Освоение специальности Data Science на Coursera: личный опыт (ч.2)

Мы публикуем вторую часть поста Владимира Подольского vpodolskiy, аналитика в департаменте по работе с образованием IBS, который закончил обучение по специализации Data Science на Coursera. Это набор из 9 курсеровских курсов от Университета Джонса Хопкинса + дипломная работа, успешное завершение которых дает право на сертификат.
Читайте в первой части: О специальности Data Science в общих чертах. Курсы: Инструменты анализа данных (программирование на R); Предварительная обработка данных; Документирование процесса обработки данных.
Часть 2
Курсы по стат. обработке данных и машинному обучению; Практика: создание ПО для обработки данных (дипломный проект); другие полезные курсы на Курсере.
Статистическая обработка данных и машинное обучение (курсы 6, 7, 8)
Пожалуй, самые математизированные курсы из всех. На них расскажут о математической статистике, о её основных понятиях и способах статистическое обработки данных: тестирование гипотез, определение p-значения, построение доверительных интервалов, регрессионных моделей и многое другое. Кульминацией всей математики в «Науке о данных» является курс по методам машинного обучения. Хотя большая часть алгоритмов машинного обучения и стоящей за ними математики в рамках курсов не раскрывается, этот курс также является одним из основополагающих.
Вдаваться в подробности я не буду – курсы 6 и 7 изобилуют математическими определениями, формулами и доказательствами теорем. Это очень важные курсы, дающие понимание того, как работает статистика на самом деле (и как она не работает, что тоже важно). Поскольку большая часть описываемой в лекциях математики реализована в R при помощи функций, формально нет особой нужды вдаваться в математические детали. Тем не менее, я склонен считать, что самые математизированные курсы DSS являются одними из самых полезных. Поняв все тонкости статистической обработки данных, можно смело бросаться на амбразуру, на аналитические задачки с данными практически любой размерности и детализации.
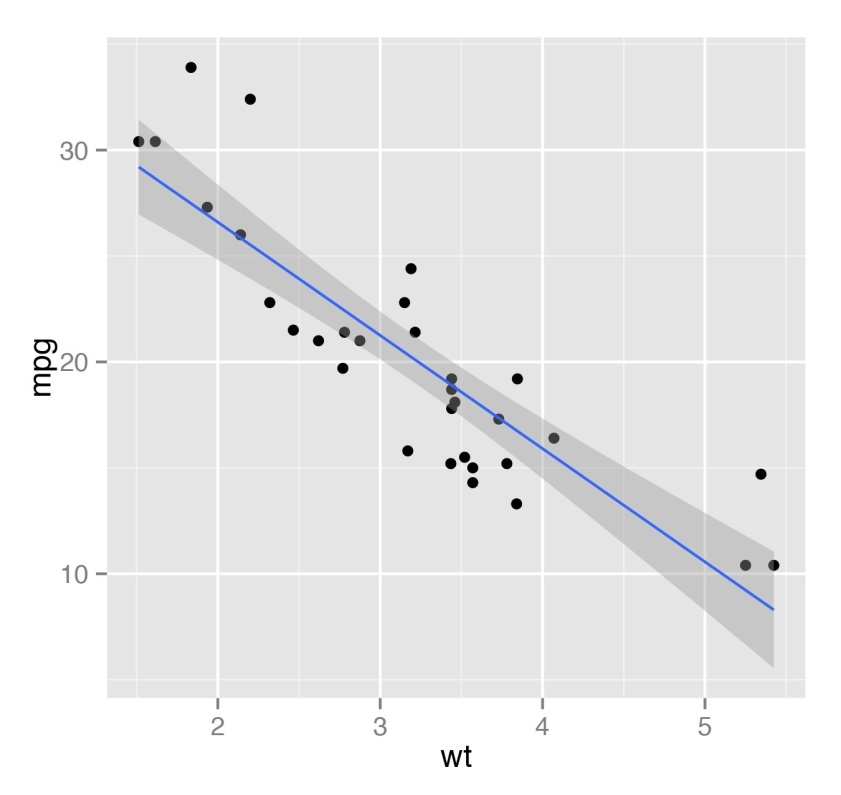
Помимо базовой статистики, в рамках этих курсах научат на качественно новом уровне обобщать данные с применением математических методов. В частности, будет рассказано и показано, как строить регрессионные модели, как их визуализировать. На самом деле, в отношении регрессионных моделей функционал R весьма широк. К примеру, имея на руках небольшой набор данных можно сходу построить обобщённую линейную модель (generalized linear model – glm), которая будет их описывать и при помощи которой можно даже прогнозировать новые точки данных. На рисунке ниже показан пример простейшей регрессионной линии. Для рисунка использован стандартный набор данных cars для R.
Серьёзный акцент в этом блоке курсов сделан на статистический вывод, то есть доказательство или опровержение гипотез. Поскольку, как правило, мы располагаем неполным набором данных (т.е. некоторой их выборкой) о некоторой вещи или явлении, то судить о характеристиках полного набора можно лишь с определённой вероятностью. Поэтому предположения о том или ином свойстве полного набора данных формируются в виде статистических гипотез, которые можно доказать или опровергнуть с некоторой вероятностью. К примеру, располагая неким набором чисел-значений температуры в течение зимней недели, мы можем сформулировать и проверить гипотезу о среднем значении температуры зимой. Конечно, на ограниченной выборке со 100% вероятностью мы не сможем доказать или опровергнуть гипотезу (для этого нам понадобилось бы пронаблюдать температуру за всю зиму), но можно это сделать для суть более низкой вероятности, например, 95%.
Проверка статистических гипотез на основе разнообразных статистических критериев (например, критерий согласия Пирсона) позволяет делать определённые выводы о наборе данных в целом, что облегчает аналитику понимание того, что описывают имеющиеся данные, на какие вопросы и как они отвечают. Помимо всего прочего, статистический вывод обладает и ценностью при визуализации данных, поскольку позволяет с некоторой долей вероятности определить, как в целом распределены точки данных.
Несмотря на довольно крепкие курсы по статистическому выводу и построению регрессионных моделей, курс по машинному обучению представляет собой лишь общий обзор основных методов машинного обучения, реализованных в R в виде набора функций. При помощи нескольких базовых интерфейсов в R легко доступен широкий набор хорошо документированных алгоритмов машинного обучения, включающих машины опорных векторов (SVM), логистическую регрессию, метод К-ближайших и другие. Подключив нужный пакет и использовав лишь одну-две строки кода, можно обучить классификатор. R делает машинное обучение лёгким и доступным даже для неподготовленного человека, убирая лишние детали. Тем не менее, именно поэтому курс по машинному обучению на R оставил двоякое впечатление: с одной стороны всё объяснено максимально понятно и прозрачно, с другой – явно не хватает детального объяснения принципов работы того или иного алгоритма машинного обучения. Конечно, такая детализация и не являлась целью курса, но всё же ощущение некоторой «магии» происходящего осталось. Чтобы развеять это магическое ощущение, рекомендуется посмотреть специальный базовый курс по машинному обучению от одного из создателей Coursera Эндрю Ына ( Andrew Ng).
Практика: создание ПО для обработки данных (курс 9, дипломный проект)
Написанный на R код поможет вам при обработке данных только при выполнении следующих условий: у вас есть под рукой данные в нужном формате и у вас есть RStudio для выполнения кода обработки данных. Думаю, понятно, к чему я клоню – у конечного пользователя далеко не всегда может оказаться установленной на компьютере RStudio. Как же быть, если вы хотите продемонстрировать пользователю красоту ваших графиков, но не хотите терять и функциональность R? А что если вы хотите добавить интерактив для пользователя, а не пичкать его набором статичных отчётов? В этом случае вам прямая дорога к разработке программных продуктов на R. Разработчики продумали этот момент – Rstudio предоставляет качественный функционал по созданию и развёртыванию web-приложений, написанных на R.
Для решения задачи создания веб-приложений на R используется фреймворк создания приложений Shiny. В заключительном курсе специальности «Наука и данных» даются базовые знания и навыки программирования и развёртывания приложений на shiny R. Дипломный проект, хотя и охватывает в той или иной степени все навыки и знания, которые получили учащиеся на протяжении изучения курсов «Науки о данных», в большей степени сосредоточен всё на том же создании приложения.
В рамках курсов по созданию web-приложений на Shiny R предлагается попробовать себя в роли разработчика аналитических продуктов. На мой взгляд, весомым преимуществом 9-го курса оказалась возможность произвольного выбора темы приложения. Если ваша работа подразумевает интенсивную обработку больших объёмов данных, то имеет смысл попробовать обработать их при помощи R (естественно, с учётом требований конфиденциальности). Главным итогом разработки web-приложения на R становятся два файла: «ui.R», содержащий описание интерфейса программы, и «server.R», содержащий описание алгоритма обработки данных приложением. Написанное приложение может быть легко опубликовано в интернете при помощи этого сайта – надо всего лишь зарегистрироваться и связать его с вашей RStudio по инструкции на сайте. При этом следует помнить, что бесплатный доступ к вашему приложению для пользователей shinyapps.io ограничен: бесплатно ваше приложение может находиться в статусе «онлайн» лишь ограниченное время – 25 часов. Конечно, соответствующее программное обеспечение shiny server можно скачать и развернуть на своём сервере, после чего свободно разрабатывать и разворачивать новые приложения на shiny R бесплатно и без ограничений по времени. Это сложнее, но это тоже допустимый вариант. Так или иначе, для выполнения заданий курса вполне достаточно shinyapps.io. Ниже скриншоты пары общедоступных web-приложений на shiny R (написанных не мной).

Разработка на shiny R на мой взгляд имеет несколько некритичных недостатков:
- необходимость привыкнуть к формату записи кода в файлах ui.R и server.R;
- мало возможностей по настройке интерфейса непосредственно из ui.R;
- низкая скорость обработки больших массивов данных (за счёт высокого уровня абстракции R).
Так или иначе, с этими недостатками можно смириться – на R можно подготовить весьма неплохое web-приложение для демонстрации возможностей аналитики или инструмент коллективного пользования для команды аналитиков в стартапе или небольшой компании (если существующие инструменты не устраивают функциональностью, либо слишком дороги).
В рамках дипломного проекта специализации «Наука о данных» предлагается покорпеть над web-приложением, которое предсказывает следующее слово, которое захочет ввести пользователь. Такой функционал полезен для мобильных телефонов, хотя, как показывает практика, предсказательная мощь большинства таких приложений оказывается не очень высокой. В основу такого приложения ложатся алгоритмы машинного обучения и большие наборы данных из твиттера, блогов, а также новостные посты. Задача – на основе имеющихся наборов данных создать приложение, которое бы предсказывало следующее слово на основе уже введённых пользователем слов. И хотя для решения этой задачи требуется глубокое погружение в тему автоматического анализа неструктурированных текстов, R предоставляет в пакете tm достаточный инструментарий для построения простейших алгоритмов предсказания следующего слова.
Чтобы создать итоговое приложение для предсказания слов, предстоит пройти все изученные фазы анализа данных: сбор и предварительная обработка данных блогов, твиттера и новостей; разведочный анализ данных (чтобы определить действительно необходимый объём данных для предсказания слова); документирование особенностей наборов данных и результатов их обработки; построение математических моделей прогнозирования нового слова и разработка алгоритма машинного обучения для предсказания следующего слова; разработка и публикация web-приложения, которое может по набору введённых слов предсказать следующее слово. Простейший вариант такого web-приложения показан на рисунке – как раз то самое приложение, которое написал в рамках дипломного проекта по DSS. Приложение подсказывает нам несколько абсурдный вариант ответа: «Интересно опаздывать» (хотя уставшие офисные сотрудники или студенты наверняка найдут логику в этом утверждении ;-) )

Конечно, я не ставлю перед собой целью описать все перипетии и тонкости дипломного проекта специализации «Наука о данных», но можно уверенно сказать, что он даёт цельное понимание последовательности применения усвоенных навыков и знаний в процессе разработки реальных аналитических продуктов. С этой точки зрения дипломный проект просто безупречен, хотя выбор такой непростой темы как автоматический анализ текстов традиционны и вызывает нарекания у проходящих курсы специализации «Наука о данных».
Wrap-up
В целом специализация «Наука о данных» даёт общее представление о том, как правильно проводить анализ данных. Понятно, что для выполнения отдельных этапов лучше иметь узких специалистов в штате компании, но, тем не менее, эффективный и соответствующий потребностям компании анализ данных станет возможным только тогда, когда у компании есть специалист, способный выстроить весь процесс анализа данных, от начала и до конца. При этом важно умение не только «ковыряться в данных», но и в доступной и понятной форме предоставить результат клиенту.
Результат анализа данных должен помочь клиенту решить его насущные вопросы – в идеале: как сделать бизнес прибыльнее? Увы, никакие курсы не смогут научить отвечать на этот вопрос в любой ситуации и при любых данных. Специальность «Наука о данных» – первая ступенька на пути становления аналитика данных, дальнейшее движение по этому извилистому маршруту невозможно без практического опыта. Ну а поскольку рынок труда в аналитике данных ещё далёк от насыщения, дерзайте – сложные задачи и новые карьерные горизонты ждут!
Вместо заключения – ещё несколько полезных курсов Coursera
Курс «Работа с массивными данными»: о Big Data доступным языком с неподражаемым гуру компьютерных технологий Джефом Ульманом.
Курс «Компьютерное обучение»: для тех, кому оказалось мало машинного обучения в DSS.
Курс «Анализ текстовой информации»: для тех, кто хочет предсказывать больше одного слова за раз ;-)
Читайте в первой части этого поста: О специальности Data Science в общих чертах. Курсы: Инструменты анализа данных (программирование на R); Предварительная обработка данных; Документирование процесса обработки данных.
