От Kubernetes в мечтах к Kubernetes в проде. Часть 4. Хранилище секретов ― HCP Vault
В серии статей по теме DevOps мы вместе с Lead DevOps инженером департамента информационных систем ИТМО Михаилом Рыбкиным рассказываем о проверенных инструментах выстраивания инфраструктуры, которыми с недавнего времени пользуемся сами. В предыдущих статьях мы уже рассмотрели предпосылки перехода на новую инфраструктуру, познакомились с азами Kubernetes и обсудили методы доставки кода. В рамках последней темы мы пришли к методологии GitOps, при которой конфигурация кластера описана декларативно и есть ровно один источник правды ― git с его историей версий и т. д. Но git не является достаточно доверенной средой для хранения секретов ― с его помощью мы не смогли бы обеспечить разделение доступов и т. п. Так что в следующей статье цикла мы рассказываем о том, как можно реализовать отдельное хранилище секретов, без которого полноценно перейти на GitOps невозможно.
Disclaimer
Как и в других статьях, важно оговориться, что GitOps и сопутствующая автоматизация ― история довольно дорогая. Нужно развернуть оператор (в нашем случае ArgoCD), который съест какое-то количество ресурсов ― оперативной памяти, процессора ― и автоматизировать развертывание, в том числе получение секретов. Необходимо не только организовать для них хранилище, но и автоматизировать процессы получения и передачи содержимого сервисами-потребителями, заложить алгоритмы обработки ошибок и покрыть всё мониторингами. Это имеет смысл делать, когда у вас много проектов или один большой проект с микросервисной архитектурой. Для единичных небольших проектов это, на наш взгляд, излишне.
Какие существуют секреты
Секретами мы предложим считать любые элементы конфигурации приложения, утечка которых может нанести ущерб. Например, переменная окружения «ENVIRONMENT» (develop/production) не является секретом, поскольку ее обнародование ни на что не повлияет. А вот разглашение «DB_PASSWORD», хранящей пароль от базы данных, вполне может принести потери.
Возьмем более сложный пример. Предположим, у нас есть пять переменных: dbhost, dbuser, dbpassword, dbsslmode и dblogin. Что из этого считать секретом ― зависит от гайдлайнов компании. Для себя в качестве best practice мы взяли идею делить переменные на блоки. Эти пять переменных ― блок, обеспечивающий подключение к БД, который должен храниться в одном месте, потому что перескакивать с одного (секретного) хранилища на другое (несекретное) очень неудобно. Так что мы все эти переменные записываем в секреты.
Как секреты попадают в приложение
Существует несколько вариантов передачи секретов в приложение из стороннего хранилища:
Монтировать как переменную окружения контейнера. Благодаря некоторой магии (которую мы рассмотрим ниже) контейнер получает нужные ему секретные данные в виде переменных окружения. Плюс этого метода в том, что нам не нужно интегрировать хранение секретов в наше приложение ― всё работает так же, как работало бы везде. Минусы ― это необходимость настраивать механизм монтирования и обязательный перезапуск контейнера в случае, если меняется какой-то секрет. А еще в переменных окружения мы не можем передать файл. Например, если библиотека воспринимает сертификат только в виде ссылки на файл, наш механизм не позволит этого реализовать.
Монтировать как файл. Секрет подключается в контейнер в виде файла, в котором и содержится нужное значение. При этом мы можем самостоятельно выбрать точку монтирования (путь до) этого файла. Этот вариант подходит как раз для тех библиотек, которые не умеют получать данные из переменных окружения.
Подключаться к хранилищу секретов напрямую из приложения. Этот вариант самый страшный и неудобный, но степень этого дискомфорта зависит от того, какое конкретно хранилище использовано. Если мы применяем git-secrets (метод хранения секретов в git в зашифрованном виде), то подход действительно добавит сложностей. Если же использовать нативные хранилища с интеграционными SDK (например HashiCorp Vault, который мы рассмотрим ниже), то решить задачу будет легче.
Где можно хранить секреты
В ходе подбора инструмента для хранения секретов мы рассматривали четыре варианта:
Cloud-specific хранилище. Некоторые облачные провайдеры предлагают свое хранилище секретов как услугу с API для работы. Например, у Яндекс.Облака это Yandex Lockbox. Это удобная вещь, но когда мы выбирали инструмент, она еще была в бета-версии, и на том этапе класть её в ядро нашей инфраструктуры казалось неправильным. Также важной спецификой таких инструментов является vendor-locking ― при построении инфраструктуры вокруг облачного провайдера нужно понимать, что мигрировать с них будет очень тяжело. Не во всех проектах и ситуациях это критично, но иметь в виду при подборе инструмента нужно.
Git-secrets и аналоги. Это инструменты шифрования и хранения секретов в git. Следит за безопасностью хранения и транспортировки pre-commit проверка, которая шифрует секреты перед коммитом в репозиторий. Шифрование позволяет сохранить секреты в тайне, даже если репозиторий будет скомпрометирован (пока не утечёт ключ шифрования). Однако, нам этот вариант не подошел из-за масштабов. Наши проекты построены на микросервисной архитектуре, и если каждому из них прописывать секреты в git, рано или поздно один из разработчиков может случайно закоммитить незашифрованный секрет. Кроме того, придется настраивать GitOps-оператор на получение секретов из git, что нативными средствами реализовать невозможно.
Переменные GitLab CI/CD. В GitLab есть хранилище environment-переменных, куда также можно положить значения секретов. По этому пути мы шли ранее, но он правильный только отчасти. Важно понимать, что GitLab CI/CD Environment ― это переменные, предназначенные для конфигурации GitLab CI/CD job«ов, а не самого приложения. Они передаются в раннер, запускающий job, а не в сервис, который мы хотим запустить. При этом раннер мы не считаем доверенным окружением ― его легко скомпрометировать. Предположим, разработчик, который не должен иметь доступ к переменным, хранящим логин и пароль к БД, зайдет в конфиг GitLab CI и настроит вывод значений всех переменных. Мы об этом никогда не узнаем ― и запуск job, и изменения в CI не должны нас триггерить. При этом доступы к БД утекут. Ещё одна сложность при работе с такими переменными ― мы не можем вытащить их значения при помощи GitOps-оператора.
Стороннее хранилище секретов. На рынке существует довольно много сервисов для хранения секретов. Многие позволяют также «из коробки» реализовывать механизмы интеграции с окружениями, в которых запускаются приложения-потребители этих секретов. Среди плюсов выделенного хранилища будет главным образом повышение контроля над процессами работы с секретами, однако за это придется заплатить цену ― ещё один сервис требует дополнительного ресурса, как в физическом исчислении (ядра процессора и гигабайты памяти), так и в моральном (отслеживание и обеспечение SLA еще одного сервиса).
HashiCorp Vault
Vault ― это сервис хранения секретов с открытым исходным кодом, разработанный компанией Hashicorp. Его используют множество компаний, в том числе из финансового сектора (а у них требования к безопасности на высочайшем уровне). В качестве хранилища он может как использовать внешние БД (например, PostgreSQL), так и выступать сам (с использованием алгоритма raft). Помимо хранения он реализует механизмы ротации, управления доступами, автоматической генерации секретов и передачи их сервисам-пользователям.
Естественно, в БД все хранится в зашифрованном виде. При первой инициализации Vault генерирует пять мастер-ключей ― с их помощью и шифруются данные хранилища. Любых трех из них достаточно для расшифровки секретов. Общее количество ключей и их доля, необходимая для разблокировки, настраиваются. Можно сделать хоть 100 ключей с необходимостью вводить каждый раз 50. К сожалению, зачастую все эти ключи печатаются на одной бумажке и складываются в ящик стола. Но в идеале они должны раздаваться администраторам, DevOps-ам или безопасникам на разных носителях. И при необходимости минимум трое из пяти (если значения по умолчанию не изменялись) должны зайти в Vault и ввести свой ключ.
Vault ― кластерный инструмент, т.е. он умеет работать в отказоустойчивом режиме. Мы можем запускать его на виртуальных машинах или в Kubernetes ― при падении одного из узлов остальные примут нагрузку на себя. При этом важно помнить, что кластерный режим в Vault работает по схеме master-slave ― одна из реплик определяется мастером, и она обрабатывает все запросы, а в случае падения эту роль принимает на себя slave-реплика.
Механизм блокировки
Поскольку данные в хранилище, используемом Vault, находятся в зашифрованном виде, где-то должна происходить расшифровка. В Vault этот механизм называется seal (шифрование данных) и unseal (расшифровка).
С точки зрения пользователей проще всего описать работу этого механизма через пример с банковским хранилищем. Уходя на ночь, менеджеры банка закрывают хранилище огромной стальной стотонной дверью. Благодаря этой двери ночью хранилище недоступно ― никто ничего не может забрать. Утром, перед тем как офис начнет работать, сотрудники приходят и открывают хранилище. С этого момента с ним можно работать. Механизм seal работает так же. Если Vault находится в состоянии sealed, т.е. зашифрован, никто из клиентов не может получить к нему доступ до тех пор, пока не выполнится механизм unseal ― расшифровки данных.
По умолчанию при старте Vault данные в хранилище зашифрованы.
Расшифровку (unseal) можно выполнить по-разному:
Ручной unseal ― механизм по-умолчанию. Для расшифровки данных требуется вручную ввести три из пяти мастер-ключей. Предполагается, что эти ключи выданы разным людям, и для разблокировки понадобится их участие. Без ключей злоумышленник, получивший доступ к базе данных и развернувший на ней собственный Vault, не сможет прочитать ни один секрет. Кстати, для шифрования мастер-ключи не нужны.
Auto unseal. Вручную каждый раз «открывать» и «закрывать» хранилище может быть излишне, особенно если посреди ночи упал и автоматически восстановился один из узлов кластера. Поэтому предусмотрена автоматизация ― ключ шифрования предоставляется окружением, в котором запускается сервис. Мы используем Яндекс.Облако и форк Vault от команды этого сервиса, в котором добавлен плагин, реализующий механизм auto unseal с использованием сервиса Yandex KMS (Key Management Service). Когда Vault запускается в Яндекс.Облаке, он получает токен доступа в сервисы Яндекса и с ним идет в Yandex KMS, где забирает ключ шифрования для работы с содержимым хранилища.
Забавная деталь механизма работы auto unseal. Когда мы шифруем хранилище Vault, он начинает отвечать на все запросы кодом 500, что отмечают проверки состояния Kubernetes. Делая вывод, что сервис не работает, автоматически отправляется сигнал на его перезапуск. Однако при старте Vault выполняется механизм auto unseal, и в итоге мы получаем расшифрованный Vault, хотя только что его шифровали.
При работе с Vault auto unseal важнейшим фактором является уровень доверия механизму. Если Vault не сможет обратиться к провайдеру auto unseal, данные расшифровать не получится. Соответственно, если вы не уверены, можно ли в вашем случае доверять определенному механизму автоматической расшифровки, лучше выбрать другой. Подробнее об этом ограничении указано в документации механизма auto unseal (синий блок warning).
Абстракции конфигурации Vault
Методы входа ― абстракции блока Access
Vault ― хранилище секретов, со значениями которых могут работать не только пользователи, но и использующие эти секреты сервисы. По принципу действия это очень похоже на GitOps ― есть единый источник правды, к которому обращаются все, кто работает с данными. Больше не нужно вручную копировать значения переменных на сервер или при изменении запускать скрипты загрузки ― окружения сами раз в какое-то время запрашивают актуальные значения секретов из Vault. Это позволяет реализовать новые механизмы работы с секретами, например автоматическую ротацию паролей.
Первое, что должен сделать любой, кто обращается к Vault ― будь то сервис или пользователь ― авторизоваться. Для этого Vault предоставляет несколько разных механизмов. В их числе OIDC, username / password, LDAP, набор cloud-сервисов авторизации, Kubernetes и другие.
Мы можем создавать несколько методов одного типа. Например, можно реализовать вход через разные OIDC-провайдеры, чтобы пользователь сам выбирал, какой применить.
Еще одна access-абстракция Vault ― это entity. По сути это доверенные авторизованные объекты, которым доступен API Vault ― независимо от использованного метода авторизации. Это может быть как пользователь, авторизовавшийся через имя и пароль, так и приложение, использовавшее Kubernetes-метод. Чтобы не терять связь с методом авторизации, у каждой entity есть alias ― это связка объекта и метода авторизации.
Для удобства управления entity можно объединять в группы ― как вручную, так и автоматически на основании нужных параметров. После добавления entity в группу на нее можно назначать политики доступа, которые будут применяться ко всем ее участникам. Например, можно объединить менеджеров в одну группу и назначить им доступ только на чтение списка секретов, не допуская работу с их значениями. Также группы Vault можно привязывать к внешним OAuth-группам. В таком случае достаточно будет назначить «внешней» группе в Vault политику доступа, и любой, кто будет добавлен в нее на сервере авторизации, войдя в Vault автоматически получит доступ к нужным секретам.
Последняя абстракция из этого блока ― lease. По сути это флаг доступа к какому-то набору секретов на какое-то время. По истечении lease его надо обновить, чтобы не проходить авторизацию при каждом запросе.
Важный нюанс работы с leases: при их генерации, а также по их истечении Vault тратит ресурсы на изменение их статуса. Учитывая, что, например, механизмы авторизации также используют под капотом leases для управления токенами, объем нагрузки на сервер может значительно вырасти при повышении количества клиентских запросов. В процессе эксплуатации мы обнаружили, что мастер-под нашего Vault не живет дольше двух часов, поскольку уже через полчаса после запуска на нем резко начинает идти в гору нагрузка, пока не достигает пика и Kubernetes не перезапускает под. При этом другая реплика принимает на себя роль мастера, и процесс повторяется. Это было связано с тем, что на старых версиях драйвера, используемого нами для интеграции Vault с Kubernetes (о котором мы напишем ниже), на каждый запрос значения каждого секрета выполнялся также запрос авторизации. В итоге за пару месяцев работы нагенерировалось столько объектов lease, что Vault уже не хватало мощностей для обработки всех истекших. Эта проблема решилась разовым расширением доступных ресурсов, ручной очисткой всех истекших leases, оптимизацией времени жизни leases и обновлением драйвера интеграции. В новой версии добавилась поддержка кеширования токенов, и объемы их генерации в Vault значительно снизились.
Закрывая тему методов авторизации, упомянем, что Vault может также самостоятельно выступать в роли OIDC-провайдера:

Хранилища секретов ― абстракции блока Secrets
Основа Vault ― секреты. Самое базовое хранилище для них ― KV (key-value, ключ-значение). Однако, в HashiCorp пошли дальше и создали ряд других механизмов работы с секретами, которые объединили под общим названием secrets engines ― «движки» секретов:
Экран создания secrets engine
Такое количество методов нужно для реализации сценариев глубокой интеграции с инфраструктурой. Например, движок databases конфигурируется адресом БД и root-паролем, после чего любой новый секрет в нем будет инициировать автоматическое создание пользователя с заданными правами и генерируемым паролем в этой базе данных. При этом создатель секрета может даже не узнать этот пароль, если у него нет на это доступа, зато сервис, который должен подключаться к БД, пароль получит и сможет им пользоваться. Метод позволяет также настроить механизм автоматической ротации паролей по расписанию и, опять же, использующие его сервисы автоматически получат этот пароль (если соответственно настроены). По похожей схеме работает движок SSH, который может по запросу создавать одноразовые пароли для доступа на ВМ.
Еще один интересный метод ― transit. Он ничего не хранит, но позволяет реализовать концепцию encryption as a service, в рамках которой сторонние сервисы делегируют Vault задачи шифрования. Это в некоторых сценариях полезно, поскольку задачи шифрования и дешифрования ресурсоёмкие и небезопасные ― нужно обеспечивать соответствующий уровень доступа к ключам шифрования. Transit позволяет использующему его сервису просто отправлять запрос в API и получать в ответ уже зашифрованные строки (и также поступать с дешифрованием), не заботясь о решении этих проблем.
Как и в случае с абстракциями блока Access, в блоке Secrets мы можем иметь несколько инстансов одного типа ― т. е. можно иметь несколько KV-хранилищ или баз данных.
Управление доступами ― абстракции блока Policies
Policies ― политики доступа ― задаются в Vault в формате JSON или HCL — HashiCorp Configuration Language (специального языка конфигурации инструментов HashiCorp). Внутри политики нужно указать path (значение пути до секрета или secret engine) и описать набор предоставляемых разрешений:

Пример политики доступа
Политика позволяет управлять доступом очень гибко. Например, мы можем выдать пользователю доступ на list, но не выдать на read ― т. е. он сможет смотреть список секретов, но не сможет читать их значения.
Vault работает по стандартизированному API. Для управления доступом к любому элементу Vault (не только к хранящимся внутри секретам, но и, например, к эндпоинтам конфигурации) достаточно знать URL этого элемента.
Интересная деталь ― при использовании KV-хранилища второй версии появляется возможность выдачи доступа отдельно на значение секрета и отдельно на его метаданные ― когда он был создан, количество версий и т. п.

Пример политики, разделяющей доступ к данным и метаданным секрета
олитики назначаются пользователям на разных этапах. Можно назначить политику на метод авторизации (и тогда политика будет назначена всем, кто его использовал для входа), на группу пользователей или персонально.
Для удобства управления политики Vault можно шаблонизировать, используя метаданные пользователя. Так, например, можно одной политикой реализовать доступ приложению из Kubernetes только к секретам, хранящимся в secrets engine с тем же названием, что и namespace, в котором он работает:

Интеграция Vault и Kubernetes
Механизм заполнения Vault секретами выглядит просто: нужно создать secrets engine (допустим, kv2), метод авторизации, определить политику на этот метод и готово ― любой пользователь может зайти и записать свой секрет в хранилище. Однако, теперь перед нами встает новая проблема ― надо как-то доставить этот секрет до приложения. Для этого есть по сути два пути ― реализовывать интеграцию с Vault на уровне приложения (разработчики добавляют запрос значения секрета при старте) или на уровне инфраструктуры (окружение отвечает за интеграцию, передавая секреты в приложение нативными методами). Мы пошли по второму пути, поскольку один раз настроить инфраструктуру проще, чем переписывать десятки микросервисов под новый сценарий.
Настройка сервера
Для использования инфраструктурных интеграций нужно предварительно настроить сам Vault. Это включает в себя создание kubernetes-метода авторизации, который конфигурируется адресом kubernetes-мастера и корневым сертификатом. После этого нужно выбрать один из двух способов взаимодействия Vault с Kubernetes:
С помощью выделенного SA ― при настройке интеграции мы создаем специальный сервисный аккаунт в кластере, которому назначаем роль auth-delegator, и токен этого сервисного аккаунта мы указываем в поле token reviewer JWT. Теперь на любой запрос из Kubernetes с токеном сервисного аккаунта нашего приложения Vault будет запрашивать у Kubernetes API валидность этого токена от своего лица, авторизуясь с помощью token reviewer JWT.
С помощью токена SA приложения ― в таком случае мы оставляем поле token reviewer JWT пустым, но каждому сервисному аккаунту каждого приложения назначаем роль auth-delegator. При использовании этого метода Vault будет обращаться к API валидации токенов Kubernetes от лица приложения с токеном его сервисного аккаунта ― по сути, по токену будет запрашиваться валидность самого токена.
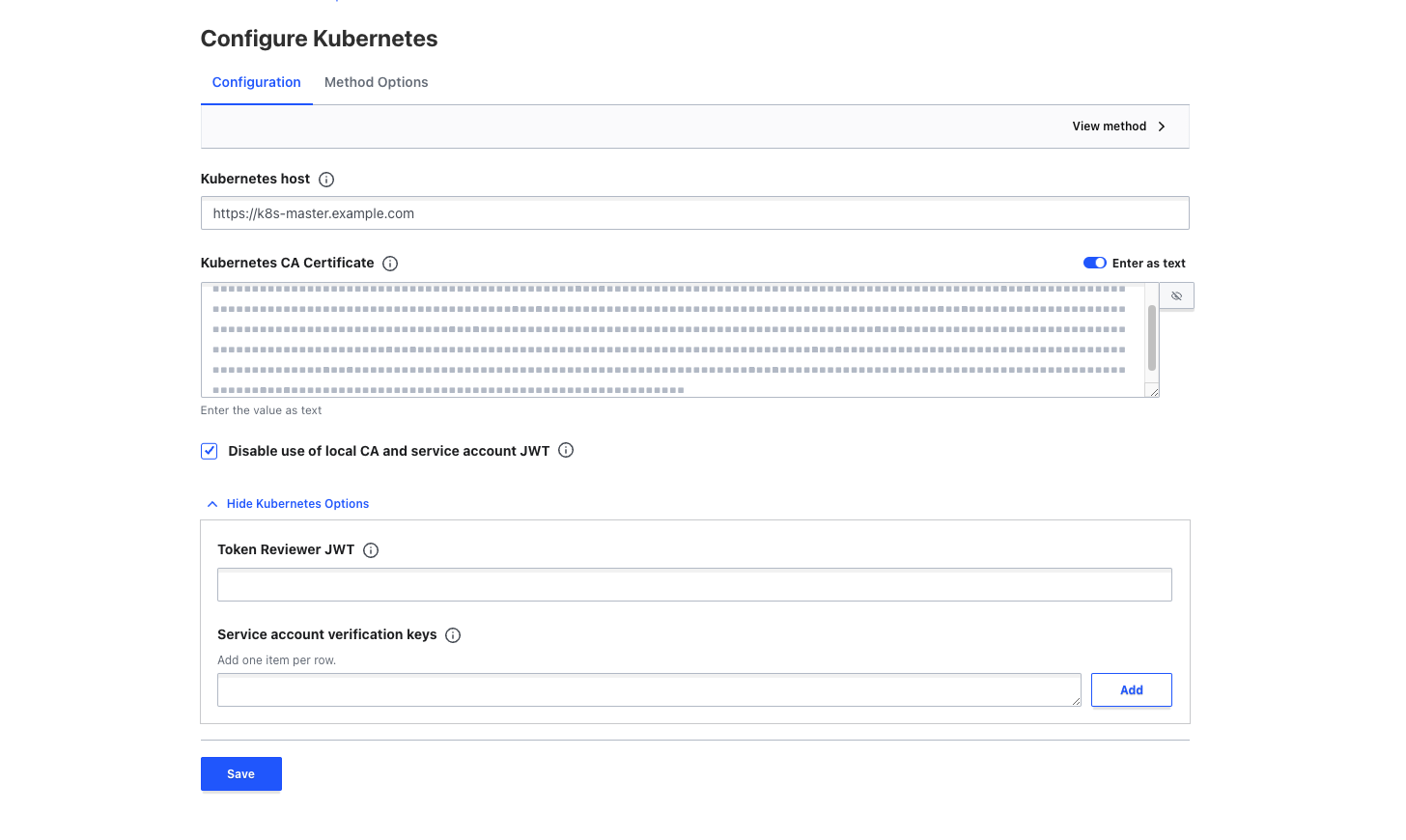
Настройки метода авторизации Kubernetes
После создания метода авторизации нам остается только настроить набор ролей ― связки политик доступа с параметрами сервисных аккаунтов:
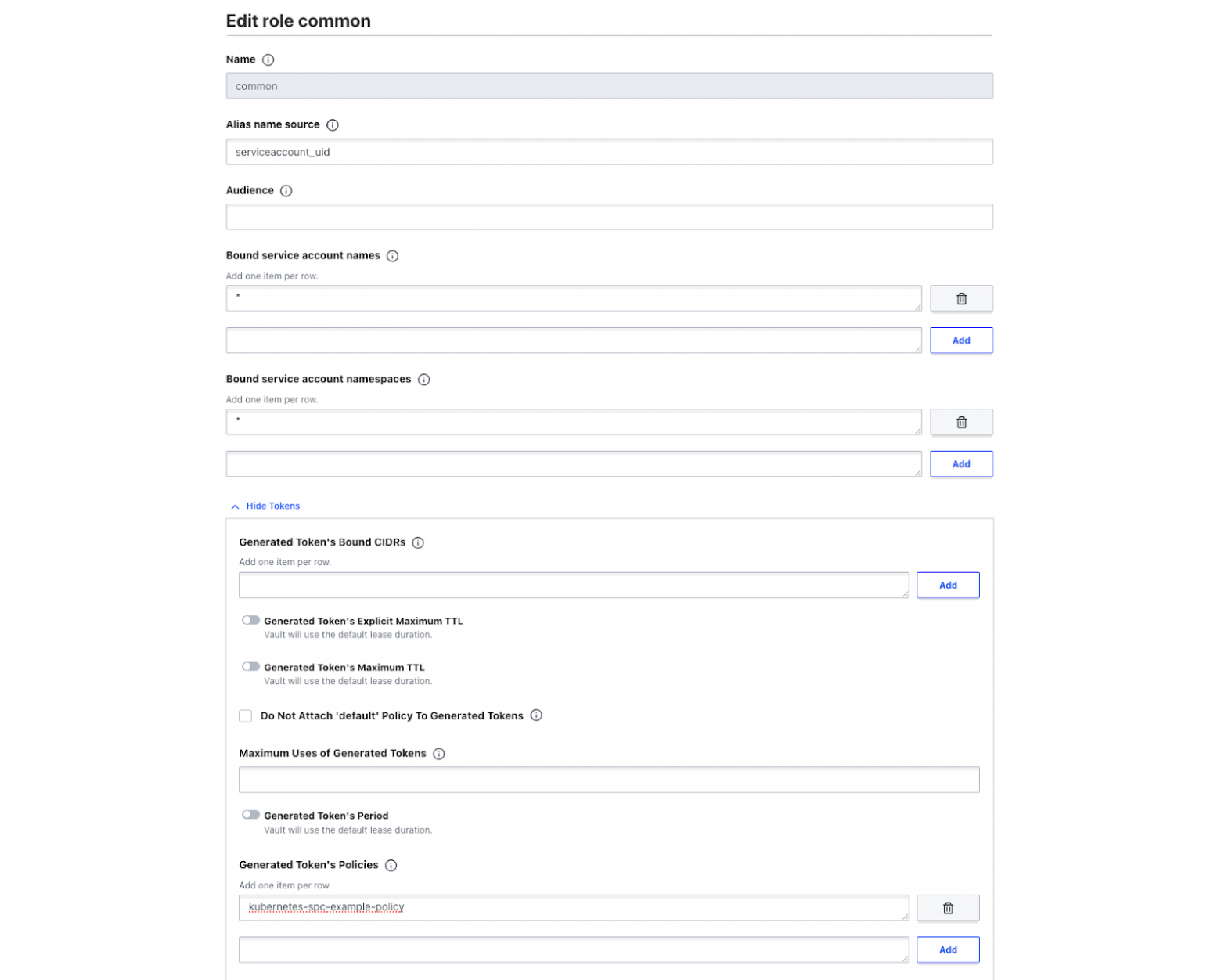
Например, создаем роль common, которая доступна любому SA из любого namespace, и назначаем им шаблонную политику kubernetes-spc-example-policy, дающую доступ сервисному аккаунту ко всем секретам, лежащим в secrets engine с названием namespace этого SA (пример такой политики см. выше).
Настройка клиента
Теперь, когда мы настроили сервер ― разложили секреты, подключили метод авторизации и описали роли и политики ― можем переходить к настройке клиентской части интеграции.
Со стороны кластера есть два метода работы с Vault — Vault agent (sidecar-контейнер, который добавляется в каждый под) и secrets store CSI driver (daemonset, устанавливающийся в кластер). Подробное сравнение двух подходов есть в документации, мы же вкратце укажем, что пошли по второму пути, поскольку посчитали, что первый нам будет дороже (как с точки зрения потребления ресурсов, так и со стороны поддержки этого решения).
В предыдущих статьях мы уже упоминали, что Kubernetes ― это фреймворк. Secrets store CSI driver ― пример реального использования его возможностей. С помощью этого драйвера мы можем декларативно описать набор секретов, которые он получит из сконфигурированного ранее провайдера ― например, vault ― и смонтирует в контейнер либо в виде переменных окружения, либо как файл. Важно также отметить, что при использовании secrets store CSI driver помимо самого драйвера нужно также установить и обработчик его запросов ― провайдер. В случае с Vault требуется установка компонента csi из стандартного чарта Vault, который добавит еще один daemonset в кластер. Именно он и будет отвечать за все взаимодействие с сервером Vault.
При установке secrets store CSI driver в кластере появляется custom resource definition (CRD) ― SecretProviderClass, в котором мы и задаем параметры провайдера и настройки интеграции с k8s.

Пример CRD SecretProviderClass
SecretProviderClass содержит несколько параметров:
Provider ― указывает название провайдера для интеграции
Parameters ― настройки провайдера, включающие в себя конфигурацию Vault (адрес сервера, метод авторизации и роль), а также список объектов — внутренних переменных SPC, используемых только в рамках работы с этой CRD, и реализующих связку «значение выбранного ключа в выбранном секрете» в Vault с абстракциями Kubernetes (секреты или монтируемые файлы)
secretObjects ― необязательный параметр, определяющий список генерируемых секретов Kubernetes и их содержимое (в привязке к objects из п. 2)
Важное уточнение. Интеграция с секретами Kubernetes работает только в том случае, если содержимое SPC примонтировано к какому-нибудь поду. Поэтому вне зависимости от использования секретов нужно помимо описания CRD также поправить шаблон нашего пода, добавив в него монтирование секретов:

Описание пода с монтированием секрета из SPC
После применения этих конфигов у нас должен появиться под, в котором по пути /mnt/secrets находится файл example-spc-object, содержащий значение ключа example-vault-secret-key из секрета, хранящегося в Vault по пути default/data/example-vault-secret-name. При этом провайдер самостоятельно авторизуется в Vault через метод авторизации kubernetes-spc-example с ролью common, используя SA нашего приложения, и получит доступ к секрету, поскольку ему это позволит политика доступа kubernetes-spc-example-policy ― ведь секрет лежит в хранилище с названием default, таким же, как название namespace, из которого идет запрос.
Это может звучать сложно, но это одноразовый процесс, который очень хорошо масштабируется. Фактически нужно только один раз разобраться в конфигах, шаблонизировать их и добавить в свой helm-чарт, после чего поставить в каждый кластер secrets-store-csi-driver и vault-csi, добавить в Vault соответствующие методы авторизации ― и всё, интеграция готова. Теперь ваши приложения самостоятельно забирают секреты из хранилища, а в их конфигах хранятся только ссылки на эти секреты.
Это минимальный фундамент, достаточный для настройки интеграции. Теперь поверх него можно настраивать монтирование переменных окружения из kubernetes-секрета в под, ротацию значений секретов, автоматический рестарт контейнера при изменении секретов (используя сторонний reloader) и т. д.
Итоги
В этой статье мы постарались описать все, что нужно для полноценного внедрения хранилища секретов HashiCorp Vault. Используя его, вы можете быть уверены, что все ваши секретные данные хранятся в безопасном, контролируемом и зашифрованном окружении. При этом все запросы ― как пользовательские, так и сервисные ― авторизованы и записаны в аудит-лог (его можно включить отдельной командой), а политики доступа настроены таким образом, что компрометация одного пода не приводит к потере доступа ко всей системе. И главное ― внедрение Vault позволяет полноценно реализовать GitOps-подход. Теперь вся конфигурация действительно описана декларативно.
