Оптимизация SQL-запросов в Oracle
Всем привет. Меня зовут Михаил Потапов, я — главный системный аналитик компании «Ростелеком Информационные Технологии». В компании занимаюсь разработкой отчетности для сегмента B2B и проектированием хранилища данных, на базе которого эта отчетность функционирует. Работоспособность каждого отчета напрямую зависит от корректно выстроенных SQL-запросов к базе данных Oracle, поскольку при работе с большими объемами данных скорость выполнения запросов может существенно снижаться. Снижение скорости сильно затрудняет работу с отчетами для конечного пользователя, а в некоторых случаях и вовсе делает ее невозможной.
В этой статье мы рассмотрим основные принципы оптимизации запросов в Oracle SQL, которые помогут ускорить работу с базой данных и повысить эффективность работы. Сразу отмечу, что статья рассчитана на junior и middle-специалистов, которые пишут сложные запросы к базе данных, работают с большими объемами данных и при этом ранее с вопросом оптимизации не сталкивались. Статья не содержит подробное руководство к действию, но описывает базовые основы «культуры кода», соблюдение которых позволит снизить нагрузку на БД и даст возможность более эффективно извлекать из нее данные.
Основные аспекты оптимизации запроса
1. Минимизация использования DISTINCT
Ключевое слово DISTINCT может быть использовано для удаления дубликатов из результирующего набора данных. Однако использование DISTINCT увеличивает время выполнения запроса, поскольку база данных должна выполнить дополнительные операции для удаления дубликатов. Поэтому рекомендуется использовать DISTINCT только тогда, когда это действительно необходимо.
2. Минимизация использования ORDER BY
Ключевое слово ORDER BY используется для упорядочивания результирующего набора данных по одному или нескольким столбцам. Однако, использование ORDER BY увеличивает время выполнения запроса, особенно если сортировка выполняется по большому количеству данных. Если сортировка не является необходимой, то лучше избегать использования ORDER BY, либо использовать ее в интерфейсе программы:
путем экспорта в excel и последующим использованием встроенных фильтров (если дальнейшая работа с данными предстоит именно в этом инструменте);
путем сортировки BI-инструменте, если скрипт будет использован там.
3. Использование партиций
Партиционирование (секционирование) таблицы — это процесс разделения таблицы на более мелкие, называемые партициями, для улучшения производительности и облегчения управления данными. Каждая партиция содержит отдельный набор данных, который может быть обработан и хранен независимо от других партиций.
При обращении к таблице, в которой есть партиции, обязательно требуется ставить фильтр на партиционированное поле (в условие WHERE или фильтр JOIN’a). При этом не используйте приведение даты к другому формату, поскольку в этом случае произойдет сканирование всей таблицы вместо конкретной партиции.
Например, при обращении к таблице SALES, партиционированной по полю SALE_DT, запрос будет выглядеть следующим образом:

SELECT * FROM SALES WHERE TO_CHAR(SALE_DT, 'YYYY') >= '2022';
SELECT * FROM SALES WHERE SALE_DT >= TO_DATE('01-01-2022', 'DD-MM-YYYY');4. Выборка необходимых полей в SELECT
При обращении к таблице вписывайте в выборку только те поля, которые действительно необходимы. Не используйте символ »*» для вызова всей полей из таблицы, это увеличивает время выполнения запроса/подзапроса.

SELECT * FROM SALES;
SELECT SALE_ID, SALE_DT FROM SALES;5. Соединение таблиц (JOIN’s) по ключам
5.1. Не используйте соединение по неравенству полей.

SELECT s.SALE_ID FROM SALES s
LEFT JOIN ORDERS o ON o.SALE_ID != s.SALE_ID;5.2. Не используйте преобразование данных в ключах соединения таблиц.

SELECT * FROM SALES s
LEFT JOIN ORDERS o ON TO_NUMBER(o.SALE_ID) = s.SALE_ID;
SELECT * FROM SALES s
LEFT JOIN ORDERS o ON o.SALE_ID = s.SALE_ID;5.3. Минимизируйте использование в качестве ключей атрибутов, связи по которым выполняются по принципу «многие-ко-многим».
5.4. Не используйте соединение по текстовым полям (с типом VARCHAR2 / CLOB / LONG).
5.5. Не используйте оператор OR в условии соединения таблиц. При необходимости связать одновременно по условию из разных таблиц лучше сделать 2 отдельных join’a, и затем связать их результат в select’е.

SELECT o.order_name FROM SALES s
LEFT JOIN JOBS j on j.job_id = s.job_id
LEFT JOIN ORDERS o ON (o.SALE_ID = s.SALE_ID OR o.job_id = j.job_id);
SELECT nvl(o1.order_name, o2.order_name) as order_name FROM SALES s
LEFT JOIN JOBS j on j.job_id = s.job_id
LEFT JOIN ORDERS o1 ON o1.SALE_ID = s.SALE_ID
LEFT JOIN ORDERS o2 ON o2.job_id = j.job_id;6. Правильный выбор операторов
6.1. Вместо использования оператора IN для проверки наличия значения в списке, можно использовать оператор EXISTS. Оператор EXISTS останавливается при первом совпадении, в то время как оператор «IN» выполняет полное сканирование списка значений.

SELECT * FROM employees WHERE department_id IN
(SELECT department_id FROM departments);
SELECT * FROM employees e WHERE EXISTS
(SELECT 1 FROM departments d WHERE e.department_id = d.department_id);6.2. Не используйте оператор LIKE там, где можно использовать точное определение значения через равенство либо использовать справочник для определения по идентификаторам.

SELECT * FROM employees where department_name like '%Тестир%';
SELECT * FROM departments where department_name = 'Тестирование';
--ИЛИ--
SELECT * FROM departments where department_id = 1;6.3. Не используйте оператор UNION, если не требуется удаление дубликатов при соединении таблиц. Достаточно использовать UNION ALL.

SELECT sale_num FROM sales
UNION
SELECT sale_num FROM sale_services;
SELECT sale_num FROM sales
UNION ALL
SELECT sale_num FROM sale_services;7. Использование CTE
Общая таблица выражений, или Common Table Expression (CTE) — это временная именованная подзапросная таблица, которая может быть использована внутри основного запроса или другой CTE. Она предоставляет более читабельный и модульный способ написания сложных запросов.
CTE может быть использован для оптимизации запросов в Oracle по нескольким причинам:
Улучшение читабельности: CTE позволяет разбить сложный запрос на более мелкие логические блоки, что делает его более понятным и легким для поддержки и отладки. Кроме того, CTE может быть именована, что дает возможность повторно использовать ее в других частях запроса.
Уменьшение повторения кода: Если одна и та же логика используется в нескольких частях запроса, то ее можно вынести в CTE и использовать ее в разных частях запроса. Это позволяет избежать дублирования кода и упрощает его поддержку.
Улучшение производительности: Использование CTE может помочь оптимизатору запросов принять лучшие решения о плане выполнения запроса. Оптимизатор может использовать информацию о CTE для принятия решений о порядке выполнения операций и выборе оптимальных индексов.
Рекурсивные запросы: CTE также может использоваться для написания рекурсивных запросов, которые требуют выполнения запроса на основе его собственных результатов. Это особенно полезно для работы с иерархическими данными, такими как деревья или графы.
Однако следует помнить, что использование CTE может иметь некоторые ограничения и потребовать дополнительных ресурсов. Например, если CTE используется несколько раз внутри запроса, то каждый раз будет выполнен полный запрос CTE. Поэтому необходимо тщательно оценить выгоду от использования CTE и убедиться, что она превышает затраты на ее выполнение.
Пример использования и синтаксис:
WITH sales_summary AS (
SELECT product_id, SUM(quantity) AS total_quantity
FROM sales
WHERE sale_date >= TRUNC(SYSDATE, 'MM') -- начало текущего месяца
GROUP BY product_id
)
SELECT p.product_name, s.total_quantity
FROM sales_summary s
JOIN products p ON p.product_id = s.product_id
ORDER BY s.total_quantity DESC;
-- то же самое, но через подзапросы:
SELECT p.product_name, s.total_quantity FROM (
SELECT product_id, SUM(quantity) AS total_quantity
FROM sales
WHERE sale_date >= TRUNC(SYSDATE, 'MM') -- начало текущего месяца
GROUP BY product_id) s
JOIN products p ON p.product_id = s.product_id
ORDER BY s.total_quantity DESC;8. Использование материализованных представлений
Материализованные представления (Materialized Views или MV) — это представления, которые хранятся как физические таблицы и могут автоматически обновляться при изменении данных. Использование индексированных представлений может значительно улучшить производительность запросов, особенно для запросов с большими объемами данных.
CREATE MATERIALIZED VIEW mv_employee_names
BUILD IMMEDIATE
REFRESH FAST ON COMMIT
AS SELECT first_name, last_name FROM employees;
SELECT * FROM mv_employee_names WHERE first_name = 'John';Если использование индексированных представлений в вашей БД ограничено, их можно заменить на обычные предрасчетные таблицы, обновление которых настраивается с помощью ETL-инструментов.
9. Минимизация использования множественных вложенных подзапросов
Множественные вложенные подзапросы могут быть плохой практикой из-за следующих причин:
Низкая производительность: каждый подзапрос будет выполняться отдельно, что может привести к повышенной нагрузке на сервер базы данных и увеличению времени выполнения запроса.
Сложность чтения и понимания: чем больше вложенных подзапросов, тем сложнее становится чтение и понимание запроса. Это может затруднить поддержку и обслуживание кода в будущем.
Ограниченность возможностей оптимизации: при использовании множественных вложенных подзапросов оптимизатор базы данных может иметь ограниченные возможности для оптимизации запроса и выбора оптимального плана выполнения.
Как вариант, вложенные подзапросы можно легко заменить на CTE.
SELECT sale_num FROM (
SELECT DISTINCT sale_num, sale_dt FROM (
SELECT * FROM sales where sale_num is not null));
-- тот же запрос, но с использованием CTE:
WITH stg1 as (
SELECT * FROM sales where sale_num is not null)
,stg2 as (
SELECT DISTINCT sale_num, sale_dt FROM stg1)
SELECT sale_num FROM stg2;10. Использование подсказок HINT
Подсказки HINT позволяют указывать оптимизатору базы данных конкретные методы выполнения запросов. Например, можно указать оптимизатору использовать определенный тип JOIN или выбрать определенный индекс.
10.1. Если база данных и сервер позволяют, можно использовать параллельное выполнение запросов для распределения нагрузки и ускорения выполнения запросов.
SELECT /+ PARALLEL(employees, 4) / * FROM employees;10.2. Можно указать оптимизатору использовать конкретный индекс или объединение.
SELECT /+ INDEX(employees idx_employees_name) / * FROM employees
WHERE first_name = 'John' AND last_name = 'Doe';10.3. Можно использовать множество других подсказок, среди которых:
/+ FULL(table_name) / — указывает оптимизатору использовать полный сканирование таблицы вместо индексного сканирования.
/+ ORDERED / — указывает оптимизатору сохранять порядок соединения таблиц, как указано в запросе.
/+ USE_HASH (table_name) / — указывает оптимизатору использовать хэш-соединение для выполнения запроса.
/+ LEADING (table_name) / — указывает оптимизатору начать соединение таблиц с указанной таблицы.
/+ NO_MERGE / — указывает оптимизатору не объединять несколько операций в одну.
/+ NO_EXPAND / — указывает оптимизатору не использовать расширение представлений для выполнения запроса.
/+ OPT_PARAM (parameter value) / — позволяет установить значение параметра оптимизации запроса.
Подробнее про hints тут: https://iusoltsev.wordpress.com/profile/individual-sql-and-cbo/cbo-hints/
Однако следует быть осторожным при использовании подсказок HINT, поскольку неправильное использование может привести к нежелательным результатам.
11. Использованием индексированных атрибутов
Индексы в Oracle — это структуры данных, создаваемые на основе столбцов таблицы, которые позволяют ускорить поиск и сортировку данных. Индексы позволяют быстро находить строки в таблице, содержащие определенные значения в индексированных столбцах. Индексы в Oracle могут быть созданы для одного или нескольких столбцов таблицы.
Существует несколько типов индексов в Oracle:
B-Tree (Balanced Tree) индексы: это наиболее распространенный тип индексов в Oracle. Они используют структуру дерева для организации данных и обеспечивают быстрый поиск по значениям столбца. B-Tree индексы подходят для равенственных и диапазонных запросов.
/*Чтобы найти сотрудника по имени и фамилии, мы можем создать индекс
на колонке "first_name" и "last_name". Это позволит оптимизатору быстро
найти соответствующие записи:*/
CREATE INDEX idx_emp_fio ON EMPLOYEES (first_name, last_name);
SELECT * FROM EMPLOYEES WHERE first_name = 'John' AND last_name = 'Doe';Bitmap индексы: этот тип индексов используется для оптимизации выполнения запросов, содержащих условия сравнения наличия или отсутствия значений в столбцах. Bitmap индексы создают битовую карту, где каждый бит соответствует значению в индексируемом столбце.
CREATE BITMAP INDEX idx_emp_gender ON EMPLOYEES (gender);Функциональные индексы: они создаются на основе выражений или функций, применяемых к столбцам таблицы. Функциональные индексы позволяют ускорить выполнение запросов, содержащих условия поиска, основанные на значениях, полученных из выражений или функций.
CREATE INDEX idx_emp_fio ON EMPLOYEES
(UPPER(first_name) || ' ' || UPPER(last_name));Партиционированные индексы: позволяют создавать индексы на отдельных фрагментах таблицы, называемых разделами. Это позволяет ускорить поиск данных в больших таблицах, разбивая их на более мелкие части и создавая индексы на каждой из них.
CREATE INDEX idx_emp_dep
ON employees (department)
PARTITION BY RANGE (salary)
(
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (5000),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);Уникальные индексы: они гарантируют уникальность значений в индексируемом столбце или комбинации столбцов. Уникальные индексы позволяют быстро проверять наличие дубликатов и обеспечивают целостность данных.
CREATE UNIQUE INDEX idx_emp_mail ON EMPLOYEES (email);Однако следует учитывать, что создание и поддержка индексов требуют дополнительных ресурсов и могут замедлить выполнение операций изменения данных (вставка, обновление, удаление). Поэтому необходимо тщательно оценить необходимость создания индексов и выбрать подходящие типы индексов для конкретных запросов и таблиц.
12. Выбор типа JOIN при соединении таблиц
12.1. Не используйте CROSS JOIN, поскольку он возвращает декартово произведение строк из обеих таблиц.

SELECT s.SALE_NUM, o.ORDER_ID FROM sales s, orders o;
SELECT s.SALE_NUM, o.ORDER_ID FROM sales s
JOIN orders o ON s.sale_id = o.sale_id;
-- ИЛИ
SELECT s.SALE_NUM, o.ORDER_ID FROM sales s, orders o
where s.sale_id = o.sale_id;12.2. Не используйте LEFT JOIN в тех случаях, где достаточно использования INNER (например, в подзапросах или CTE).
12.3. Не используйте FULL JOIN, если в этом нет крайней необходимости. В отличие от LEFT, INNER и RIGHT, где хэш-таблица строится для одной таблицы, при FULL JOIN хэш-таблица строится сразу для двух, что увеличивает время выполнения запроса.
Что на выходе?
Время выполнения сложного запроса в БД в худшем случае не должно превышать пары минут.
Важно! Время выполнения запроса оценивается строго при выгрузке всего объема данных, а не первых 50 строк, как это работает, например, в Oracle SQL Developer. Чтобы выгрузить весь объем, достаточно кликнуть в любую ячейку таблицы и нажать комбинацию CTRL + A («выбрать всё»).
Если соблюдение базовых правил выше не привело к желаемому результату, необходимо обратиться к плану запроса.
Анализ плана запроса
План запроса в Oracle SQL представляет собой информацию о том, как Oracle планирует выполнить запрос и какие операции будут использоваться. Чтение плана запроса помогает понять, какой тип JOIN и какие индексы используются, а также оценить производительность запроса.
Построение плана запроса (рассмотрим на примере ПО Oracle SQL Developer) вызывается через F10 или путем выбора соответствующей кнопки на панели (курсор при этом должен стоять на запросе, без выделения его отдельных частей):

Общий вид плана запроса выглядит следующим образом:

1. Operation (Тип операции) — указывает на тип операции, выполняемой в плане запроса, такой как TABLE ACCESS, INDEX SCAN, JOIN и т.д.
2. Object_name (Имя объекта) — указывает на таблицы/индексы/представления, которые используются в плане запроса. Можно увидеть, какие таблицы сканируются полностью (FULL), какие используются с использованием индексов (INDEX), а также какие таблицы объединяются (JOIN).
3. Options (Параметры) — указывает на конкретное действие при выполнении запроса для каждого типа операции.
4. Cardinality (Кардинальность, или количество строк) — относится к оценке количества строк, которые будут обработаны или возвращены в результате выполнения запроса. Чем больше значение этого показателя, тем менее эффективен запрос. Кардинальность может быть оценена для каждой операции в плане запроса и используется оптимизатором для выбора наиболее эффективного плана выполнения запроса. Неправильная оценка кардинальности может привести к неправильному выбору плана выполнения и, как следствие, к плохой производительности запроса. Оптимизатор Oracle использует статистику таблиц и индексов, а также информацию о распределении данных, чтобы оценить кардинальность.
5. Cost (оценка стоимости) — указывает на оценку стоимости выполнения каждой операции в плане запроса. Более низкая стоимость обычно означает более эффективное выполнение операции.
Как прочитать?
При анализе план просматриваетcя снизу вверх и от самого вложенного процесса (т.е. справа налево).
1. В процессе просмотра в первую очередь обращается внимание на строки с большим значением COST и CARDINALITY.
2. Помимо поиска больших COST и CARDINALITYв строках плана следует просматривать столбец OPERATION плана на предмет наличия в нем HASH JOIN. Соединение по HASH JOIN приводит к соединению таблиц в памяти и, казалось бы, более эффективным, чем вложенные соединения NESTED LOOP. Недостатком этого соединения является то, что при нехватке памяти для таблицы (таблиц) будут задействованы диски, которые существенно затормозят работу запроса.
3. Особое внимание в плане следует так же уделить строкам в плане с операциями полного сканирования таблиц и индексов в столбец OPTIONS: FULL — для таблиц и FULL SCAN, FAST FULL SCAN, SKIP SCAN — для индексов. Причинами полного сканирования могут быть проблемы с индексами: отсутствие индексов, неэффективность индексов, блокировка (например, при применении строковой функции на индексированном поле). При небольшом количестве строк в таблице полное сканировании таблицы FULL может быть нормальным явлением и эффективнее использования индексов.
4. Наличие в столбцах OPERATION и OPTIONS параметра MERGE JOIN CARTESIAN говорит, что между какими-то таблицами нет полной связки. Эта операция возникает при использовании CROSS JOIN, что крайне не рекомендуется делать.
Физические JOIN’s
В Oracle SQL доступны различные типы JOIN. Каждый из них имеет свои особенности и может быть эффективным в разных сценариях.
1. MERGE JOIN — используется для объединения двух таблиц на основе сортированных столбцов. Он основывается на принципе «разделяй и властвуй», где каждая таблица разделяется на отсортированные блоки данных, а затем эти блоки объединяются. MERGE JOIN эффективен при выполнении JOIN операций на больших наборах данных, особенно если обе таблицы отсортированы по соответствующим столбцам. Он также может использоваться при JOIN операциях на неключевых столбцах.
Однако MERGE JOIN требует предварительной сортировки данных, что может занять время и ресурсы. Поэтому он может быть менее эффективным, если данные не отсортированы или если требуется сортировка большого объема данных.

2. HASH JOIN — используется для объединения двух таблиц на основе хэш-значений столбцов. Он создает хэш-таблицу, где каждый элемент содержит пару значений из двух таблиц, которые имеют одинаковые хэш-значения. HASH JOIN эффективен при выполнении JOIN операций на больших наборах данных, особенно если таблицы не отсортированы или если требуется JOIN по неключевым столбцам.
Однако HASH JOIN требует большого объема памяти для создания хэш-таблицы, поэтому он может быть менее эффективным, если доступная память ограничена.

3. NESTED LOOP JOIN — использует вложенные циклы для выполнения JOIN операции. Он последовательно обрабатывает каждую строку из одной таблицы и для каждой строки выполняет поиск соответствующей строки в другой таблице. NESTED LOOP JOIN эффективен при выполнении JOIN операций на небольших наборах данных или когда одна из таблиц имеет мало строк. Он также может быть эффективным, если для JOIN операции доступны индексы на соответствующих столбцах.
Однако NESTED LOOP JOIN может быть медленным, если одна из таблиц имеет большое количество строк или если для JOIN операции отсутствуют соответствующие индексы.
Работа без индекса
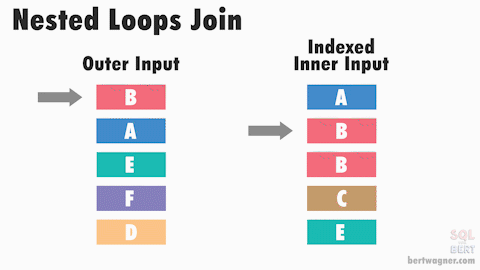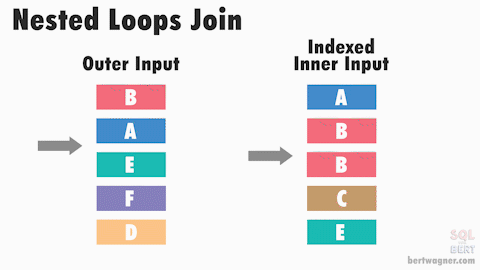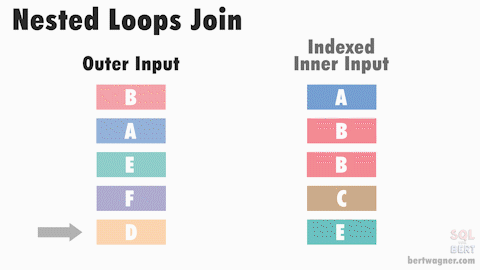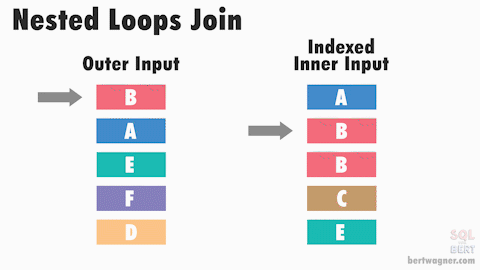
Работа с индексом
Доп.информация
Красивые анимации взяты с сайта https://bertwagner.com/, там же есть ссылки на видео (на английском), где подробно объясняется про физические соединения таблиц.
P.s. это вторая версия статьи, с исправленными примерами и дополнениями.
