Отличаем автобус от автомобиля по GPS-трекам
 Фото Artem SvetlovДля построения правдоподобной пробочной картины проект Карты Mail.Ru обрабатывает большое количество информации по GPS-трекам участников движения. Часто о самом источнике треков мало что известно, в том числе из соображений безопасности. Но для определения истинной ситуации на дорогах мне всегда хотелось знать больше. Хотя бы для того, чтобы понимать насколько скорость машины источника соответствует скорости остального потока. В данной статье речь пойдёт о методе выделения маршрутных транспортных средств (автобусов, троллейбусов, маршруток и трамваев) из необработанного потока данных GPS.Маршрутные транспортные средства чаще всего движутся не со скоростью остального потока. Они, конечно, могут быть индикаторами транспортной ситуации, но с некоторой спецификой: Автобусы и троллейбусы, как правило, имеют свой график движения с большим количеством остановок на маршруте. Это значит, что по свободной дороге автобус будет ехать заведомо медленнее потока и часто останавливаться на непродолжительное время. В час пик, когда автобусы ходят с интервалом в 7–10 минут, они могут прислать достаточное количество информации о снижении скорости потока в районе остановки.
Благодаря выделенным полосам, автобус может ехать быстрее потока в пробке.
Водители маршруток часто ездят вопреки всяким правилам.
Отдельно хотелось бы описать трамваи, которые практически всегда ездят по выделенным полосам, проходящим рядом или по центру улиц с автомобильным движением. Поэтому трек трамвая практически не отличим от трека автомобиля.
Заранее оговорюсь, что целью статьи не является сравнить, какая из спутниковых систем навигации лучше. Практически на всех клиентских устройствах сейчас стоят чипы, которые принимают данные от всех доступных систем и выдают обобщённые координаты. Для экономии места здесь и в дальнейшем буду называть трек, полученный с использованием спутниковой системы навигации, GPS-треком.Для начала, давайте определим, что такое GPS-трек. GPS-трек — это последовательность координат положения устройства во времени. К сожалению, единственное, что мы знаем о каждом присылающем трек устройстве — это его уникальный идентификационный номер. Таковы жёсткие требования конфиденциальности.
Фото Artem SvetlovДля построения правдоподобной пробочной картины проект Карты Mail.Ru обрабатывает большое количество информации по GPS-трекам участников движения. Часто о самом источнике треков мало что известно, в том числе из соображений безопасности. Но для определения истинной ситуации на дорогах мне всегда хотелось знать больше. Хотя бы для того, чтобы понимать насколько скорость машины источника соответствует скорости остального потока. В данной статье речь пойдёт о методе выделения маршрутных транспортных средств (автобусов, троллейбусов, маршруток и трамваев) из необработанного потока данных GPS.Маршрутные транспортные средства чаще всего движутся не со скоростью остального потока. Они, конечно, могут быть индикаторами транспортной ситуации, но с некоторой спецификой: Автобусы и троллейбусы, как правило, имеют свой график движения с большим количеством остановок на маршруте. Это значит, что по свободной дороге автобус будет ехать заведомо медленнее потока и часто останавливаться на непродолжительное время. В час пик, когда автобусы ходят с интервалом в 7–10 минут, они могут прислать достаточное количество информации о снижении скорости потока в районе остановки.
Благодаря выделенным полосам, автобус может ехать быстрее потока в пробке.
Водители маршруток часто ездят вопреки всяким правилам.
Отдельно хотелось бы описать трамваи, которые практически всегда ездят по выделенным полосам, проходящим рядом или по центру улиц с автомобильным движением. Поэтому трек трамвая практически не отличим от трека автомобиля.
Заранее оговорюсь, что целью статьи не является сравнить, какая из спутниковых систем навигации лучше. Практически на всех клиентских устройствах сейчас стоят чипы, которые принимают данные от всех доступных систем и выдают обобщённые координаты. Для экономии места здесь и в дальнейшем буду называть трек, полученный с использованием спутниковой системы навигации, GPS-треком.Для начала, давайте определим, что такое GPS-трек. GPS-трек — это последовательность координат положения устройства во времени. К сожалению, единственное, что мы знаем о каждом присылающем трек устройстве — это его уникальный идентификационный номер. Таковы жёсткие требования конфиденциальности.
Все треки имеют различную природу и приходят от различных поставщиков. В данной статье я буду рассматривать случай, когда устройство жёстко закреплено на транспортном средстве и присылает данные через равные промежутки времени. Это упрощение позволит мне не рассматривать ситуацию, когда записывающее трек устройство было в руках у кого-то, потом этот кто-то сел в автобус и проехал на нём пару остановок.
Целью анализа будет выделение из общего списка треков тех, которые большую часть времени передвигаются по одинаковым последовательностям улиц — маршрутам.
Первым делом исходный непрерывный трек необходимо разделить на единичные поездки, которые мы и будем сравнивать между собой. Как было описано ранее — физически на машинах стоит GPS-трекер, который раз в несколько секунд присылает свои координаты. Чаще всего трекер работает, когда у машины включено зажигание, но есть устройства, которые работают круглосуточно. Поэтому разделителем поездок примем продолжительный отрезок времени, на котором скорость была всегда 0 или устройство не присылало данные.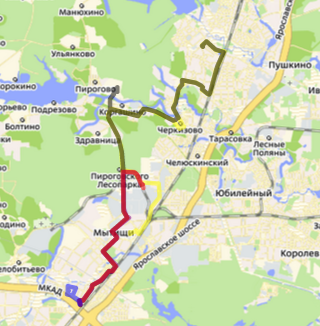 Пример разделения трека на поездки
Пример разделения трека на поездки
Теперь для каждого транспортного средства у нас есть набор треков-поездок, которые оно совершило за определённый период времени. Среди них есть как реальные поездки, так и малосвязанные треки, вызванные ошибками определения координат, перемещениями внутри закрытой зоны предприятия, «перепарковками» и тому подобным мусором. Чтобы не тратить на него вычислительные ресурсы, я фильтрую все треки длинной менее 400 метров, количеством точек меньше 10 и географическим разбросом менее 200 метров для ограничивающего трек прямоугольника (bounding box). Это позволит избежать треков-звёздочек, которые образуются из-за больших случайных ошибок GPS-приёмника.
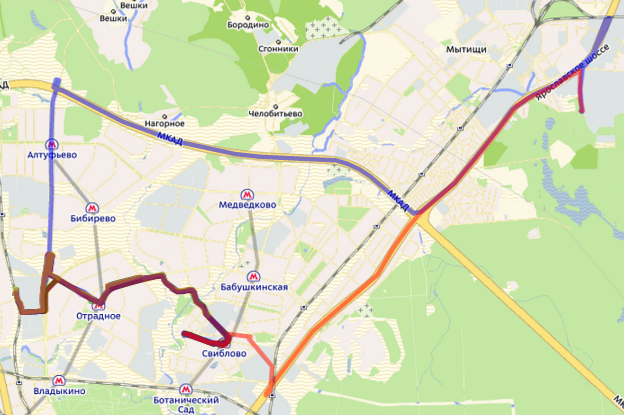
 Характерные треки-звёздочки
Характерные треки-звёздочки
Следующая задача — сравнить эти треки между собой и определить, проходят ли они по одному и тому же маршруту. Для этого первым делом я приведу все GPS-треки в единую форму, привязав их к нашему дорожному графу. О работе привязчика я писал в своём прошлом посте. С тех пор он претерпел некоторые изменения, но основные принципы остались такими же. На выходе из привязчика я получаю трек в виде цепочки пар (id ребра графа, направление (прямое или обратное)). На этом этапе можно отфильтровать треки, которые не ложатся на наш дорожный граф. Это могут быть треки от самолётов/вертолётов, контейнеров в морях, зерноуборочных комбайнов. Или просто от машин, которые проехали по местам, где у нас по тем или иным причинам нет дорожного графа. Хочу заметить, что здесь фильтруются только те треки, которые совсем не соответствуют дорожному графу. Если машина выезжала со стоянки, где у нас нет дорожного графа, потом долго ехала по дорогам, где привязалась к дорожному графу и в конце пути заехала на стоянку (где снова нет дорожного графа), то такой трек будет засчитан.
Получившиеся цепочки уже гораздо проще сравнивать между собой. Я просматривал различные метрики сравнения и остановился в итоге на метрике Левенштейна. Алфавитом в данном случае является набор всех возможных пар ребро-направление. Таким образом, я получил возможность численно определить «похожесть» треков как количество правок рёбер маршрута (добавление/удаление/замена ребра), чтобы из одного маршрута получить другой маршрут.
Следующим шагом стоит группировка треков по маршрутам. Этот вопрос решают алгоритмы кластеризации данных. Так как у меня уже есть одномерная метрика «похожести» треков, я взял самый простой алгоритм иерархической кластеризации данных: дендрограмму. Дерево строится на основании минимального расстояния Левенштейна и после разбиваются его ветки, отличающиеся более чем на n рёбер. Императивно получилось вычислить оптимальное n равное 16.
В итоге я получаю набор кластеров, хранящих в себе похожие маршруты. Обладая этой информацией, уже можно сделать вывод о том, ездит ли транспортное средство по заранее заданному маршруту. У меня были идеи использовать различные n в зависимости от количества рёбер в маршруте, но это улучшение не даёт прироста качества поиска, и я решил оставить фиксированное n.
Изначально были мысли, что большинство транспортных средств имеют 2 маршрута следования (от конечной до конечной) в обе стороны. Но, как показала практика, иногда маршрут может быть круговым, или состоять из нескольких частей.
 Маршрутные транспортные средства не всегда перемещаются по маршруту. Есть поездки в гараж, на заправку и т.д.
Маршрутные транспортные средства не всегда перемещаются по маршруту. Есть поездки в гараж, на заправку и т.д.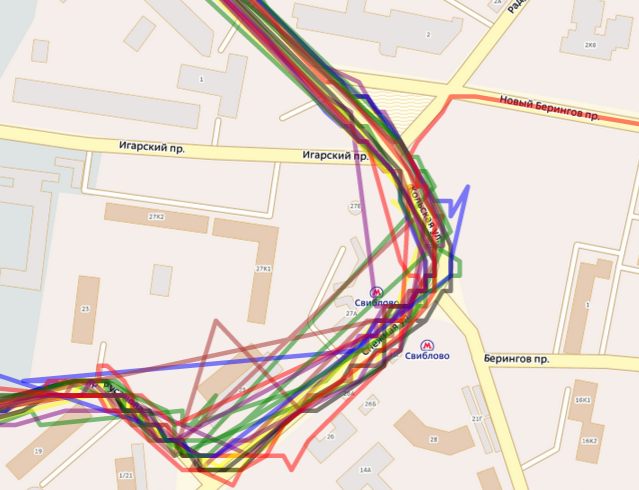 Треки с маршрута. Вид вблизиТаким образом, у большинства транспортных средств есть хотя бы один кластер в котором копятся поездки, и несколько служебных: одноразовых или более редких маршрутов (до гаража, до заправки и так далее). На основе полученных данных можно проверить ещё одну гипотезу: раз мы имеем маршруты транспортных средств и метрики сравнения маршрутов, то мы можем выделить транспортные средства, работающие на одном и том же маршруте. Для этого нужно всего лишь взять отдельные кластеры разных транспортных средств и сравнить их между собой (тем более функция сравнения кластеров уже есть в реализации иерархического дерева).
Треки с маршрута. Вид вблизиТаким образом, у большинства транспортных средств есть хотя бы один кластер в котором копятся поездки, и несколько служебных: одноразовых или более редких маршрутов (до гаража, до заправки и так далее). На основе полученных данных можно проверить ещё одну гипотезу: раз мы имеем маршруты транспортных средств и метрики сравнения маршрутов, то мы можем выделить транспортные средства, работающие на одном и том же маршруте. Для этого нужно всего лишь взять отдельные кластеры разных транспортных средств и сравнить их между собой (тем более функция сравнения кластеров уже есть в реализации иерархического дерева).

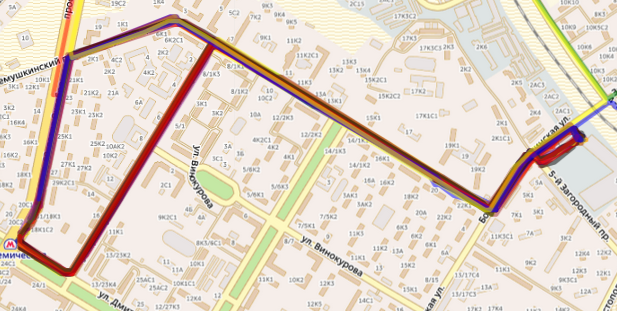 Два различных автобуса, перемещающихся по одинаковым маршрутамТаким образом, я могу уточнить маршрут и группировать транспортные средства по паркам.
Два различных автобуса, перемещающихся по одинаковым маршрутамТаким образом, я могу уточнить маршрут и группировать транспортные средства по паркам.
Анонимные данные GPS несут в себе множество информации. Правильно анализируя эти данные, можно узнать много дополнительной информации как о создавшем трек транспортном средстве, так и о самом городе и его дорогах. Поэтому область применения этих треков не должна ограничиваться получением информации о пробках, а сама информация может принести пользу не только автолюбителям, но также коммунальным и градостроительным службам. При этом для обработки этих треков не обязательно знать точные данные о машине, которая их создаёт. Всю необходимую информацию о транспортном средстве может рассказать статистика его перемещений. Одновременно с этим, GPS-треки — это неточный инструмент определения информации. Для получения результата необходимо исследовать большое количество данных, что предъявляет высокие требования к обрабатывающей инфраструктуре.
