Опыт эксплуатации Mellanox под управлением Switchdev
Мы уже писали про Linux Switchdev в Mellanox — что это такое и как мы с ним живем в Qrator Labs. Сегодня я хочу рассмотреть этот вопрос с другой стороны. Меня зовут Дмитрий Шемонаев, я руковожу центром сетевых операций.
Кроме того, что этот коммутатор можно использовать как Whitebox, он поддерживает и perl-скрипты, с помощью которых мы автоматизировали управление сетевой конфигурацией. Потому что Switchdev и это позволяет делать. Об этом я сегодня и расскажу.
 Источник — www.arista.com
Источник — www.arista.com
Наша компания занимается предоставлением услуг по нейтрализации DDoS атак. То есть на нашу сеть в любой момент может прийти очень большая нагрузка. Поэтому мы используем сетевое оборудование не для фильтрации трафика, а в первую очередь для его форвардинга. За это отвечают три важных сущности:
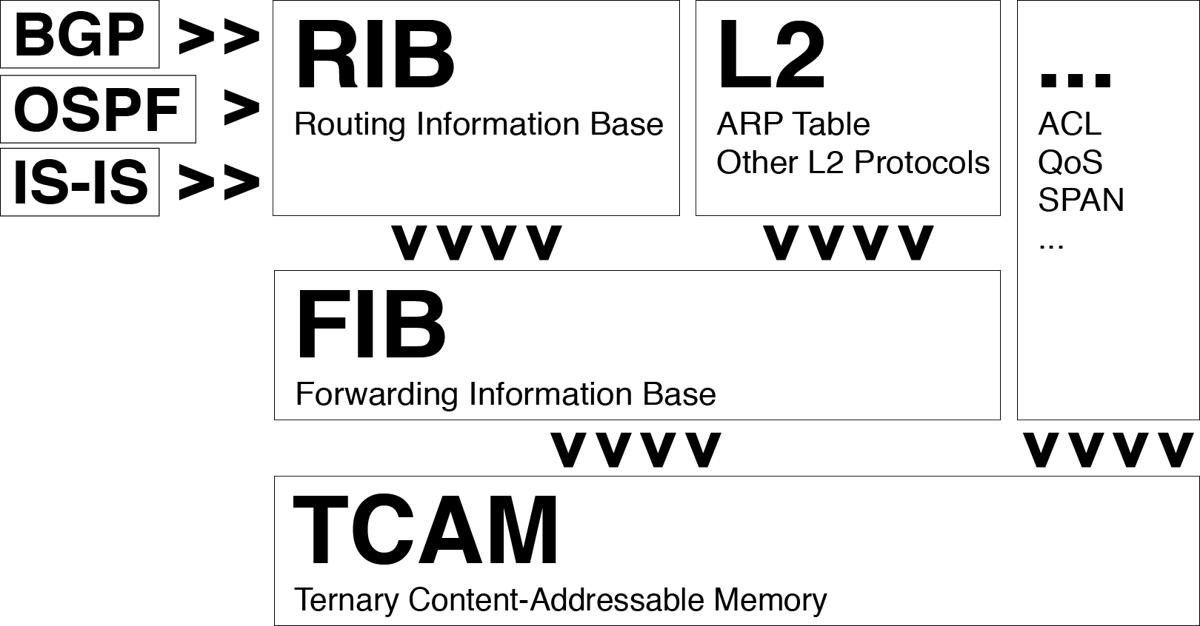
В RIB (Routing Information Base) загружается вся информация от роутинговых протоколов (BGP, OSPF, IS-IS, статика) — все L3 хозяйство копится там. В RIB происходит процесс выбора наилучшего маршрута, то есть, по сути, выбор от nexthop до определенного префикса. Сбоку — все возможные L2 вещи (ARP-таблицы и разные L2 протоколы).
Все это загружается в сущность под названием FIB (Forwarding Information Base) — это некая софтверная абстракция лучших маршрутов и L2 путей до nexthop. Дальше все спускается в TCAM — это, по сути, троичная контекст-адресационная память. Она очень хитрая и очень дорогая.
Плюс TCAM в том, что он может сделать lookup за один проход, и этот проход будет очень быстрым. В сетевом оборудовании у нас нет возможности, например, при обращении к RAM, чтобы наши lookup«ы занимали произвольное количество времени — нет, lookup всегда должен занимать одинаковое и минимальное время. Именно поэтому TCAM такой дорогой.
Чтобы через RIB поместить в FIB полную таблицу маршрутизации интернет, а потом это отправить в TCAM, последние нужны большие TCAM — и стоят они очень дорого. Еще дороже — большие TCAM«ы для высокоскоростных интерфейсов. Именно поэтому коробки-маршрутизаторы, которые могут вмещать в себя большие таблицы, стоят дорого — их чипы дороже за счет TCAM.
Кроме того, большие маршрутизаторы (Big F***ing Routers) умеют резервировать аппаратные компоненты: блок питания, routing engine — мозг коробки, а также вентиляторы, иногда матрицы коммутации. Маршрутизаторы поддерживают очень много роутинговых протоколов, например, OSPF, BGP, IS-IS. И при этом в маршрутизатор можно вставить оптический трансивер, который будет бить на очень большую дистанцию, потому что интерфейс таких коробок выделяет достаточно много электрической мощности на порт.
Но если смотреть на недостатки, то это оборудование очень-очень дорогое (без иронии), а иногда вы к нему должны еще купить и лицензии. Оно достаточно сложное. Чтобы его настроить и отладить, нужно обладать большими компетенциями — в том числе, и по внутренней архитектуре конкретной коробки.
Маршрутизаторы потребляют достаточно много электричества и занимают много места в стойке. Хотя, конечно, теперь есть коробки и на 3 юнита. Их софт недостаточно гибок в том плане, что если вы небольшая компания, то даже если вы попросите у вендора какую-нибудь функциональность, она вам будет предоставлена примерно… никогда.
Поэтому мы для себя выбрали второй вариант — это коммутаторы. Они бывают модульными, в которых всего много: и резервирования, и линейных плат, и потребляемой мощности, и блоков питания. Коммутаторы не такие дорогие и зачастую (но не всегда) потребляют меньше электроэнергии и занимают меньше места в наших телекоммуникационных стойках (первое — зачастую, второе — не всегда). Если говорить об одноюнитовых коробках, то там достаточно большая плотность 100 или 400 Гб портов на один рек-юнит. Например, 32 сотки в одном юните — это нормально.
Предлагаю разделить коммутаторы по двум категориям: Hardware и Software. По аппаратному обеспечению коммутаторы глобально делятся на типы с точки зрения используемых чипов:
Own chips — чипы, которые производят сетевые вендоры, например, Cisco (чип Monticello) или Juniper (чип Paradise, он же Q5).
Commodity chips — чипы, произведенные третьими вендорами. Эти вендоры могут производить сетевые чипы, но не обязательно производят коробки. Например, у той же Arista нет собственного кремния, его для нее производят различные вендоры (Broadcom, Intel, Cavium, Barefoot). Самые известные из них — Broadcom с чипами Tomahawk и Jericho.
А по программному обеспечению деление такое:
Proprietary OS — проприетарные операционные системы, например, Cisco IOS, Juniper Junos, Arista EOS. Это софт, который пишут инженеры, работающие в сетевом вендоре. Он прекрасно совместим с их коробками — не всегда, но зачастую. Конечно, баги бывают и там.
Whitebox-свитчи, на которых вы можете сами выбирать операционную систему из определенного списка. А если вам не подходят текущие протоколы маршрутизации, то можно написать свой вместе с демоном — и интегрировать в коробку.
У свитчей тоже есть минусы. Зачастую у них фиксированная аппаратная конфигурация, и там нет резервирования «мозгов». Вы не сможете инсталлировать полную таблицу маршрутизации интернет в сущность FIB из-за ограничений его TCAM. Полная таблица маршрутизации в интернете сейчас более 850 тысяч префиксов.
Whitebox switches
Whitebox-коммутаторы производят разные компании, например, EdgeCore или Accton, но мы поговорим про Mellanox. Эта израильская компания производит различные InfiniBand и ethernet, и недавно ее купила NVIDIA.
Для коммутаторов Mellanox на чипе Spectrum (собственный чип, разработанный Mellanox) на выбор есть различные ОС. Это может быть MLNX-OS (он же Mellanox Onyx), а также Cumulus — сетевая ОС на базе Linux, которую тоже купила компания NVIDIA. Другие варианты софта — SAI (Switch Abstraction Interface), на базе которого работает ОС SONiC (NOS) от Microsoft и, наконец — switchdev (Linux kernel). О ней мы и поговорим.
Switchdev — это внутриядерная инфраструктура, которая переводит абстракции сетевого стека Linux непосредственно в dataplane коммутатора, то есть в его железо. Это называется offload, и Switchdev умеет offload«ить бриджинг, маршруты и фильтры. Вообще этот проект начали в 2014 году, а Mellanox стал это поддерживать в 2015:

Firmware: in driver (linux ≥ 4.13, fw ≥ 13.1420.122) или tool (mstflint). Initramfs: premature driver load.
Как я уже говорил, это внутриядерная структура, но вам не нужно хитро собирать ядро. Switchdev в том или ином виде есть уже даже в «ванильном» Linux. И тут есть два варианта:
Ветка net-next, куда разработчики коммитят самые свежие изменения — если вы хотите экспериментов и bleeding edge. Но думаю, если вы будете использовать net-next на проде, у вас будет кровоточить не только edge, но и лицо.
Если вы любитель относительно тестированных решений, то, пожалуйста — «ванильное» ядро Linux. Можете поставить на Spectrum любой Linux по умолчанию — Fedora, Arch, Ubuntu, Gentoo или что угодно. Это как раз наш вариант, и ниже я объясню, почему.
Думаю, что все представляют, что такое Cisco CLI (Command Line Interface) или Junos CLI. Конфиг этих сетевых железок — это некий монолит, который разбит на блоки. Там могут быть блоки Access Control List, системные сервисы (SSH, DNS и пр.), конфиги протоколов маршрутизации, конфиги интерфейсов и т.д. Но все это один большой, условно текстовый, файл, в который мы переходим с помощью CLI и что-то в нем меняем. О дальнейшем заботятся уже более низкоуровневые абстракции, а мы работаем с достаточно высокоуровневыми вещами.
Производители дают то, что можно с некоторой натяжкой назвать синтаксическим сахаром, то есть всевозможные автодополнения, группировки интерфейсов. Например, в Junos можно сделать интерфейс-группу и потом ее применять не только для агрегации, но и повесить на интерфейс-группу одинаковые Access Control List, сделать какой-то description и т.д.
В Linux — всё немного не так (мы говорим про голый Linux). В системе есть большое количество разных конфигурационных файлов, которые могут лежать в разных местах, а так же мы имеем некоторое количество рантайма. Мы должны помнить, где это лежит, как это менять, и самое важное — мы должны помнить, в каком порядке это менять, чтобы наш edge не был bleeding.
Вместо синтаксического сахара (моя любимая картинка, всегда смеюсь) у нас sed, awk, grep, и пр. Pwd, конечно, нет — в общем, ничего не изменилось.

Linux toolkit
В сетевой стек в первую очередь offload«ится iproute2 с его командами: ip, bridge, devlink и tc (Traffic Control)). Чтобы смотреть за состоянием трансиверов и ethernet-интерфейсов, используется ethtool. А чтобы соседние устройства могли друг друга видеть, им на помощь приходит открытый опенсорсный протокол LLDP (Link Layer Discovery Protocol). Это аналог CDP (Cisco Discovery Protocol), который давным-давно уже служит для этих целей. Также через lldpad можно передавать параметры QoS через стандарт DCB (Data Center Bridging). Ну и sysctl для маленьких штук — hash policy, qos prio update.
Перейдем к технологиям, которые мы используем в Linux для Whitebox-коммутаторов:

LACP example
Агрегация портов используется, если мы хотим подключить сетевое устройство не одним интерфейсом, а двумя. Например, нам десятки мало, сороковки — много, а сетевая карта у нас с двумя 10 Gb интерфейсами. Тогда мы эти два интерфейса в коммутаторе объединяем в агрегацию канала.
В Juniper это делается примерно так:
set interfaces ae0 unit 0 family ethernet-switching
set interfaces xe-0/0/[1,2] ether-options 802.3ad ae0Объявляется группа агрегации и говорится, что это ethernet-свитчинг, дальше добавляем два интерфейса и показываем, что это ae0. В Cisco примерно так же:
interface range TenGigabitEthernet1/0/1-2
channel-protocol lacp
channel-group 1 mode activeВ Linux это делается тоже достаточно просто — определяется bond и, как мастер, он выбирается для двух интерфейсов:
ip link add bond0 type bond mode 802.3ad
ip link set enp1s0np1 master bond0
ip link set enp1s0np2 master bond0Vlan example
Думаю, все знают, что такое vlan. Для Cisco это будет выглядеть так:
c-switch(config)# vlan 20
c-switch(config)# name highload2021
c-switch(config)# interface TenGigabitEthernet1/0/1
c-switch(config-if)# switchport mode trunk
c-switch(config-if)# switchport trunk encapsulation dot1q
c-switch(config-if)# switchport trunk allowed vlan add 20Для Juniper:
j-switch# set vlans highload2021 vlan-id 20
j-switch# set interfaces ge-0/0/1 unit 0 family ethernet-switching port-mode trunk vlan members highload2021И для Linux:
ip link add link enp1s0np1 name port1vlan20 type vlan id 20
ip link add brvlan20 type bridge
ip link set port1vlan20 master brvlan20Linux VRF example
VRF — это по сути некоторый виртуальный маршрутизатор. То есть мы берем наш большой маршрутизатор или коммутатор — то есть некую большую сущность — и нарезаем на маленькие. Например, мы хотим, чтобы для каждой таблицы маршрутизации были свои маршруты по умолчанию (default route). Для этого и используется нарезка в виртуальном маршрутизаторе.
Есть два способа это сделать в Linux: через сетевые namespace netns и с помощью VRF. В Mellanox лучше использовать VRF, просто потому что они offload«ятся в чип. Для этого создаем специальное правило и сам VRF, где указываем его имя, что это тип VRF, и номер таблицы. Потом линкуем интерфейс к VRF и, например, если нам нужно сделать route из VRF в другое место, делаем как здесь:

Из таблицы 100 делаем маршрут до префикса 113.0 через vlan20, который в таблице 200.
ECMP (Equal Cost Multi-Path)
Если у нас в таблице маршрутизации есть маршруты с одинаковым весом до одного префикса, но с разными nexthop, то железу нужно понимать, в какой интерфейс отправлять трафик. Для этого используется хэширование, которое может быть реализовано по различным полям в IP пакете, например:
src ip, dst ip;
src ip, src port, dst ip, dst port;
src ip, src port, dst ip, dst port, proto.
Сюда можно добавить больше вариаций хэша для одной и той же условно пары — src ip и dst ip — потому что чем больше полей для хэширования, тем лучше. Исходя из этого хэша уже выбирается тот или иной nexthop, что позволяет балансировать трафик по нескольким линкам.
Configuration
В классических сетевых ОС конфигурация происходит так: мы идем в нужный нам блок, что-то меняем, дальше всё делает железо. В Linux мы должны идти по другому пути: port → bond → bridge → vlan, loopback → vrf → ip. Если мы хотим что-то поменять, нам нужно в правильном порядке это разобрать, поменять, и потом в правильном порядке собрать.
Если нарушить порядок, то получим bleeding edge — что, понятно, не очень хорошо, особенно на проде. Поэтому у нас есть некоторые ограничения, чтобы не получить «благодарность» от коллег.
Старые сетевые инженеры помнят, что в Cisco есть замечательная команда write или copy running-config startup-config, после применения которой все рантаймовские изменения записываются и при перезагрузке свитч стартует с нужной конфигурацией.
У Linux нет команды, которая скажет, что этот рантайм мы полностью копируем — либо вы сами руками трогаете эти конфиги, либо как-то еще изворачиваетесь. Например, можно сделать большой скрипт для инициализации, и, если его постоянно править (это нормально), то это работает.
Есть только одна проблема — этот скрипт инициализируется при рестарте системы, а рестартовать систему при каждом изменении мы не можем. Соответственно, нам нужно это дело как-то синхронизировать — что, мягко говоря, очень неудобно и превращает изменения рантайма в боль. Одно неверное движение — и вся наша фабрика может развалиться.
Чтобы жизнь не была настолько болезненной, наш коллега написал два perl-скрипта. Первая утилита — mlxrtr — конфигурит маршрутизацию и интерфейсы. Пример конфигурационного файла для mlxrtr:

Мы берем некий port 1 и разбиваем его на 4 субпорта — чтобы, например, из 100 Гб интерфейса получить 4 интерфейса по 25 Гб. Потом делаем два bond из этих 4 интерфейсов, делаем vlan 10, добавляем их в vrf, прописываем ip-адреса и т.д., заканчивая роутингом. Внутри Linux этот скрипт преобразует конфиг:
Config example
sysctl -w …
ip rule del pref 0
ip rule add pref 30000 table local
devlink port split pci/0000:01:00.0/25 count 4
tc qdisc add dev enp1s0np1s0 ingress_block 100 ingress
…
ip link add name bond_srv1 type bond lacp_rate fast min_links 1 \
mode 802.3ad xmit_hash_policy layer3+4
ip link set dev bond_srv1 down
…
ip link add name loop10 type dummy
ip link set dev loop10 down
ip link add name switch type bridge vlan_filtering 1
ip link set dev switch down
ip link add name vrf-ext type vrf table 100
ip link set dev vrf-ext down
ip link add name vrf-int type vrf table 200
ip link set dev vrf-int down
ip link set dev enp1s0np1s0 down
ip link set dev enp1s0np1s0 master bond_srv1
ip link set dev enp1s0np1s0 down
…
ip link set dev enp1s0np2 master switch
ip link set dev enp1s0np2 down
ip link set dev bond_srv1 master switch
ip link set dev bond_srv1 down
…
ip link set dev loop10 master vrf-ext
ip link set dev loop10 down
ip link add link switch name vlan10 type vlan id 10
ip link set dev vlan10 down
…
ip link set dev vlan10 master vrf-ext
ip link set dev vlan10 down
ip link set dev vlan20 master vrf-int
ip link set dev vlan20 down
bridge vlan del vid 1 dev bond_srv1
bridge vlan add vid 20 dev bond_srv1
…
bridge vlan add vid 10 dev enp1s0np2 pvid untagged
bridge vlan add vid 10 dev switch self
bridge vlan add vid 20 dev switch self
ip link set dev enp1s0np1s0 up
…
ip link set dev bond_srv1 up
ip link set dev bond_srv2 up
ip link set dev loop10 up
ip link set dev switch up
ip link set dev vlan10 up
ip link set dev vlan20 up
ip link set dev vrf-ext up
ip link set dev vrf-int up
ip -4 address add 192.0.2.1/32 dev loop10
ip -4 address add 192.0.2.2/31 dev vlan10
ip -4 address add 198.51.100.1/24 dev vlan20
ip -4 route replace 0.0.0.0/0 metric 0 table 100 proto static \
nexthop via 198.51.100.2 dev vlan20 weight 1
ip -4 route replace blackhole 0.0.0.0/0 metric 4278198272 \
table 100 proto static
ip -4 route replace 0.0.0.0/0 metric 0 table 200 proto static \
nexthop via 192.0.2.3 dev vlan10 weight 1
ip -4 route replace blackhole 0.0.0.0/0 metric 4278198272 \
table 200 proto static
ip -4 route replace 203.0.113.0/24 metric 0 table 200 \
proto static nexthop via 198.51.100.2 dev vlan20 weight 1Так выглядят изменения, если мы переносим порт из одного bond в другой:
changes
ip link set dev enp1s0np1s2 down
ip link set dev enp1s0np1s2 nomaster
ip link set dev bond_srv1 down
ip link set dev bond_srv1 nomaster
ip link set dev enp1s0np1s2 master bond_srv1
ip link set dev enp1s0np1s2 down
ip link set dev bond_srv1 master switch
ip link set dev bond_srv1 down
bridge vlan del vid 1 dev bond_srv1
bridge vlan add vid 20 dev bond_srv1
ip link set dev enp1s0np1s2 up
ip link set dev bond_srv1 upЧтобы сделать простое действие, которое в условном Juniper или Cisco делается за 1–2 команды, нам нужно сделать это именно в этой последовательности, потому что по-другому это не заработает.
ACL (Access Control List)
Чтобы в Linux реализовывать Access Control List, можно использовать две подсистемы: TC (Traffic Control) и iptables. В случае со switchdev с помощью iptables можно лишь прикрыть control plane, так как iptables не offload«ится в железо.
Причем TC не смотрит на то, к чему применен этот конфиг. Он применяется к интерфейсам и не важно, маршрутизируется он или коммутируется — он просто смотрит в пакет и дальше работает.
tc qdisc add dev enp1s0np1s0 ingress_block 100 ingressУ нас есть один большой ACL, который вешается на все интерфейсы коробки. Внутри него с помощью опции goto из ТС можно сделать условную нечеткую логику. А также — размашистые Access Control листы, которые, например, нельзя сделать в Cisco. ACL в Traffic Control выглядит как-то так:
ACL
[vlan10]
ip_proto a dst_ip 192.0.2.2 action pass
src_ip 203.0.113.0/24 action drop
dst_ip 203.0.113.0/24 action goto [ex1]
dst_ip 203.0.113.0/24 action drop
action pass
[ex1]
ip_proto icmp action pass
ip_proto tcp action pass
action dropЗдесь на конфиге видно, что если у нас происходит матч по dst_ip из префикса 203.0.113.0/24, то мы делаем action, переходим в блок ex1, пропускаем icmp и tcp, остальное дропаем и дальше идем. И, например, чтобы удалить четвертую строку, изменения будут выглядеть так:
config
tc filter add block 100 …
… protocol ip chain 101 pref 1 flower ip_proto icmp action pass
… protocol ip chain 101 pref 2 flower ip_proto tcp action pass
… protocol ip chain 101 pref 3 flower action drop
… protocol ip chain 100 pref 1 flower ip_proto icmp dst_ip 192.0.2.2 action pass
… protocol ip chain 100 pref 2 flower src_ip 203.0.113.0/24 action drop
… protocol ip chain 100 pref 3 flower dst_ip 203.0.113.0/24 action goto chain 101
… protocol ip chain 100 pref 4 flower dst_ip 203.0.113.0/24 action drop
… protocol ip chain 100 pref 5 flower action pass
… protocol 802.1q chain 0 pref 1 flower vlan_id 10 action goto chain 100
… protocol 802.1q chain 0 pref 2 flower action pass
tc filter add block 100 \
protocol ip chain 102 pref 1 flower src_ip 203.0.113.0/24 action drop
tc filter add block 100 \
protocol ip chain 102 pref 2 flower dst_ip 203.0.113.0/24 action goto chain 100
tc filter add block 100 \
protocol ip chain 102 pref 3 flower dst_ip 203.0.113.0/24 action drop
tc filter add block 100 \
protocol ip chain 102 pref 4 flower action pass
tc filter add block 100 \
protocol 802.1q chain 0 pref 3 flower vlan_id 10 action goto chain 102
tc filter add block 100 \
protocol 802.1q chain 0 pref 4 flower action pass
tc filter del block 100 chain 0 pref 1
tc filter del block 100 chain 0 pref 2
Чтобы не делать это всё руками, мы два скрипта (mlxrtr и mlxacl) выложили на наш GitLab под лицензией MIT. Они требуют только Perl, все остальное уже есть. Используйте на свой страх и риск. Мы не даем никаких гарантий, но у нас это работает. Это не значит, что у нас какая-то лучшая версия — нет, у нас такая же версия, просто мы умеем ее готовить. Но иногда можно погореть.
Остались еще некоторые фишки, о которых хочется сказать.
Serial console tips
● ESC, R, ESC, r, ESC, R. Например, если Linux падает в панику, ему можно послать «Ctrl-Alt-Del», чтобы он перезагрузился. Проблема в том, что мы не можем послать «Ctrl-Alt-Del» коммутатору, у нас с ним есть только серийный интерфейс RS232. Но ему можно сказать: «ESC, R, ESC, r, ESC, R» — это будет равносильно «Ctrl-Alt-Del», и коммутатор сделает всё как надо.
● SysRq: use «break». Чтобы использовать SysRq, обычно мы передаем «Print Screen». Но здесь это сделать тоже невозможно, поэтому выручит команда «break»: для minicom «Ctrl+a, Ctrl+f» и для screen: «Ctrl+a, Ctrl+b»
● BIOS: «Ctrl+b» — чтобы войти в BIOS коммутатора (в серийную консоль) при загрузке.
Summary
Подведем итоги, что нужно помнить и держать в голове, если вы хотите использовать это всё:
Свитчи — это только свитчи. Не надо думать, что их достаточно для всего — нет, у них есть свой собственный спектр применения. Но если вы понимаете, как это применяется, то можете немного эту систему обмануть, хотя лучше трижды подумать, потому что иногда это может обмануть вас.
У свитчей очень слабый CPU, как я уже говорил. Поэтому всё, что можно offload«ить, лучше offload«ить.
Linux может не поддерживать некоторые фичи. Если мы используем коммутаторы и некоторый опенсорс, например, Switchdev, то нужно постоянно «держать руку на пульсе». Во-первых, смотреть, что умеет коммутатор и что умеет Switchdev. Во-вторых, чтобы они умели это делать совместно. И в третьих, желательно offload«ить, потому что это конструктор, который мы собираем сами. Это не вендорский свитч, в котором есть вендорская ОС, и вендор говорит, что это там будет работать. Здесь нет никаких гарантий. Linux может не поддерживать, например, MCLAG или другие фичи, которые вы хотите использовать. Об этом тоже лучше прочитать заранее.
Еще раз — помните о FIB. Если вы загрузите в FIB больше, чем он сможет «прожевать», то это попадет в TCAM. Ничем хорошим это не кончится, коммутатор придется перезагружать.
Сохраняйте свой рантайм куда-нибудь, например, с помощью наших скриптов. Или просто делайте конфиги на основе наших скриптов и применяйте их через скрипты. Тогда у вас будет хотя бы какой-то startup-config. Потому что, если вы будете менять рантайм рантаймом, вы можете про это забыть и при перезагрузке могут возникнуть не очень приятные открытия.
Если у вас нет опыта с Linux, не повторяйте это дома. Если у вас мало опыта с сетями, то тоже лучше дома это не повторять.
Конференция Highload++ Foundation пройдет 13 и 14 мая в Москве, в Крокус-Экспо. Описание докладов и раcписание уже готовы. Билеты можно купить на сайте.
В программу также добавили актуальные на сегодня темы: от импортозамещения, новой инфраструктурной парадигмы и переезда обратно из облаков — до построения карты рисков, перестройки офисной инфраструктуры и безопасности с резким ростом нагрузки в условиях рисков по железу. Подробнее смотрите на сайте конференции.
