Особенности использования Druid на примере Одноклассников

Меня зовут Юрий Невиницин, и я занимаюсь системой внутренней статистики в «ОК». Хочу рассказать о том, как 50-терабайтную аналитическую систему реального времени, в которой ежедневно журналируются миллиарды событий, мы переносили с Microsoft SQL на колоночную базу под названием Druid. И заодно вы узнаете несколько рецептов использования Druid«а.
Зачем нам статистика?
Мы хотим знать всё про свой сайт, поэтому журналируем не только поведение дисков, процессоров, и т. д., но и каждое действие пользователя, каждое взаимодействие между подсистемами и все внутренние процессы практически всех наших систем. Система статистики тесно интегрирована в процесс разработки.
На основании данных из системы статистики наши менеджеры ставят командам цели, отслеживают их достижение и ключевые показатели. Администраторы и разработчики следят за работой всех систем, расследуют инциденты и аномалии. Автоматический мониторинг постоянно отслеживает и на ранней стадии выявляет неполадки, строит прогнозы по превышению лимитов. Также у нас постоянно запускаются фичи и эксперименты, вносятся обновления и изменения. И эффект от всех этих действий мы отслеживаем через систему статистики. Если она откажет, мы не сможем вносить изменения на сайт.
Статистика у нас представлена, в основном, в виде графиков. Обычно на графике отображается сразу несколько дней, чтобы была понятна динамика. Вот пример моих экспериментов с Druid. Здесь график загрузки данных (строк/5 мин).
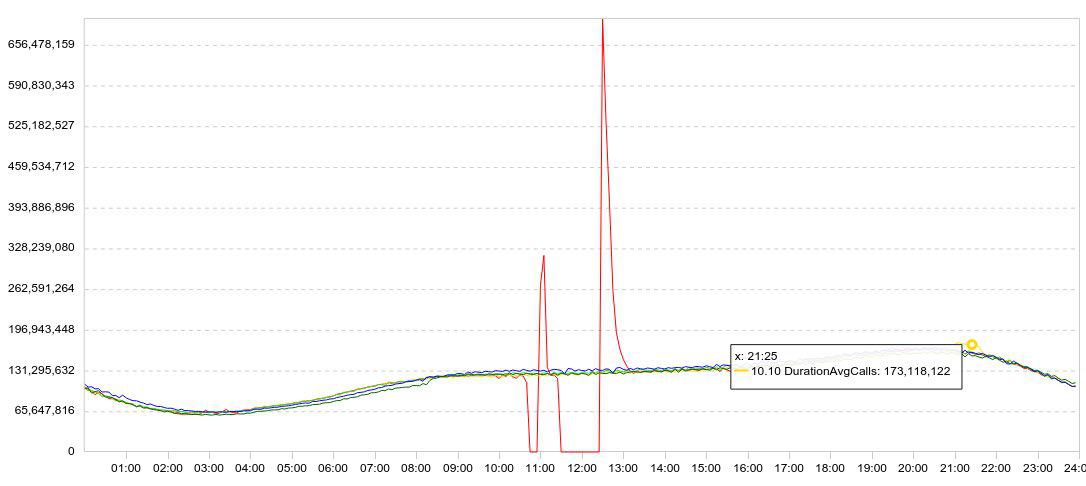
Я притормаживал загрузку (красный график проваливается в ноль), выжидал некоторое время, перезапускал загрузку, и смотрел, как быстро Druid сможет загрузить накопленные данные (пики после провалов).
Любой график можно разложить по любому параметру, например, по хосту, таблице, операции, и т.д. Также у нас есть долгосрочные графики с годовой динамикой. Для примера ниже график посуточного увеличения количества записей в Druid.
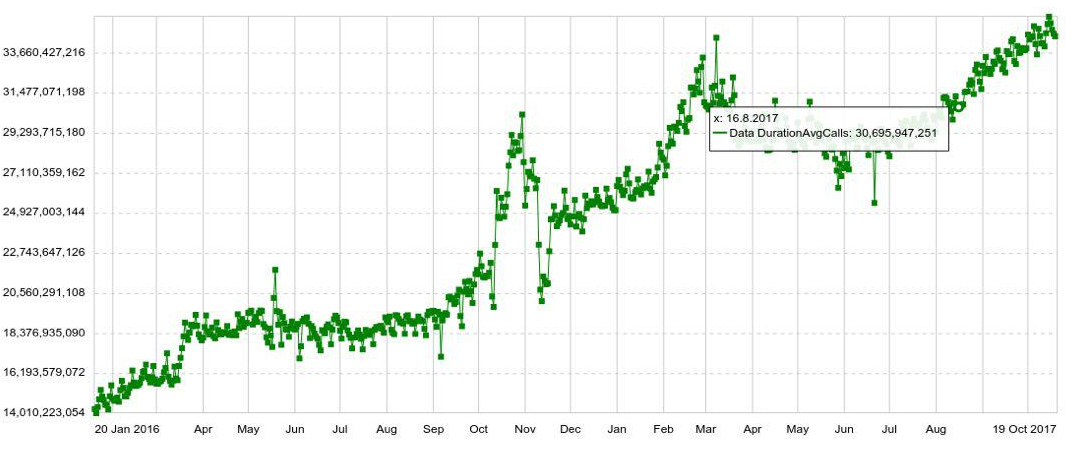
Также мы можем комбинировать по несколько графиков на отдельных панелях (дашбордах), что оказалось очень удобно. И даже если пользователю нужно посмотреть всего пару графиков из сотни, он всё равно открывает их не по отдельности, а в панели, что усиливает нагрузку на систему.
Проблема
Пока объем данных был маленький, мы вполне справлялись с SQL. Но по мере роста объема данных выдача графиков замедлялась. И в конце концов статистика в час пик стала отставать на полчаса, а среднее время отклика одного графика достигло 6 секунд. То есть кто-то получал график за 2 секунды, кто-то за 10—20, а кто-то и за минуту. (О развитии системы на SQL можно почитать здесь)
Когда расследуешь аномалию или инцидент, обычно требуется открыть и посмотреть десяток графиков, причем каждый следует из предыдущего, их невозможно открыть одновременно. Приходилось 10 раз ждать по 10—20 секунд. Это сильно раздражало.
Миграция
Можно было еще что-то выжать из системы, добавить серверы… Но примерно в это же время Microsoft поменяла политику лицензирования. Если бы мы продолжили использовать SQL Server, то пришлось бы отдать миллионы долларов. Поэтому решили мигрировать.
Требования были такие:
- Статистика не должна отставать (более чем на 2 минуты).
- График должен открываться не больше, чем за 2 секунды.
- Вся панель должна открываться не больше, чем за 10 секунд.
- Система должна быть отказоустойчивой, способной пережить потерю дата-центра.
- Система должна быть легко масштабируемой.
- Система должна быть удобной для модифицирования, поэтому мы хотели, чтобы она была на Java.
Всё это нам предлагал только Druid. Также в нем есть предварительная агрегация, которая позволяет еще немного сэкономить объем, и индексация во время вставки данных. Druid поддерживает все типы запросов, которые нужны для нашей статистики. Поэтому казалось, что мы легко можем подставить Druid вместо SQL Server.
Разумеется, на роль кандидата для переезда мы рассматривали не только Druid. Первой мыслью было заменить Microsoft SQL Server на PostgreSQL. Однако это решало бы лишь проблему финансовых затрат, но никак не помогло бы с доступностью и масштабированием.
Также проанализировали Influx, но оказалось, что часть, которая отвечает за высокую доступность и масштабируемость, закрыта. Prometheus, при всём уважении к его производительности, больше заточен под мониторинг и не может похвастаться ни высокой доступностью, ни простой масштабируемостью. OpenTSDB тоже больше годится под мониторинг, в ней нет индексов по всем полям. Click House мы не рассматривали, так как на тот момент его не было.
Поставили Druid. Смигрировали терабайты данных. И сразу же после переключения с SQL Server на Druid количество просмотров графиков выросло в 5 раз. Дальше начали запускать «тяжелую» статистику, которую раньше запускать боялись, т.к. SQL вряд ли справился бы.
Сейчас Druid из 12 нод (40-ядер, 196 GB RAM) забирает 500 тыс. событий в секунду в час пик, при этом есть большой запас прочности (колонка MAX: почти пятикратный запас по CPU).
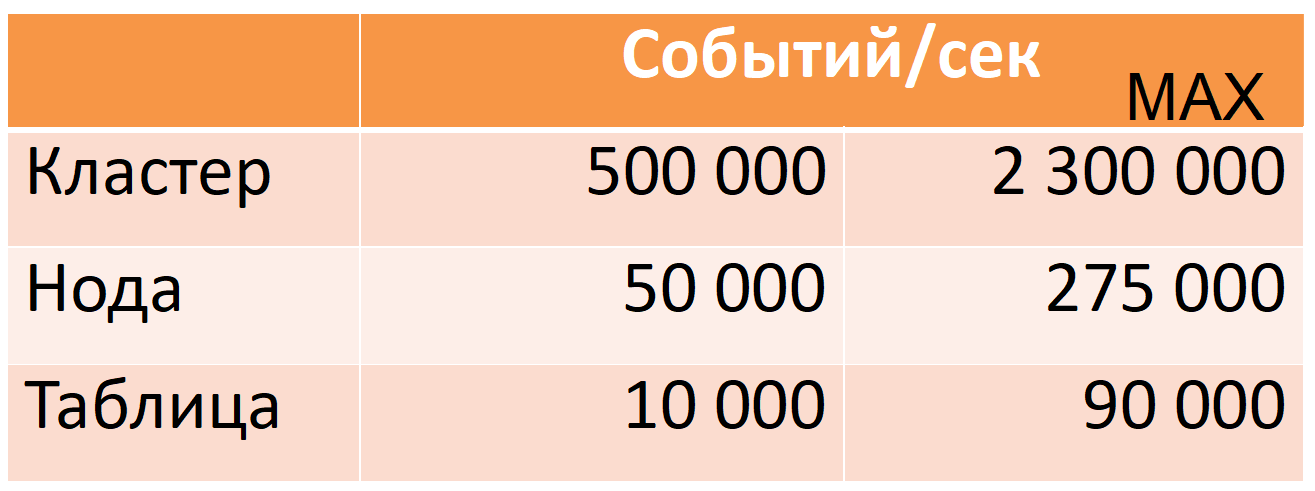
Эти показатели сняты на production-данных. Расскажу, как мы этого добились, но сначала подробнее опишу сам Druid.
Druid
Это распределенная колоночная timeseries OLAP система. (В его документации нет привычных для мира SQL понятий таблица (вместо неё datasource) и строка (вместо неё event), но я буду их использовать для простоты описания).
Druid основан на нескольких допущениях (ограничениях) о данных:
- в каждой строке данных есть timestamp, который монотонно растёт (в пределах окна в 10 минут по умолчанию).
- данные не меняются, Insert only (операции Update нет).
Это позволяет нарезать данные на так называемые сегменты по времени. Сегмент — это минимальная неделимая и неизменная «партиция» одной таблицы за определенный промежуток времени. Все операции с данными, все запросы выполняются посегментно.
Каждый сегмент самодостаточен: помимо основной таблицы, записанной в колоночном виде, в нем также содержатся справочники и индексы, необходимые для выполнения запросов. Можно сказать, что сегмент — это небольшая колоночная read-only БД (Более детальное описание устройства сегмента будет ниже).
В свою очередь, отсюда возникает «распределенность»: возможность поделить большой объем данных на небольшие сегменты, чтобы выполнять вычисления параллельно (как на одной машине, так и на многих сразу).
Если требуется «проапдейтить» хотя бы одну строку, придется заново перезагрузить сегмент целиком. Это возможно и для этого всё готово. Каждый сегмент имеет версию, и сегмент с более свежей версией автоматически вытеснит сегмент со старой версией (однако, если update требуется регулярно, то стоит переоценить подходит ли Druid для этого usecase).
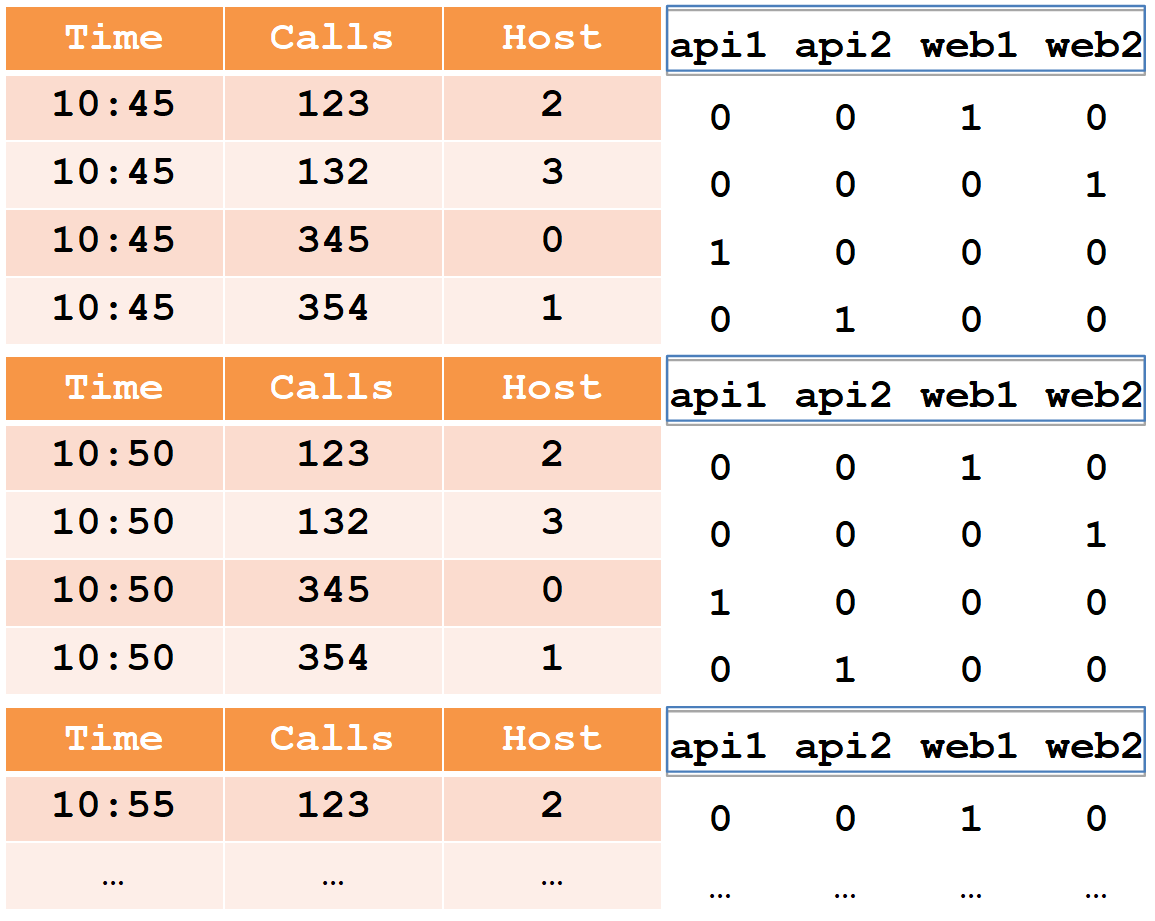
Для описания устройства сегмента рассмотрим простой пример в привычном табличном виде:
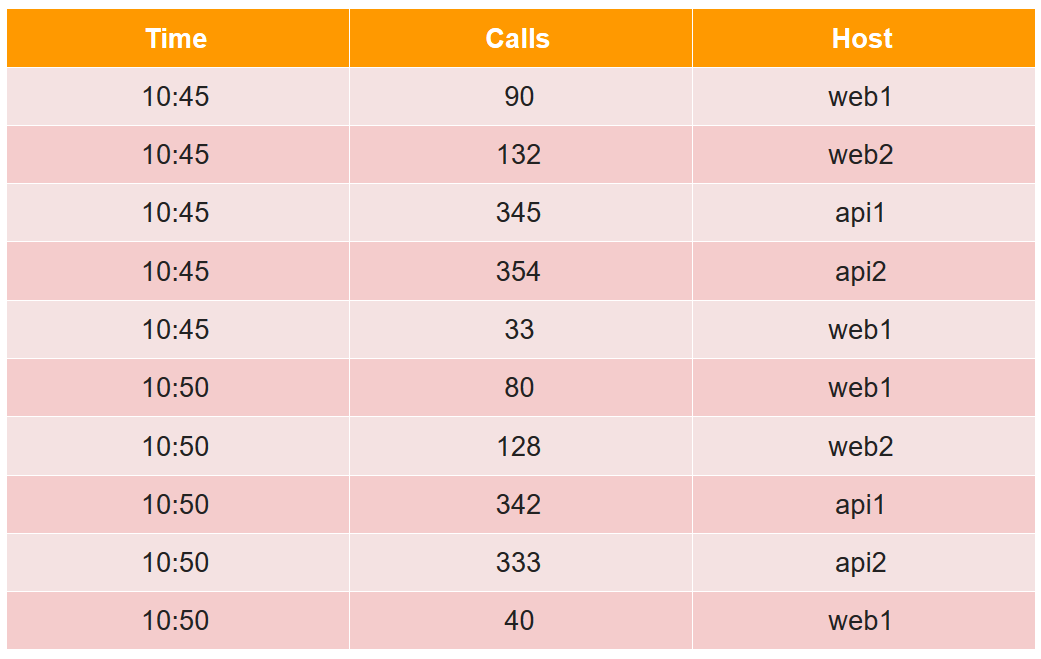
В этой таблице количество вызовов (calls) за две пятиминутки с четырех хостов (обратите внимание, для хоста web1 по две строки в каждой пятиминутке).
Все ячейки данных с точки зрения друида делятся на три вида:
- timestamp — UTC timestamp в мс (в примере это Time).
- metrics — это то, что нужно посчитать (sum, min, max, count, …), причем их нужно знать заранее для каждой таблицы (в примере это Calls, и считать мы будем сумму).
- dimensions — это то, по чему можно группировать и фильтровать (их заранее знать необязательно и можно менять на лету) (в примере это Host).
При вставке все строки группируются по полному набору dimensions+timestamp, и при совпадении к каждой из metrics применяется «её» агрегационная функция (в результате нет строк с одинаковым набором dimensions+timestamp). Таким образом наш пример после вставки в друид станет выглядеть так:

Timestamp и все metrics (в нашем случае это Time и Calls) будут записаны в виде массивов чисел типа long (float и double тоже поддерживаются). Для каждого из dimensions (в нашем случае это Host) будет создан словарь — отсортированный набор строк (с именами хостов). Сама колонка хостов будет записана в виде массива int, указывающих на номера в словаре.
Обратите внимание, что после вставки в друид, пары строк для хоста web1 с совпадающим timestamp были агрегированы, и в calls записана итоговая сумма (вытащить исходные данные из друида невозможно).
Для быстроты фильтрации данных требуются индексы, ведь здесь могут быть миллионы строк и тысячи хостов. Индексы представляют собой битмапы, по одному на каждую строку в словаре.

Единички означают номера строк, в которых участвует этот хост. Чтобы отфильтровать два хоста, нужно взять два битмапа, объединить их через ИЛИ, и в полученном битмапе по единицам выбрать номера строк.
Друид состоит из множества компонентов.
Во-первых, он имеет несколько внешних зависимостей.
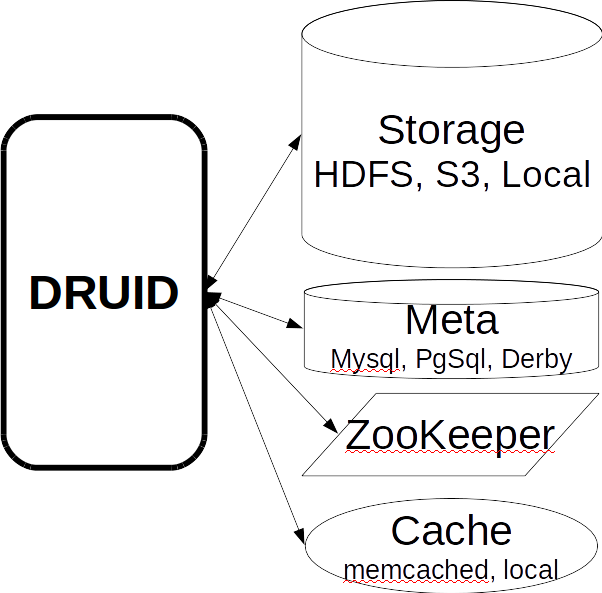
- Storage. Там Druid просто хранит сегменты в сжатом виде. Это может быть локальная директория, HDFS, Amazon S3. Здесь используется только место, никаких вычислений не делается.
- Meta: база данных для Meta-информации. В этой базе хранится полная карта данных: какие сегменты актуальны, какие устарели, по какому пути в находятся в storage.
- С помощью ZooKeeper система выполняет discovery и объявляет, на каких нодах друида какие сегменты доступны для запроса.
- Cache выполненных запросов, это может быть memcached или локальный кеш в java heap.
Во-вторых сам Druid состоит из компонентов нескольких видов.
- Realtime-ноды загружают поток свежих данных в порядке их поступления и обслуживают запросы по ним.
- Historical-ноды содержат всю массу данных и обслуживают запросы по ним. Когда мы говорим, что у нас кластер на 300 Тб, то имеем в виду именно historical-ноды.
- Broker отвечает за распределение вычислений между historical- и realtime-нодами.
- Coordinator отвечает за распределение сегментов по historical- нодам и за репликацию.
- Indexing service, который позволяет (пере-)загружать данные пакетно, например чтобы «проапдейтить» часть данных.
Поток данных
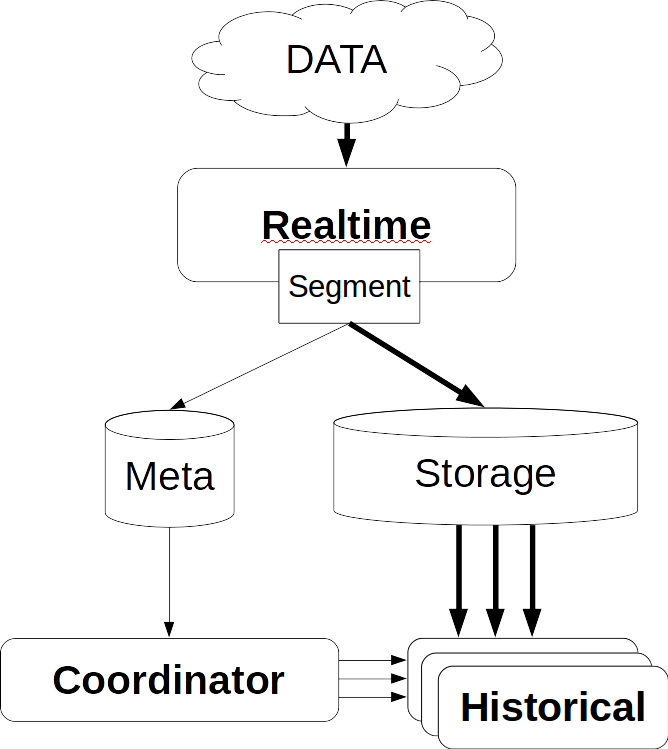
Жирными стрелками обозначен поток данных, тонкими — поток метаданных.
Realtime-нода берет данные, индексирует и нарезает на сегменты по времени, например, по суткам.
Каждый новый сегмент realtime-нода записывает в storage и оставляет свою копию, чтобы обслуживать запросы по нему. Затем она записывает метаданные, о том, что в хранилище по такому-то пути появился новый сегмент.
Эту информацию получает координатор, периодически перечитывая базу метаданных. Когда он находит новый сегмент, то (через ZooKeeper) приказывает нескольким historical-нодам скачать этот сегмент. Те скачивают и (через ZooKeeper) объявляют, что у них появился новый сегмент. Когда realtime-нода получает это сообщение (через ZooKeeper), она удаляет свою копию, чтобы освободить место для новых данных.
Обработка запросов

В обработке запросов участвуют ноды трёх видов: broker, realtime и historical. Запрос приходит в broker, который знает, на каких нодах какие сегменты находятся. Он распределяет запрос по historical (и realtime) нодам, хранящим нужные сегменты. Historical ноды также распараллеливают вычисления насколько это возможно, отправляют результаты брокеру, а тот отдает их клиенту. Благодаря сочетанию этой схемы с колоночным хранением данных Druid может очень быстро обрабатывать большие объемы информации.
Высокая доступность
Как вы помните, у Druid в списке зависимостей есть база для метаданных, которая бывает MySQL или PostgreSQL. Упоминается ещё Apache Derby, но этот продукт нельзя использовать для production, только для разработки (как я понял, derby используется в embedded-виде, чтобы в дев-среде не поднимать mysql/pgsql).
Что будет, если откажет эта база (и/или storage и/или координатор)? Realtime-нода не сможет записывать метаданные (и/или сегменты). Тогда координатор не сможет их перечитать и не найдет новый сегмент. Historical нода его не скачает, и realtime-нода не удалит свою копию, но продолжит скачивать свежие данные. В результате данные начнут копиться в realtime-нодах. Бесконечно это продолжаться не может. Тем не менее, известно, какие ресурсы доступны на realtime-нодах, и какой у нас поток данных. Поэтому у нас есть предсказуемый запас времени, за который мы можем починить отказавшую базу (и/или storage и/или координатор).
Поскольку поддерживаемые mysql/pgsql не гарантируют высокую доступность из коробки, мы решили перестраховаться и использовали собственное (уже готовое) решение на базе Cassandra, так как она из коробки обеспечивает высокую доступность (подробно о нем можно почитать здесь).
Кроме того, мы доработали realtime-ноды таким образом, что при избыточном накоплении самые старые данные удаляются, освобождая место для новых. Для нас это очень важно, потому что ситуация, когда мы долго не можем поднять отказавшую базу (и/или storage и/или координатор), и накапливается много данных, скорее всего, является следствием большой аварии. И в этот момент самые свежие данные важнее всего.
Druid и ZooKeeper
С ZooKeeper всё и лучше, и хуже. Лучше потому, что ZooKeeper сам по себе отказоустойчивый, у него из коробки есть репликация. Казалось бы, что может случиться?
Вообще говоря, эта глава уже не актуальна. И это не success-story, это боль, которую (и мы, и в свежем друиде) решили кардинально, убрав почти все данные из ZooKeeper, и теперь ноды друида запрашивают их друг у друга напрямую по HTTP.
В ZooKeeper есть два вида таймаутов. Таймаут соединения — это простой сетевой таймаут, по истечении которого клиент заново подключается к ZooKeeper и пытается восстановить свою сессию. И таймаут сессии, по истечении которого, сессия удаляется и все ephemeral-данные созданные в рамках этой сессии тоже удаляются (самим ZooKeeper«ом), о чем оповещаются все остальные клиенты ZooKeeper«a.
На основе этого работает discovery в друиде: при запуске каждая нода создает новую сессию в ZooKeeper и записывает ephemeral-данные о себе: host: port, тип ноды (broker/realtime/historical/…), timestamp подключения, и т.д… Другие ноды друида получают уведомления от ZooKeeper и вычитывают эти данные, так они узнают о том, что поднялась новая нода друида и что именно это за нода. Если какая-то нода друида упала, по истечении таймаута её сессии, данные о ней будут удалены ZooKeeper«ом, и остальные ноды друида об этом узнают. Чтобы они узнавали об этом быстрее, мы предпочли проставить маленький таймаут сессии.
Когда поднимается realtime или historical нода, она кроме данных о себе также записывает в ZooKeeper список сегментов, которые у неё есть (это тоже ephemeral-данные). Дальше по ходу работы, сегменты на realtime и historical нодах создаются новые и удаляются старые, и каждая нода отражает это в своём списке в ZooKeeper. Этот список может быть большим, поэтому он разбивается на части, чтобы перезаписать не весь список, а только измененную часть.
Broker, в свою очередь, когда видит новую realtime или historical ноду, также вычитывает из ZooKeeper её список сегментов, чтобы распределять запросы и на эту ноду. Realtime ноды вычитывают этот список, чтобы удалить свою копию сегмента, который появился на historical ноде. Поскольку список разбит на части, и перезаписывается по частям, ZooKeeper подскажет, какая именно часть была изменена, только она и будет перечитана.
Как я говорил, этот список может быть большим. Когда данных в ZooKeeper становится много, тогда и выясняется, что он уже не так стабилен. В нашем случае явные проблемы начались, когда количество сегментов достигло примерно 7 млн, снапшот ZooKeeper тогда занимал 6GB.
Что происходит в случае, если нода друида теряет связь с ZooKeeper?
Druid работает с ZooKeeper таким образом, что в случае таймаута сессии каждая нода создаёт новую сессию и записывает туда все свои данные и перечитывает данные других нод. Поскольку данных много, взлетает трафик на ZooKeeper-ах. Это может привести к таймауту на других нодах друида, тогда они тоже начнуть перезаписывать и перечитывать. Таким образом трафик растет лавинообразно вплоть до того, что ZooKeeper теряет синхронизацию между своими инстансами и начинает гонять туда-сюда снэпшоты.
Что в этот момент видит пользователь?
Когда broker теряет связь с ZooKeeper (и происходит таймаут сессии), то уже не знает, какие сегменты на каких historical нодах лежат. И выдает пустые ответы. То есть если ZooKeeper лег, то и Druid не работает. «Вылечить» это полностью нельзя, но можно кое-где подстелить соломки.
Во-первых, можно удалять данные из ZooKeeper. Ничего страшного, если они потеряются: Druid их просто перезапишет. Если проблема с ZooKeeper уже началась, то для её скорейшего решения рекомендуется отключить ZooKeeper, удалить данные и поднять его пустым, а не ждать, когда само рассосется.
Теперь мы повышаем таймаут сессии. Что происходит в этом случае?
Допустим, историческая нода перезапустилась некорректно и не удалила старую сессию из ZooKeeper, при этом создала новую и записала туда кучу данных. Пока старая сессия еще жива и не прошел таймаут, в ZooKeeper хранятся две копии данных. Если таких нод перезапустится много сразу, то и данных будет продублировано немало. Поэтому нужно держать для ZooKeeper запас памяти, чтобы она у него не кончилась и ZooKeeper не перестал работать. Почему нельзя было удалить данные старой сессии?
По той же причине нужно обязательно корректно завершать работу historical нод, так как они в этот момент удаляют свои данные из ZooKeeper, причем могут делать это долго. У нас завершение исторических нод занимает примерно полчаса.
У исторических нод есть еще одна особенность. Когда они запускаются, то смотрят, какие на них хранятся сегменты, и потом информацию об этом записывают в ZooKeeper. А поскольку данные размазаны по историческим нодам более или менее равномерно, то если их запускать одновременно, то и в ZooKeeper они начнут писать примерно одновременно. Это снова повышает вероятность волнообразного роста трафика и возникновения таймаутов. Поэтому запускать исторические ноды нужно последовательно, чтобы разнести сессии записи в ZooKeeper по времени.
Также мы сделали ещё две оптимизации:
- Немного перепрограммировали работу с ZooKeeper так, чтобы из Druid вычитывали данные только те ноды, которым они нужны. А нужны они только realtime, брокеру и координатору, но не историческим нодам. Им не нужно знать, у каких других исторических нод какие есть сегменты. Также всё это не нужно сервису индексирования и его воркерам, которых может быть много.
- Из данных, которые пишутся в ZooKeeper, убрали всё лишнее и оставили лишь то, что необходимо для выполнения запросов. Это сократило объем данных в ZooKeeper с 6 Гб до 2 Гб (это размер снапшота).
В результате объём резко вырастающего трафика снизился примерно в 8 раз; тем самым мы максимально снизили вероятность возникновения веерных таймаутов.
Загрузка в Druid
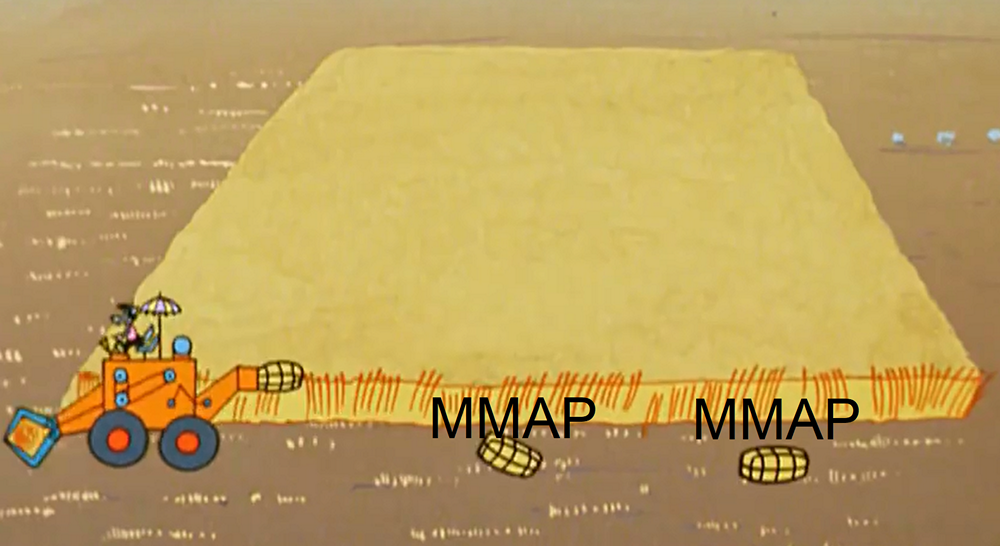
По ходу загрузки данных realtime нода периодически освобождает память, сбрасывая данные по частям на диск. Технически эти части представляют собой мини-сегменты (в каждой есть таблица, справочники, индексы). А для обработки запросов по этим данным, они подтягиваются с помощью MMAP (как и полноценные сегменты). К концу загрузки одного сегмента таких частей накапливается довольно много. С этим связано два момента.
Во-первых, realtime-нода может испортить данные, причем не только во время крэша JVM или неожиданной перезагрузки сервера, но даже во время корректного перезапуска.

Происходит это вот почему. Процесс сброса данных на диск состоит из двух частей: 1) непосредственно сброс данных и 2) сохранение позиции с которой начинать после перезапуска. Эти два типа данных записываются совершенно независимо, друг про друга они ничего не знают. И, конечно же, не атомарно. И в зависимости от того, что именно потеряется, у нас происходит или потеря данных, или дублирование. (В данный момент, в оригинальном друиде это активно чинится, но не починено).
Эту проблему можно решить, если не использовать realtime-ноды и загружать данные с помощью сервиса индексирования, или использовать их в паре, т.к. сервис индексирования вообще не сохраняет позицию, он либо загрузит сегмент целиком, либо выбросит то, что загрузить не удалось (по любой причине).
Второй момент, это деградация производительности по запросам. Чем больше этих частей накапливается на диске, особенно на тяжелых данных и запросах, тем хуже.
Чтобы разобраться в этой проблеме, нужно вернуться к устройству сегмента в Druid и нашему примеру. Как я показывал ранее, после загрузки данных из примера в друид, результирующий сегмент будет выглядеть как набор колонок, словарь и индексы к нему.
Теперь разберёмся, как работает запрос по этому сегменту. Допустим, нужно посчитать общее количество вызовов по нескольким классам хостов (web%, api%).
- Druid сначала возьмет первый фильтр — регулярное выражение. С его помощью обработает весь словарь и найдет удовлетворяющие фильтру хосты.
- Возьмет соответствующие битмапы, объединит и сохранит в промежуточный битмап.
- Затем Druid возьмет вторую регулярку, второй фильтр, сделает то же самое: пройдет по словарю, возьмет битмапы, объединит, получит промежуточный второй битмап.
- В конце Druid полученную пачку промежуточных битмапов объединяет в конечный битмап, который и покажет, из каких именно строк нам нужно просуммировать calls.
С помощью профилировщика я выяснил, что при обработке запроса 5% времени тратится на подсчёт суммы, а 95% — на фильтрацию.
Теперь посмотрим, что происходит, когда realtime-нода сбрасывает данные по частям на диск во время загрузки.
Начали качать данные, сбросили часть (за 10:45) на диск. Получился мини-сегмент с тремя колонками, словарём и битмап-индексами. Качаем дальше, сбрасываем вторую часть (за 10:50) на диск, опять получился мини-сегмент. И так далее. Если проанализировать по частям, то мы заметим, что колонки «calls», «time» и «host» по этим частям разрезались пропорционально.
Но со словарём и индексами выходит по-другому. Каждый хост раз в пять минут сбрасывает свои данные, поэтому все хосты «отмечаются» в каждой части сброшенной на диск. Словарь получается одинаково большим, он никак не разрезан, и индексов к нему столько же. При обработке запроса проход по словарю и объединение битмапов (на что уходит 95% времени) нужно выполнить для каждой из частей, поэтому зависимость практически линейная: чем больше частей, тем дольше работает запрос. Это почти не заметно пока в словаре до 100 значений, и станет очень заметно тормозить когда их станет больше 1000.
Что можно с этим сделать? Можно контролировать количество частей, сброшенных на диск. Например, если у вас суточный сегмент и запросы тормозят в realtime нодах, то сократите его до часового. Тогда количество частей сократится пропорционально (т.к. данные будут быстрее перемещаться в historical ноды и удаляться с realtime-нод), и тормозить будет пропорционально меньше.
Также есть два параметра, которые позволяют контролировать частоту сброса этих частей на диск: максимальное количество строк в памяти и интервал сброса на диск. Например, можно сбрасывать не раз в пять минут, а раз в полчаса. И не каждые 100 тыс. строк, а каждый миллион. Тогда частей станет меньше и всё будет работать в разы быстрее.
Еще есть важный момент. Иногда 80% времени, уходящего на фильтрацию, занимает проход по словарю регулярными выражениями, а не объединение битмапов. Мы об этом не знали и при миграции все фильтры сделали регулярными выражениями. Так делать не надо. Когда мы фильтруем по точному значению, следует использовать фильтр типа selector, так как он бинарным поиском находит нужное значение и сразу достает битмап. Это работает в тысячу раз быстрее, чем регулярное выражение.
Оптимизация ленты
Как вы знаете, в любой соцсети есть лента событий, собирающая контент, создаваемый всеми командами разработчиков. Конечно, все эти команды хотят смотреть и писать статистику. У нас статистика ленты пишется в одну табличку, 8 млрд строк в сутки. Она тормозила даже в Druid. И самое страшное, что когда она тормозила, то перегружала весь Druid, то есть тормозило всё и у всех. В этой статистике было комбинированное поле, которое состоит из нескольких слов соединённых через точку. Примерно так:

Мы можем полайкать фото на главной, в альбоме, в группе. То же самое с видео и музыкой. Также мы можем на главной, в альбоме и в группе поделиться фотографиями, видео и музыкой. И можем всё прокомментировать. Итого получилось 27 комбинаций событий. Соответственно, в словаре будет 27 строчек, 27 битмапов.
Мы хотим посчитать, сколько было лайков. Этот запрос пройдет регулярным выражением по 27 значениям в словаре, выберет из них 9, достанет 9 битмапов, объединит и пойдет считать.
Теперь давайте разрежем это на три части.

Первая — действие: лайкнули, поделились, прокомментировали. Вторая часть — объект: фото, видео, музыка. Третья часть — место: на главной, в альбоме, в группе. Тогда запрос пойдет всего по одному словарю — действие, в котором всего три значения и три битмапа. Для чистоты эксперимента допустим, что это тоже регулярное выражение. То есть в данном случае будет три регулярных выражения, а в предыдущем их было 27. Битмапов было 9, сейчас один. В результате в проход по словарю и объединение битмапов (на что уходит 95% времени) мы сократили в 9 раз. И это мы всего лишь словарь из 27 строк разрезали на три.
В реальности у нас было 14 тыс. комбинаций. Соответственно, у нас в словаре было 14 тыс. значений и 14 тыс. битмапов. В результате, когда мы разрезали это поле на маленькие части по словам, скорость статистики ленты выросла в 10 раз, а размер данных сократился вдвое. Теперь всё работает быстро.
Приоритеты запросов
Но вот приходит пользователь и хочет посмотреть статистику за год, это 2 ТБ. На нашем кластере нужно поднять по 11 ГБ с диска, на это потребуется 74 секунды. Пользователь знает, что запрашивает тяжелые данные и готов подождать. Но что будут делать остальные пользователи эти 74 секунды? Мягко говоря, они будут нервничать и спрашивать почему графики не работают.
Druid позволяет выставлять приоритеты запросов. Мы попробовали снизить приоритет тяжелым данным, стало полегче, но всё равно тормозило, потому что приоритеты работают на уровне очереди. Это значит, что если часть тяжелого запроса уже попала в обработку, то всем придется подождать. Потом легкие, быстрые запросы проскакивают вперед, и снова тяжелые запросы занимают все ресурсы. Возникает ощущение, что система работает натужно, на пределе.
Мы воспользовались тем обстоятельством, что у Druid есть вся информация о запросе и о данных. Реализовали простую приоритезацию, которая выставляет приоритет по количеству (в мегабайтах) данных, которые этот запрос пройдет. При этом мы сделали 5 очередей: одна для самых тяжелых запросов, одна для самых легких и три промежуточные. В них раскидали запросы по вычисленному приоритету. У каждой очереди есть приоритет на уровне операционной системы (выставляется стандартными средствами и настройками java), таким образом быстрые запросы вытесняют тяжелые. Теперь наконец Druid заработал так, как от него ожидаешь.
Итог
Мы внедрили отказоустойчивую, распределенную, быструю систему вместо SQL Server, и не отдали несколько миллионов долларов Microsoft.
Мы получили легкую горизонтальную масштабируемость, нужно просто добавлять диски и/или сервера по необходимости.
Мы получили большой запас по производительности как вставки данных, так и запросов, и возможность детализировать нашу статистику на порядок.
На текущий момент у нас более 20 таблиц, в каждую из которых пишется более миллиарда строк в сутки, в самую большую пишется 18 млрд строк в сутки.
Наш друид почти целиком переведен в one-cloud (https://habr.com/company/odnoklassniki/blog/346868/), что еще сильнее упрощает процедуру масштабирования.
