Парсинг FIT файлов c данными тренировок
 Oscar Wong / Getty Images
Oscar Wong / Getty Images
Мне стало интересно проанализировать данные о своих тренировках за последние несколько лет, и я понял, что обычного функционала приложений типа Garmin Connect или бесплатной версии Strava будет недостаточно. В этой статье я расскажу как получить свои персональные данные о тренировках из устройств Garmin и разместить их в реляционной базе данных с помощью библиотек python.
Что такое FIT файл и что он может содержать
Если вы используете носимые устройства (фитнес-браслеты, часы, смартфоны, велокомпьютеры) для записи своих активностей или тренировок, то скорее всего информация будет сохранена в FIT файле активности — наиболее распространенный формат, используемый в фитнес-приложениях для обмена детальными данными о совершенных тренировках.
Для каждой отдельной активности файл включает в себя набор обязательных и дополнительных сообщений. Я разобрался с обязательными: они включают в себя записи о дате и времени тренировки, ее типе спорта, данные о кругах, GPS-трек, данные с сенсоров (может быть датчик пульса, датчик каденса/скорости, мощемер и прочее). Подробнее о структуре каждого сообщения ниже в таблице.
Название сообщения | Описание и содержание сообщения |
File Id | Содержит данные о производителе устройства сбора данных и название устройства |
Activity | Включает данные о дате и времени активности, общее время, количестве сессий |
Session | Обобщенная информация об активности (средняя и максимальная скорость, общее время, общее расстояние, общий набор высоты, вид и подвид спорта, средняя и максимальная частота пульса и другие) |
Lap | Отображает обобщенные сведения о кругах или интервалах в рамках одной активности (номер круга, общее расстояние круга, максимальная скорость круга и другие). Может быть несколько кругов для одной активности |
Record | Содержит данные со всех сенсоров в момент времени (координаты, номер круга, абсолютная высота на местности, дата и время, значение пульса, каденса, скорости, мощности, температуры воздуха и другие) |
Как получить доступ к данным
Все персональные данные о тренировках, собранные с помощью устройств Garmin (в моем случае это несколько версий часов и велокомпьютер), можно получить по запросу с официального сайта Garmin. После запроса в течение 48 часов вам на почту должна быть прислана ссылка на загрузку пакета данных.
 Сообщение от Garmin о готовности пакета с данными для скачивания
Сообщение от Garmin о готовности пакета с данными для скачивания
В скачанном архиве наиболее ценные файлы с точки зрения данных об активностях будут находиться в папке DI_CONNECT\DI-Connect-Fitness-Uploaded-Files\UploadedFiles_0-_Part1. Каждый файл содержит информацию об одной совершенной активности.
Структура данных
На базе PostgreSQL я создал пять новых таблиц, которые будут соответствовать сообщениям из FIT файла — File Id, Activity, Session, Lap, Record. Таблица Activity будет содержать в себе ключ (activity_id) к каждой уникальной активности, все остальные таблицы будут содержать этот ключ как foreign key. При парсинге файла заполнение таблиц будет начинаться именно с сообщения Activity. Сгенерированная в PostgreSQL ERD схема базы данных представлена ниже.
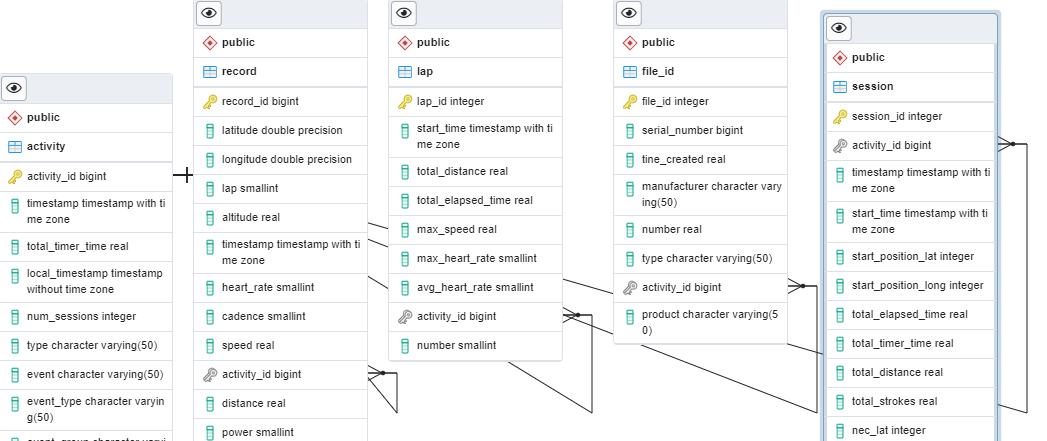 Фрагмент ERD схемы, сгенерированной в PostgreSQL для базы данных активностей
Фрагмент ERD схемы, сгенерированной в PostgreSQL для базы данных активностей
Описание кода
Для декодирования, чтения и загрузки и проверке данных об активностях из FIT файлов в таблицы PostgreSQL я использовал Jupiter Notebook и несколько библиотек python, в том числе os, pandas, psycopg2, fitdecode и matplotlib.
Код для каждого файла из указанной выше папки проходит следующие шаги:
Извлечение уникального номера активности и идентификатора пользователя из названия FIT файла
Чтение, декодирование и запись данных в датафрейм для каждого из пяти сообщений (File Id, Activity, Session, Lap, Record)
Загрузка датафреймов в соответствующую таблицу PostgreSQL
Я подготовил схему данных для каждой из таблиц, чтобы код искал только те поля данных, которые мне будут необходимы из каждого отдельного сообщения. Например, из сообщения Activity мне нужны следующие данные:
activity = ['timestamp', 'total_timer_time', 'local_timestamp', 'num_sessions', 'type', 'event', 'event_type', 'event_group']Извлечение кода активности и идентификатора пользователя
Названия файлов могут варьироваться по содержанию, но всегда содержат идентификатор пользователя и номер активности как два первых параметра, разделенных символом '_'. Для извлечения этих параметров использовал простую функцию:
def get_user_activity_details(file):
filename = os.path.basename(file)
user_id, activity_id = filename.split('_')[0], filename.split('_')[1]
if '.' in activity_id:
activity_id = activity_id.split('.')[0]
return user_id, activity_idЧтение, декодирование и запись данных в датафрейм
Для парсинга FIT файла была использована специальная библиотека fitdecode. Здесь можно найти исходную документацию. Установка библиотеки через PyPI:
pip install fitdecodeБиблиотека позволяет создать объект FitReader, который считывает FIT файл и получает доступ к каждому сообщению (или фрейму) в этом файле. Каждый фрейм включает в себя FitHeader, FitDefinitionMessage, FitDataMessage, FitCRC. Нас будет интересовать только FitDataMessage, так как он содержит в себе данные об активности. В этой статье описано подробнее.
Пример извлечения данных из сообщения Activity в датафрейм ниже:
def get_fit_other_data(col, frame: fitdecode.records.FitDataMessage) -> Optional[Dict[str, Union[float, int, str, datetime]]]:
data: Dict[str, Union[float, int, str, datetime]] = {}
for field in col:
if frame.has_field(field):
data[field] = frame.get_value(field)
return data
def get_dataframes(fname: str) -> Tuple[pd.DataFrame]:
activity_data = []
with fitdecode.FitReader(fname) as fit_file:
for frame in fit_file:
if isinstance(frame, fitdecode.records.FitDataMessage):
if frame.name == 'activity':
activity_data.append(get_fit_other_data(activity, frame))
activity_df = pd.DataFrame(activity_data, columns = activity)
df['activity_id'] = activity_id
if activity_df.empty:
activity_df = activity_df.append({'activity_id':activity_id}, ignore_index=True)
return activity_dfЗагрузка датафрейма в таблицу базы данных
Для подключения и загрузки данных в PostgreSQL я использовал стандартную библиотеку psycopg2. Пример загрузки данных из датафрейма Activity в соответствующую таблицу ниже:
def load_dataframe_to_postgres(df, tabl):
if not df.empty:
df = df.fillna(0)
cursor = conn.cursor()
if tabl == 'activity':
df = df.astype({'activity_id': 'int64','timestamp': 'datetime64[ns, UTC]', 'total_timer_time': 'float64', 'local_timestamp': 'datetime64[ns]', 'num_sessions': 'int64', 'type': 'object', 'event': 'object', 'event_type': 'object', 'event_group': 'object'})
for index, row in df.iterrows():
cursor.execute("""insert into activity(activity_id, timestamp, total_timer_time, local_timestamp, num_sessions, type, event, event_type, event_group)
values (%s, %s, %s, %s, %s, %s, %s, %s, %s)""", [row.activity_id, row.timestamp, row.total_timer_time, row.local_timestamp, row.num_sessions, row.type, row.event, row.event_type, row.event_group])
conn.commit()
cursor.close()Проверка полученных данных
Для проверки адекватности полученных данных я попробовал визуализировать количество минут, потраченных на вид активности по месяцам за весь доступный период времени (с апреля 2014 по февраль 2022).
Мне было достаточно обобщенных данных из таблицы Session — я использовал поля с данными о дате активности, ее продолжительности и виде (timestamp, total_timer_time, sport). Итоговые данные сгруппированы по месяцам и виду активности.
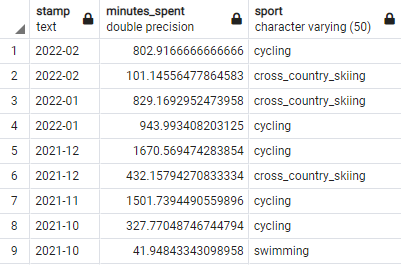 Фрагмент таблицы со сгруппированными данными из таблицы Session
Фрагмент таблицы со сгруппированными данными из таблицы Session
# get session data summary with sport split
conn = psycopg2.connect(host="localhost", database="garmin_data", user="postgres", password="afande")
df = pd.read_sql_query("""select to_char(timestamp, 'YYYY-MM') as stamp, sum(total_timer_time / 60) as minutes_spent, sport
from session
group by to_char(timestamp, 'YYYY-MM'), sport
having sum(total_timer_time / 60) > 0
order by to_char(timestamp, 'YYYY-MM') desc""", conn)Дополнительно был создан датафрейм со всеми месяцами для их отображения на графике даже при нулевом значении (когда не было ни одной завершенной активности). Для этого были определены самый ранний и самый поздний месяцы, которые есть в таблице. После создан range с шагом в месяц и этими месяцами как граничными значениями.
# get min and max dates from the dataframe
min_date = datetime.strptime(min(df.stamp), '%Y-%m')
max_date = datetime.strptime(max(df.stamp), '%Y-%m')
n_max_date = max_date + pd.DateOffset(months=1)
# create a table with all months from min to max date
data = pd.DataFrame()
data['Dates'] = pd.date_range(start=min_date, end=n_max_date, freq='M')
data['Dates'] = data['Dates'].dt.strftime('%Y-%m')
# merge datasets
df_main = pd.merge(data, df, left_on='Dates', right_on='stamp', how='left', indicator=True)
df_main = df_main[['Dates', 'minutes_spent','sport']]
df_main = df_main.fillna(0)Сводная таблица была использована для построения графика stacked bar из библиотеки matplotlib. На график дополнительно добавлена разграфка по годам в виде вертикальных разделительных линий.
# pivot table
df_pivot = pd.pivot_table(df_main, index='Dates', columns='sport', values='minutes_spent').reset_index()
df_pivot = df_pivot.fillna(0)
df_pivot = df_pivot[['Dates', 'cross_country_skiing', 'cycling', 'running', 'swimming', 'walking']]
# create stacked bar chart for monthly sports
df_pivot.plot(x='Dates', kind='bar', stacked=True, color=['r', 'y', 'g', 'b', 'k'])
# labels for x & y axis
plt.xlabel('Months', fontsize=20)
plt.ylabel('Minutes Spent', fontsize=20)
plt.legend(loc='upper left', fontsize=20)
for num in [69, 57, 45, 33, 21, 9]:
plt.axvline(linewidth=2, x=num, linestyle=':', color = 'grey')
# title of plot
plt.title('Minutes spent by Sport', fontsize=20)
plt.rcParams['figure.figsize'] = [24, 10] График с количеством минут, потраченных на виды активностей по месяцам
График с количеством минут, потраченных на виды активностей по месяцам
Итоговый график правдоподобно отображает количество минут потраченных на виды активностей — например максимум минут на велосипеде в апреле-мае 2019 года соответствует велотуру по Скандинавии, отсутствие велотренировок в августе-сентябре 2021 года из-за травмы и их замены на занятия по плаванию и пешими прогулками, появление лыжных тренировок с декабря 2021 года соответствует обкатке новой пары лыж.
Итоги
Всего я получил доступ к 5,300 FIT файлам, среди которых только один оказался битым и не выдавал доступ к данным. Полный код для загрузки данных из всех главных сообщений FIT файла в таблицы PostgreSQL DB можно найти здесь.
Данный метод позволяет получить доступ ко всем историческим данным одновременно и проводить дальнейший анализ в удобной среде.
Стоит отметить, что существует способ получения данных через Activity API, он больше ориентирован для разработчиков приложений, которым необходим постоянный доступ к обновляемым данным.
