Оптимизация вставки в R-дереве в рамках Unity проекта

Привет, Хабр! В этой статье хочу поделиться небольшой историей оптимизации вставки данных в R-дереве в рамках проекта на Unity. В статье не будет кода, но будут сравнения результатов поэтапного процесса оптимизации вышеупомянутого алгоритма.
* * *
Немного предыстории. Некоторое продолжительное время назад я задался целью реализовать несложный геймплей игры уровня «танчики», который бы поддерживал мультиплеерный режим по сети на удаленных устройствах. Примером для копирования я выбрал многим известную игру из 90хдля MS-DOS Dyna Blaster, или более известную как Bomberman.
Выбор пал на бомбермена из-за незатейливого, но в то же время затягивающего геймплея. Кроме этого, в оригинальной игре присутствует локальный мультиплеер на пятерых игроков, в связи с чем идея встроить в неё мультиплеерный режим по сети кажется вполне естественной. Ну, и ещё одной немаловажной причиной лично для меня является то, что эта самая первая игра, через которую я познакомился с миром гейминга на PC.
В силу специфики основной цели проекта, из которой вытекает требование к детерминированности геймплея и, как результат, невозможность использования встроенного в Unity физического движка, следовала необходимость реализации некоторого упрощенного варианта физического движка, а именно цепочки обнаружения и разрешения столкновений — collision detection + collision resolver.
Первым приходящим на ум решением, и возможно вполне достаточным для такого рода геймплея, является структура данных Spatial Hash в виде двумерной таблицы, размерами равному количеству ячеек по ширине и высоте игрового поля. Каждая ячейка такой таблицы содержит в себе коллекцию сущностей/объектов, которые в ней находятся на данный момент симуляции мира. Но мне захотелось обобщить решение для объектов произвольных размеров и получить опыт в реализации и в использовании более сложных структур данных. По этой причине и ряду других мой выбор остановился именно на R-дереве.
R-дерево представляет собой ускоряющую древовидную структуру данных для хранения и доступа в некотором многомерном пространстве. Простейший пример подобной структуры это интерактивные географические карты.

Выше отображено R-дерево высотой в две единицы, заполненное объектами в двумерном пространстве. Каждый из этих объектов позиционирован в пространстве посредством ограничивающего объема AABB конкретного объекта. Черным цветом обозначены корневые вершины дерева, синим внутренние дочерние и красным листовые. Именно листовые вершины содержат сами объекты. Поиск в подобной структуре оценивается как O (logMn) и O (n), в лучшем и худшем случаях, соответственно, где M — является свойством дерева и обозначает максимальное количество дочерних вершин у любой вершины. Кроме максимального количества дочерних вершин, R-дерево имеет ограничение и по минимальному количеству дочерних вершин для каждой родительской вершины и обозначается как m. Корневые вершины являются исключением и ограничены отдельным значением, обычно должны содержать в себе как минимум две дочерние вершины, или не имеют подобного ограничения вообще. R-дерево, в том числе, применяется и в играх, например, для организации доступа к ограничивающим объемам игровых сущностей таких как герой, мобы, предметы и т. п.
Основной целью большинства реализаций R-дерева отличных от оригинальной реализации Гуттмана, автора R-дерева, заключается в уменьшении или в устранении перекрытий вершин дерева между собой, что в свою очередь повышает затраты по времени построения дерева и/или увеличивает затраты по памяти. Принимая во внимание то, что объекты игрового поля в основе своей составляют упорядоченные по сетке поля блоки, именно реализация Гуттмана кажется достаточной для представления взаимного расположения объектов внутри игрового мира.
Алгоритм вставки Гуттмана в R-дерево описан довольно подробно в различных источниках, но в рамках этой статьи достаточно и поверхностного понимания алгоритма:
при вставке очередного элемента, рекурсивно, по всей глубине дерева происходит взаимная оценка внутренних вершин и определяется конечная листовая вершина, в которую должна произойти вставка;
оценка и выбор вершины определяется специфической для каждой реализации R-дерева логикой, но так или иначе выбирается та вершина, при вставке в которую будет минимальное увеличение ограничивающего объема оцениваемой вершины по сравнению с другими, соседними, вершинами;
при вставке в полностью заполненную вершину (EntriesCount === M) происходит разделение вершины и увеличение высоты дерева.
Результат работы первого варианта реализации алгоритма выглядит в редакторе следующим образом:
Полученный результат меня вполне устраивал ровно до тех пор, пока я не прогнал под профайлером работу алгоритма вставки в рамках кадра.
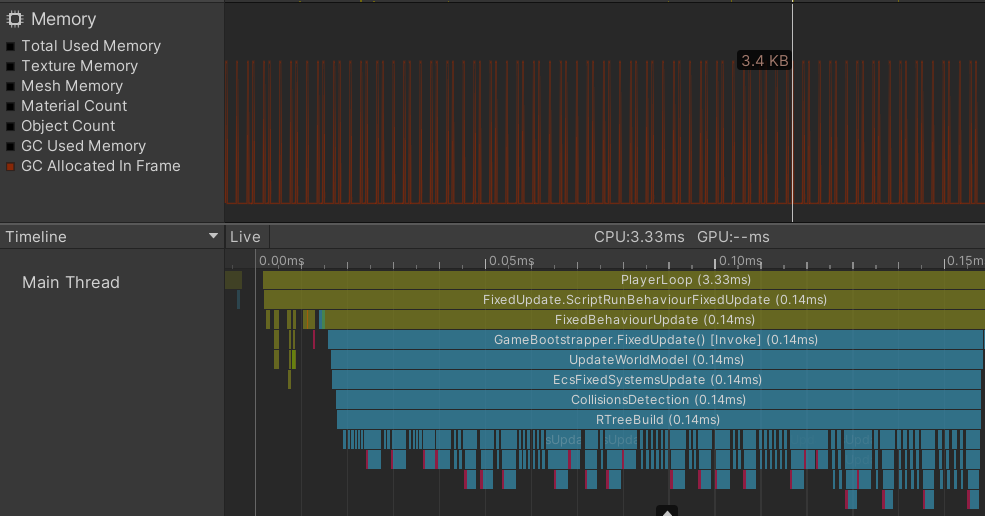
Результат профилирования вставки в дерево полторы сотни игровых сущностей
Время вставки в дерево хоть и сравнительно небольшое по времени, но сразу бросается в глаза огромные скачки по выделению и освобождению памяти в куче. Очевидно, это плохо, и не только из-за потенциальной фрагментации памяти, но также из-за частой работы сборщика мусора (garbage collector), который в свою очередь будет занимать часть времени кадра, приводя к резким падениям FPS. Ситуация усугубляется, если увеличить количество обрабатываемых игровых сущностей на порядок.
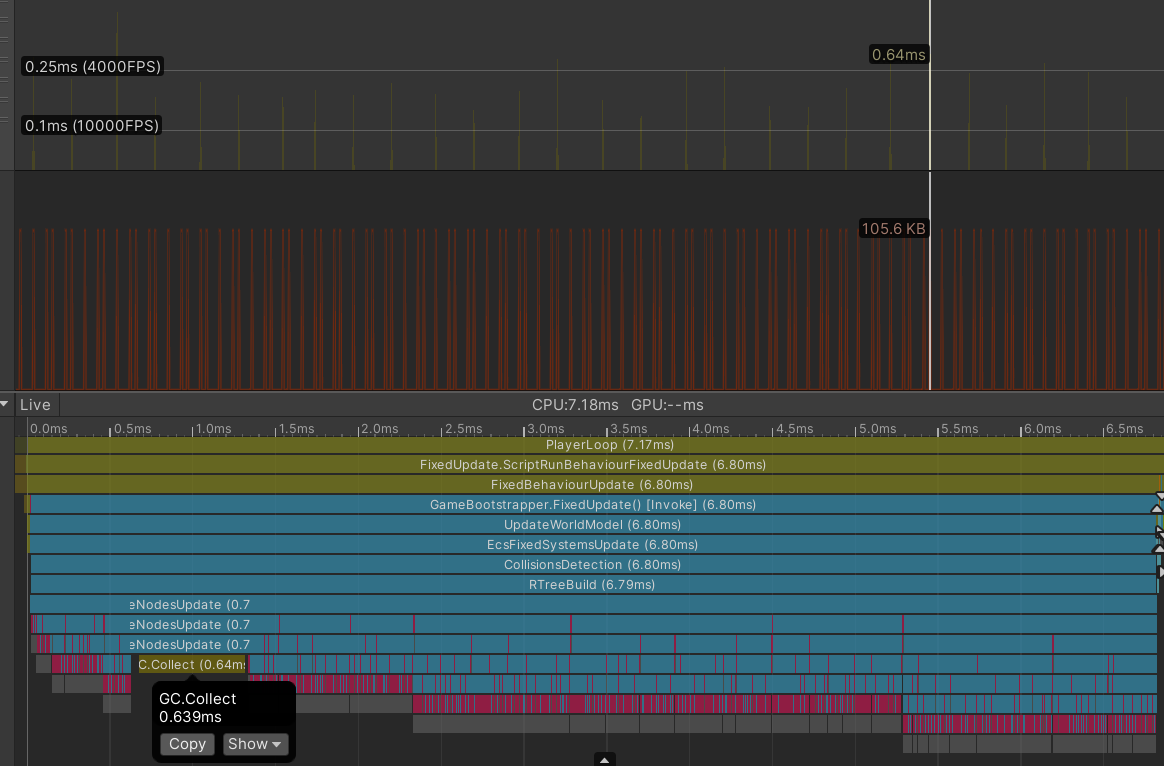
Результат профилирования вставки в дерево полторы тысячи игровых сущностей
Unity приходится вызывать метод GC.Collect заметно чаще, так как и частота выделений памяти повышается значительно, очевидно, из-за большего количества игровых сущностей на поле. В нижней трети скриншота видно как вызов метода GC.Collect прерывает процесс построения дерева, а в верхней трети скриншота отчетливо обозначены так называемые GC spikes — шипы, отображающие нагрузку на сборщика мусора.
Проблема очевидна — нужно избавиться от выделений памяти в куче. Но перед этим, интересно было бы проверить насколько сильно меняется картина при использовании разных реализаций сборщика мусора на разных скриптовых бэкендах. Unity по умолчанию использует реализацию Boehm–Demers–Weiser garbage collector. Данная реализация позволяет не останавливать выполнение игры, отдавая ресурсы системы одной системе — сборщику мусора, а распределять выполнение алгоритмов сборки мусора по времени. Unity позволяет отключить инкрементную систему сбора мусора и взамен использовать stop-the-world реализацию сборщика, чем я воспользовался и сравнил итоговые результаты.
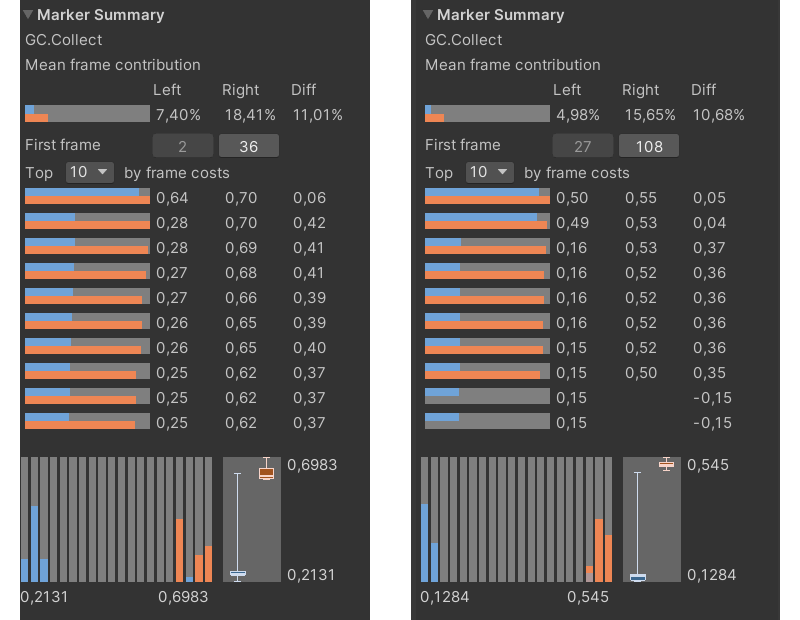
Слева Mono бэкенд, справа IL2CPP; инкрементный вариант сборки мусора обозначен голубым цветом, stop-the-world вариант — рыжим
Результат получился ожидаемый и однозначный. Отмечу также, что далее в профилировании в качестве скриптового бэкенда будет использоваться именно IL2CPP.
Причины выделения памяти:
выделение памяти в контейнерах внутренних и листовых вершин при росте дерева;
boxing при использовании non-generic enumerators;
boxing при использовании методов сравнения Object.Equals() при сравнении экземпляров структур;
создание лямбда функций с захватом и передача их в качестве параметра в метод;
срабатывание со стороны компилятора шаблона поведения »defensive copy» при использовании non-readonly структур.
Избавившись от вышеперечисленных причин результат получился следующий:

Результат вставки 9601 объекта: в верхней половине жёлтым цветом обозначен единственный вызов GC.Collect в течении 1000 кадров, в нижней половине — отсутствие выделений памяти
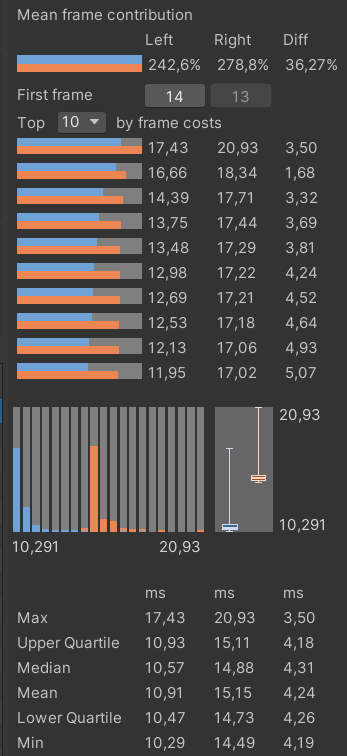
Статистика времени вставки 9601 объекта: рыжий цвет — было, голубой — стало
Вызов GC.Collect теперь происходит значительно реже — примерно один раз в 1000 кадров, и график выделения памяти выровнялся. Выигрыш на кадр составил немногим больше 4 миллисекунд — 10.57 против прежних 14.88 мс. В целом неплохо, но общее время работы всё ещё неприемлемо. Поэтому следующим шагом я решил переложить расчёт алгоритма на несколько потоков.
Unity с версии 2018.1 предоставляет API для работы с потоками Job system. Благодаря этой системе можно распределить нагрузку с одного потока сразу на несколько. Чем больше ядер у процессора устройства и чем больше потоков задействовано, тем больше выгоды от использования потоков.
Для перевода алгоритма на многопоточный вариант работы необходимо перенести хранение всех входных и выходных данных на неуправляемые (unmanaged) контейнеры, одним из которых является NativeArray. По сути своей, это кусок памяти выделенный в куче, время жизни которого не управляется встроенными языковыми средствами и позволяет хранить в себе не преобразуемые и неуправляемые типы и избегать накладных расходов маршалинга (marshalling) при передаче данных между управляемым и неуправляемым кодом (managed и unmanaged code).
Кроме изменения хранения данных необходимо перенести логику алгоритма в задачи (Jobs). Задачи представляют собой структуры наследующие один из интерфейсов IJob или IJobParallelFor, содержат в себе данные и методы для чтения и изменения упомянутых данных. Задачи исполняются воркерами (workers), по одному экземпляру воркера на поток. Входной точкой задачи является метод Execute. У каждого типа задачи своя собственная сигнатура этого метода. Для распределения выполнения алгоритма на несколько потоков необходимо чтобы структура, представляющая собой набор данных и методы обрабатывающие данные, наследовала интерфейс IJobParallelFor.
Ключевым моментом при переходе на многопоточную обработку данных является строгое разделение данных и минимизирование зависимостей между воркерами. Для этого необходимо изменить существующий алгоритм таким образом, чтобы дерево было разделено на несколько поддеревьев, по одному на воркер, и контейнер входных данных из игровых объектов так же был разделён на равные части между воркерами. То же самое происходит и с контейнером с результатами работы алгоритма. Теперь внутри воркера находятся только те данные, которые он должен собрать в поддерево, а само поддерево объединяется по итогу с другими в одно общее дерево для внешнего потребителя, например, для collision resolver.
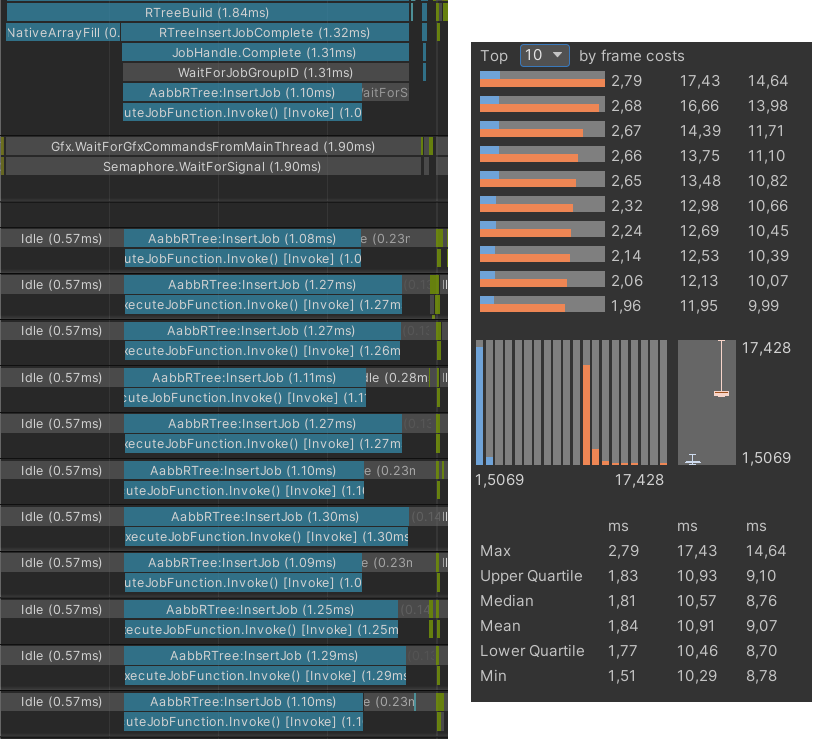
Слева — «средний» кадр при распределении работы на несколько потоков, справа — сравнение статистики по кадрам однопоточного и многопоточного реализаций
На моей машине с 12-поточным процессором Unity может выделить под задачи все 12 потоков. На таймлайне профайлера видно, что вся работа была распределена как раз по 12 воркерам. Кроме собственно работы воркеров, на таймлайне отмечен факт работы и другого метода — NativeArrayFill. Как, возможно, понятно из названия эта часть кода перекладывает данные из управляемого контейнера в неуправляемый NativeArray. Чтобы не тратить на это время можно перенести хранение исходных данных в неуправляемые контейнеры, что в случае моего проекта означает глубокую переделку ECS фреймворка. Другой вариант — завести систему, внутри которой и будут заполняться нужные данные на каждом тике симуляции мира. Второй вариант кажется больше полумерой чем реальным решением, а первый вариант — слишком объемным по времени, чтобы рассматривать этот вариант как ad-hoc оптимизацию. По этим причинам перекладывание данных останется внутри метода алгоритма построения дерева. Но стоит отметить, если изначально хранить все данные о сущностях мира в native-контейнерах, то общее время построения дерева будет определяться только временем работы группы воркеров, медианное значение которого, судя по «среднему» кадру, равно 1.32 мс.
В целом, ускорение построения дерева значительное, но если проанализировать статистику именно по группе воркеров в отрыве от однопоточного варианта, исключив влияние перекладывание данных в нативный контейнер NativeArrayFill, то получится что существует некоторый разброс по статистике:
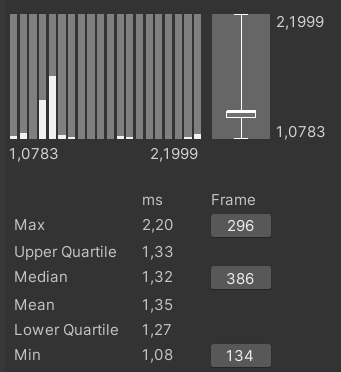
Диаграмма размаха выполнения алгоритма вставки на 12 воркерах
По диаграмме размаха верхняя и нижняя квартили расходятся друг от друга не столь значительно, что хорошо, но максимальные и минимальные значения находятся подозрительно далеко друг от друга. Это может указывать на то, что в нескольких кадрах некоторые воркеры финишируют раньше или позже относительно других, а некоторые могут вообще не включаться в работу, из-за чего общее время работы алгоритма увеличивается, т. к. итоговое значение определяется временем выполнения самого медленного воркера.
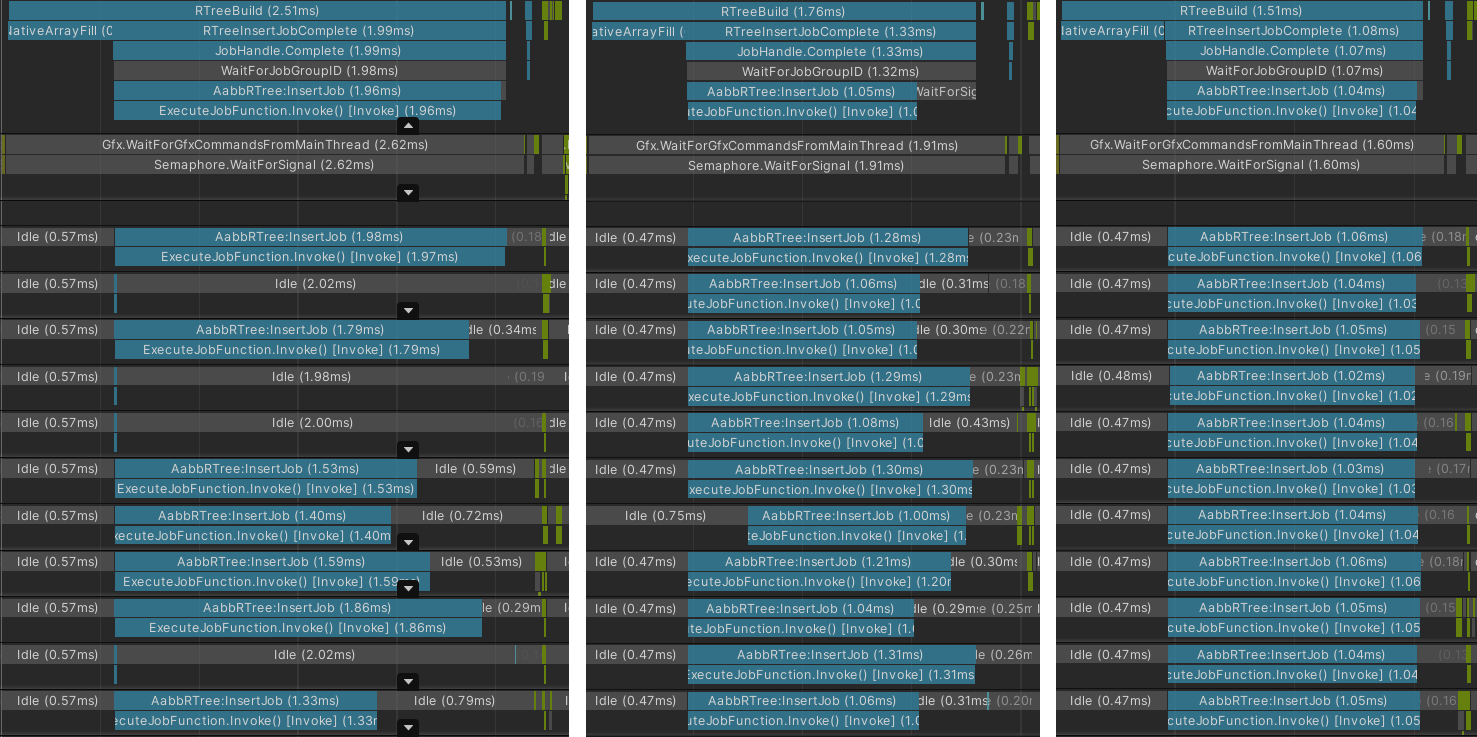
Примеры работы планировщика задач Unity, слева направо: плохо, приемлемо, идеально.
На левом рисунке — это случай, когда Unity, по какой-то причине, решила утилизировать меньшее количество потоков которое ей доступно на текущей машине. На рисунке посередине показан «приемлемый» случай работы планировщика — большинство воркеров начали работу одновременно, но не все завершили свою работу за одно и то же время. Следствием этого является то, что общее время работы воркеров больше чем время работы тех же воркеров в «идеальном» случае на рисунке справа.
Всё это происходит потому, что планировщик Unity не гарантирует ни равномерного распределения нагрузки по воркерам, ни одновременного запуска задач в воркерах. Чтобы уменьшить влияние этой особенности планировщика, необходимо поделить входные данные на сильно меньшие куски, на так называемые батчи (batch), чтобы воркеры могли отбирать работу у других воркеров, если те не успевают со своей частью работы — work stealing подход.
Для того чтобы запланировать задачу на пакетную обработку данных недостаточно используемого интерфейса IJobParallelFor. Для этого нужно использовать другой тип задачи — IJobParallelForBatch. Про этот интерфейс мало что сказано в документации, но всё отличие от IJobParallelFor в том, что нагрузка в такую задачу передается в виде некоторого диапазона обрабатываемых данных (batch). Таким образом, можно поделить входные данные на небольшие куски с расчётом на то что каждый отдельный воркер при каждом вызове метода Execute() будет расширять собственное дерево, отбирая из общего набора данных набор (batch) данных. Что, теоретически, должно исключить ситуации как на рисунке выше с «плохим» вариантом работы планировщика.
Я решил пойти немного дальше и реализовать собственный тип задачи. Это позволило вынести начальную инициализацию каждого отдельного воркера из метода задачи ICustomJob.Execute() внутрь кастомного продюсера задачи JobProducer. С помощью метода GetWorkStealingRange внутри JobProducer«а осуществляется выбор диапазона входных данных для передачи на обработку в сами задачи. Ниже приводится сравнение именно работы группы воркеров, без учёта потраченного времени на перенос данных в нативный контейнер.
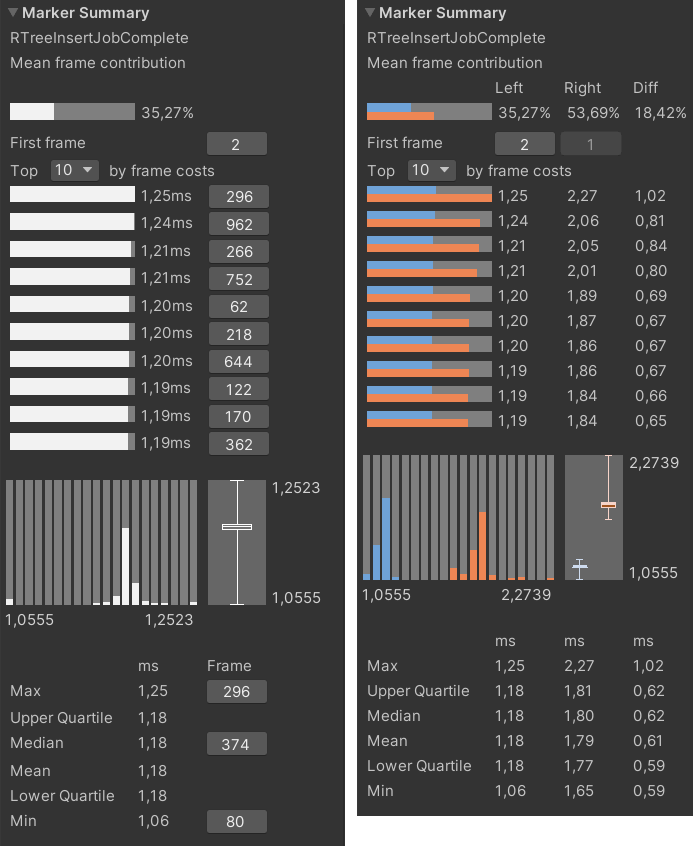
Слева статистика работы пакетной нагрузки воркеров. Справа сравнение времени выполнения группы воркеров с пакетным планированием нагрузки и без
Значения верхней и нижней квартилей не отличаются от медианного значения, что положительно сказалось на общем времени выполнения алгоритма, а минимальное и максимальное значения теперь значительно ближе друг к другу. Даже в самом «худшем» кадре воркеры выстроены по таймлайну идеально:

«Худший» кадр.
В итоге перенос алгоритма на воркеры дал значительный прирост производительности по сравнению с изначальным вариантом реализации алгоритма вставки в дерево:
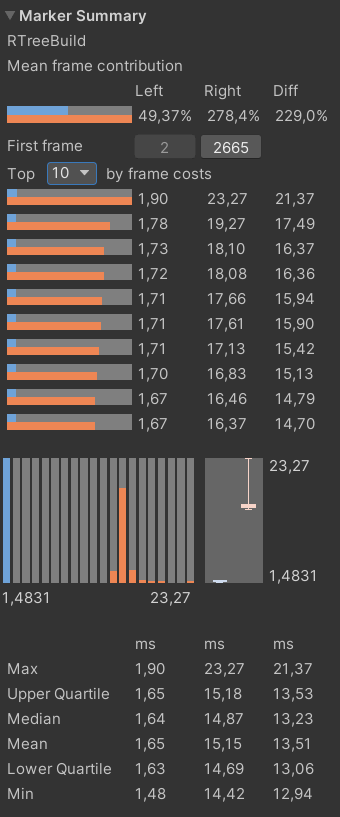
Сравнение изначального варианта с многопоточным вариантом
Но следует отметить один немаловажный момент — work stealing подход означает то, что теперь поддеревья каждого отдельного воркера будут значительно чаще перекрываться между собой по очевидным причинам. Это может сказаться негативно на производительности алгоритмов поиска в дереве. Но эту проблему можно потенциально решить если сами батчи строить исходя из их пространственного положения, например, как в реализациях lowx/lowy packed R-tree или Hilbert R-tree.
Следующий этап оптимизации — оптимизация за счёт компилятора Burst Compiler. Burst компилятор позволяет оптимизировать существующий код практически «бесплатно». Всё что требуется от разработчика это подогнать код под требования самого компилятора. Изменив хранение и чтение данных и код алгоритма в воркерах был получен следующий результат:
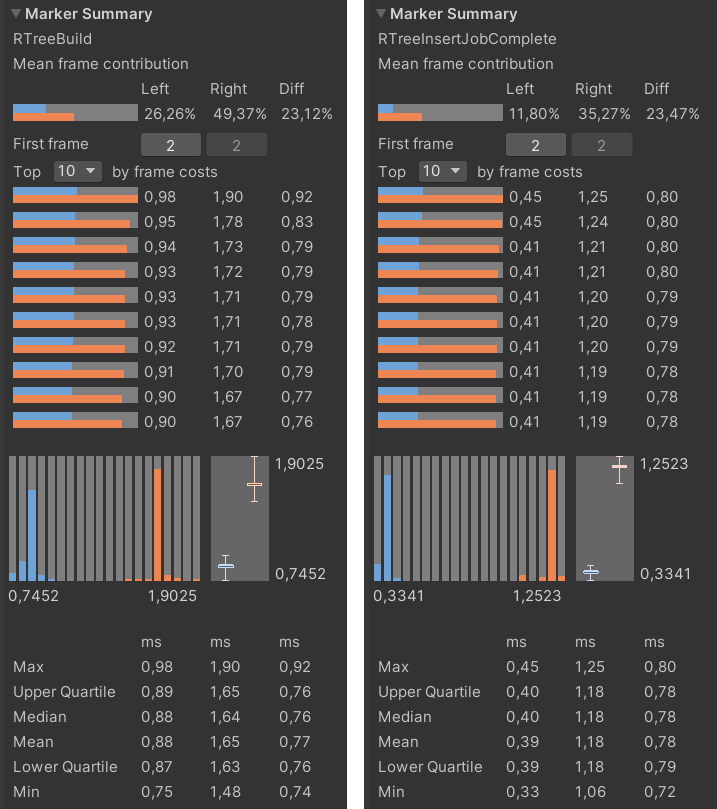
Голубым цветом отмечена оптимизация Burst компилятором: слева с учетом потраченного времени на перенос данных в нативный контейнер, справа — без
Полученный результат оптимизации более чем удовлетворителен — текущие 0.40/0.88 мс против оригинальных 14.87 мс. В целом на этом можно и закончить. Но есть ещё несколько способов как ускорить алгоритм.
Например, как было выше упомянуто, вместо чисел с плавающей запятой в проекте используются числа с фиксированной запятой. Одним из недостатков этого типа является большее количество процессорных инструкций в арифметических операциях и больший занимаемый объем по памяти по сравнению с float32. Если перевести расчёты внутри алгоритма на числа с плавающей запятой одинарной точности, то можно ускорить алгоритм ещё в два-три раза. Кроме этого, если точность вычислений с плавающей запятой не имеет значения, можно указать низкую точность через соответствующий флаг FloatPrecision у атрибута BurstCompile и сэкономить ещё несколько микросекунд на вычислениях.
Хорошими кандидатами для оптимизации через векторизацию являются циклы. Компилятор вполне справляется с этим сам по себе, но при наличии ветвлений внутри тела цикла векторизация может быть невозможна. Если переписать подобные циклы с учётом потенциальной векторизации, есть шанс получить дополнительное ускорение в работе алгоритма. Чтобы не вчитываться в оптимизированный ассемблерный код в поисках проблемных мест, можно использовать интринсик Loop.ExpectVectorized() для валидации на этапе компиляции кода в циклах и в случае подтверждения отсутствия векторизации попытаться по возможности переписать проблемный участок кода.
В ряде случаев может помочь использование атрибута NoAlias. Этот атрибут указывает компилятору что те или иные переменные не будут пересекаться между собой в памяти, что позволяет компилятору не обращаться к памяти за значением одной той же переменной при вычислениях.
При оптимизации за счёт многопоточности стоит учитывать расположение данных в памяти, размеры батча и количество используемых воркеров/потоков — в ряде случаев тонкая настройка в этом направление позволяет уменьшить частоту кэш промахов (cache miss rate).
И как последним вариантом оптимизации следует учесть возможность рефакторинга всего алгоритма с учётом вышеперечисленного, возможно, вплоть до перехода на другой вариант реализации R-дерева.
