Откуда Карты знают, когда приедет автобус
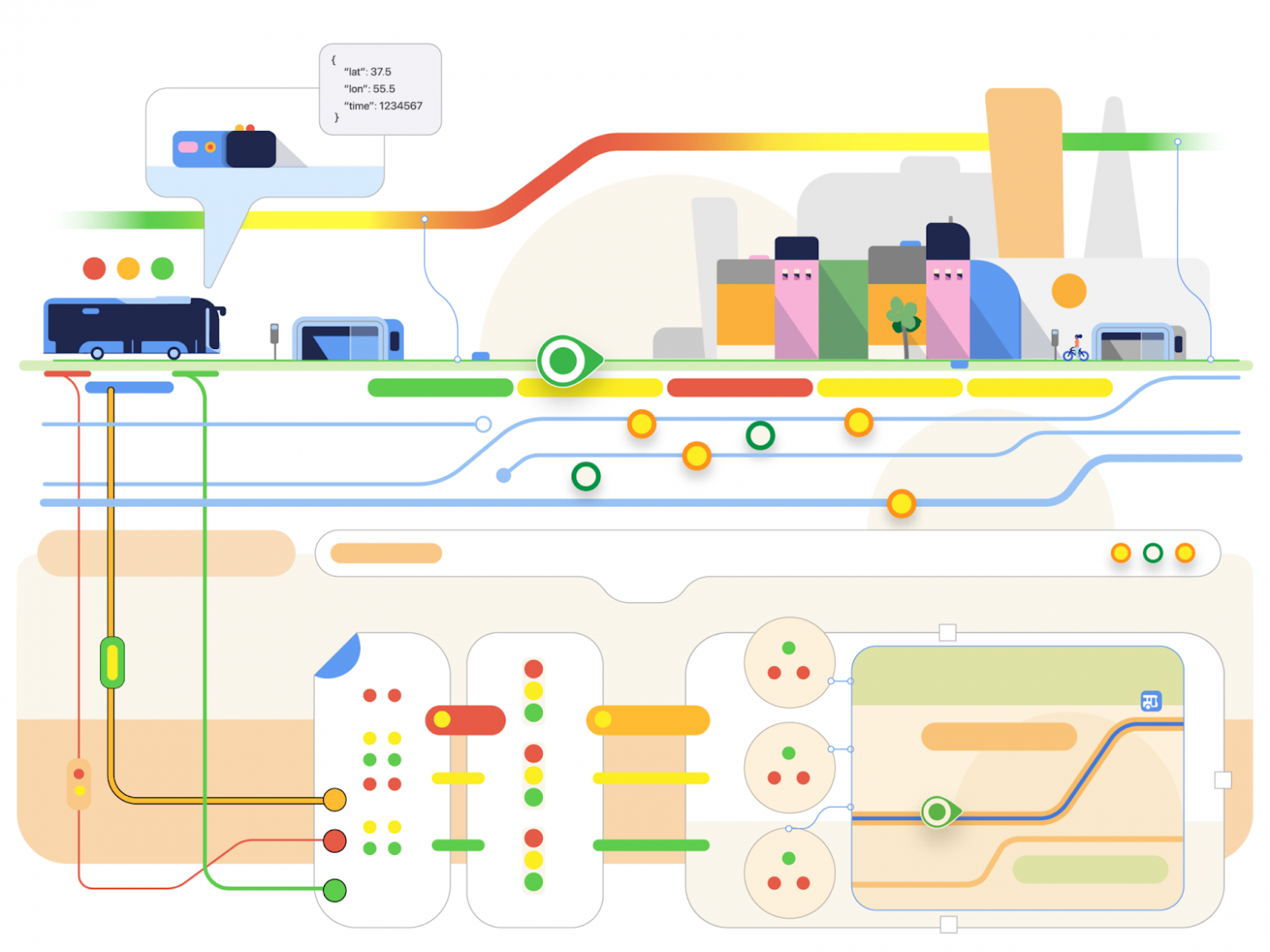
Раздел «Транспорт» — один из самых популярных в Яндекс Картах: там автобусы, троллейбусы и трамваи перемещаются прямо по карте в реальном времени, а для каждой остановки есть виртуальное табло. Можно посмотреть, сколько ещё ждать транспорт, или понять, когда лучше выходить из дома, чтобы его не пропустить. А если оказались в незнакомом районе — узнать, как быстрее добраться домой, и сразу найти ближайшую остановку или станцию метро.
Меня зовут Антон Овчинкин, я руководитель группы разработки пешеходной и транспортной навигации. Сегодня я расскажу, что у «Транспорта» под капотом, какие алгоритмы отвечают за то, чтобы автобусы появлялись на карте, двигались по ней плавно и реалистично, а прогноз был максимально точным.
Транспорт подаёт сигналы
Всё начинается с GPS-приёмников — они установлены в транспорте и с помощью спутников примерно раз в минуту определяют координаты. Эти приёмники не принадлежат Яндексу, их устанавливают сами перевозчики. Пока они установлены не везде, поэтому некоторые автобусы могут быть не видны на карте.
Определив свою геопозицию, приёмник отправляет этот сигнал на сервер партнёров Яндекса. Партнёры каждую секунду присылают нам сотни таких сигналов, и они попадают в сервис приёма реалтайм-данных.
Там сигналы проходят базовую проверку — важно убедиться, что они корректны: время соответствует реальному, а координаты находятся в пределах земного шара. После этого данные нужно привести к единому формату, ведь у разных партнёров разный формат описания позиций автобусов. Это может быть, например, JSON или XML.
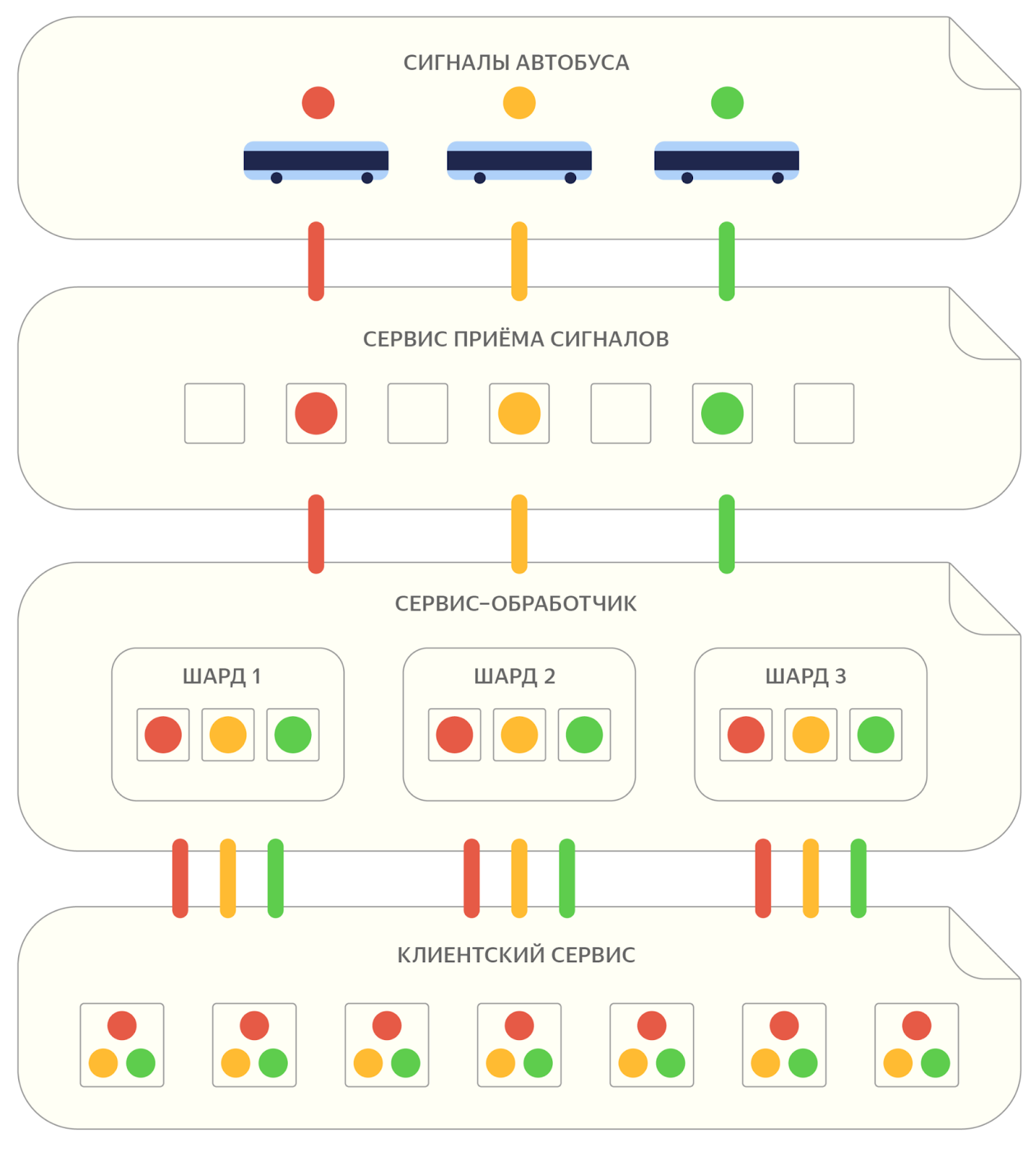
Потом сигналы отправляются в сервис-обработчик. Чтобы сбалансировать нагрузку, сервис приёма реалтайм-данных распределяет их между серверами.
В систему ежедневно приходят сотни миллионов сигналов, и обработать их на одном сервере практически невозможно. Во-первых, для этого потребовалось бы слишком много вычислительных ресурсов, то есть времени CPU. Во-вторых, для качественной работы алгоритму нужно хранить всю информацию о передвижении автобусов в течение дня в оперативной памяти, а её размер сильно ограничен.
Но даже если бы все данные помещались на один сервер, вопросы масштабируемости и надёжности оставались бы нерешёнными.
Масштабируемость — важное свойство для такой системы. Количество автобусов постоянно увеличивается, транспорт из старого парка оснащается GPS-приёмниками, появляются партнёры в новых городах. В итоге тех мощностей, которых ещё вчера хватало, завтра может оказаться недостаточно.
Другой важный аспект — надёжность. Даже если все сигналы можно обработать на одном сервере, данные легко потерять, если он внезапно выйдет из строя. Поэтому сервис-обработчик спроектирован шардированным и реплицированным.
Шардированием мы называем разделение входящих данных на партиции, каждую из которых можно обработать независимо от других. При этом все сигналы одного транспортного средства гарантированно попадают в один обработчик.
Перед отправкой сигнала сервис приёма реалтайм-данных определяет, в какой шард нужно обратиться, чтобы он был корректно обработан. А репликация обеспечивает сохранность сигналов: каждый из них обрабатывается на нескольких серверах. Так что при поломке любого сервера сигнал не потеряется.
Кстати, когда «Транспорт» только появился, сервис хранил информацию не в оперативной памяти, а в базе данных. Так любой сервер мог обрабатывать любой запрос, а при его сбое ничего не ломалось, потому что сигналы и так приходили на разные серверы за счёт общего стейта в базе. Но у этого подхода оказался минус: такую систему не получается эффективно масштабировать. Сколько бы серверов ни добавлялось в базу, им всем требовалось дополнительное сетевое взаимодействие.
Сервис-обработчик распутывает маршрутную сеть
Первый шаг в обработке сигнала — определить, по какому маршруту поедет транспорт. Тогда пользователи, нажав на автобус в приложении, увидят траекторию, по которой он движется.
Главная проблема здесь — сложная маршрутная сеть. Некоторые автобусы едут по разным маршрутам в зависимости от времени суток или дня недели, другие несколько раз проезжают одни и те же остановки. А бывают случаи, когда два маршрута совпадают в начале, но потом расходятся. Это актуально, например, для автобусов с нерегулярными заездами в дополнительный район или даже город.
Если автобус только выехал с конечной, сложно понять, по какому маршруту он поедет. Здесь помогает алгоритм, который мы назвали «привязка». Кроме текущего сигнала, он учитывает всю историю геопозиций автобуса, а ещё информацию о маршруте: его положение на карте, расположение остановок и расписание.
Когда сервис получает новый сигнал, он пытается решить, к какому варианту маршрута его лучше привязать. Такие варианты мы называем кандидатами привязки.

Дальше нужно выбрать из кандидатов лучшего. Здесь на помощь приходят результаты привязки прошлых полученных сигналов. Сервис анализирует все возможные варианты передвижения автобуса и просчитывает их правдоподобность. В результате тот вариант, который казался оптимальным на прошлом шаге алгоритма, может быть изменён на другой с учётом новых данных, потому что картина в целом теперь больше соответствует другой траектории движения.
Рассчитываем, сколько ждать на остановке
Двигаемся дальше — в прямом и переносном смысле. Следующий шаг — оценить скорость автобуса. Так мы сможем предсказать, когда он приедет на каждую остановку на маршруте. А пользователи смогут нажать на эту остановку в приложении и увидеть, сколько ещё ждать автобус.
Чтобы рассчитать скорость автобуса, разобьём предстоящий маршрут на отдельные участки, а их длину будем подбирать так, чтобы она отражала периоды движения с относительно постоянной скоростью — тогда итоговая ошибка будет меньше.
Дальше каждый участок нужно проанализировать. Для этого используем исторические данные о движении на этом участке, но только те, что соответствуют текущим условиям: дню недели, времени суток. Важно учитывать и дорожную инфраструктуру: это может быть многополосная магистраль или маленькая улочка, прямой участок или извилистый, с поворотом, разворотом, круговым движением или светофорами. Всё это сказывается на скорости и времени движения. Ещё один фактор — положение участка относительно остановок. Понятно, что перед остановкой автобус будет тормозить, а после — разгоняться.
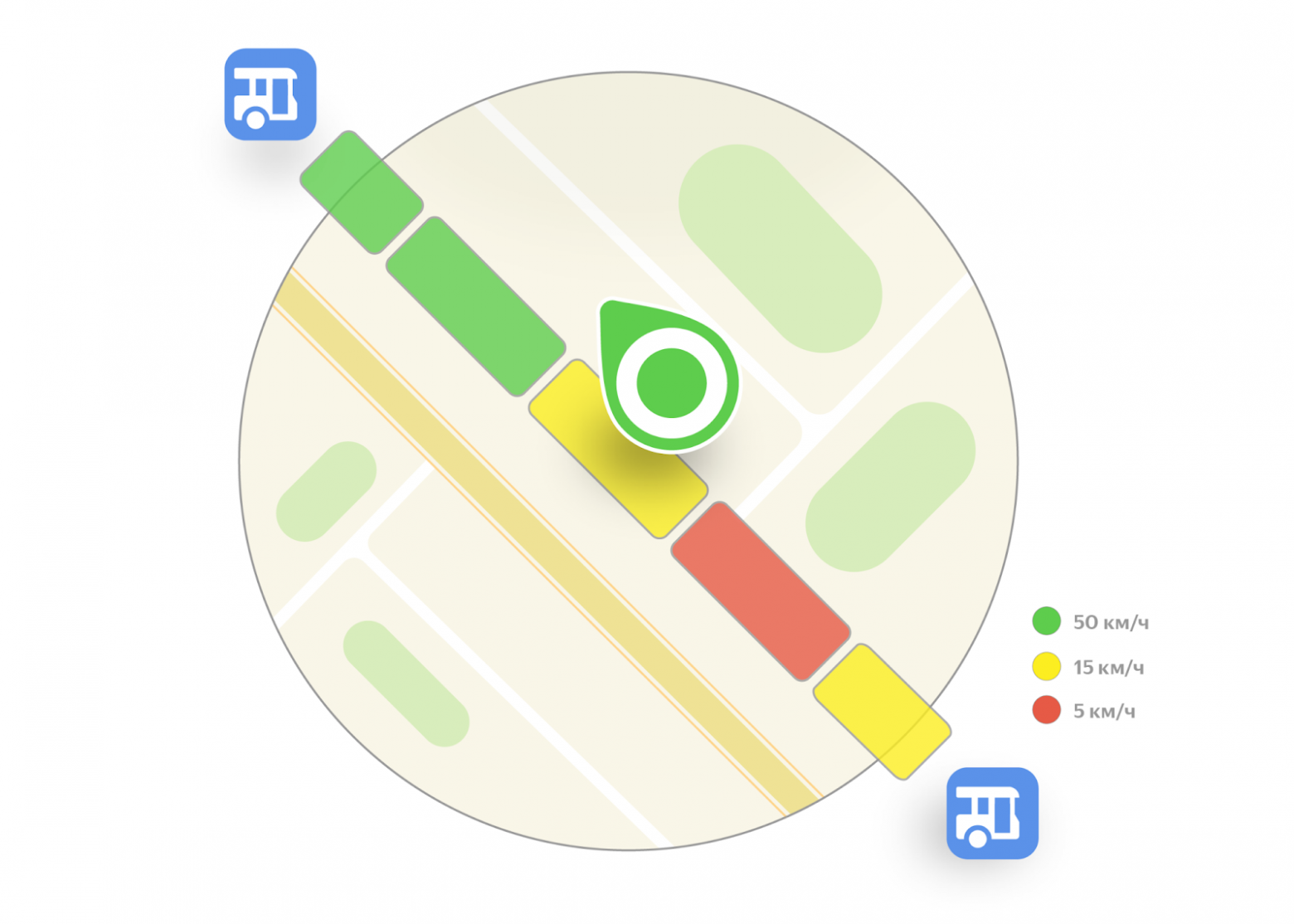
Теперь, когда все значения определены, можно использовать их в модели предсказания. Она представляет собой предподсчитанный набор параметров для алгоритма машинного обучения. Именно он тщательно подбирается заранее с помощью обработки гигантского объёма исторических данных о передвижении транспорта.
Стандартное решение для определения времени прибытия на остановку — суммировать скорости автобуса на отдельных участках. Но важно учитывать свойство ошибки накапливаться, поэтому мы продолжаем дорабатывать алгоритм, чтобы ещё точнее предсказывать время прибытия.
Учитываем пробки в прогнозе
Текущая дорожная ситуация, безусловно, влияет на время движения транспорта, поэтому в прогнозе очень важно учитывать пробки. Также стоит обратить внимание на то, есть ли на дороге выделенная полоса и поможет ли она в этой ситуации. Получить всю эту информацию помогают данные о пробках из Яндекс Карт.
Сложность в том, что технически транспорт и пробки находятся на разных слоях карты. При этом траектории дорог и маршруты транспорта постоянно меняются. Чтобы информация из одного слоя попала на другой и была актуальна, нужно ежедневно выполнять «привязку» данных, то есть соотносить между собой дороги с двух этих слоёв.
Когда связь между слоями найдена, нужно сохранить её в эффективную структуру, которая позволит максимально быстро обновлять данные о дорожной ситуации по маршрутам транспорта. В частности, она должна позволять быстро получать все пробки, например, между двумя остановками, и при этом обновлять их десятки раз в час в соседнем потоке исполнения.
Транспорт едет по карте
Когда мы итеративно рассчитали скорости на всех участках впереди, можно использовать их и для движения метки.
Казалось бы, автобусы передают нам сигналы со своим местоположением, почему бы просто не показывать их на карте. Дело в том, что GPS-сигналы не всегда точные, у них есть погрешность, порой в десятки метров. Кроме того, сигналы бывают редкими и попадают к нам с небольшой задержкой.
В большинстве случаев такое искажение легко исправляется алгоритмом, но бывают и очень нетривиальные случаи. Например, если автобус заедет в тоннель, сигнал может потеряться, прийти с огромным опозданием или иметь погрешность в десятки раз больше, чем обычно. В результате такие метки будут хаотично прыгать по карте и пользоваться ими будет невозможно.
Чтобы понять, где автобус едет на самом деле, и корректно показать его, придётся немного заглянуть в будущее. Поэтому положение, которое видно на карте «в реальном времени», на самом деле наш прогноз.
При этом важно учитывать нюансы и следить за тем, чтобы движение метки на карте соответствовало информации в карточке остановки. Так, если метка автобуса находится перед остановкой, в карточке остановки должно быть время его прибытия. А когда метка перемещается за остановку, этого автобуса не должно быть и в карточке остановки, ведь он уже уехал.
Итак, у нас есть прогноз, метка по нему движется — всё в порядке. Но приходит следующий сигнал, по нему строится прогноз, более новый и более точный. Выходит, что текущее положение метки по старому и новому прогнозу различаются. Конечно, можно просто переместить метку в новую позицию, но тогда на карте будут постоянные прыжки, которые будут сильно раздражать.
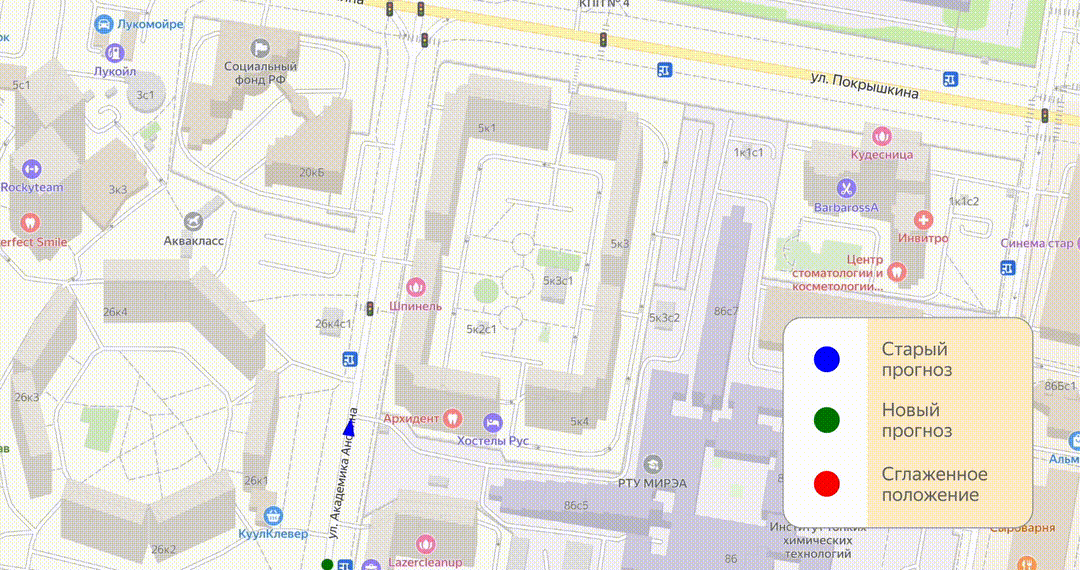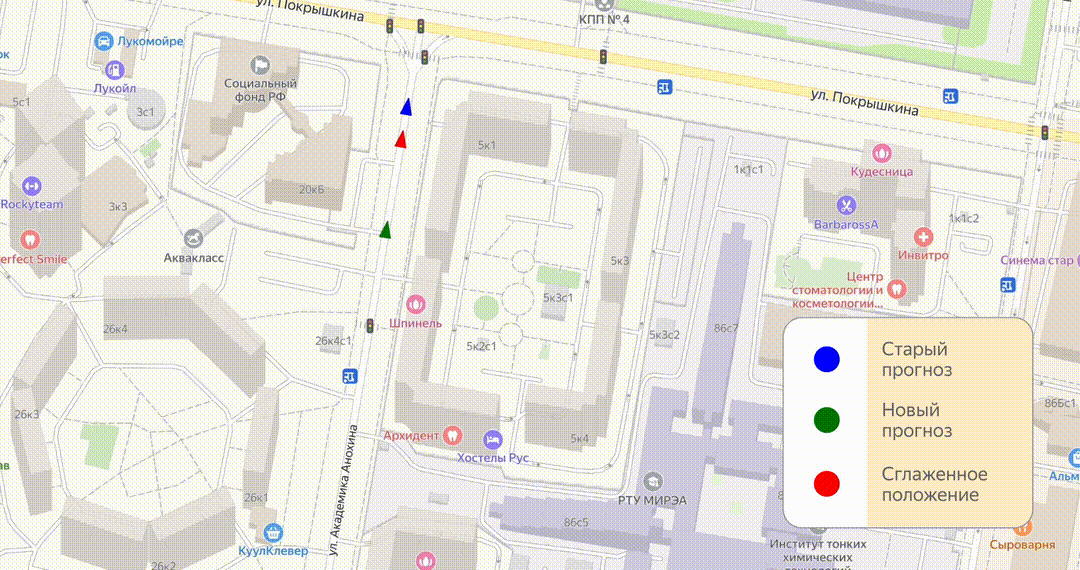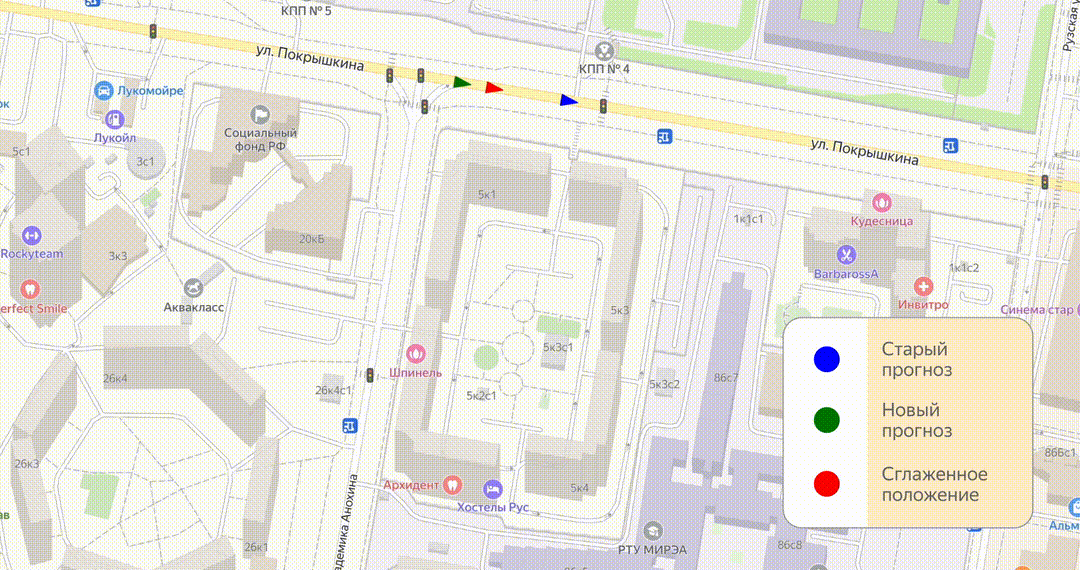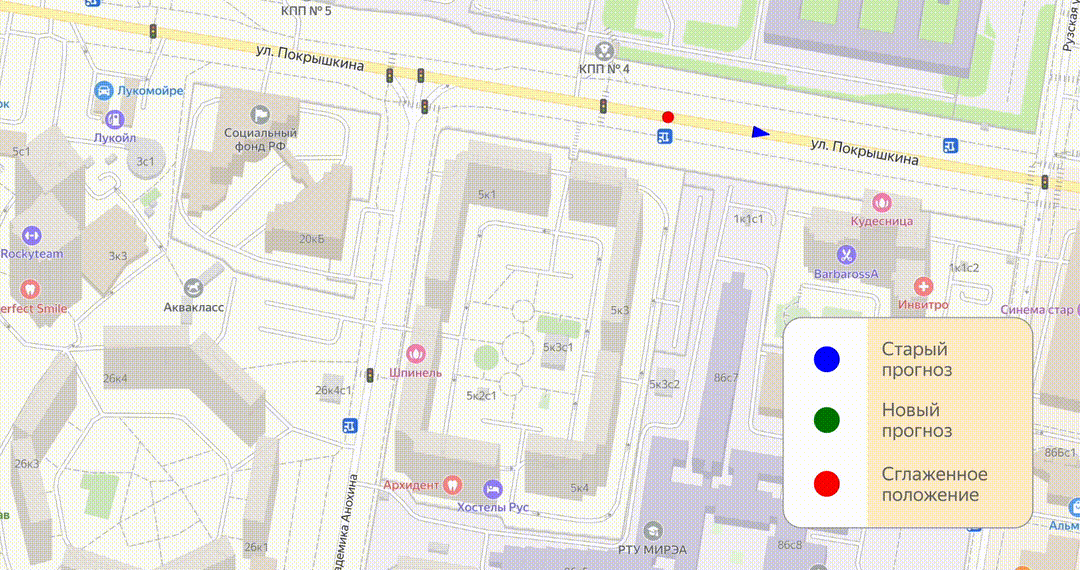
Чтобы этого избежать, мы используем алгоритм под названием «смузинг»: с его помощью один прогноз постепенно догоняет другой. Например, если новый прогноз оказался впереди, мы не резко двигаем метку, а немного ускоряем старый прогноз, чтобы он постепенно и без резких скачков догнал новый.
Вместо заключения
Чтобы алгоритм постоянно совершенствовался, он должен учиться на своих ошибках. А чтобы найти эти ошибки и понять, удалось ли их исправить, нужна метрика и регулярная оценка качества.
Когда транспорт приезжает на остановку, мы анализируем наши предсказания и сравниваем прогноз прибытия с фактом. Особенно важны популярные остановки и маршруты, которыми пользуется большое количество пассажиров. Сравнив реальное время с нашим прогнозом, мы можем оценить качество работы алгоритма и сервиса в целом.
Также алгоритм принимает это время за эталон обучения модели. Так с каждым днём он становится точнее, чтобы поездки на общественном транспорте становились предсказуемыми.
