Отказоустойчивые системы: зачем нужны и как построить
Статья содержит вводную информацию о резервировании и других возможностях обеспечения отказоустойчивой работы серверов и прочего оборудования ИТ-инфраструктуры предприятия.
Мы всегда надеемся, что оборудование и инфраструктура будут работать чётко, надёжно, и без поломок. Особенно это важно там, где неисправности приводят к остановке бизнес–процессов и как следствие — финансовым и репутационным потерям. Как минимум, эти потери складываются из оплаты сотрудников за время простоя (пока они ждут восстановления работы системы), и упущенной за это время прибыли. К этому можно добавить суммы, затраченные на сам ремонт и восстановление системы (покупку исправных комплектующих, оплату работ по установке и замене, и т.п.). Сумма убытков может быть достаточно большой; в некоторых случаях простой может привести к непоправимым последствиям — вплоть до исчезновения бизнеса. Это является поводом задуматься о том, как можно избежать остановки работоспособности.

Самым простым и очевидным способом избежать простоя из-за неисправности является резервирование — то есть такая избыточность оборудования, которая позволит продолжить работу при выходе его части из строя.
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне — самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически — двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости — это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская
плата. Выход из строя RAID-контроллера может привести к частичной или полной
потере данных, а выход из строя материнской платы приведет к остановке всего
сервера. Как защититься от таких неисправностей и обеспечить безотказную
работу?
Резервирование серверов (кластеры)
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двхузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
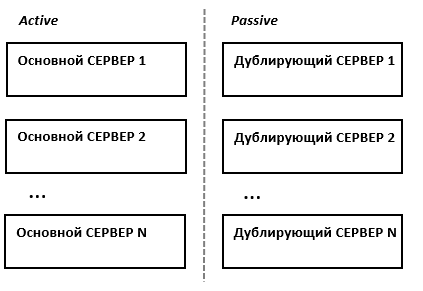 Конфигурация Active/Passive
Конфигурация Active/Passive
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.
 Конфигурация Active/Active
Конфигурация Active/Active
Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
 Конфигурация N+1
Конфигурация N+1
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M — когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
Active/Active | Active/Passive | N+1 | |
Стоимость решения | Нормальная (суммарная стоимость всех узлов; все узлы кластера работают) | Высокая (фактически — двойная, т.к. дублируются все узлы кластера) | Нормальная + 1 (суммарная стоимость всех узлов + 1 резервный узел) |
Производи-тельность при отказе | Снижение производительности | Нет снижения производительности | Нет снижения производительности |
Отказоустойчивость СХД
К системам хранения данных в части обеспечения отказоустойчивости предъявляются более высокие требования, чем к серверам. Проблема неисправности сервера в большинстве случаев относительно легко решается его ремонтом или заменой. В то же время потеря данных может оказать серьёзное негативное влияние на бизнес и принести существенные убытки. Для предотвращения подобных случаев уделяется повышенное внимание обеспечению надёжности и отказоустойчивости СХД. Так, во всех СХД корпоративного класса применяется дублирование контроллеров, благодаря чему при выходе из строя одного из них доступ к данным сохраняется. Кроме того, СХД используют организацию дисков в RAID-массивы, которые позволяют восстановить данные при отказе нескольких дисков массива. Наконец, существуют кластерные конфигурации, когда несколько СХД объединяются в единую систему. Такая система состоит из нескольких контроллеров (принадлежащих разным физическим СХД), а данные могут быть распределены между различными СХД, входящими в её состав.
Отказоустойчивость на уровне инфраструктуры
Как было показано выше, основным способом повышения отказоустойчивости является дублирование узлов. Рассмотрим этот процесс на нескольких примерах. Для начала возьмём простую (и довольно часто встречающуюся) топологию инфраструктуры небольшой компании:
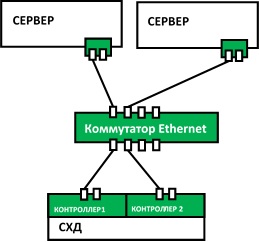
В конфигурации на этом рисунке мы защищены от потери данных на СХД (т.к. СХД имеет два контроллера), но не защищены от простоя в случае, если выйдет из строя коммутатор. Поэтому для повышения отказоустойчивости нам нужно добавить второй коммутатор, и подключить к нему остальное оборудование:

Теперь мы защищены от неполадок как со стороны СХД, так и со стороны коммутатора. Но что будет, если выйдет из строя сетевой адаптер сервера? Этот сервер потеряет доступ к сети и СХД. Поэтому нужно задублировать также и сетевые адаптеры:

Кажется, теперь мы задублировали всё, что можно. Остаются только сами серверы. Их можно объединить в отказоустойчивый кластер, как было описано ранее:

Заключение
Итак, повышение отказоустойчивости заключается в выявлении критических точек отказа (то есть таких, потеря работоспособности которых приводит к приостановке работы) и дублировании таких точек. Однако дублирование приводит к практически двойному росту стоимости системы. Поэтому для обоснования целесообразности дублирования следует определить, к каким именно последствиям приведёт отказ оборудования (финансовые потери, потери в скорости обслуживания и проч.), и насколько это окажется критичным для деятельности предприятия.
