Одномерный лес и все прочее
Для кого статья
В первую очередь статья для меня, чтобы сформулировать мои неокрепшие знания в теме и вместе с тем попрактиковаться в написании этих самых деревьев.
Ну и надеюсь кто-то найдет статью интересной, поэтому постараюсь больше показывать и предоставлять реализации, и делать как можно меньше скучных формул)
Что за деревья такие
Дерево принятия решений (также называют деревом классификации или регрессионным деревом) — средство поддержки принятия решений, использующееся в машинном обучении, анализе данных и статистике.
Структура дерева представляет собой «листья» и «ветки». На рёбрах
(«ветках») дерева решения записаны признаки, от которых зависит целевая
функция, в «листьях» записаны значения целевой функции,
а в остальных узлах — признаки, по которым различаются случаи. Чтобы
классифицировать новый случай, надо спуститься по дереву до листа и
выдать соответствующее значение.
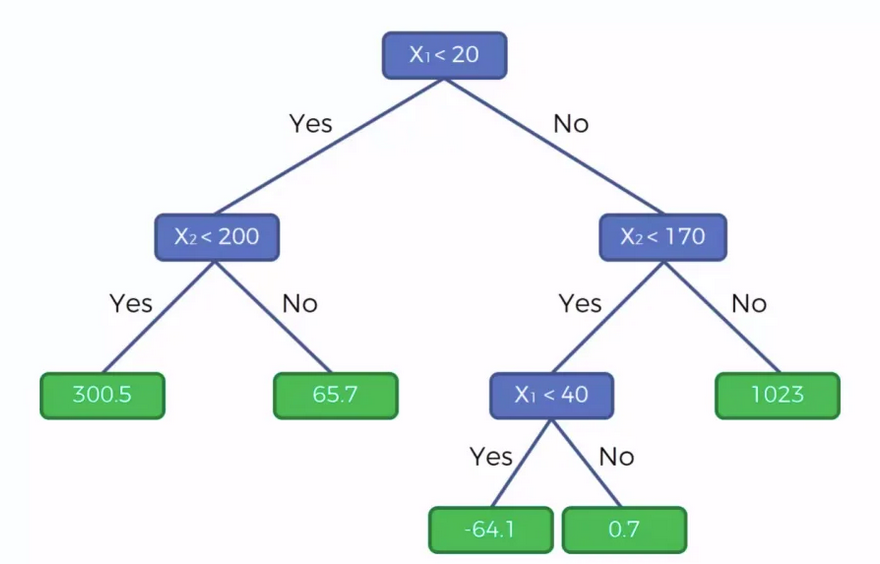
Пример дерева решений
Определение с Википедии.
Грубо говоря это просто бинарное дерево, которое в каждом этапе делает выбор на основании входных данных, разбивая входные данные на 2 группы в каждой ветви.
Дойдя до листьев дерево возвращает среднее (либо медианное) обучающих данных.
Принятие решений происходит по формуле

Наша задача в данном случае найти X.
А тут все просто, мы группируем входные данные на интервалы и берем среднее (или медианное) каждого интервала, и пытаемся подставлять вместо X.
Попадая в локальный минимум по loss, оставляем значение как дискриминатор.
Листинг кода
Вспомогательные функции
Для начала потребуется определить функции для выяснения наших функций потерь и метрик:
![MSE = \sum{(y_{pred} - y_{true})^2} \\[10px] MAE = \sum{\left| y_{pred} - y_{true} \right|} \\[10px] Accuracy = \frac{TP + TN}{TP + TN + FP + FN}](https://habrastorage.org/getpro/habr/upload_files/cb2/f9b/9a8/cb2f9b9a8d6c572bffa6ddfb98839dcf.svg)
В формулах нет ошибки, коэффициент 1/N был отброшен намерено за ненадобностью.
def get_mse_loss(model, x,y):
return ((model.predict(x) - y)**2).mean()
def get_mae_loss(model, x,y):
return np.abs(model.predict(x) - y).mean()
def get_accuracy(model, x,y):
count = 0
preds = model.predict(x)
for i in range(len(preds)):
if (preds[i] == y):
count +=1
return count/len(y)Само дерево
class MyDecisionTree:
@staticmethod
def get_loss(node, x, y, loss_type):
preds = np.array([node.classify(i) for i in x])
if loss_type == "mse":
return ((preds - y)**2).mean()
if loss_type == "mae":
return np.abs(preds - y).mean()
raise NotImplementedError
class NodeTree:
def __init__(self, approx, separator:float = 0, left_node = None, right_node = None,):
self.separator = separator
self.approx = approx
self.left_node = left_node
self.right_node = right_node
#we can divide dataset into intervals with certain step and calculate means of it
@staticmethod
def get_intervals(x,y, step):
means = []
for i in range(len(x)-min(step, len(x))+1):
means.append((x[i:i+min(step, len(x))], y[i:i+min(step, len(x))]))
return means
#creates node with minimal loss
@staticmethod
def create_node(x,y, loss_type, step):
if len(x) == 0:
raise ValueError("empty data")
intervals = MyDecisionTree.NodeTree.get_intervals(x,y, step)
min_loss = 100000000
minNode = None
if len(intervals) < 1:
raise ValueError("inrervals must be more than 0")
for i in intervals:
approx = i[1].mean() if loss_type == "mse" else np.median(i[1])
n = MyDecisionTree.NodeTree(approx, i[0].mean())
loss = MyDecisionTree.get_loss(n, x, y, loss_type)
if loss < min_loss or minNode is None:
min_loss = loss
minNode = n
if minNode is None:
raise ValueError("null node")
return minNode
#this function creates new nodes from leaves
def grow(self, x,y, loss, step, min_data_size = 2):
if(len(x)) < min_data_size:
return
if(len(x)!=len(y)):
raise ValueError
l_x =[]
l_y =[]
r_x =[]
r_y =[]
for i in range(len(x)):
if x[i] < self.separator:
l_x.append(x[i])
l_y.append(y[i])
else:
r_x.append(x[i])
r_y.append(y[i])
if self.left_node is None or self.right_node is None:
if(len(l_x)):
self.left_node = self.create_node(np.array(l_x),np.array(l_y), loss, step)
else:
self.left_node = MyDecisionTree.NodeTree(approx=self.approx)
if(len(r_x)):
self.right_node = self.create_node(np.array(r_x),np.array(r_y), loss, step)
else:
self.right_node = MyDecisionTree.NodeTree(approx=self.approx)
else:
self.left_node.grow(np.array(l_x), np.array(l_y), loss, step, min_data_size)
self.right_node.grow(np.array(r_x), np.array(r_y), loss, step,min_data_size)
def classify(self, x:float):
if self.left_node is None or self.right_node is None:
return self.approx
if(x < self.separator):
return self.left_node.classify(x)
return self.right_node.classify(x)
def __init__(self, loss = "mse", interval_step = 2, min_node_data_size = 2, max_depth = None):
self.loss = loss
self.step = interval_step
self.min_data_size = min_node_data_size
self.max_depth = max_depth
def fit(self, x, y, logging = False):
self.root = MyDecisionTree.NodeTree.create_node(x,y, self.loss, self.step)
iters = 0
while (self.max_depth is None or iters < self.max_depth):
loss = MyDecisionTree.get_loss(self.root, x,y, self.loss)
self.root.grow(x,y, self.loss, self.step, self.min_data_size)
new_loss = MyDecisionTree.get_loss(self.root, x,y, self.loss)
if logging:
print(f"iter {iters}: loss: {loss} new loss: {new_loss}")
iters+=1
if loss <= new_loss and iters > 5:
break
self.depth = iters
def predict(self, x):
return np.array([self.root.classify(i) for i in x])
Пример работы
x = np.arange(0, 100)
y = 5*np.sin(3*x/len(x)* 2*np.pi)
tree = MyDecisionTree(loss="mse")
tree.fit(x[::3],y[::3])
plt.scatter(x,y, color="orange")
x_tree = np.linspace(-5,len(x)+5,len(x)*10)
plt.plot(x_tree, tree.predict(x_tree), "-")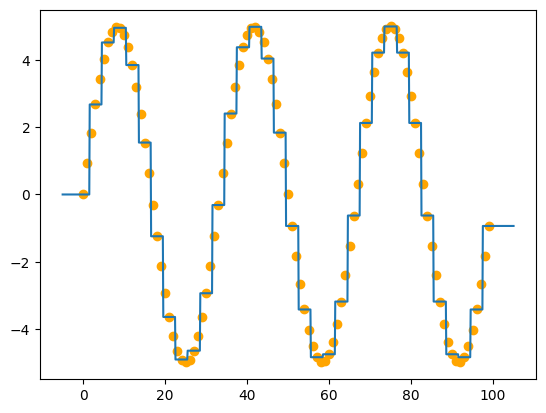
Аппроксимация синуса через дерево
Возможно у вас появился вопрос: «а почему ты передаешь каждый третий отсчет функции, а не каждый?». А я вам отвечу: Потому что… Ну, а вообще особенность дерева заключается в том, что деревья способны запомнить весь датасет и оно так и сделает, дайте ему возможность.
Выводы
Сделаем recap информации на текущий момент:
Деревья разделяют обучающие данные на 2 группы в каждом узле на основании какого-то значения X
Листья дерева аппроксимируют значения к среднему из дошедшей до листа обучающей подвыборки
Деревья аппроксимируют данные в виде ступенчатых функций
Деревья очень сильно подвержены переобучению
Из последних двух следует, что деревья готовы поглощать данные в любом виде практически без первичных обработок
Дерева мало, посадим лес
Деревья — это конечно круто, но если мы можем позволить себе bagging, то почему бы его и не использовать.
Как это работает
Случайный лес — это ансамблевый метод аппроксимации, работающий по следующему алгоритму:
Делим датасет на какие-то случайные куски в n кусков по m элементов в каждом, где n — количество деревьев (если длинна датасета меньше, чем n*m, то будут пересечения, что не плохо)
Скармливаем подвыборки деревьям
Аппроксимируем данные каждым деревом и далее
Если задача классификации — выбираем мажоранту
Если задача регрессии — берем среднее
А собственно и все:-)
Листинг кода
Лес
class RandomForest:
def __init__(self, estimators_count = 100, loss="mse", approx = "regression", max_depth = None, interval_size = 2, min_node_data = 2, cluster_size = None):
self.__forest = [MyDecisionTree(max_depth = max_depth, interval_step= interval_size, min_node_data_size = min_node_data, loss=loss) for _ in range(estimators_count)]
self.__cluster_size = cluster_size
self.__approx = approx
@staticmethod
def __spit_dataset(x,y, cluster_size, splits):
subsets = []
n_x = list(x)
n_y = list(y)
for i in range(splits):
set = ([],[])
for i in range(cluster_size):
ind = r.randint(0, len(n_x)-1)
set[0].append(n_x.pop(ind))
set[1].append(n_y.pop(ind))
if (len(n_x) ==0):
n_x = list(x)
n_y = list(y)
subsets.append(set)
return np.array(subsets)
@staticmethod
def get_loss(forest, x, y, loss_type = "mse"):
pred = forest.predict(x)
if (loss_type == "mse"):
return ((pred - y)**2).mean()
if (loss_type == "mae"):
return np.abs(pred - y).mean()
def fit(self, x, y, logging=False):
if self.__cluster_size is None:
self.__cluster_size = len(x)//3
data = RandomForest.__spit_dataset(x,y, self.__cluster_size, len(self.__forest))
for index_tree in range(len(self.__forest)):
if(logging):
print(f"tree: {index_tree}/{len(self.__forest)}")
self.__forest[index_tree].fit(data[index_tree][0],data[index_tree][1], logging= logging)
def predict(self, x):
predicts = np.array([i.predict(x) for i in self.__forest]).T
if self.__approx == "regression":
return predicts.mean(axis=1)
if self.__approx == "classification":
return st.mode(predicts)
raise ValueError("approximation type error")Пример работы
forest = RandomForest(cluster_size=60)
forest.fit(x,y, logging=False)
plt.scatter(x,y, color="orange")
x_tree = np.linspace(-5,len(x)+5,len(x)*10)
plt.plot(x_tree, forest.predict(x_tree), "-")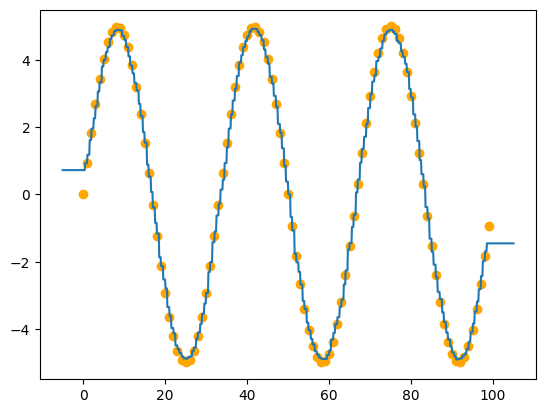
Аппроксимация через случайный лес
Можно заметить, что график стал мягче, благодаря усреднению результатов.
Древесный бустинг
Разобравшись с bagging методом, разберемся с другим ансамблевым методом — boosting.
В отличии от случайного леса, где каждое дерево делает предсказание из одних и тех же данных. В бустинге наши деревья делают предсказание друг за другом, предсказывая ошибку предыдущего.
Отличной аналогией является игра в гольф: первым ударом мы максимально сокращаем расстояние с лункой, а каждым последующим подгоняем шар как можно ближе.
![\text{Первое дерево} \\ err_{1} = Y_{true} - y_{pred1} \\ \text{Второе дерево}\\ err_{2} = err_{1} - y_{pred2} = Y_{true} - y_{pred1} - y_{pred2}\\ \text{n дерево}\\ err_{n} = Y_{true} - \sum_{i=1}^{n}{y_{pred_{i}}} \\[15px] \text{Итоговая формула }\\ y_{pred} = \sum_{i=1}^{n}{y_{i}}](https://habrastorage.org/getpro/habr/upload_files/3ac/400/9aa/3ac4009aa4dd46201668b651ec10def7.svg)
Листинг кода
Бустинг
class ForestBoosting:
def __init__(self, estimators_count = 100, loss = "mse", approx = "regression"):
self.__estimators_count = estimators_count
self.__loss = loss
self.__approx = approx
self.__forest = None
def fit(self, x,y, logging = False):
data = y
trees = []
last_loss = 10000000
for i in range(self.__estimators_count):
tree = MyDecisionTree(loss=self.__loss, interval_step=len(x)//2, max_depth=5)
if (logging):
print("tree:", i)
tree.fit(x, data, logging = logging)
pred = tree.predict(x)
data = (data - pred)
trees.append(tree)
l = (data**2).mean() if self.__loss == "mse" else np.abs(data).mean()
if(logging):
print("err:", l)
if last_loss <= l:
break
last_loss = l
self.__forest = trees
def predict(self, x):
if(self.__forest is None):
raise ValueError("Boosting not fitted")
res = np.zeros(shape=len(x))
for tree in self.__forest:
res += tree.predict(x)
return resyПример работы
oscillation_x = np.linspace(0,5,1000)
oscillation_y = np.exp(-oscillation_x)*5*np.sin(10*oscillation_x)
boosting = ForestBoosting(loss="mse")
boosting.fit(oscillation_x, oscillation_y, True)
plt.scatter(oscillation_x,oscillation_y, color="orange")
x_tree = np.linspace(-1,6,1000)
plt.plot(x_tree, boosting.predict(x_tree), "-")
plt.grid(True)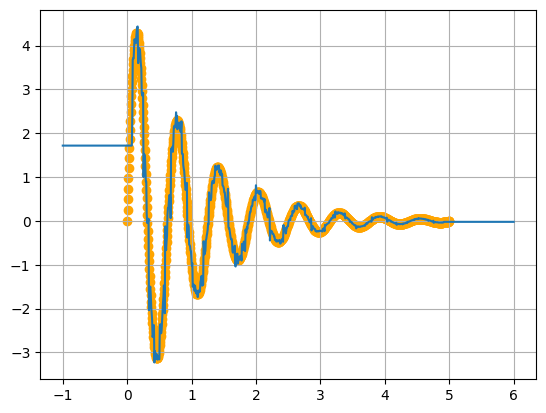
Аппроксимация через бустинг
Заключение
Касательно статьи, то было разобрано 3 варианта аппроксимации на основе решающих деревьев с примером кода и практически без математических выкладок.
Жду ваших замечаний, пожеланий и прочего :-)
