Organization as a Function. Введение в бережливую разработку для инженеров
Когда я учился в вузе, нашей группе дали домашнее задание — рассчитать результаты социологического опроса. Каждому выдали excel-файл с исходными данными. В методических указаниях была детально описана последовательность шагов: в каких ячейках таблицы что писать, какие выражения для вычислений использовать и т.д.
Вручную делать эту механическую работу не хотелось, и мы решили, что сделаем макрос, который будет выполнять методические указания. Что в них было написано, то макрос и делал.
Наша программа правильно выполняла свою задачу: на экране в бешеном темпе курсор прыгал по ячейкам, писал в них формулы, выделял диапазоны данных. Выполнение программы занимало 40 минут, а загруженность процессора была 100%. Мы хотели быстрее. Может быть, надо запустить программу на компьютере помощнее? Или написать распределенную программу и собрать компьютеры в кластер? Любой здравомыслящий программист поймет, что это плохие решения и ускорения можно добиться куда более простыми методами. Мы исследовали причины низкой производительности и обнаружили, что вся проблема была в том, что программа механически повторяла методические указания. Гораздо эффективнее было не повторять поведение человека в Excel, а перенести все данные из таблицы в память, выполнить необходимые расчеты и записать результаты обратно. Новая версия программы работала 50 мс, так мы оптимизировали программу приблизительно в 50000 раз.
На первый взгляд может показаться, что эта история никак не связана с организацией разработки программного обеспечения, но на самом деле приемы разработки эффективного ПО имеют системную природу и находят применение в разных областях.
В производстве подобные приемы были созданы в Toyota и назывались Toyota Production System. Эти приемы были обобщены до бизнеса в целом в виде философии кайдзен. В области разработки программного обеспечения их называют приемами бережливой разработки программного обеспечения.
Согласитесь, как здорово улучшить работу организации в 50 000 раз! Это конечно сказки, но и 10% может быть весьма неплохо.
Когда мы оптимизируем программное обеспечение, мы внедряем изменения, которые улучшают некоторые показатели. Например, время выполнения программы или пропускную способность. Чтобы понять, как применить приемы оптимизации программного обеспечения к организации надо выяснить, что является показателями организации, которые надо улучшать.
Моделируем организацию
Цель коммерческой организации — получение и увеличение прибыли. Наши оптимизации так или иначе должны увеличивать прибыль. Путь от работы инженера до финансовых результатов может быть длинным, улучшить непосредственно финансовые метрики получится далеко не всегда. Давайте проследим, как работа инженера влияет на прибыль организации.
Прибыль = доходы - расходы
Зарплата, аппаратура, оплата интернета, программное обеспечение и т.п. входит в расходы и понятно, как инженер на это влияет.
С доходами чуть сложнее. Путь их поступления в организацию зависит от бизнес-модели: некоторые организации продают ПО, а другие предоставляют сервисы. В этой статье мы рассмотрим предоставление сервиса, как это происходит в Joom. Мы получаем следующие составляющие дохода, которые зависят от инженеров.
Сервис должен приносить выгоду пользователю. То есть его функциональность должна быть полезной. Joom, например, продает и доставляет товары.
Сервис должен надежно и правильно работать. Если он не работает или работает не так, то грош цена всей его функциональности.
Программисты вкладываются в обе составляющие наряду с командами инфраструктуры и DevOps.
Цель разработчиков программного обеспечения — создавать функциональность, которая прямо или косвенно приносит пользу и поддерживать ее в работоспособном состоянии, тратя на это минимум ресурсов.
Продуктовые команды разработки создают функциональность, которая непосредственно приносит пользу. Инфраструктурные команды делают инструменты, которые сокращают расходы команд разработчиков. Команды эксплуатации или DevOps поддерживают все в работоспособном состоянии.
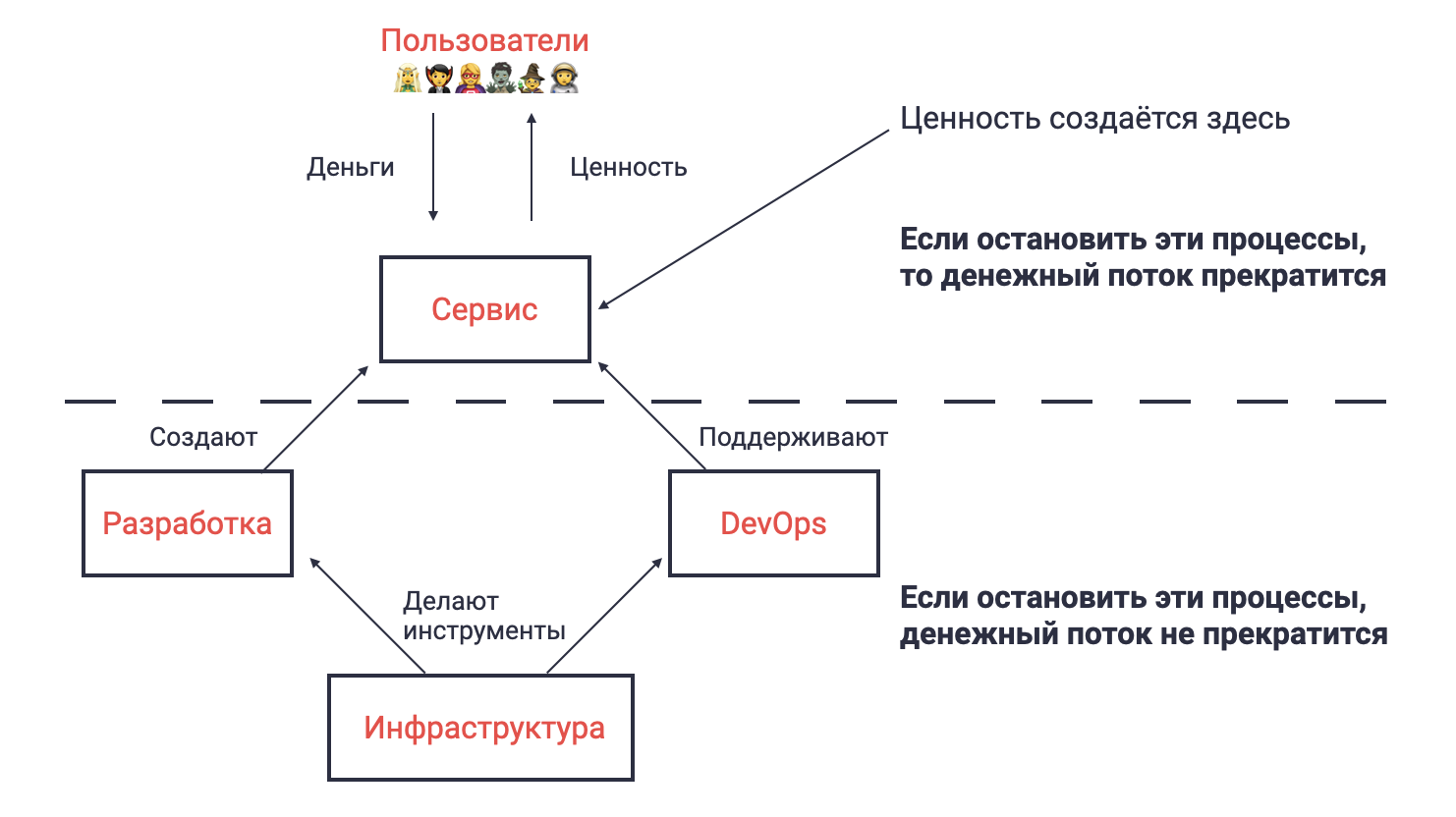
Решение о том, какая функциональность нужна пользователю, приходит через взаимодействие организации со внешней средой — анализ рынка, исследования и эксперименты.
Вернемся к аналогии про оптимизацию программного обеспечения.
Организацию можно представить как функцию. В качестве аргумента она принимает внешнюю информацию — анализ рынка, результаты исследований и экспериментов. На выходе функция оказывает услуги пользователю и если пользователь доволен тем, что он получил, то он платит организации. Чем большую пользу оказывает наша функция-организация, тем выше ее доход.
Функция при своей работе тратит ресурсы. Когда мы говорим о настоящей функции в программе, речь идёт обычно о CPU, памяти и времени выполнения. Когда мы говорим об организации — о деньгах и времени производства.
Приступим к оптимизации!
Давайте заглянем в код нашей функции-организации. Мы увидим там цепи создания ценностей и методологию разработки, например:
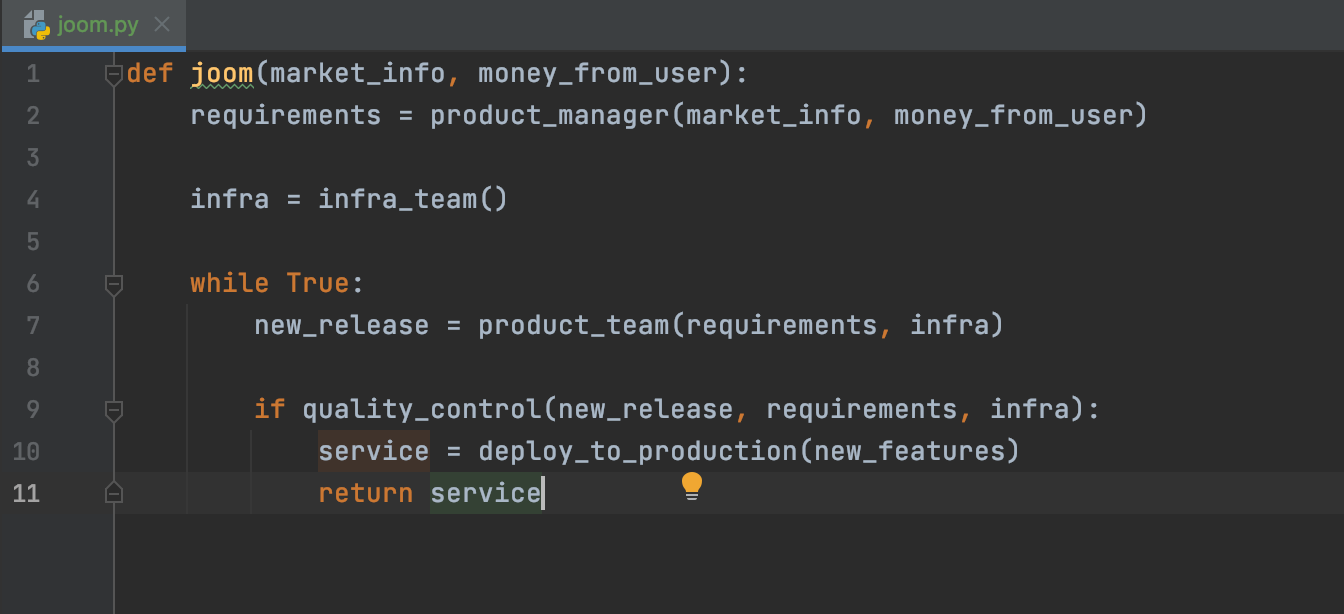
def joom(market_info, money_from_user):
requirements = product_manager(market_info, money_from_user)
infra = infra_team()
while True:
new_release = product_team(requirements, infra)
if quality_control(new_release, requirements, infra):
service = deploy_to_production(new_features)
return serviceПриведенный выше пример весьма упрощенный. Этот код однопоточный, а реальная организация — это многопоточная асинхронная деятельность.
Удаляем «мертвый код»
Это самый низко висящий фрукт. Если какие-то вычисления не влияют на результат функции, то этот код надо просто удалить.
Бывает, что код непосредственно не влияет на результат работы функции, но его нельзя удалить по каким-то другим соображениям. Такой код должен потреблять минимум ресурсов.
Взгляните на этот пример
def product_team(requirements, infra):
long_useless_meeting() # what is that for? Let's remove it.
implementation_plan = plan(requirements, infra)
log.debug(implementation_plan) # if logging is fast enough, we can leave it here
return code(implementation_plan, requirements, infra)
Если некоторая деятельность в организации не приводит к профиту пользователя — прекратите это делать.
Если вы разработчик, то все, что вы делаете должно быть ориентировано на создание нужных фич для пользователей и поддержание работоспособным того, что уже сделано.
Если что-то нельзя не делать, то тратьте на это минимум ресурсов.
Реализуем только полезную функциональность
Посмотрим на организацию как функцию еще раз.
def joom(market_info, money_from_user):
# something
return service
Цель этой функции — возвращать такой сервис, который приносит доход. Если это не так, то результат ее работы можно расценивать как ошибку. Если бы мы написали тесты для этой функции то в них было бы примерно следующее:
def test():
service = joom(some_marketing_info, previous_money_from_user)
assert makes_money(service)
Представьте себе, что функция joom оказалась с багами и периодически она по непонятным причинам выдает некорректные значения. Если мы не можем исправить ошибку, то придется делать retry вот так:
def profitable_joom(market_info, money_from_user):
while True:
service = joom(market_info, money_from_user)
if makes_money(service)
return service
Теперь тест будет проходить, но цикл while будет тратить много ресурсов при условии, что функция joom часто возвращает не то, что нужно.
Идеально было бы полностью устранить возможности вывода неправильного результата у функции joom. Но если это в принципе невозможно? Все равно есть способ оптимизировать. Взгляните на функцию еще раз. Чем раньше мы поймем, что сервис не будет приносить профита, тем больше ресурсов мы сэкономим.
def joom(market_info, money_from_user):
requirements = product_manager(market_info, money_from_user)
assert makes_money(requirements) # fail-fast if cannot make money
infra = infra_team()
while True:
new_release = product_team(requirements, infra)
assert makes_money(new_release) # fail-fast if cannot make money
if quality_control(new_release, requirements, infra):
service = deploy_to_production(new_features)
assert makes_money(service) # fail-fast if cannot make money
return service
Мы добавили assert для промежуточных результатов. Теперь в случае ошибки мы можем сделать retry раньше и избежать потерь ресурсов.
Вопрос для размышления читателю. А что если сама функция makes_money подвержена ошибкам?
Можно потратить человеко-месяц на функциональность, которая не приносит пользы. По сути это то же самое, что и ошибка на примере кода выше.
Вот возможные причины, почему организация сделала то, что не приносит профит.
Сама идея не принесет профит, даже если будет правильно реализована.
Реализовали не то, что хотели — потери в коммуникации.
Реализовали то, что хотели, но оно не работает из-за потерь качества.
Конечно, лучшее решение — избегать ошибок. Потери в коммуникации и качестве еще как-то можно устранить, но потери на этапе идеи — вряд ли.
Выбрать среди всех идей ту, что действительно принесет профит — сложная и важная задача, особенно в текущем быстро меняющемся мире. К тому же это самая первая работа в цепочке формирования ценностей.
Любой метод выбора правильных идей требует ресурсов и может давать ложные результаты.
Если проверка идеи ложно говорит, что идея хорошая, то вы напрасно реализуете функциональность — ресурсы будут потрачены впустую.
А если проверка идеи ложно говорит, что она плохая, то вы не будете делать перспективные идеи. Если вы проверили идею и отвергли ее, то ресурсы, потраченные на проверку, не были скомпенсированы доходом. Это прямые потери. Довод «зато мы не потратили еще больше ресурсов на реализацию бессмысленной идеи» не работает: потери есть потери. Команда, которая тратит все свое время на отбрасывание идей — это «мертвый код», так как ее работа не влияет на результаты. Такой команде стоит задуматься о смысле своего существования. В нашей аналогии с исходным кодом это такая функция, которая постоянно проваливает assert makes_money.
Для продуктивной разработки нужен надежный дешевый метод проверки идей. Прогнозы и экспертные оценки на практике работают плохо. Лучше всего проверять идеи прямо на реальных пользователях, но тратя на это мало ресурсов. Такой подход называется MVP (minimum viable product). Для проверки идеи создается дешевая реализация, но которая все-таки реально работает. По реакции пользователей на MVP принимается решение, стоит ли делать хорошую, но дорогую реализацию. Если идея не проходит проверку, то код ее реализации доводится до абсолютного совершенства — его удаляют.
Порой MVP называют не отдельную функциональность, а продукт целиком, и на его реализацию выделяют месяцы работы. Но можно делать MVP функциональности. Это занимает буквально часы.
MVP, конечно, часто не удобны для пользователей и существует риск, что невостребованность функциональности является следствием неудобства. Это требует анализа компромиссов.
Обратите внимание! MVP позволяет не только быстро проверить саму идею, но и обнаружить потери коммуникации и качества. Возвращаясь к аналогии с исходным кодом, можно даже записать так:
def profitable_joom(market_info, money_from_user):
while True:
mvp_service = joom_prototyping(market_info, money_from_user)
if makes_money(mvp_service):
service = joom(market_info, money_from_user)
if makes_money(service)
return service
Это классический метод оптимизации. Например, он широкого распространен в форме double check locking.
Минимизируем бюрократию
В области программирования существует класс алгоритмов, когда сначала составляется план действий, а потом этот план выполняется.
Например, это типично для баз данных и систем анализа данных. Сначала строится план выполнения запроса. Если планирование запроса тратит меньше ресурсов, чем прирост производительности в выполнении запроса — это отличная оптимизация.
Возвращаясь к нашей функции-организации, посмотрим на функцию работы продуктовой команды.
def product_team(requirements, infra):
implementation_plan = plan(requirements, infra)
return code(implementation_plan, infra)
В организации работы инженеров также есть класс подобных вспомогательных действий, которые требуют усилий, но приводят к росту эффективности работы и в итоге окупают вложенные усилия.
SCRUM, KanBan, planning poker, недельные отчеты, квартальное планирование, peer review и т.п. — все это инструменты повышения продуктивности. Я собирательно назвал их бюрократией, но не вкладываю в это понятие негативную оценку.
Бюрократия позволяет и сокращать расходы ресурсов, и увеличивать выработку полезной функциональности. Например:
устраняет потери ресурсов из-за недостатка коммуникации,
устраняет потери из-за вытеснения одних задач другими,
мотивирует сотрудников к профессиональному росту,
улучшает фокусировку на том, что принесет максимальную пользу,
создает ритм работы с регулярными промежуточными результатами.
Это все очень здорово, но когда инженер занимается бюрократией, он не создает непосредственную пользу, поэтому бюрократия должна занимать минимум времени, но тем не менее продолжать выполнять свою позитивную роль.
Чтобы выработать оптимальный уровень бюрократии, критически важно, чтобы инженеры понимали свою роль в организации и были правильно мотивированы. Менеджер, не погруженный в технические аспекты создания ценности инженерами, не может определить оптимальный уровень бюрократии и скорее завышает его. Роль руководителя в данном вопросе — донести, как инженеры приносят прибыль организации, а также мотивировать делать это. Обратите внимание — не мотивировать заниматься бюрократией, а мотивировать приносить прибыль. Бюрократия — это инструмент, а не цель.
Бывает, что команда инженеров привыкла пользоваться одним процессом и сопротивляется внедрению другого, даже если бы он поднял их эффективность. Эта проблема пропадает сама собой, если инженеры мотивированы увеличивать прибыль и знают, как измерить свой вклад.
Я работаю в команде Joom Ads, и мы отвечаем за рекламу в маркетплейсе. Когда мы начинали работать над проектом, мы намеренно не делали никакого процесса (AdHoc), но затем, по мере роста команды и сложности разработки, мы стали обращать внимание на потери и адаптировали свои процессы. Сейчас наш процесс эволюционировал в KanBan с continuous delivery, практически все рутинные процессы автоматизированы.
Вопрос для размышления читателю. Чтение этих строк приносит пользу?
Используем эффективные алгоритмы
При написании кода важно использовать эффективные алгоритмы. Лучше использовать алгоритм со сложностью O (NLogN) вместо O (N2). Но если вдруг N небольшое, то никакой практической разницы между этими двумя алгоритмами может не быть, можно воспользоваться алгоритмом со сложностью O (N2), к тому же такие алгоритмы, как правило, проще. Проблемы с таким решением начнутся, если N начнет расти.
С организацией происходит то же самое. Если мы делаем что-то маленькое с небольшим сроком жизни, то и быстрые решения будут отлично работать. Но когда начнется рост, появятся проблемы.
Например:
def product_team(requirements, infra):
for implemented in already_implemented:
if implemented == requirements:
return None
implementation_plan = plan(requirements, infra)
release = code(implementation_plan, requirements, infra)
already_implemented.append(requirements)
return release
Отличная оптимизация — не делать то, что уже сделано. Но только до поры, пока количество реализованных требований не станет очень большим.
Самая частая причина, почему команда теряет производительность по мере роста проекта — это технический долг.
Управляем техническим долгом
Если разработчики будут реализовывать функциональность, не соблюдая ограничений архитектуры, не делая тестов или документации, а новые требования все будут поступать, продуктивность команды будет падать. В результате создание новых фич будет требовать больших ресурсов, а надежность — падать. Получается рост расходов с почти отсутствием роста доходов. Подобное состояние называют техническим долгом. Его суть в том, что сэкономив ресурсы в прошлом, вы вынуждены вкладывать значительные ресурсы сейчас, чтобы восстановить продуктивность.
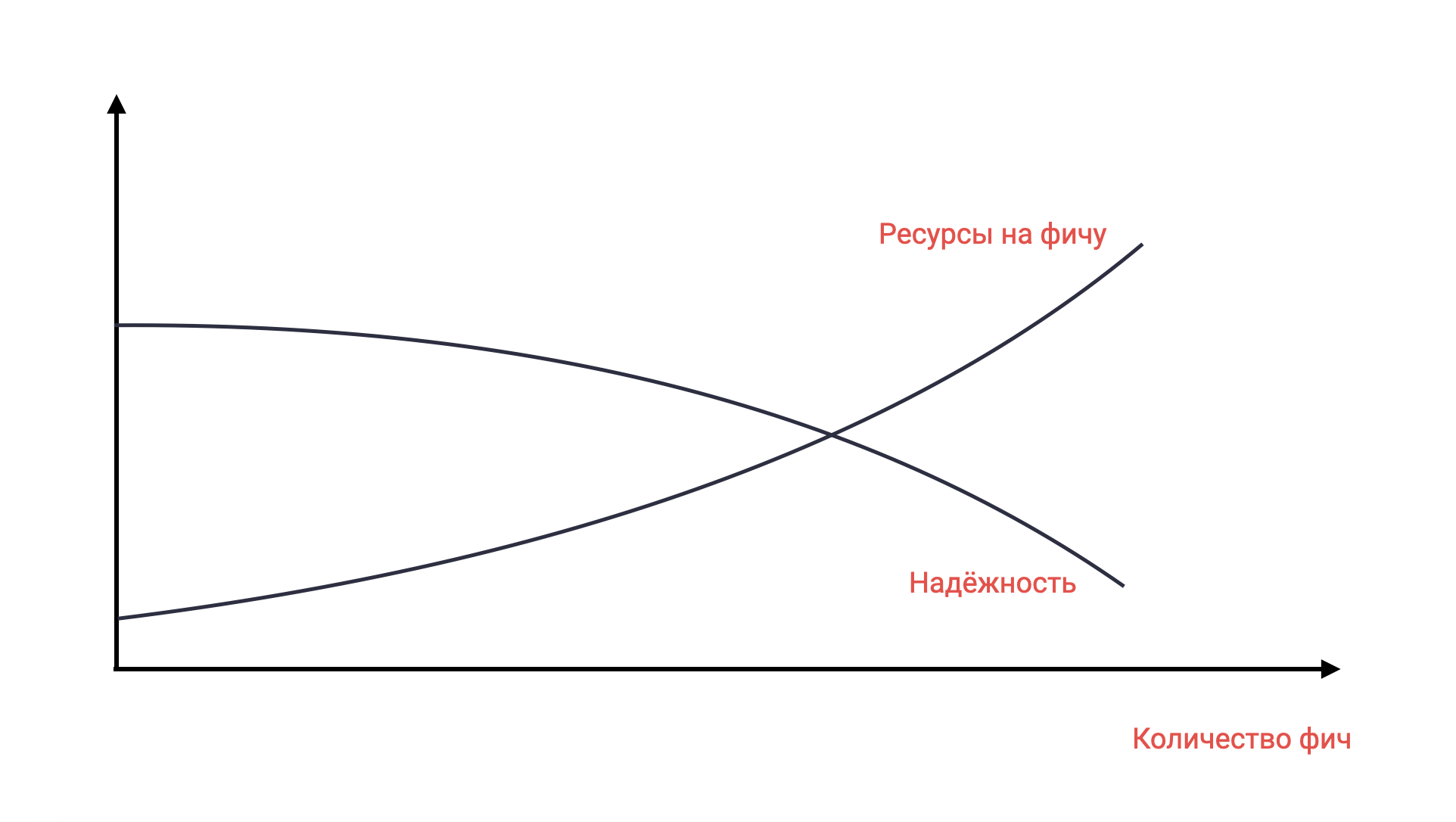
MVP, о котором было написано ранее — это форма осознанного технического долга. Мы можем осознанно пойти на экономию ресурсов сейчас, за счет будущего. Но ведь эта будущая разработка может вообще не понадобиться, так как большинство идей на самом деле не работают. Таким образом технический долг может растить продуктивность. Такой долг — хороший, проценты по нему меньше, чем получаемый профит.

Но вот если мы допускаем технический долг неосознанно, либо не возвращаем его, оставив грязную MVP реализацию, то это скорее всего будет плохим долгом. Проценты по этому долгу превысят профит. Суммарная продуктивность окажется ниже, чем могла бы быть.
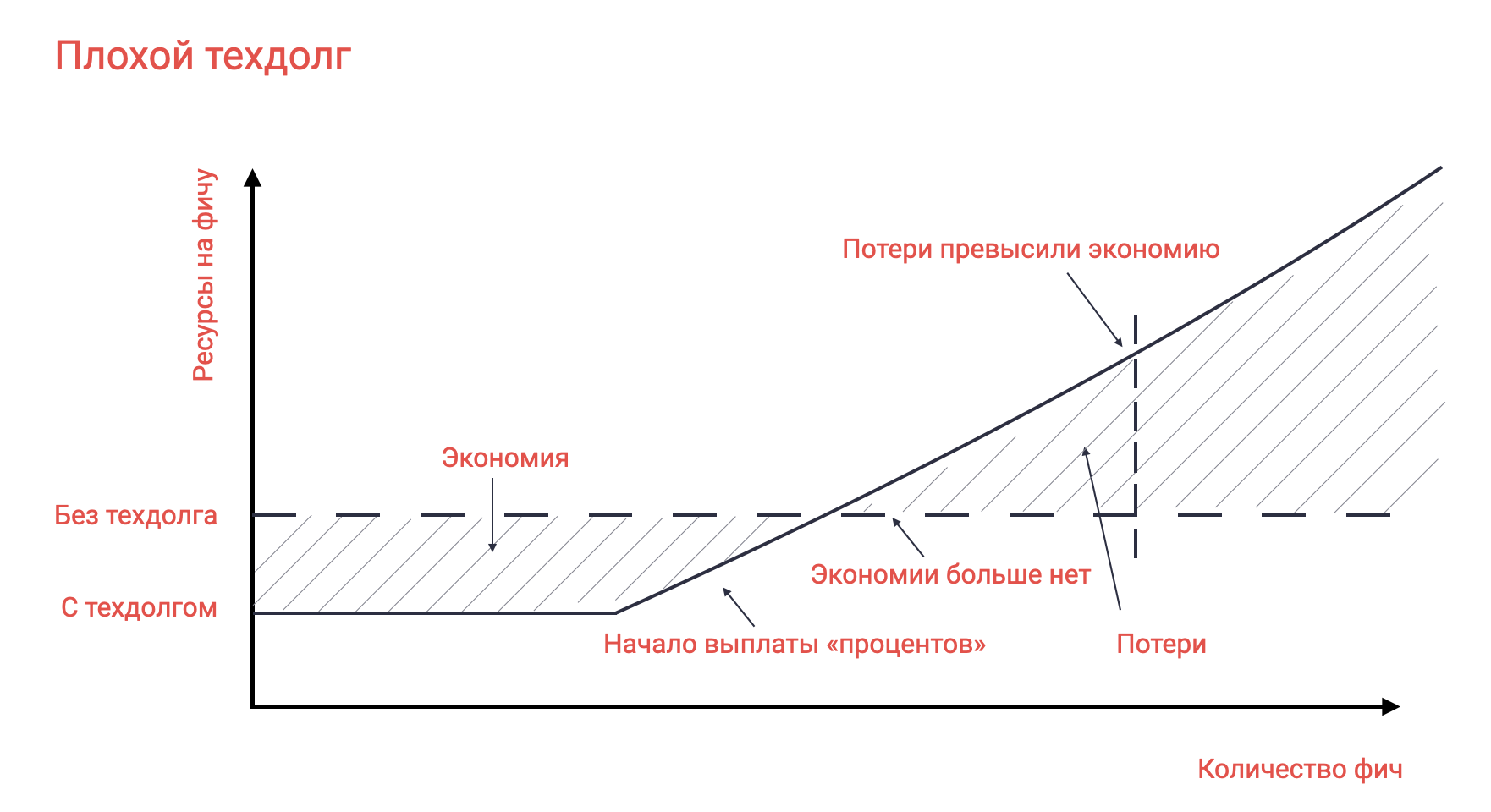
Если команда начинает возвращать большой технический долг, то она, как правило, не может создавать новую функциональность. При этом важно помнить, что доход формируется не только новыми фичами, но и старыми, которые все еще работают. Если команда повысит надежность старой функциональности, это может освободить ресурсы и все-таки привести к небольшому росту продуктивности. Лучше исправлять проблемы надежности, чем тратить ресурсы на поддержку.
Инвестируем в рефакторинг
Исправление технического долга — это техническая инвестиция, так как она не окупается быстро.
Помимо устранения технического долга есть и другие разновидности инвестиций, например, рефакторинг или разработка новой библиотеки / инструмента.
Инвестиции со временем должны окупаться. Команда должна анализировать, какие инвестиции были удачные, а какие нет, и не повторять ошибок. Очень нехорошо с точки зрения продуктивности вложить недели труда в «устранение энтропии», а потом даже не проследить, стало лучше или хуже. Это примерно как сделать спорную оптимизацию в коде и не провести тестирование производительности.
Проверка эффективности инвестиции должна происходить не на основе субъективного мнения разработчика «стало удобнее», а на основе фактических данных о возможностях реализации новой нужной функциональности с использованием меньших ресурсов. К сожалению, нередко бывает так, что рефакторинг делает разработку более трудоемкой за счет внедрения гибкости и слоев абстракции не там, где это надо.
Технические инвестиции сложно оценить заранее. Это такая же проверка идеи, о которой мы говорили раньше в контексте функциональности. Своего рода MVP для рефакторинга тоже возможен — следует избегать изменений впрок, обоснованных только эстетическими соображениями. Если в архитектуре есть неудачный участок, но этот код надежно выполняет свою задачу и новая функциональность там сейчас не требуется — не надо его трогать, потому что вы пока наверняка не знаете, какие именно изменения там будут нужны с точки зрения профита.
В Joom Ads нам приходится проверять множество гипотез — разные варианты размещения рекламы в приложении, приемы персонализации и ранжирования рекламы, интерфейс работы с рекламодателем, настройки аукциона и т.д. Нам удалось создать абстракции, которые позволяют быстро проверять гипотезы. Чтобы поддерживать архитектуру адаптированной к быстрому прототипированию новых идей, мы прибегали к рефакторингу, который порой был весьма трудоемким. Но за год разработки мы заметили, что рефакторинг становится все менее инвазивным, а архитектура стабилизируется, сохраняя гибкость. Это связано с тем, что гибкость нужна не по всей кодовой базе, а только в определенных местах, в которых и происходит большинство изменений. Последовательность рефакторингов уже привела эти точки расширения к достаточной гибкости, чтобы можно было проверять практически любые идеи. Все чаще мы сталкиваемся с ситуацией, что мы можем проверить идею без какой-либо подготовки, просто путем новой реализации уже существующих расширений. Подобный путь рефакторингов стал выгодной инвестицией. Оглядываясь назад, я с уверенностью могу сказать, что прийти к такой архитектуре путем раннего принятия решений фактически невозможно.
Инвестируем в библиотеки и инструменты
А как оценить инвестицию не в рефакторинг, а в некоторый инструмент или библиотеку? Стоит ли взять какой-то open source инструмент или написать своё будет продуктивнее? Ведь со сложным open source придется разбираться, это потребует ресурсов, а написать свой инструмент будет даже быстрее.
Главный вопрос при создании велосипедов —, а что будет дальше?
Пока на написание и поддержку своего инструмента уходит меньше времени, чем на изучение open source, профит точно есть.
Но вот если планируется развивать свое решение и сделать его конкурентом существующему open source, то вам надо будет окупить следующие затраты.
Создание и отладку инструмента. Open source уже прошел этот путь.
Поддержку инструмента своими силами. У open source есть community для этого.
Написание качественной документации. Про open source могут быть написаны книги, как минимум — множество ответов в stackoverflow и т.п.
Изучение своего инструмента коллегами. Вам не пришлось изучать свой инструмент, так как вы его создатель, но коллегам придется изучать ваш инструмент по той документации и с теми ресурсами, которые вы для них подготовите.
Представьте себе, насколько прорывным должно быть ваше решение, чтобы все это окупить. Не продуктивнее ли будет вместо написания своего инструмента разобраться в коде open source и присоединиться к его создателям?
Тем не менее создание собственного решения может быть продуктивным.
Open source инструмент может делать гораздо больше, чем вам понадобится. Тогда ваше решение будет проще и, скорее всего, надежнее. Но важно не забыть, что со временем требования имеют тенденцию к усложнению, а значит, ваш инструмент тоже станет сложнее.
Бывают низкокачественные open source решения. Они постоянно требуют ресурсов на поддержку, и починить их уже почти невозможно вашими силами из-за огромного технического долга в самом решении.
Open source решение могло быть написано давно, и может быть несовместимо с более молодыми технологиями. Тогда за счет более тесной интеграции с другими технологиями вы действительно можете совершить прорыв.
В ходе разработки JoomAds нам не довелось изобретать велосипеды, мы брали существующие инструменты, порой внося изменения в их код и исправляя баги. К сожалению, некоторые решения пришлось менять. Так, мы не смогли добиться достаточной надежности от Apache Ignite и заменили его на сочетание Apache Cassandra, Apache Kafka и Apache Flink. Как ни странно, решение с большим количеством компонентов в итоге оказалось и проще, и надежнее. Подробнее о нем можно прочитать тут.
Заключение
В этой статье мы рассмотрели приемы оптимизации работы команды разработки программного обеспечения. Самый важный принцип заключается в том, что цель команды разработчиков программного обеспечения не просто писать код, а автоматизировать процессы получения прибыли. В следующей статье рассмотрим способы оптимизации межкомандной работы. Делитесь вашим опытом и задавайте вопросы, буду рад дискуссии в комментариях.
