Оптимизация сервинга нейросетей
Привет, я работаю ML-инженером в OK и последнее время занимался оптимизацией скорости инференса нейросетей, поэтому сегодня расскажу о них. И не просто о нейросетях, а о нейросетях в продакшене.
Как вы обычно представляете себе нейросеть в продакшене? Мне приходят в голову 4 варианта:
В batch режиме — разово применили модель к данным и используем только полученные предсказания.
В потоке обрабатываем задачи из входящей очереди и пишем в исходящую очередь.
Запустили REST сервис, к которому обращаемся через API.
Применяем непосредственно на том же сервере, на котором выполняется основная логика приложения.
Все эти подходы применяются в различных системах социальной сети Одноклассники. Основная часть моделей у нас обрабатывается комбинированным подходом. Входные данные для модели поступают в очередь, далее подписчик очереди готовит данные и отправляет локальный запрос в REST сервис, на котором производится препроцессинг и инференс.
На данный момент у нас в таком режиме работают несколько сотен нейросетей, например, внутренний OCR сервис и доступный всем deepfake сервис. При таком количестве даже небольшая оптимизация производительности позволят освободить десятки дорогих серверов с GPU для новых задач. В статье расскажу о том, как мы проводили исследование по оптимизации производительности и к какому решению пришли.
Поиск узкого места
На рисунке ниже представлена высокоуровневая архитектура нашей системы инференса нейросетей.

При наличии большого потока запросов к сервису инференса нейросетей мы замечаем, что наш сервер, а точнее GPU, не загружена. Добавление еще одной версии REST сервиса, как показано на следующем рисунке, немного улучшает показатели пропускной способности и утилизации GPU.
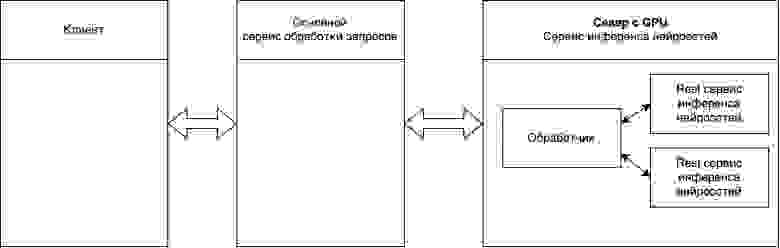
На момент исследования у нас используется самописный REST сервис на FastAPI. Наша основная задача — освободить серверы, перекинув с них нагрузку на незагруженные серверы, поэтому необходимо разобраться как оптимизировать REST сервис с точки зрения пропускной способности.
REST API для инференса нейронки
Чтобы понять, каким образом необходимо подходить к оптимизации, начнем с базового понимания REST сервиса для инференса нейросети. Основной особенностью сервиса для инференса нейросетей, в отличие от большинства других REST сервисов, является постоянная коммуникация между CPU и GPU.

Выглядит просто, пора обратить внимание на проблемы производительности.
Во-первых, для оптимального использования GPU мы должны отправлять несколько объектов в одном пакете.
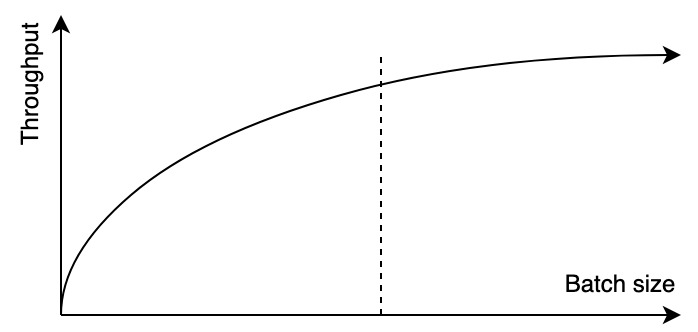 Зависимость пропускной способности от количества объектов в пакете
Зависимость пропускной способности от количества объектов в пакете
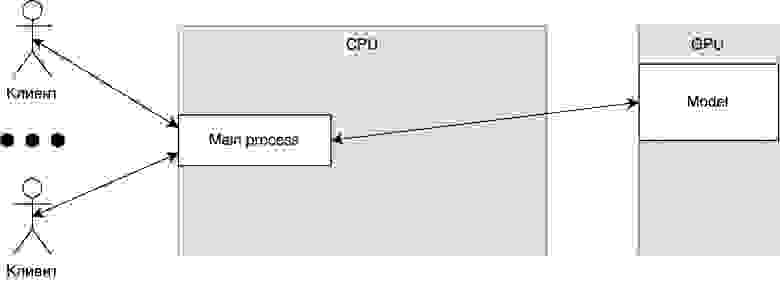
Во-вторых, лучше иметь один GPU процесс, в который будет прилетать batch данных один раз в 100 мс, чем 2 GPU процесса, в каждый из которых будет прилетать batch один раз в 200 мс. Во втором варианте мы теряем производительность из-за особенностей работы GPU и сильнее ограничены в GPU памяти — самом дефицитном ресурсе. На следующем рисунке архитектура, приведенная справа, более производительная, чем архитектура, приведенная слева.
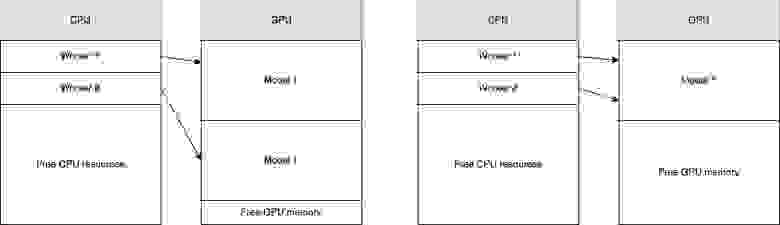
Также в архитектуре слева мы ограничены количеством копий моделей, которые можно загрузить в память GPU.
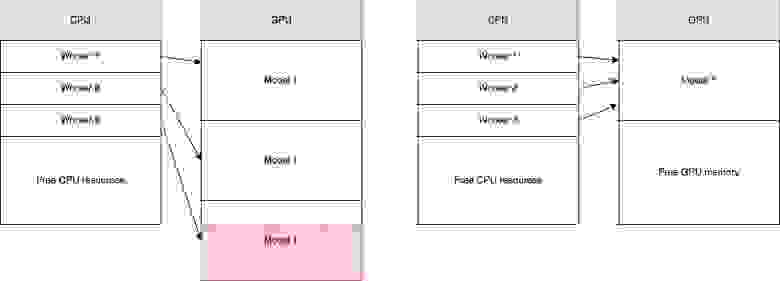
Таким образом нам нужна архитектура, в которой несколько обработчиков могут отправлять запросы в один GPU процесс.
Пока не так всё страшно, но вспомним, что у нас есть пост-процессинг и клиент, который ждет ответ на свой запрос, и расширим архитектуру.

Основное изменение в том, что данные передаются в обоих направлениях, то есть клиент не просто отправляет запрос, чтобы нагрузить GPU, он также хочет получить ответ. Да, мы можем упростить архитектуру и убрать main process. В таком случае мы просто поднимаем REST на каждом процессе, но проблема общения между GPU и CPU процессами сохраняется.
Стоит также заметить, что в этой архитектуре мы предположили, что клиент уже отправляет пакет данных, и мы не должны агрегировать запросы на нашей стороне.
Готовые решения для сервинга нейросетей
Для оптимизации производительности инференса нейросетей существуют готовые решения. Из наиболее популярных стоит выделить TorchServe, TF Serve, Triton, BentoML, Cortex. Для нас важна простота запуска нового сервиса и пропускная способность. Хотя Triton позиционирует себя как фреймворк с хорошей производительностью, мои локальные тесты, а также тесты, которые я смог найти, не показали преимущества Triton над, например, TorchServe с точки зрения пропускной способности. Большинство наших моделей написано на torch, а остальные легко на него мигрировать. Таким образом TorchServe, будучи родным сервингом для PyTorch моделей — хорошее готовое решения для нас. Но эта статья не о том, как мы выбирали фреймворк, мы попытаемся разобраться, как получить такую же производительность без фреймворка и убедиться, что всё корректно настроили.
TorchServe
TorchServe — это фреймворк с открытым исходным кодом для сервинга PyTorch моделей. Для запуска простой модели достаточно реализовать функции пре-процессинга и пост-процессинга. Можно найти большое количество примеров от простых моделей классификации изображений до сложных направленных графов из связанных друг с другом нейросетевых моделей. Детальнее про фреймворк можно почитать в документации, а более подробно разобраться в преимуществах и недостатках — в github issues.
Я попытался узнать, как работает общение между CPU и GPU. Судя по ответу разработчиков, они просто запускают несколько копий моделей на GPU. Но это был ответ разработчика, который сам не писал бэкенд, и на практике я не вижу несколько моделей, запущенных на GPU.
Так как у нас задача оптимизации производительности, то я написал тест, который асинхронно отправляет 1600 изображений и считает время ответа. Для теста TorchServe выбрал простой пример классификации картинок и запускал для resnet-18 и resnet-152. Я тестировал на локальной машине с 4 ядрами и Nvidia 2080TI. Для теста установил 3 min_workers, чтобы оставить одно ядро для основного процесса, batch_size подбирал для каждого запуска отдельно. Тест запускается 20 раз и логируется 95% доверительный интервал. Получаем baseline, который будем стараться побить.
Модель | Доверительный интервал, сек |
Resnet-18 | 4.59–5.07 |
Resnet-152 | 6.58–7.15 |
В проекте https://github.com/BraginIvan/cpu_gpu_async можно найти описание как воспроизвести этот и последующие эксперименты.
Для того, чтобы добиться максимальной производительности, были прописаны некоторые неочевидные настройки
В handler нужно прописать torch.set_num_threads (1), детали можно почитать в github issue
У TorchServe устанавливаются min_workers, initial_workers и max_workers. Можно ожидать что будут запускаться новые процессы пока есть свободные ресурсы CPU и не превышено max_workers, но по факту TorchServe предпочитает использовать именно min_workers процессов. Поэтому необходимо установить min_workers столько, сколько хочется процессов.
Далее посмотрим на примеры кода для различных архитектур: от простой к сложной.
Синхронно в 1 процессе
Начнем с простейшей архитектуры, в которой есть 1 обработчик и одна модель.
app = FastAPI()
cpu = Cpu() # класс который умеет препроцессинг и постпроцессинг
gpu = Gpu() # класс при инициализации загружает модель в GPU и умеет инферить
@app.post("/predict")
async def predict(data: list[bytes] = File(...)):
preprocessed = cpu.pre_process(data)
predicted = gpu.process(preprocessed)
postprocessed = cpu.post_process(predicted)
return postprocessed
Для удобства понимания, я буду показывать код, делать небольшое описание и добавлять схему, как на рисунке ниже для каждого подхода.
 Архитектура. Синхронно в 1 процессе
Архитектура. Синхронно в 1 процессе
TorchServe агрегирует запросы в пакеты на стороне сервера, а наше приложение ждет готовый батч, поэтому необходимо увеличить batch_size в конфиге теста. Получаем такой результат:
Модель | Доверительный интервал, сек |
Resnet-18 | 10.21–10.98 |
Resnet-152 | 14.80–15.52 |
Асинхронно. Несколько CPU обработчиков
Добавим несколько CPU процессов для параллельного пре-процессинга. Как я писал выше, нам лучше иметь одну копию модели на GPU, поэтому для общения между CPU процессами и процессом, в котором работает GPU, будем использовать встроенные очереди из python.
from multiprocessing import Manager
manager = Manager()
gpu_queue = manager.Queue()
prediction_queue = manager.Queue()Нам нужен GPU процесс, который будет принимать сообщения из входящей очереди, обрабатывать и отправлять в исходящую очередь. А так же CPU процессы, которые будут писать в очередь для GPU.
def gpu_processing(input_queue: Queue, output_queue: Queue):
gpu = Gpu()
while True:
key, batch = input_queue.get()
preds = gpu.process(batch)
output_queue.put((key, preds))
def cpu_processing(batch, gpu_queue:Queue, req_id: int):
result = cpu.pre_process(batch)
gpu_queue.put((req_id, result))Запустим этот GPU процесс и несколько CPU процессов при инициализации сервиса.
@app.on_event("startup")
async def startup_event():
app.state.executor = ProcessPoolExecutor(max_workers=3)
loop = asyncio.new_event_loop()
loop.run_in_executor(ProcessPoolExecutor(max_workers=1), input_queue_listener, gpu_queue, prediction_queue)Пишем основной endpoint:
# тут есть баг
@app.post("/predict")
async def predict(data: list[bytes] = File(...)):
loop = asyncio.get_event_loop()
loop.run_in_executor(app.state.executor, cpu_processing, data, gpu_queue, id)
return cpu.post_process(prediction_queue.get())Проблема в том, что мы из очереди, вероятно, заберем предсказания для другого запроса. Нам надо как то забрать из prediction_queue тот самый ответ, который нужно вернуть текущему клиенту.
Я реализовал далеко не самое оптимальное решение, но в такой архитектуре других идей нет.
Давайте с каждым запросом прокидывать его идентификатор, это может быть рандомное число или лучше хэш от запроса. Также в отдельном потоке читать очередь и создавать словарь, в котором для идентификатора будут храниться предсказания.
results = {}
async def read_predict(id):
for _ in range(100):
await asyncio.sleep(1/10)
if id in results:
return results.pop(id)
try:
key, value = prediction_queue.get(block=False)
if key == id:
return value
else:
results[key]=value
except:
pass
return -1Перепишем основной endpoint:
@app.post("/predict")
async def predict(data: list[bytes] = File(...)):
# тут конечно лучше хэш запроса, но для теста и так норм.
id = random.randint(0, 1000000)
loop = asyncio.get_event_loop()
loop.run_in_executor(app.state.executor, cpu_processing, data, gpu_queue, id)
res = await read_predict(id) # ждем когда идентификатор появится в словаре
return cpu.post_process(res)Распараллеливание пост-процессинга сильно усложнит код. Полное отключение постпроцессинга не влияет на результаты теста, так как там выполняются относительно простые действия. Поэтому я решил оставить его в основном процессе.
 Асинхронно. Несколько CPU обработчиков
Асинхронно. Несколько CPU обработчиков
У меня не получилось запустить этот код на текущем окружении и получить сопоставимый отчет. Выполнение model.to («cuda») в отдельном процессе зависает. Раньше запустить получалось, но версии библиотек не были зафиксированы, сравнимые результаты по старым запускам будут в итоговой таблице.
Асинхронно. REST API на каждом процессе
Как я писал выше, нам ничего не мешает отказаться от «мастер» процесса и поднять REST сервис в каждом процессе.
Часть кода, связанная с созданием очередей и работой GPU, почти не меняется, осталось только создать несколько исходящих очередей — по одной для каждого обработчика. Вместо идентификатора запроса мы используем порт, с которого прилетел запрос.
cpu = Cpu()
gpu = Gpu()
manager = Manager()
gpu_queue = manager.Queue()
ports = [8080, 8081, 8082]
out_queues = {port: manager.Queue() for port in ports}
def input_queue_listener(input_queue: Queue, output_queues: dict[Queue]):
gpu = Gpu()
while True:
key, port, batch = input_queue.get()
preds = gpu.process(batch)
output_queues[port].put((key, preds))Каждый процесс может работать синхронно, а значит у нас нет никакой проблемы понять, какой предикт вернуть клиенту.
def get_app(gpu_queue: Queue, out_queue: Queue, port: int):
app = FastAPI()
@app.post("/predict")
async def predict(data: list[bytes] = File(...)):
# в этот раз синхронно работаем, можно хэш посчитать
id = hash(data[0])
res = cpu.pre_process(data)
gpu_queue.put((id, port, res))
return cpu.post_process(out_queue.get()[1])
return appСтартуем несколько API:
def start_rest(port: int):
app = get_app(gpu_queue, out_queues[port], port)
uvicorn.run(app, host="127.0.0.1", port=port)
if __name__ == "__main__":
for port in ports:
p = Process(target=start_rest, args=(port,))
p.start()
input_queue_listener(gpu_queue, out_queues)
Архитектурно выглядит так.
 Асинхронно. REST API на каждом процессе
Асинхронно. REST API на каждом процессе
Получаем такие результаты:
Модель | Доверительный интервал, сек |
Resnet-18 | 4.53–4.96 |
Resnet-152 | 6.04–6.69 |
Сеть вместо очередей
После просмотра небольшого курса по асинхронности в python, мне пришла идея заменить очередь и словари на сокеты. В таком подходе у нас создается соединение между процессами и нам не нужно понимать, какое сообщение от какого клиента было получено.
Для начала запускаем сервер сокет. Сервером у нас будет GPU процесс, с которым сможет соединиться любой CPU процесс и отправить данные по сети.
def gpu_listener():
gpu = Gpu()
def accept_connection(server_socket):
client_socket, addr = server_socket.accept()
selector.register(fileobj=client_socket, events=selectors.EVENT_READ, data=gpu_process)
def gpu_process(client_socket):
batch = recvall(client_socket)
preds = gpu.process(batch)
client_socket.send(preds)
client_socket.close()
selector.unregister(client_socket)
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server_socket.bind((localhost, 5000))
server_socket.listen()
selector.register(fileobj=server_socket, events=selectors.EVENT_READ, data=accept_connection)
while True:
events = selector.select()
for key, _ in events:
callback = key.data
callback(key.fileobj)На основном endpoint создаем соединение с GPU сервером, отправляем данные и ждем ответа.
@app.post("/predict")
async def predict(data: list[bytes] = File(...)):
res = cpu.pre_process(data)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((localhost, 5000))
s.sendall(res.tobytes())
s.shutdown(socket.SHUT_WR)
data = recvall(s)
data = np.frombuffer(data, dtype="float32")
data = data.reshape(-1, 1000)
s.close()
return cpu.post_process(data)В данном случае имеем такую архитектуру.

Как и в предыдущем варианте мы запускаем по одному API на каждом процессе, так как такой подход оказался производительнее. Получаем следующие результаты теста.
Модель | Доверительный интервал, сек |
Resnet-18 | 4.98–5.42 |
Resnet-152 | 6.67–7.45 |
Итоги
Сведем все результаты в таблицу. Во время исследования я использовал другой компьютер с более мощным CPU (8 ядер вместо 4) и такой же GPU. Результаты, которые получил на этапе исследования добавил в колонку «Старый запуск».
Подход | Resnet-18 | Resnet-152 | Старый запуск |
TorchServe | 4.59–5.07 | 6.58–7.15 | 7.06 |
Синхронно | 10.21–10.98 | 14.80–15.52 | 20.39 |
Асинхронно | - | - | 8.34 |
Несколько портов | 4.53–4.96 | 6.04–6.69 | 7.66 |
Сокеты | 4.98–5.42 | 6.67–7.45 | 6.16 |
Видно, что TorchServe из коробки дает такую же пропускную способность, как лучшее из решений, которые мы разобрали. Результаты сильно зависят от конфигурации сервера, на которой проводится тестирование. При большем количестве CPU ядер решение с сокетами выигрывает. В итоге мы сделали выбор в пользу TorchServe и уже запустили одну модель в продакшн. В дальнейшем расскажем подробнее о том, как выглядит наша архитектура инференса нейросетей и сколько серверов мы освободим после переезда всех моделей на TorchServe.
