд ли коснется парсинга в обозримом будущем.
Есть и такой теоретический аргумент: право знать о о судебных делах со своим участием (в т.ч. с использованием парсинга, если законодатель не упростил поиск) — это элемент права на судебную защиту (ч. 1 ст. 46 Конституции РФ).
Учитывая:
содержание норм ст. 3, 8 Закона № 262-ФЗ;
что информация на сайтах судов != информации на сайтах судов коммерческих;
необходимость гласности и открытости судопроизводства;
что собирая информацию таким способом, я реализую свое право на судебную защиту,
я склонен толковать отсутствие прямого запрета на парсинг сайтов судов общей юрисдикции в пользу его правомерности. При этом этику парсинга никто не отменял.
Есть и «стахановцы» — Дальневосточный федеральный университет угрожал разработчикам уголовной ответственностью (ст. 272 УК РФ, «Неправомерный доступ к компьютерной информации»). No comments.
III. Разведка боем
Обобщим и проанализируем собственный пользовательский опыт.
1. Поиск на сайтах судов устроен по-разному, например:
Типичный случай — Центральный районный суд г. Красноярска: результаты поиска вносит прямо в html-код страницы, делая его удобным для сбора;
В противоположность коллегам Советский районный суд г. Казани отражает результат через обращение к «тайным сегментам» ГАС «Правосудие» с использованием Java Script.
Суды Санкт-Петербурга славятся не только диалектизмами, но и каптчей.
Суды Москвы, как положено москвичам, имеют абсолютно другой сайт. И по стилю, и по архитектуре, и по кодировке — UTF-8 вместо windows-1251. Он называется «портал» и охватывает все релевантные суды, например: Бабушкинский районный суд. Поиск спора там все равно происходит по отдельному суду.
2. Компания может называться на сайте по-разному, и поисковая выдача будет отличаться
Пример — Министерство финансов:
Ищем дела в Центральном районном суде г. Красноярска с участием «Министерство финансов РФ»:
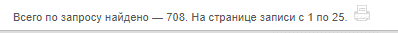
Ищем дела с участием «Минфин»:

Я проверил 5 случайных дел из 50 (выдача «Минфин»), 2 из них попали в 708 (выдача «Министерство финансов»), а 3 — нет.
Сюда попадают сложные / иностранные названия компаний.

3. Поиск по ИНН не всегда срабатывает
Не все суды указывают его в карточке дела => не все споры попадают в выдачу. Смотреть все равно приходится по названию компании или ФИО лица. Возьмем Минфин в Химкинском городском суде.
Поиск по названию «Министерство финансов РФ»:

Поиск по ИНН Министерства финансов РФ (7710168360):

4. Время отклика сайта отличается от 2 сек до 2 мин, и они постоянно падают
У меня стабильное подключение к интернету. Несмотря на это один и тот же сайт прогружается с разной скоростью, а иногда и вовсе падает. Обновил еще раз — заработало.
Как-то раз одновременно и ровно на 5 дней упало 12 сайтов из 19.
5. Гражданские и административные дела в первой инстанции == один каталог
Я не нашел ни одного суда из 19, который для поиска административных дел создал бы отдельный каталог для споров с гос.органами. Задача немного проще, т.к. один сайт суда == один каталог.
6. Полезное наблюдение
У каждого сайта есть счетчик дел, которые сайт нашел применительно к конкретной компании:


Однако иски к моему доверителю есть не во всех судах, поэтому может срабатывать и такое:


Выводы по итогам разведки:
Я пока не умею преодолевать капчи, сайты судов Спб недоступны для меня. Аналогично с сайтами, получающими данные от других сайтов через Java Script. Благо, среди тех 19 сайтов их не оказалось.
Написать что-то унифицированное тоже вряд ли получится — сайты различаются.
Придется выяснить все возможные названия доверителя, чтобы поисковая выдача была полной.
У парсера нужно сделать «вторую попытку» попасть на сайт.
Сайт обновляется, смотреть его нужно каждый день и сравнивать результаты с предыдущими наблюдениями.
IV. Что нужно от сайта
Стандартная поисковая выдача не-московских судов выглядит так:
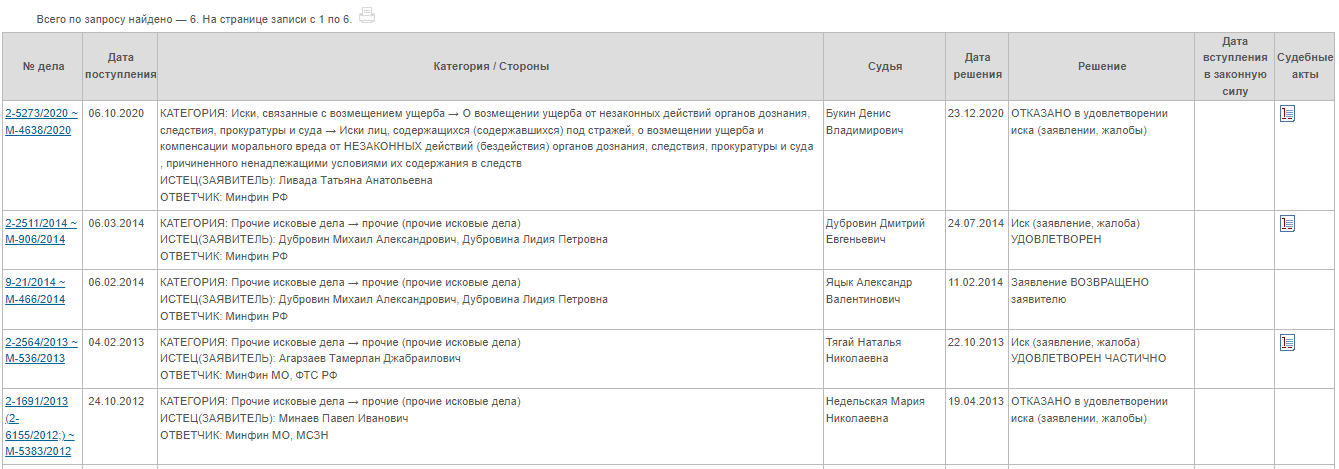
У московских — так:

Как видим, указывается № дела, дата поступления, стороны, судья и др. Не всегда поисковая выдача влезает на 1 страницу.
При переходе в конкретное дело появляется справочная информация:

Поскольку доверитель — не частый гость в судах, судебное дело для него — серьезное событие. Появления дела на сайте уже достаточно, чтобы юрист начал тратить на него время: знакомиться с материалами дела, запрашивать информацию у коллег и суда и др. Заставлять парсер считывать и выгружать еще и карточки по конкретным делам не нужно — достаточно уведомить юриста о появлении нового дела в конкретном суде.
Это сильно облегчает задачу — нужен парсер-«будильник», который сообщает о новом деле.
V. Выбор стратегии поиска
Среди вариантов сбора наиболее подходящие:
Считаем количество вхождений названия доверителя каждый день, если вхождений стало больше => появилось новое дело.
Смотрим на дату: как только а) появилась новая дата (счетчик) или б) дата позднее определенного числа => появилось новое дело. Этот подход очень удобен при ручном сборе данных.
У каждого суда есть счетчик дел по конкретному делу. Счетчик по сравнению со вчерашним днем увеличился => появилось новое дело.
Попробовав все варианты по очереди, всласть наигравшись с датами, остановился на варианте № 3 как на самом простом и посильном для меня.
VI. Собираем
Нужно собрать конкретный кусок html-кода с 19 неодинаковых сайтов.
Я разрубил гордиев узел. На сайте вручную нашел нужную поисковую выдачу и скопировал ссылку из браузера. Все. Какой уж там Scrapy или Selenium. Даешь request-хардкор!
Получилось так:
import pandas as pd
import os
import requests
import re
import datetime
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
headers = {'user-agent': '__________'}
############################### СОБИРАЕМ ИНФОРМАЦИЮ ПО КАЖДОМУ СУДУ ИЗ СПИСКА ################################
#N-ский районный суд
response = requests.get("https://огромная в 8 строк ссылка на конкретную поисковую выдачу N-ского районного суда", headers=headers)
response.encoding = 'windows-1251'
pattern = re.compile(r'Всего по запросу найдено.....')
c = pattern.findall(response.text)
err = 0
try:
print('N-ский районный суд', datetime.date.today(), c[0][27:]) #индекс переменной c для каждого сайта подбирал руками. Помните? Только request-хардкор!
except IndexError:
try:
print('N-ский районный суд', datetime.date.today(), c[0][27:]) # распечатка нужна для отладки и просмотра работы при запуске в терминале
except IndexError:
err = 1
# N5-ский районный суд, где судов в отношении доверителя нет вовсе
response5 = requests.get('https://mos-gorsud.ru/rs/babushkinskij/search?formType=shortForm&courtAlias=babushkinskij&uid=&instance=&processType=&letterNumber=&caseNumber=&participant=ИКЕА',
headers=headers)
pattern5 = re.compile(r'ничего не найдено')
c5 = pattern5.findall(response5.text)
err5 = 0
if c5 == ['ничего не найдено']:
print("N5-ский районный суд ", datetime.date.today(), 0)
else:
try:
print("N5-ский районный суд ", datetime.date.today(), c5[0][27])
except IndexError:
try:
print("N5-ский районный суд ", datetime.date.today(), c5[0][27])
except IndexError:
err5 = 1
После получения ссылки находим в ней нужные слова, потом выводим результат, проиндексировав pattern.
И так применительно ко всем 19 судам по одному наименованию доверителя. Там, где кодировка UTF-8, я ее не указывал, но все работало. На создание ссылок ушло 30 минут. Даже подумал, что парсер не нужен, надо выписать эти ссылки в отдельный документ и просто каждое утро открывать их в браузере руками.
Если нужно было бы обработать 200+ сайтов судов — задача заиграла бы новыми красками.
VII. Записываем
Прежде чем записывать собранную информацию, создадим переменные дат, чтобы хранить и сравнивать результаты в .txt-файлах. Сравнивать будем за 3 дня.
date = datetime.date.today()
filename_today = str(datetime.date.today()) + str('.txt')
filename_yesterday = str(datetime.date.today()-datetime.timedelta(days=1)) + str('.txt')
filename_2_days_ago = str(datetime.date.today()-datetime.timedelta(days=2)) + str('.txt')При написании этой истории для Хабра меня осенило, что это можно было проще запилить через MySQL, но это уже «на будущее».

Формируем строку для записи:
# N-ский районный суд
if err == 1: #на случай, если сайт не прогрузился или упал.
N-sk = str('N-ский районный суд ') + str(date) + ' ' + str(0.1) # указываем десятичную дробь, чтобы при сравнении датасетов было видно, что информация с сайта не получена
else:
N-sk = str('N-ский районный суд ') + str(date) + ' ' + str(c[0][27:])
# N5-ский районный суд, где судов в отношении доверителя нет вовсе
if c5 == ['ничего не найдено']:
N5-sk = str('N5-ский ') + str(date) + ' ' + str(0)
elif err4 == 1:
N5-sk = str('N5-ский ') + str(date) + ' ' + str(0.1)
else:
N5-sk = str('N5-ский ') + str(date) + ' ' + str(c15[0][2]
VIII. Формируем датасеты для сравнения и отчёт
x = pd.read_csv(filename_today, sep=" ", header=None)
y = pd.read_csv(filename_yesterday, sep=" ", header=None)
z = pd.read_csv(filename_2_days_ago, sep=" ", header=None)
col1 = x[2]
col2 = y[2]
col3 = z[2]
consolidated_table = z.join(col2, rsuffix='Вчера').join(col1)
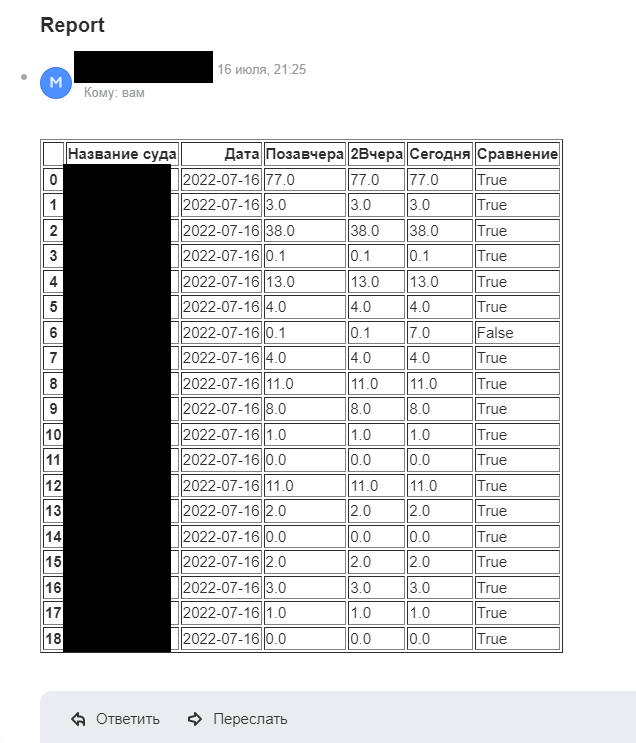
consolidated_table.rename(columns={0: 'Название суда', 1: 'Дата', '2': 'Позавчера', 2: 'Сегодня'}, inplace=True)
consolidated_table['Сравнение'] = (consolidated_table['Сегодня'] == consolidated_table['Позавчера']) & (consolidated_table['Сегодня'] == consolidated_table['2Вчера'])
html_table = consolidated_table.to_html()
Как ни крутил .join, так и не смог в итоговой выдаче избавиться от »2Вчера».
IX. Отправляем отчёт себе или коллегам на почту
msg = MIMEMultipart()
message = 'Report'
# определяем параметры сообщения
password = ""
msg['From'] = ""
msg['To'] = ""
msg['Subject'] = "Report"
# добавляем текст сообщения
html_table = MIMEText(html_table, 'html')
msg.attach(html_table)
# создаем сервер
server = smtplib.SMTP('smtp._______: 587')
server.starttls()
# логинимся для отправки
server.login(msg['From'], password)
# отправляем
server.send_message(msg)
server.quit()
print("Отправлено: %s:" % (msg['To']))
Хотя подключение и разрешения для отправки писем и предусмотрено стандартными почтами, мне пришлось повозиться с подключением и разрешениями отправлять письма с этого адреса. К своему стыду не сразу понял, что письма с отчетами автоматически улетали в спам.
Вот так выглядит результат анализа, который приходит на почту каждые 8 часов (спасибо планировщику задач, который запускает программу по расписанию):
Итоговый код выложил на Гитхабе здесь.
X. Заключение
Из моих мытарств случился рабочий код, который экономит время. Отсмотрел код в очередной раз и теперь не уверен, что это «приложение» можно назвать парсером в чистом виде.
Что дальше:
Краулеры под отдельные типы сайтов или хотя бы функция, которая перебирает словарь, чтобы код было удобнее сопровождать и проводить отладку.
Доставать данные с сайтов судов, которые обращаются к другим через Java Script, обходить питерские каптчи. Интересно какие еще сюрпризы таят в себе 2500+ сайтов.
Уйти от сравнения данных через .txt файлы, при долговременном использовании неудобно.
Буду благодарен за критику.
